文章目录
- 一、彻底弄懂IO
- 1、基本概念
- 2、IO 模型
- 二、IO发展历程
- 1、OS基础
- 2、引入
- 3、BIO
- 4、NIO
- 5、select
- 6、poll
- 7、epoll
- 8、对比总结
- 三、IO是个细活
- 1、epoll
- 2、零拷贝
- 附:分布式学习路径
相关链接:
https://www.topgoer.cn/docs/golangxiuyang/golangxiuyang-1cmef12eubu5j
https://blog.csdn.net/TTTZZZTTTZZZ/article/details/87888487
https://www.bilibili.com/video/BV11K4y1C7rm?p=2
一、彻底弄懂IO
BIO→NIO→select→epoll
从内核的角度去看 IO 这件事,这也是IO发展的根本原因。
1、基本概念
- 同步
同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。 - 异步
异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
- 阻塞
阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。 - 非阻塞
非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。 - BIO
Blocking I/O:同步阻塞I/O模型。
数据的读取写入必须阻塞在一个线程内等待其完成。 - NIO
New I/O: 同步非阻塞的I/O模型。
NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
BIO与NIO的区别:
(1)IO流是阻塞的,NIO流是不阻塞的。
(2)IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
(3)NIO 通过Channel(通道) 进行读写。
(4) NIO有选择器,而IO没有。
- AIO
Asynchronous I/O: 异步非阻塞的IO模型 。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
2、IO 模型

二、IO发展历程
redis、nginx、netty[可设置]、kafka等热门技术都是基于epoll。
1、OS基础

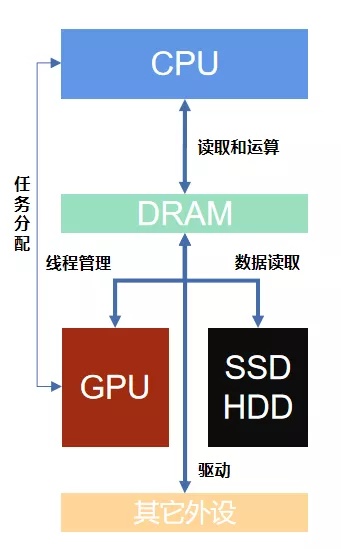
程序存在磁盘里,加载到内存之后才能run起来。
PC开机后第一个运行的程序kernel,它向下管理硬件,向上承托其它程序。
kernel内核程序进入内存之后,进行GDT【全局描述符表】注册,它划分出用户空间和内核空间。内核不能被其它程序直接修改,因为需要保证OS的安全可靠,所以开启了保护模式【基于CPU指令集rang0到3】。
程序是不能直接IO访问硬件的,内核可以。所以程序都是通过系统调用syscall【软中断】的方式去调内核进行IO【包括磁盘IO、网络IO等】。这个IO是需要成本的。如何降低IO成本,是IO发展【BIO>NIO>select>epoll>AIO等多路复用技术】的初衷。
2、引入
一个简单的BIO代码示例。

抓取命令【抓取程序与OS发生的系统调用syscall】
strace -ff -o ./ooxx java TestSocket.java 一个输出文件就是一个线程。
查找哪个文件是主程序 grep 'step1' ./*

思路:如果某个程序慢,找出这个进程,看这个进程下是不是有很多线程。

执行 客户端连接命令:【网络就会多一个连接,文件描述符也多了一个socket,主线程文件就会多一个accept系统调用过程:socket、bind、listen、poll、accept【创建socket会生成一个socket文件并且生成文件描述符,套字节文件,用于存储建立链接后的数据】】
nc localhost 8090

java其实并不值钱,JVM虚拟机才是真正的有价值。凡是可以编译成字节码的语言【不止java】都可以运行在JVM上。
java是解释型语言。JVM是java的解释器,它将由java编译来的字节码文件解释成OS认识的程序,然后再去j进行系统调用。【这也是Java比C语言慢的原因】
3、BIO
凡是服务端应用程序,一定会有以下几个步骤:

socket、bind、listen、accept【这时如果没有客户端连接,则会阻塞,如果有多个客户端来连接,则clone新的线程来处理客户端连接:一个线程对应一个客户端,这是传统的BIO】
缺点很明显:成本高,无论是新建scoket,clone新线程[也占用栈内存,线程切换浪费CPU成本],还是读写,都需要系统调用syscall软中断。根本原因:阻塞的,bio使得不得不新建多线程。如何非阻塞?
确实可以解决早期的业务,但是随着业务越来越丰富,不得不考虑降低IO成本。
BIO 通过clone新线程处理client请求证明如下:

4、NIO
上述BIO的缺陷使得不得不考虑在应用层实现NIO。
服务器操作系统OS是支持非阻塞NIO的,通过执行 man 2 socket 可以证明。
如果在app应用层【比如Java NIO】可以调用OS底层的NIO【不再创建新线程,通过for死循环来轮询】,那么就实现了的应用层级别的NIO。
app应用层的NIO:New IO。OS操作系统的NIO:NonBlocking IO。

但是NIO也有缺陷:C10K问题。比如来了10000个客户端连接,不管客户端有没有发送数据,服务端就会通过轮询【O[n]复杂度,即O[n]次syscall】所有socket文件来判断有没有发送数据【O[m]复杂度】。所以在高并发下虽然没有新建多个线程,但是多次的系统调用syscall还是依然存在。
5、select
服务器操作系统OS支持另外一种非阻塞的系统调用select,通过执行 man 2 select 可以证明。
select 多路复用器。一次性读取【O[1]复杂度】所有socket文件,处理有数据发送【O[m]复杂度】的的客户端。
缺点:一次需要传很多文件数据【虽然只syscall了一次,但是拷贝了很多数据到内核】;需要CPU主动遍历O[n]次来判断谁发送了数据。

-
select函数执行流程
step1、从用户空间拷贝fd_set(注册的事件集合)到内核空间。
step2、遍历所有fd文件,并将当前进程挂到每个fd的等待队列中,当某个fd文件设备收到消息后,会唤醒设备等待队列上睡眠的进程,那么当前进程就会被唤醒。
step3、如果遍历完所有的fd没有I/O事件,则当前进程进入睡眠,当有某个fd文件有I/O事件或当前进程睡眠超时后,当前进程重新唤醒再次遍历所有fd文件。 -
select函数的缺点
单个进程所打开的FD是有限制的,通过 FD_SETSIZE 设置,默认1024。
每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大。
每次调用select都需要将进程加入到所有监视socket的等待队列,每次唤醒都需要从每个队列中移除。
select函数在每次调用之前都要对参数进行重新设定,这样做比较麻烦,而且会降低性能。
进程被唤醒后,程序并不知道哪些socket收到数据,还需要遍历一次。
6、poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的
7、epoll
如何避免select多路复用器的两个缺陷:
一次需要传很多文件数据。→ 基于增量模式传文件数据。
需要CPU主动遍历O[n]次来判断谁发送了数据。→ 基于事件驱动模式【硬件中断。充分发挥硬件,尽量不浪费CPU】。
epoll可以理解为event pool,不同与select、poll的轮询机制,epoll采用的是事件驱动机制,每个fd上有注册有回调函数,当网卡接收到数据时会回调该函数,同时将该fd的引用放入rdlist就绪列表中。
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
- epoll执行流程
step1、调用epoll_create()创建一个ep对象,即红黑树的根节点,返回一个文件句柄。
step2、调用epoll_ctl()向这个ep对象(红黑树)中添加、删除、修改感兴趣的事件。
step3、调用epoll_wait()等待,当有事件发生时网卡驱动会调用fd上注册的函数并将该fd添加到rdlist中,解除阻塞。
服务器操作系统OS支持epoll,通过执行man epoll、man epoll_create、man epoll_ctr、man epoll_wait可以证明。

示例:通过strace命令追踪redis、nginx、kafka等应用程序,可以发现epoll技术的使用。
- nginx

- redis

细节问题:同样使用epoll,nginx为啥阻塞,redis为啥轮询?
redis是单线程的,除了IO,它还需要做其它事,比如LRU、LFU、RDB、AOF等,所以需要轮询。
nginx的work进程仅仅就是等客户端连接,,不需要做其它事情,所以阻塞。nginx的work进程仅仅就是等客户端连接,,不需要做其它事情,所以阻塞。
8、对比总结
select、poll、epoll等都是多路复用器的实现,返回的是I/O的状态[哪个客户端连接是通的]。读写仍然需要程序自己发起,所以都是同步。
EPOLL支持的最大文件描述符上限是整个系统最大可打开的文件数目, 1G内存理论上最大创建10万个文件描述符。
每个文件描述符上都有一个callback函数,当socket有事件发生时会回调这个函数将该fd的引用添加到就绪列表中,select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多。
三、IO是个细活
redis在版本6.X之前都是单线程,原子性、串行化操作。
redis在版本6.X之后支持多线程,并发读、串行写【写仍然是原子性操作】。
1、epoll

2、零拷贝
kafka是基于JVM的。
kafka是怎么做持久化的?→零拷贝、mmap。
考虑到内核kernel,很多技术的创新都在于减少内核调用。
kafka写:用到mmap技术,将数据封装好之后通过mmap直接刷到磁盘的segment文件上,充分利用硬件支持的mmap技术,不经过syscall。
这里用到虚拟内存,虚拟内存是一种内存扩种技术,如果通过参数设置【RandomAccessFile】可以用到堆外内存,所以才能直接映射到磁盘,不会浪费内存。
kafka读:如果没有零拷贝,消费者消费数据的流程:请求给kafka,kafak调用内核,内核读磁盘,数据从磁盘返回给内核,内核拷贝给kafka,kafka再把数据write给内核的socket返回给客户端。
零拷贝技术,消费者消费数据的流程:请求给kafka,kafak调用内核的sendfile,内核读磁盘,数据从磁盘返回给内核,内核不需要再拷贝给kafka【零拷贝的前提:数据不需要加工】,直接返回到客户端。

附:分布式学习路径
从网络到分布式。
- 网络
高并发负载均衡:网络协议原理
高并发负载均衡:LVS的DR TUN,NAT模型推导
高并发负载均衡:LVS的DR模型试验搭建
高并发负载均衡:基于keepalived的LVS高可用搭建 - redis
redis介绍及NIO原理
redis的string类型&bitmap
redis的list、set、hash、sorted_set、skiplist
redis的消息订阅、pipeline、事务、modules、布隆过滤器、缓存LRU
redis的特久化RDB、fork、copyonwrite、AOF、RDB&AOF混合使用
redis的集群:主从复制、CAP、PAXOS、cluster分片集群
redis开发:spring.data.redis、连接、序列化、high/low api - zookeeper
zookeeper介绍、安装、shell c小i使用,基本概念验证
zookeeper原理知识,paxos、zab、角色功能、AP开发基础
zookeeper案例:分布式配置注册发现、分布式锁、ractive模式编程