ps:本文较长,全文两千五百字左右!
前言
半导体工艺和架构是提升CPU性能的双驾马车。CPU的发展史,其实就是处理器架构和半导体工艺交互升级、协同演进的发展史。半导体工艺采用更先进的制程,晶体管尺寸变小了,芯片面积降低了,CPU的主频就可以做得更高;在相同的工艺制程下,通过不断优化CPU架构,从Cache、流水线、乱序执行、SIMD、多发射、指令预测等方面不断更新迭代,就可以设计出比别家公司性能更高、功耗更低的处理器。
单核处理器的瓶颈
在相同的半导体工艺制程下,芯片的面积越大,芯片的良品率就越低,芯片的成本就会越高,功耗也会越大。而在相同的工艺下,提升芯片性能和减少功耗之间往往又是冲突的。
以Cache为例,我们可以通过增加L1、L2、L3级Cache的容量来增加Cache的命中率,提高CPU的性能,但芯片的面积和功耗也会随之增加。流水线同样如此,我们可以通过增加流水线级数、减少每一级流水的时间延迟,来提高处理器的主频,但随之而来的就是芯片电路的复杂性增加。鱼与熊掌不可兼得,很多厂家在发布自己的处理器时,都会根据产品的市场定位在性能、成本和功耗之间反复做平衡,或者干脆发布一系列低、中、高端产品:要么追求高性能,要么追求低功耗,要么追求能效比。单核时代的玩法玩得差不多了,就要换种新玩法,才能让消费者有欲望和动力扔掉旧机器,刷着花呗白条更新换代。于是,一个更加缤纷多彩的多核大战时代来临了。
片上多核互连技术
现代的计算机,无论是PC、手机还是服务器,一般都是多个任务同时运行,单核CPU的性能再强劲,其实也是在串行执行这几个任务,多个任务轮流占用CPU运行。只要任务切换得足够快,就可以以假乱真,让用户觉得多个程序在同时运行。多核处理器则可以让多个任务真正地同时执行。在单核处理器通过指令级并行性能提升空间有限的情况下,通过多核在任务级做到真正并行,可以进一步提升CPU的整体性能。单核处理器芯片内部除了集成CPU的各个基本电路单元,还集成了各级Cache。当在一个芯片内部集成多个核(Core)时,各个Core之间怎么连接呢?Cache是每个Core独享,还是共享?不同架构的处理器,甚至相同架构不同版本的处理器,其连接方式都不一样。早期的计算机比较简单,CPU和内存、I/O模块直接相连,这种连接也称为星型连接。星型连接通信效率最高,但是浪费的资源也多。举一个简单的例子,如邮局,如图。

星型连接与总线型连接图
计算机的CPU和其他模块,如果像邮局一样采用星型连接,通信效率确实高效,快递员到每家都有专门的道路,永不堵车。但星型连接成本高、可扩展性差:如果老王家的小王结婚盖了新房,则还需要专门修一条新公路,从邮局通到小王家;小李家拆迁了,乔迁新居,原来的公路就浪费了,还得继续修公路通到新家。为了解决这种缺陷,如图2-44右侧图所示,总线型连接就产生了:各家共享公路资源,邮局对他们各家进行编址管理。总线型连接可以随意增加或减少连接模块,兼容性和扩展性都大大增强。在单核处理器时代,总线型连接是最理想和最经济的,但是到了多核时代就未必如此了。

总线连接图
总线型连接也有缺陷,在某一个时刻只允许一对设备进行通信,当多个Core同时想占用总线与外部设备通信时,就会产生竞争,进而影响通信效率。一个解决方法是使用线性阵列,分段使用总线,就像高速公路上的不同收费点一样,多个处理器可以分段使用总线资源进行通信,如IBM的Cell处理器。另一个解决方法是使用交叉开关(Crossbar)。交叉开关像路由器一样有多个端口,多个Core可以通过交叉开关的端口互连,并行通信。相互通信的各对节点都是独立的,互不干扰。
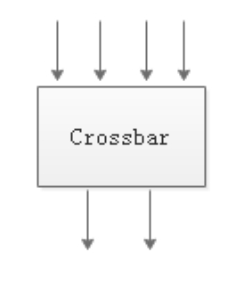
交叉开关图
交叉开关可以提高通信效率,但其自身也会占用芯片面积,功耗很大,尤其当连接设备很多,交叉开关的端口很多时,芯片面积和功耗会急剧上升。为了缓解这一矛盾,我们可以使用层次化交叉开关,通过层次化交叉开关可以在局部构建一个节点的集群,然后在上一层将每个局部的集群看成一个节点,再通过合适的方式进行连接。

层次交叉开关图
层次化交叉开关利用网络通信的局部特征,缓解了单个开关在连接的节点上升时产生的性能下降,在性能、芯片面积和功耗之间达到一个平衡。交叉开关两两互连如下图所示,处理器的多个Core之间通过开关可以相互独立通信,效率很高。但随之而来的问题是,随着连接节点增多,交叉开关的互连逻辑也越来越复杂,功耗和占用的芯片面积也越来越大,所以这种连接结构一般适用于四核以下的CPU。

交叉开关两两相连图
四核以上的CPU可以采用Ring Bus结构(如下图所示):将总线和交叉开关结合起来,连成一个环状,相邻的两个Core通信效率最高,远离的两个Core之间可以通过开关路由通信。Intel的八核处理器一般都是采用这种结构的。

Ring Bus结构
Ring Bus结构结合了总线型连接和开关型连接两者的优点,在成本功耗和通信效率之间达到一个平衡,但是也有局限性,当这个环上连接的Core很多时,通信延迟又会带来效率下降。面向服务器的处理器一般都是16核以上的,这种众核结构如果再使用以上连接方式则都会有局限性,影响多核整体性能的发挥。面向众核处理器领域,目前比较流行的一种片上互连技术叫作片上网络(Net On Chip,NoC)。
现在比较常用的二维Mesh网络,当处理器的Core很多时,我们不再使用总线型连接,而是使用网络节点的方式连接。每个节点包括计算单元、通信单元及其附属电路。计算和通信实现了分离,每一个节点中的处理单元可以是一个Core,也可以是一个小规模的SoC。Core与Core之间的通信基于通信协议进行,数据包在网络中按照设定的路由算法传输,通过网络通信的分布化来避免总线的竞争。当2D Mesh网络连接的Core很多时,距离较远的两个Core,因为经过太多的路由,通信延迟也会对处理器整体性能产生一定影响。将网络路径中每一条线的首尾路由节点相连,就变成了二维的Ring Bus结构,即Torus网络,可以进一步减少路由路径较远时带来的通信延迟。

二维Mesh网络



