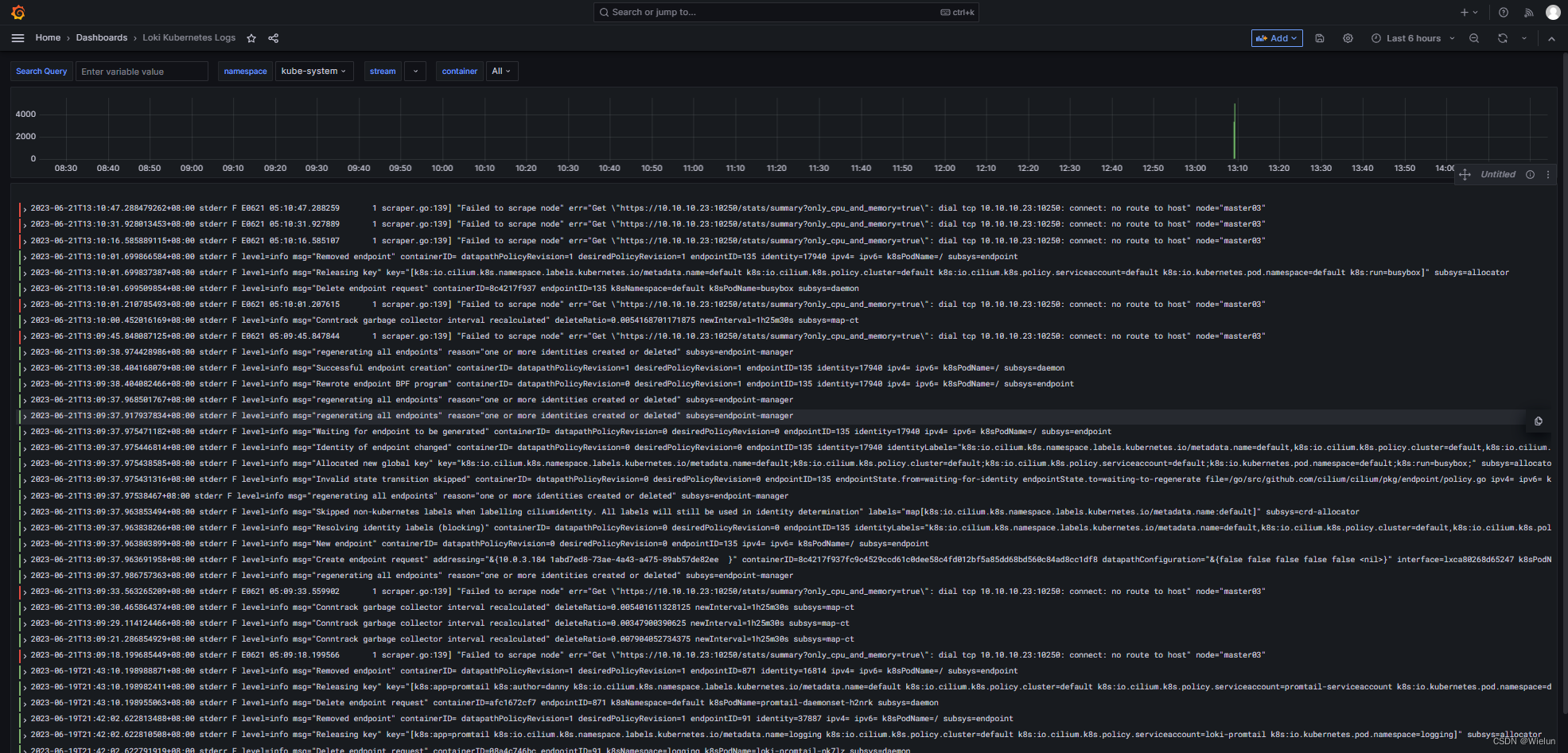
| Top-k抽样 | 模型从最可能的"k"个选项中随机选择一个 | 如果k=10,模型将从最可能的10个单词中选择一个 |
| Top-p抽样 | 模型从累计概率大于或等于“p”的最小集合中随机选择一个 | 如果p=0.9,选择的单词集将是概率累计到0.9的那部分 |
| Temperature | 控制生成文本随机性的参数。较高的温度值会产生更随机的输出,而较低的温度值则会使模型更倾向于选择最可能的单词 | 较高的温度值,如1.0,会产生更随机的输出,而较低的温度值,如0.1,会使模型更倾向于选择最可能的单词 |
前言
上一篇文章介绍了几个开源LLM的环境搭建和本地部署,在使用ChatGPT接口或者自己本地部署的LLM大模型的时候,经常会遇到这几个参数,本文简单介绍一下~
- temperature
- top_p
- top_k
关于LLM
上一篇也有介绍过,这次看到一个不错的图
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.

LLM看似很神奇,但本质还是一个概率问题,神经网络根据输入的文本,从预训练的模型里面生成一堆候选词,选择概率高的作为输出,上面这三个参数,都是跟采样有关(也就是要如何从候选词里选择输出)。
temperature
用于控制模型输出的结果的随机性,这个值越大随机性越大。一般我们多次输入相同的prompt之后,模型的每次输出都不一样。
- 设置为 0,对每个prompt都生成固定的输出
- 较低的值,输出更集中,更有确定性
- 较高的值,输出更随机(更有创意😃)

一般来说,prompt 越长,描述得越清楚,模型生成的输出质量就越好,置信度越高,这时可以适当调高 temperature 的值;反过来,如果 prompt 很短,很含糊,这时再设置一个比较高的 temperature 值,模型的输出就很不稳定了。
遇事不决就调参,调一下,万一就生成了不错的回答呢?
PS:ChatGLM提供的例子把范围限定在0-1之间。
top_k & top_p
这俩也是采样参数,跟 temperature 不一样的采样方式。
前面有介绍到,模型在输出之前,会生成一堆 token,这些 token 根据质量高低排名。
比如下面这个图片,输入 The name of that country is the 这句话,模型生成了一堆 token,然后根据不同的 decoding strategy 从 tokens 中选择输出。

这里的 decoding strategy 可以选择
- greedy decoding: 总是选择最高分的 token,有用但是有些弊端,详见下文
- top-k: 从 tokens 里选择 k 个作为候选,然后根据它们的
likelihood scores来采样 - top-p: 候选词列表是动态的,从 tokens 里按百分比选择候选词
-
Top-k抽样 模型从最可能的"k"个选项中随机选择一个 如果k=10,模型将从最可能的10个单词中选择一个 Top-p抽样 模型从累计概率大于或等于“p”的最小集合中随机选择一个 如果p=0.9,选择的单词集将是概率累计到0.9的那部分 Temperature 控制生成文本随机性的参数。较高的温度值会产生更随机的输出,而较低的温度值则会使模型更倾向于选择最可能的单词 较高的温度值,如1.0,会产生更随机的输出,而较低的温度值,如0.1,会使模型更倾向于选择最可能的单词
top-k 与 top-p 为选择 token 引入了随机性,让其他高分的 token 有被选择的机会,不像 greedy decoding 一样总是选最高分的。
greedy decoding
好处是简单,坏处是容易生成循环、重复的内容
Greedy decoding is a reasonable strategy but has some drawbacks such as outputs with repetitive loops of text. Think of the suggestions in your smartphone's auto-suggest. When you continually pick the highest suggested word, it may devolve into repeated sentences.
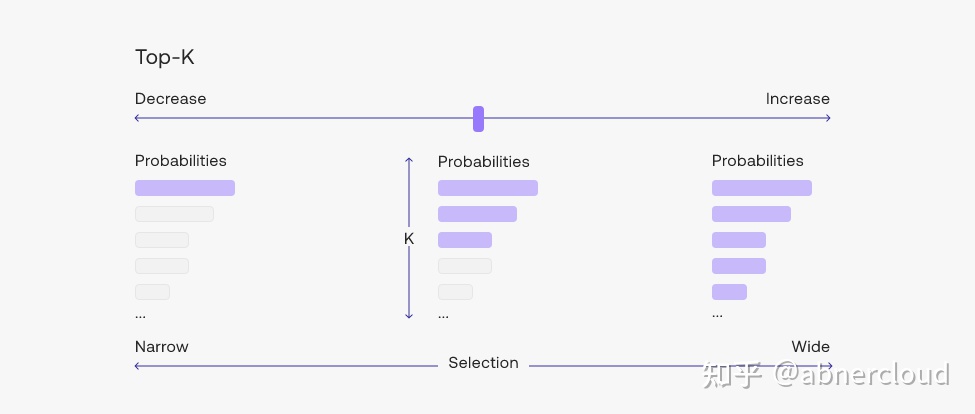
top-k
设置越大,生成的内容可能性越大;
设置越小,生成的内容越固定;
设置为1时,和 greedy decoding 效果一样。

Changing the top-k parameter sets the size of the shortlist the model samples from as it outputs each token. Setting top-k to 1 gives us greedy decoding.
top-p
top-p 又名 Nucleus Sampling(核采样)
与 top-k 固定选取前 k 个 tokens 不同,top-p 选取的 tokens 数量不是固定的,这个方法是设定一个概率阈值。
继续上面的例子,将 top-p 设定为 0.15,即选择前 15% 概率的 tokens 作为候选。如下图所示,United 和 Netherlands 的概率加起来为 15% ,所以候选词就是这俩,最后再从这些候选词里,根据概率分数,选择 united 这个词。

Top-p is usually set to a high value (like 0.75) with the purpose of limiting the long tail of low-probability tokens that may be sampled. We can use both top-k and top-p together. If both
kandpare enabled,pacts afterk.
经常遇到的默认 top-p 值就是 0.7/0.8 这样,还是那个说法,设置太低模型的输出太固定,设置太高,模型彻底放飞自我也不好。
2.从top tokens中挑选:top-k
另一种常用的策略是从前 3 个tokens的候选名单中抽样。这种方法允许其他高分tokens有机会被选中。这种采样引入的随机性有助于在很多情况下生成的质量。
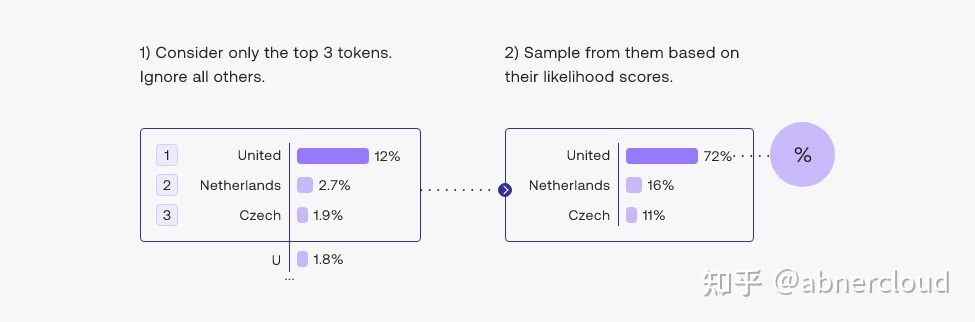
Adding some randomness helps make output text more natural. In top-3 decoding, we first shortlist three tokens then sample one of them considering their likelihood scores.
更广泛地说,选择前三个tokens意味着将 top-k 参数设置为 3。更改 top-k 参数设置模型在输出每个token时从中抽样的候选列表的大小。将 top-k 设置为 1 可以进行贪心解码。
Adjusting to the top-k setting.
3.从概率加起来为15%的top tokens中挑选:top-p
选择最佳 top-k 值的困难为流行的解码策略打开了大门,该策略动态设置tokens候选列表的大小。这种称为Nucleus Sampling 的方法将可能性之和不超过特定值的top tokens列入候选名单。top-p 值为 0.15 的示例可能如下所示:

In top-p, the size of the shortlist is dynamically selected based on the sum of likelihood scores reaching some threshold.
Top-p 通常设置为较高的值(如 0.75),目的是限制可能被采样的低概率 token 的长尾。我们可以同时使用 top-k 和 top-p。如果 k 和 p 都启用,则 p 在 k 之后起作用。
参考资料
- docs.cohere.com/docs/contro…
- docs.cohere.com/docs/temper…
- mp.weixin.qq.com/s/IswrgDEn9…