前言
书接上回,我们实现了批量修改文件的时间,但是却没有实现文件名称的批量修改,是因为我也说过,没有界面的话直接在命令行实现显得有点繁琐,所以我们就通过接口+界面的方式来实现我们这个小需求吧。所以,闲话不多说啦,开始写我们的代码啦~~
本次教程过于啰嗦,所以这里先放上预览地址供大家预览——点我预览,也可到文末直接下载代码先自行体验。。。
简单的说下实现的效果
通常我们在蓝湖上下载的切图是和UI小姐姐定义的图层名相关的,一般下载下来之后我们就需要修改名称,但是一个个修改又显得十分傻逼 ??,所以我们就自己写一下代码自己修改,具体效果如图:

看到这里,是不是也想跃跃欲试啦,所以,我们就开始写我们的代码吧
简单的搭建一下
新建一个 batch-modify-filenames 目录
初始化一个node项目工程
npm init -y
安装依赖,这里依赖比较多,所以下面我会讲一下他们大概是干嘛的
npm i archiver glob koa koa-body koa-router koa-static uuid -S
npm i nodemon -D
koa Nodejs的Web框架
koa-body 解析 post 请求,支持文件上传
koa-router 处理路由(接口)相关
koa-static 处理静态文件
glob 批量处理文件
uuid 生成不重复的文件名
nodemon 监听文件变化,自动重启项目
archiver 压缩成 zip 文件
ps:nodemon 是用于我们调试的,所以他是开发依赖,所以我们需要-D。其他的都是主要依赖,所以-S
配置一下我们的启动命令
{
...
"scripts": {
"dev": "nodemon app.js"
},
...
}
Koa 是什么
既然用到了Koa,那么我们就了解一下他是什么?
Koa 是由 Express 原班人马打造的,致力于成为一个更小、更富有表现力、更健壮的 Web 框架,采用了 async 和 await 的方式执行异步操作。 Koa 并没有捆绑任何中间件, 而是提供了一套优雅的方法,帮助您快速而愉快地编写服务端应用程序。也正是因为没有捆绑任何中间件,Koa 保持着一个很小的体积。
通俗点来讲,就是常说的后端框架,处理我们前端发送过去的请求。
上下文(Context)
Koa Context 将 node 的 request 和 response 对象封装到单个对象中,为编写 Web 应用程序和 API 提供了许多有用的方法。 这些操作在 HTTP 服务器开发中频繁使用,它们被添加到此级别而不是更高级别的框架,这将强制中间件重新实现此通用功能。
Context这里我们主要用到了state、request、response这几个常用的对象,这里我大概讲讲他们的作用。
state 推荐的命名空间,用于通过中间件传递信息和你的前端视图。
req Node 的 Request 对象.
request Koa 的 Request 对象.
res Node 的 Response 对象.
response Koa 的 Response 对象.
ctx.req 和 ctx.request 的区别
通常刚学Koa的时候,估计有不少人弄混这两个的区别,这里就说说他们两有什么区别吧。
最主要的区别是,ctx.request 是 context 经过封装的请求对象,ctx.req 是 context 提供的 node.js 原生 HTTP 请求对象,同理 ctx.response 是 context 经过封装的响应对象,ctx.res 是 context 提供的 node.js 原生 HTTP 响应对象。
所以,通常我们是通过ctx.request获取请求参数,通过ctx.response设置返回值,不要弄混了哦 (⊙o⊙)
ctx.body 和 ctx.request.body 傻傻分不清
以为通常get请求我们可以直接通过ctx.query(ctx.request.query的别名)就可以获得提交过来的数据,post请求的话这是通过body来获取,所以通常我们会通过猜想,以为ctx.body也是ctx.request.body的别名,其实- -这个是不对的。因为我们不仅要接受数据,最重要还要响应数据给前端,所以ctx.body是ctx.response.body的别名。而ctx.request.body为了区分,是没有设置别名的,即只能通过ctx.request.body获取post提交过来的数据。
总结:ctx.body是ctx.response.body的别名,而ctx.request.body是post提交过来的数据
Koa 中间件
Koa 的最大特色,也是最重要的一个设计,就是中间件(middleware)。Koa 应用程序是一个包含一组中间件函数的对象,它是按照类似堆栈的方式组织和执行的。Koa 中使用 app.use()用来加载中间件,基本上 Koa 所有的功能都是通过中间件实现的。每个中间件默认接受两个参数,第一个参数是 Context 对象,第二个参数是 next 函数。只要调用 next 函数,就可以把执行权转交给下一个中间件。
下面两张图很清晰的表明了一个请求是如何经过中间件最后生成响应的,这种模式中开发和使用中间件都是非常方便的:
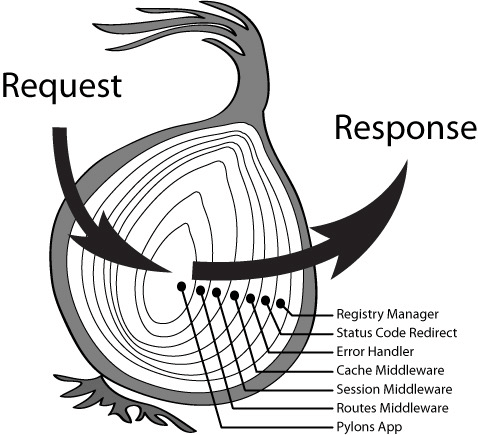
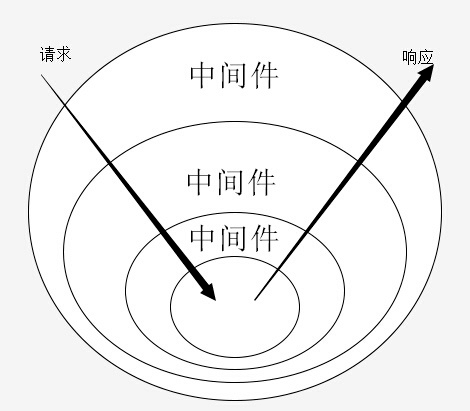
再来看下 Koa 的洋葱模型实例代码:
const Koa = require("koa");
const app = new Koa();
app.use(async (ctx, next) => {
console.log(1);
await next();
console.log(6);
});
app.use(async (ctx, next) => {
console.log(2);
await next();
console.log(5);
});
app.use(async (ctx, next) => {
console.log(3);
await next();
console.log(4);
});
app.listen(8000);
怎么样,是不是有一点点感觉了。当程序运行到 await next()的时候就会暂停当前程序,进入下一个中间件,处理完之后才会回过头来继续处理。
理解完这些后就可以开始写我们的代码啦!!! (lll ¬ ω ¬),好像写了好多和这次教程主题没关的东西,见怪莫怪啦
简单的搭建前端项目
既然说到了写界面,这里我们技术栈就采用vue吧,然后UI库的话,大家都用惯了ElementUI,我想大家都特别熟悉了,所以我们这里就采用Ant Design Vue吧,也方便大家对Antd熟悉一下,也没什么坏处
所以,我们就简单的创建一下我们的项目,在我们batch-modify-filenames文件夹下运行vue create batch-front-end,如图所示:

基本上都是无脑下一步,只不过是ant-design-vue用了less,我们为了符合它的写法,我们配置上也采用less。当然,采用sass也是可以的,没什么强制要求。
创建完项目后就是安装依赖了,因为其实我们用到的组件不多,所以这里我们使用按需加载,即需要安装babel-plugin-import,这里babel-plugin-import也是开发依赖,生产环境是不需要的,所以安装的时候需要-D
这里我们用到了一个常用的工具库(类库)—— lodash,我们不一定用到他所有的方法,所以我们也需要安装个babel插件进行按需加载,即babel-plugin-transform-imports,同样也是-D
最后,既然是与后端做交互,我们肯定需要用到一个http库啦,既然官方推荐我们用axios,所以这里我们也要把axios装上,不过axios不是vue的插件,所以不能直接用use方法。所以,这里我为了方便,也把vue-axios装上了。在之后,因为我又不想把最终的zip文件留在服务器上,毕竟会占用空间,所以我以流(Stream)的方式返回给前端,让前端自己下载,那么这里我就采用一个成熟第三方库实现,也就是file-saver,所以最终我们的依赖项就是:
npm install ant-design-vue lodash axios vue-axios file-saver -S
npm install babel-plugin-import babel-plugin-transform-imports -D
配置babel.config.js:
module.exports = {
presets: ["@vue/cli-plugin-babel/preset"],
plugins: [
[
"import",
{ libraryName: "ant-design-vue", libraryDirectory: "es", style: true },
], // `style: true` 会加载 less 文件,
[
"transform-imports",
{
lodash: {
transform: "lodash/${member}",
preventFullImport: true,
},
},
],
],
};
因为我们这里改成了style: true,按需引入的时候大概会报下面的这个错误:
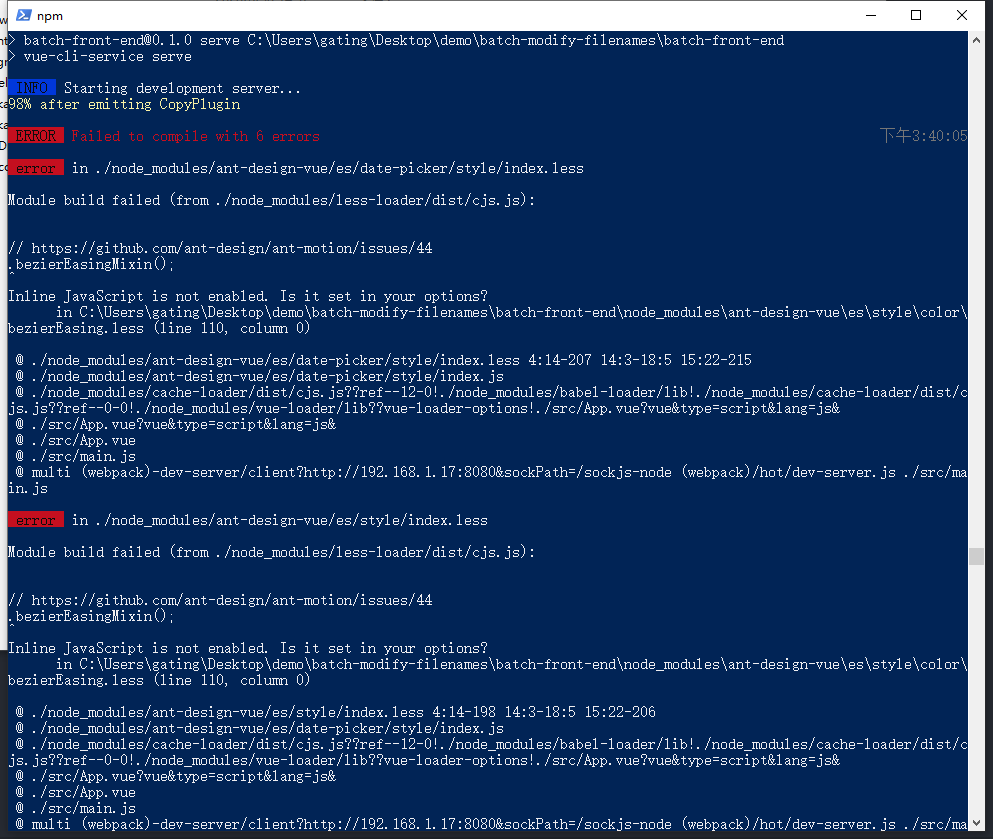
解决方案这里也说的很清楚了,在https://github.com/ant-design/ant-motion/issues/44这个链接,也有说明Inline JavaScript is not enabled. Is it set in your options?,告诉我们less没开启JavaScript功能,我们需要修改下 lless-loader的配置即可
因为vue-cli4的webpack不像vue-cli2.x,他对外屏蔽了webpack的细节,如果像修改必须创建vue.config.js来修改配置,所以我们创建一个vue.config.js文件,书写下面配置:
module.exports = {
css: {
loaderOptions: {
less: {
javascriptEnabled: true,
},
},
},
};
关掉服务,在重新跑一下npm run serve,看是不是没有报错了?这样子我就可以书写我们的代码了。
编写布局

界面大概长这样子,我想大家写界面应该比我厉害多了,都是直接套用Antd的组件,所以这里我主要分析我们怎么拆分这个页面的组件比较好,怎么定义我们的数据比较好~~
从这个图我们可以看出新文件列表是基于原文件列表+各种设置得出来的,所以新文件列表我们就可以采用计算属性(computed)来实现啦,那么接下来就是拆分我们页面的时候啦。。。
ps:这里我不会详细讲怎么写界面,只会把我觉得对开发有用的讲出来,不然文章就太多冗长了。虽然现在也十分冗长了(;′д `)ゞ
拆分页面
其实从页面的分割线我们大概就可以看出,他是分成 3 个大的子组件了,还有文件列表可以单独划分为孙子组件,所以基本上如图所示:
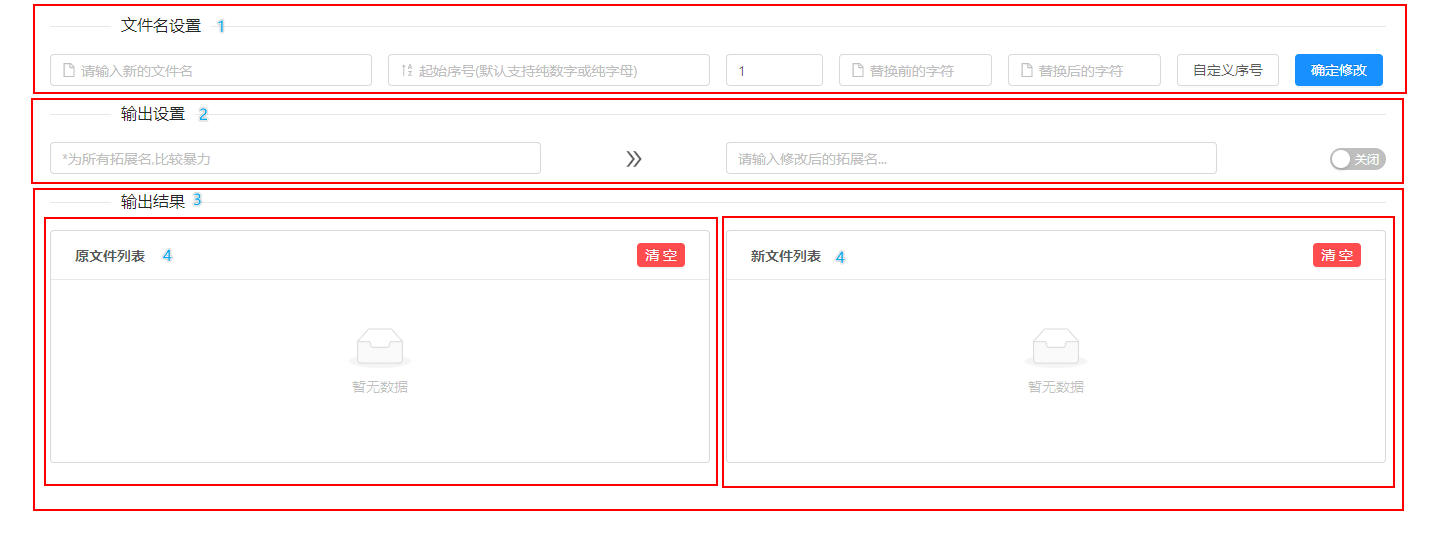
代码结构如图:
|-- batch-front-end
├─.browserslistrc
├─.eslintrc.js
├─.gitignore
├─babel.config.js
├─package-lock.json
├─package.json
├─README.md
├─vue.config.js
├─src
| ├─App.vue
| ├─main.js
| ├─utils
| | ├─helpers.js
| | ├─index.js
| | └regexp.js
| ├─components
| | ├─ModifyFilename2.vue
| | ├─ModifyFilename
| | | ├─FileList.vue
| | | ├─FileListItem.vue
| | | ├─FileOutput.vue
| | | ├─FileSetting.vue
| | | └index.vue
| ├─assets
| | └logo.png
├─public
| ├─favicon.ico
| └index.html
看到这里,基本知道我是怎么拆分的吧?没错,一共用了四个组件分别是FileSetting(文件名设置)、FileOutput(输出设置)、FileList(输出结果)和FileListItem(列表组件)这么四大块
当然知道怎么拆分了还远远不够的,虽然现在我们只有 4 个组件,所以写起来问题不是那么的大,但是呢。。。写起页面来其实也是比较麻烦的,一般正常的写法是:
文件名设置
输出设置
输出结果
import { Divider } from "ant-design-vue";
import FileList from "./FileList";
import FileOutput from "./FileOutput";
import FileSetting from "./FileSetting";
export default {
name: "ModifyFilename",
components: {
Divider,
FileList,
FileOutput,
FileSetting,
},
computed: {
// 新文件列表
newFiles() {
return this.oldFiles;
},
},
data() {
return {
// 存放这文件名设置的数据
fileSettings: {},
// 存放自定义序号数组
diyForm: {},
// 启用输出设置
enable: false,
// 输出设置后缀名
ext: [],
// 原文件列表
oldFiles: [],
};
},
};
.content {
width: 1366px;
box-sizing: border-box;
padding: 0 15px;
margin: 0 auto;
overflow-x: hidden;
}
思考一下
但是有没有发现,我们写了三个divider组件,要绑定的数据也是相当之多,虽然我都整合在fileSettings了。如果我们要单独拿出来的话,岂不是要累死个人?所以我们思考一下,怎么可以更加方便的书写我们的这个页面。所以我引申出了下面三个问题:
有没有办法可以用一个组件来标识我们导入的另外三个子组件呢?
有没有办法一次性绑定我们要的数据,而不是一个个的绑定呢?
一次性绑定之后,组件间怎么通信呢(因为这里涵盖了子孙组件)?
针对于这三个问题,我分别使用了动态组件、v-bind和provide实现的,接下来我们就讲讲怎么实现它,先上代码:
{{ item.label }}
:is="item.name"
v-bind="{ ...getProps(item.props) }"
@update="
(key, val) => {
update(item.props, key, val);
}
"
/>
import getNewFileList from "@/utils/";
import { Divider } from "ant-design-vue";
import FileList from "./FileList";
import FileOutput from "./FileOutput";
import FileSetting from "./FileSetting";
export default {
name: "ModifyFilename",
components: {
Divider,
FileList,
FileOutput,
FileSetting,
},
// 传递给深层级子组件
provide() {
return {
parent: this,
};
},
data() {
return {
components: [
{
label: "文件名设置",
name: "FileSetting",
props: "fileSettingsProps",
},
{
label: "输出设置",
name: "FileOutput",
props: "fileOutputProps",
},
{
label: "输出结果",
name: "FileList",
props: "fileListProps",
},
],
fileSettingsProps: {
fileSettings: {
filename: {
value: "",
span: 6,
type: "file",
placeholder: "请输入新的文件名",
},
serialNum: {
value: "",
span: 6,
type: "sort-descending",
placeholder: "起始序号(默认支持纯数字或纯字母)",
},
increment: {
value: 1,
span: 2,
placeholder: "增量",
isNum: true,
},
preReplaceWord: {
value: "",
span: 3,
type: "file",
placeholder: "替换前的字符",
},
replaceWord: {
value: "",
span: 3,
type: "file",
placeholder: "替换后的字符",
},
},
diyForm: {
diySerial: "",
separator: "",
diyEnable: false,
},
},
fileOutputProps: {
enable: false,
ext: ["", ""],
},
oldFiles: [],
};
},
computed: {
newFiles() {
const { fileSettings, diyForm } = this.fileSettingsProps;
const { ext, enable } = this.fileOutputProps;
const { diySerial, separator, diyEnable } = diyForm;
return getNewFileList(
this.oldFiles,
fileSettings,
ext,
enable,
this.getRange(diySerial, separator, diyEnable)
);
},
},
watch: {
"fileSettingsProps.diyForm.diySerial"(val) {
if (!val) {
this.fileSettingsProps.diyForm.diyEnable = !1;
}
},
},
methods: {
getRange(diySerial, separator, enable) {
if (!enable) return null;
!separator ? (separator = ",") : null;
return diySerial.split(separator);
},
getProps(key) {
if (key === "fileListProps") {
return {
oldFiles: this.oldFiles,
newFiles: this.newFiles,
};
}
return this[key] || {};
},
update(props, key, val) {
if (props === "fileListProps") {
return (this[key] = val);
}
this[props][key] = val;
},
},
};
.content {
width: 1366px;
box-sizing: border-box;
padding: 0 15px;
margin: 0 auto;
overflow-x: hidden;
}
代码里,我通过component的is来标识我们导入的组件,这样就解决了我们的第一个问题。第二个问题,从文档可知,v-bind是可以绑定多个属性值,所以我们直接通过v-bind就可以实现了。
】
但是,解决第二个问题后,就引发了第三个问题,因为通常我们可以通过.sync修饰符来进行props的双向绑定,但是文档有说,在解析一个复杂表达式的时是无法正常工作的,所以我们无法通过this.$emit(‘update:props‘,newVal)更新我们的值。
所以这里我自定义了一个update方法,通过props的方式传递给子组件,通过子组件触发父组件的方法实现状态的更新。当然,也通过provide把自身传递下去共子组件使用,这里提供FileListItem(列表组件)的代码供大家参考:
{{ filename }}
清空
{{ item.name }}
{{ item.name }}
ghost
type="danger"
size="small"
@click="
() => {
delCurrent(index);
}
"
>
删除
import { List, Button, Tooltip } from "ant-design-vue";
const { Item } = List;
export default {
name: "FileListItem",
props: {
fileList: {
type: Array,
required: true,
},
filename: {
type: String,
required: true,
},
pagination: {
type: Object,
default: () => ({
pageSize: 10,
showQuickJumper: true,
hideOnSinglePage: true,
}),
},
},
inject: ["parent"],
components: {
"a-list": List,
"a-list-item": Item,
"a-list-item-meta": Item.Meta,
"a-button": Button,
"a-tooltip": Tooltip,
},
methods: {
delCurrent(current) {
this.parent.oldFiles.splice(current, 1);
},
clearFiles() {
this.parent.update("fileListProps", "oldFiles", []);
},
drop(e) {
e.preventDefault();
this.parent.update("fileListProps", "oldFiles", [
...this.parent.oldFiles,
...e.dataTransfer.files,
]);
},
},
mounted() {
let $el = this.$refs.list.$el;
this.$el = $el;
if ($el) {
$el.ondragenter = $el.ondragover = $el.ondragleave = () => false;
$el.addEventListener("drop", this.drop, false);
}
},
destroyed() {
this.$el && this.$el.removeEventListener("drop", this.drop, false);
},
};
.list-header {
display: flex;
justify-content: space-between;
align-items: center;
}
这里我们看到,可以直接调用父组件身上的方法来进行数据的更新(当然这里也可以用splice更新数据),这样也就解决了我们之前的三个问题啦。
react,react可是很常用扩展运算符传属性的哦,虽然是jsx都可以 ?? 但是我们通过v-bind也可以绑定复杂属性,知识点哦(●‘?‘●)
Antd 的坑

因为我自定义序号采用的事弹窗,又因为我们采用的是按需加载,在ant-design-vue@1.6.2版本中会报Failed to resolve directive: ant-portal无法解析指令的错误,所以我们需要在main.js中全局注册他,然后因为我们请求可能会用message,所以我顺便也把message放到vue的原型链上了,即:
import Vue from "vue";
import App from "./App.vue";
import { Message, Modal } from "ant-design-vue";
import axios from "axios";
import VueAxios from "vue-axios";
Vue.config.productionTip = false;
Vue.use(VueAxios, axios);
// Failed to resolve directive: ant-portal
// https://github.com/vueComponent/ant-design-vue/issues/2261
Vue.use(Modal);
Vue.prototype.$message = Message;
new Vue({
render: (h) => h(App),
}).$mount("#app");
这样子就可以愉快的使用我们的Modal了,然后到了组件选型上了,一开始我选的组件时Form组件,但是写着写着发现我们有个自定义序号和是否启用自定义相关联,而且Form组件如果时必选的话,只能通过v-decorator指令的rules实现绑定数据和必选,不能通过v-model进行数据的双向绑定(不能偷懒)。
因为我们的ant-design-vue版本已经是1.5.0+,而FormModel组件也支持支持v-model检验,那么就更符合我们的需求啦,所以我这里改了下我的代码,使用FormModel组件实现我们的需求了:
title="自定义序号"
:visible="serialNumVisible"
@cancel="serialNumVisible = !1"
@ok="handleDiySerialNum"
>
ref="diyForm"
:model="diyForm"
:rules="rules"
labelAlign="left"
:label-col="{ span: 6 }"
:wrapper-col="{ span: 18 }"
>
v-model="diyForm.diySerial"
placeholder="请输入自定义序号"
aria-placeholder="请输入自定义序号"
/>
v-model="diyForm.separator"
placeholder="请输入自定义序号分隔符(默认,)"
aria-placeholder="请输入自定义序号分隔符"
/>
ps:果然,懒人还是推动技术进步的最主要的动力啊 ??
post 请求下载文件
因为我之前说过,我们后端不想保留返回的zip文件,所以我们是以流(Stream)传递个前端的,那我们怎么实现在个功能呢?
其实,还是挺简单的。主要是后端设置两个请求头,分别是Content-Type和Content-Disposition,一个告诉浏览器是什么类型,一个是告诉要以附件的形式下载,并指明默认文件名。
Content-Type我想大家都很常见了把,而且也不用我们处理了,所以这里我们讲讲再怎么处理Content-Disposition,即获取默认的文件名,如图所示:

从图可以看出,响应头信息为content-disposition: attachment; filename="files.zip"。看到这个字符串,我们第一眼可以能机会想到通过split方法分割=然后下标取1就可以获取文件名了。但是发现了吗?我们获取的文件名是"files.zip",与我们想要的结果不同,虽然我们可以通过切割来实现获取到files.zip,但是假设有一天服务器返回的不带"就不通用了。
那怎么办呢?没错啦,就是通过正则并搭配字符串的replace方法来获取啦~~当然,正则不是本篇的重点,所以就不讲正则怎么写了,接下来书写我们的方法:
// 获取content-disposition响应头的默认文件名
const getFileName = (str) => str.replace(/^.*filename="?([^"]+)"?.*$/, "$1");
const str = `content-disposition: attachment; filename=files.zip`;
const doubleStr = `content-disposition: attachment; filename="files.zip"`;
console.log(getFileName(str)); // files.zip
console.log(getFileName(doubleStr)); // files.zip
看输出的是不是和预期的一样?如果一样,这里就实现了我们的获取用户名的方法了,主要用到的就是正则和replace的特殊变量名
ps:不知道repalce的搞基(高级)用法的请看请点击我,这里就不阐述啦
当然,写到这里其实如果是get请求,那么浏览器会默认就下载文件了,我们也不用获取文件名。但是我们是post请求,所以我们需要处理这一些列的东西,并且期待responseType是blob类型,所以我们就写一下前端怎么请求后端并下载文件的。
既然要写前端代码,那么就要先和后端约定接口是什么,这里因为后端也是自己写的,所以我们暂且把接口定义为http://localhost:3000/upload,又因为我们这里vue的端口在8080,肯定会和我们的后端跨域,所以我们需要在vue.config.js,配置一下我们的代理,即:
module.exports = {
// 静态资源导入的路径
publicPath: "./",
// 输出目录,因为这里我们Node设置本上级public为静态服务
// 实际设置成koa-static设置batch-front-end/dist为静态目录的话就不要修改了
// 具体看自己变通
outputDir: "../public",
// 生产环境下不输出.map文件
productionSourceMap: false,
devServer: {
// 自动打开浏览器
open: true,
// 配置代理
proxy: {
"/upload": {
target: "http://localhost:3000",
// 发送请求头中host会设置成target
changeOrigin: true,
// 路径重写
pathRewrite: {
"^/upload": "/upload",
},
},
},
},
css: {
loaderOptions: {
less: {
javascriptEnabled: true,
},
},
},
};
这样子我们就可以跨域请求我们的接口啦,既然说到了下载文件,我们就简单看下file-saver是怎么使用的,从官方实例来看:
import { saveAs } from "file-saver";
const blob = new Blob(["Hello, world!"], { type: "text/plain;charset=utf-8" });
saveAs(blob, "hello world.txt");
从示例来看,它可以直接保存blob,并指定文件名为hello world.txt,知道这个之后我们就可以书写我们的代码啦:
import { saveAs } from "file-saver";
this.axios({
method: "post",
url: "/upload",
data,
// 重要,告诉浏览器响应的类型为blob
responseType: "blob",
})
.then((res) => {
const disposition = res.headers["content-disposition"];
// 转换为Blob对象
let file = new Blob([res.data], {
type: "application/zip",
});
// 下载文件
saveAs(file, getFileName(disposition));
this.$message.success("修改成功");
})
.catch(() => {
this.$message.error("发生错误");
});
基本下,这样就可以实现下载文件啦,下面是FileSetting.vue源码,仅供参考:
:key="key"
:span="setting.span"
v-for="(setting, key) in fileSettings"
>
style="width:100%"
:placeholder="setting.placeholder"
:min="1"
v-model="setting.value"
/>
:placeholder="setting.placeholder"
v-model="setting.value"
allowClear
>
slot="prefix"
:type="setting.type"
style="color:rgba(0,0,0,.25)"
/>
自定义序号
确定修改
title="自定义序号"
:visible="serialNumVisible"
@cancel="serialNumVisible = !1"
@ok="handleDiySerialNum"
>
ref="diyForm"
:model="diyForm"
:rules="rules"
labelAlign="left"
:label-col="{ span: 6 }"
:wrapper-col="{ span: 18 }"
>
v-model="diyForm.diySerial"
placeholder="请输入自定义序号"
aria-placeholder="请输入自定义序号"
/>
v-model="diyForm.separator"
placeholder="请输入自定义序号分隔符(默认,)"
aria-placeholder="请输入自定义序号分隔符"
/>
import {
Row as ARow,
Col as ACol,
Icon as AIcon,
Input as AInput,
Switch as ASwitch,
Button as AButton,
InputNumber as AInputNumber,
FormModel as AFormModel,
} from "ant-design-vue";
import { saveAs } from "file-saver";
// 是否符合默认序号规范
import { isDefaultSerialNum } from "@/utils/regexp";
const AFormModelItem = AFormModel.Item;
// 获取content-disposition响应头的默认文件名
const getFileName = (str) => str.replace(/^.*filename="?([^"]+)"?.*$/, "$1");
export default {
name: "FileSetting",
props: {
fileSettings: {
type: Object,
required: true,
},
diyForm: {
type: Object,
required: true,
},
},
components: {
ARow,
ACol,
AIcon,
AInput,
ASwitch,
AButton,
AInputNumber,
AFormModel,
AFormModelItem,
},
inject: ["parent"],
// 没有自定义序号时不可操作
computed: {
disabled() {
return !this.diyForm.diySerial;
},
},
data() {
return {
serialNumVisible: !1,
rules: {
diySerial: [
{
required: true,
message: "请输入自定义序号",
trigger: "blur",
},
],
},
};
},
methods: {
handleModify() {
// 获取填写的序号
const serialNum = this.fileSettings.serialNum.value;
// 当没有启用自定义时,走默认规则
if (isDefaultSerialNum(serialNum) && !this.diyForm.enable) {
return this.$message.error("请输入正确的序号,格式为纯数字或纯字母");
}
const { newFiles, oldFiles } = this.parent;
const data = new FormData();
for (let i = 0; i < oldFiles.length; i++) {
const { name } = newFiles[i];
data.append("files", oldFiles[i]);
data.append("name", name);
}
this.axios({
method: "post",
url: "/upload",
data,
responseType: "blob",
})
.then((res) => {
const disposition = res.headers["content-disposition"];
// 转换为Blob对象
let file = new Blob([res.data], {
type: "application/zip",
});
// 下载文件
saveAs(file, getFileName(disposition));
this.$message.success("修改成功");
})
.catch(() => {
this.$message.error("发生错误");
});
},
handleDiySerialNum() {
this.$refs.diyForm.validate((valid) => {
if (!valid) {
return false;
}
this.serialNumVisible = !1;
});
},
},
};
至此,和后端交互的逻辑基本上已经写完了,但是- -我们好像还没有写前端页面的实际逻辑,那么接下来就开始写前端逻辑啦,可能比较啰嗦- -So Sorry??
ps:webpack 是开发解决跨域问题,线上该跨域还是要跨域,最好的方法是cors或者proxy,再不然就是放在node的静态服务里。
书写前端逻辑
从之前的图来看,很显然我们的逻辑就是处理新文件列表这个数据,而这个数据则是根据页面其他组件的值来实现的,所以我们之前用了计算属性来实现,但是我们逻辑却还没写,所以接下来就是处理这个最重要的逻辑啦。
不过好像写好了界面,却还没有说,我想实现什么东西,所以简单的说一下我们界面的交互,我们再开始写逻辑吧。
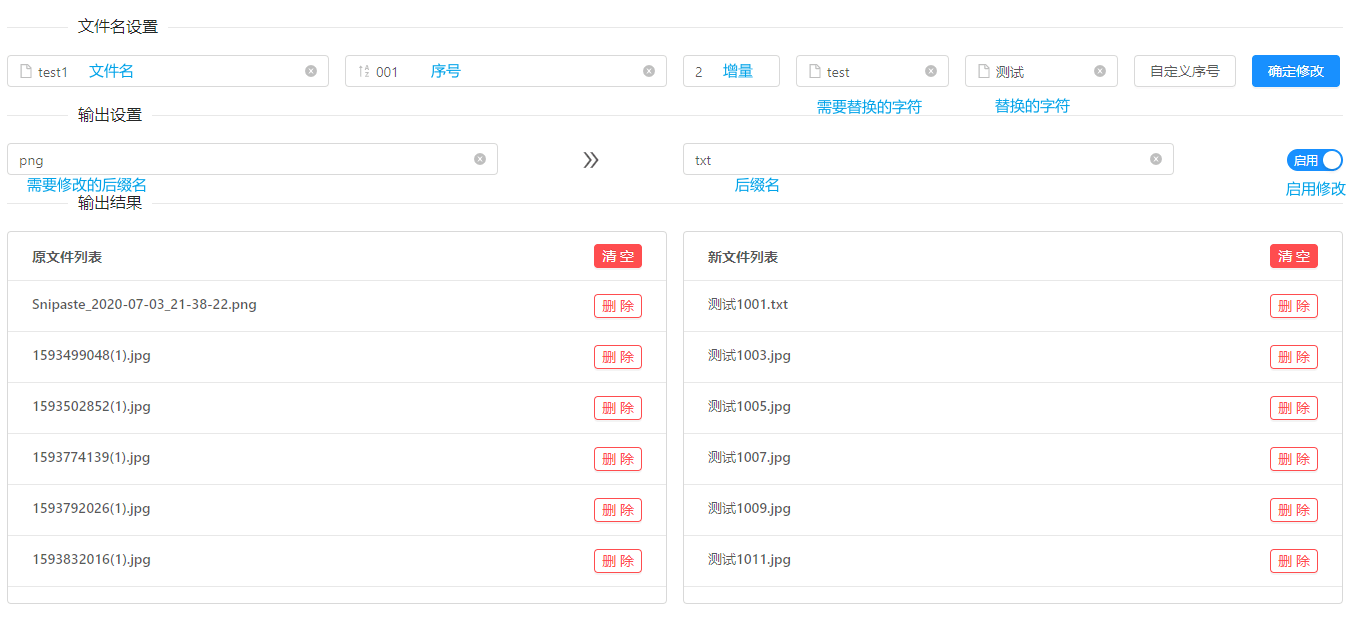
通过图片,我们大概可以知道有这些操作:
我们可以通过输入文件名,批量修改所有的文件名
通过序号,让文件名后面添加后缀,默认支持纯数字和纯字母,即输入test1+001则输出test1001
通过增量,我们可以让文件的后缀加上增量的值,即加设增量为 2,这里的下一个就是test1+00(1+2),为test1003
通过输入需要替换的字符-test和替换的字符-测试,把所有文件的名称修改替换为为测试1+001,即测试1001
通过输入需要修改的后缀名-png和替换的字符-txt并打开修改开关,把所有符合png后缀名的都修改为txt,因为这里只有一个,所以修改为测试1001.txt,即test1001.png->测试1001.png->测试1001.txt
而启用自定义序号之后,还有后续操作,如图所示:
输入g,a,t,i,n,g这个自定义序号化时,我们的序号的值就应该为["g", "a", "t", "i", "n", "g"]中的一个
当我们序号为g且增量为2时,第一个文件的后缀为g,第二个为t,以为g为列表的第一个,那么他下一个的就为1+2,即列表的第三个,也就是t
纯字母分小写和大写,所以这里我们也需要处理一下
文件名+后缀名不能为.,因为在 pc 上是创建不了文件的
知道这 9 点后,我们就可以开始写我们的代码啦。其实主要分为几大块:
文件名的处理
后缀名的处理
自定义序号的处理
思考一下
还记得我们之前的目录结构吗?里面有一个utils(工具库)的文件夹,我们就在这里书写我们的方法。
先思考一下,我们这些都是针对字符串的,那么什么和字符串最合适呢?肯定是正则啦。
首先当然是书写我们常用的正则啦,主要有那么几个:
获取文件名和拓展名
判断是不是空字符串,为空不处理
文件名+后缀名不能是.
在没有自定义序号的情况下,是否符合纯字母这种情况,主要用于区分纯数字和纯字母这两种情况
是否符合默认序号规范(纯数字或者纯字母)
在utils/regexp.js中写上:
// 匹配文件名和拓展名
export const extReg = /(.+)(\..+)$/;
// 是否为空字符串
export const isEmpty = /^\s*$/;
/**
* 整个文件名+后缀名不能是 .
* @param { string }} str 文件名
*/
export const testDot = (str) => /^\s*\.+\s*$/.test(str);
/**
* 序号是否为字母
* @param { string }} str 序号
*/
export const testWord = (str) => /^[a-zA-Z]+$/.test(str);
/**
* 是否符合默认序号规范
* @param { string } str 序号
* @return { object } 返回是否符合默认序号规范(纯字母/纯数字)
*/
export const isDefaultSerialNum = (str) =>
!/(^\d+$)|(^[a-zA-Z]+$)/.test(str) && !isEmpty.test(str);
书写完正则后,就到了我们的utis/helpers.js帮助函数了,帮助函数主要有三个,分别做了三件事:
判断首字母是不是大写,用于区分a和A,因为a和A序号输出的内容完全不同
计算默认情况中字母序号和自定义序号的实际值
用于转换默认情况中字母序号和自定义序号的值
针对第一点,其实大家应该都知道怎么写了把,也比较简单,我们直接通过正则就好了:
/**
* 判断是不是大写字母
* @param { string } word => 字母
* @return { boolean } 返回是否大写字母
*/
export const isUpper = (word) => {
return /^[A-Z]$/.test(word[0]);
};
2、3点的话,可能会觉得比较拗口,也比较难理解。不怕,我举个例子你就理解了。
假设我们是默认是输入的是纯字母的情况,如果输入a,那么输出是不是就是1,即是第一个字母;输入z,则是26。又因为我们最后得到的字符串,所以我们需要把26这个值转换成z,其实就是反着来。
乍一看,是不是很像26进制转10进制?对的,没错,其实就是26进制转换成10进制。那么我们怎么转换呢?
然后我们也说过,要把字母先转成实际的值,在转换成十进制在进行上面的操作。
那么怎么计算十进制的值呢?比如baa转成十进制是多少?它的运算规则是这样的baa = 26**2*2 + 26**1*1 + 26**0*1,即1379,知道规则之后,我们就可以写出以下的计算代码,
// 创建一个连续的整数数组
import { range } from "lodash";
// 创建一个[0-25]的数组,并转换为[A-Z]数组供默认字母序号使用
let convertArr = range(26).map((i) => String.fromCharCode(65 + i));
const serialNum = "baa",
complement = serialNum.length;
/**
* 计算第n位26进制数的十进制值
* @param {*} range => 26进制数组
* @param {*} val => 当前值
* @param {*} idx => 当前的位置
* @returns { number } 第n位26进制数的十进制值
*/
const calculate = (range, val, idx) => {
let word = range.indexOf(val.toLocaleUpperCase());
return word === -1 ? 0 : (word + 1) * 26 ** idx;
};
const sum = [...serialNum].reduce(
(res, val, idx) => res + calculate(convertArr, val, complement - 1 - idx),
0
);
console.log(sum); // 1379
这样子就计算好了我们的值,接下来就是对这个值进行转换为字母了。因为我们不是从 0 开始,而是从 1 开始,所以每一位的时候我们只需要前的位进行减 1 操作即可。
ps: 不知道**幂运算符的,建议看看 es7,比如26 ** 3,它相当于 Math.pow(26,3),即26 * 26 * 26
// 创建一个连续的整数数组
import { range } from "lodash";
// 创建一个[0-25]的数组,并转换为[A-Z]数组供默认字母序号使用
let convertArr = range(26).map((i) => String.fromCharCode(65 + i));
/**
* 26进制转换
* @param { number } num => 转换的值
* @param { array } range => 转换的编码
* @return { string } 返回转换后的字符串
*/
const convert = (num, range) => {
let word = "",
len = range.length;
while (num > 0) {
num--;
word = range[num % len] + word;
// ~~位运算取整
num = ~~(num / len);
}
return word;
};
console.log(convert(1379, convertArr)); // BAA
所以最终的utils/helpers.js文件代码如下:
/**
* 判断是不是大写字母
* @param { string } word => 字母
* @return { boolean } 返回是否大写字母
*/
export const isUpper = (word) => {
return /^[A-Z]$/.test(word[0]);
};
/**
* 进制转换
* @param { number } num => 转换的值
* @param { array } range => 转换的编码
* @return { string } 返回转换后的字符串
*/
export const convert = (num, range) => {
// 没有range的时候即为数字,数字我们不需要处理
if (!range) return num;
let word = "",
len = range.length;
while (num > 0) {
num--;
word = range[num % len] + word;
num = ~~(num / len);
}
return word;
};
/**
* 计算第n位进制数的十进制值
* @param {*} range => 进制数组
* @param {*} val => 当前值
* @param {*} idx => 当前的位置
* @returns { number } 第n位进制数的十进制值
*/
export const calculate = (range, val, idx) => {
let word = range.indexOf(val);
const len = range.length;
return word === -1 ? 0 : (word + 1) * len ** idx;
};
这里我把range作为参数传过来我想大家应该能理解吧?因为其实自定义序号和默认的字母序号的处理是一样,所以这里我们直接传入range就可以处理自定义和纯字母这种情况了。
无非就是n进制转十进制的操作,计算规则也同理。。。
不过写到这里,可能要骂我了- -这不就是把baa转为1379,然后再把1379转回BAA,压根就没有做什么操作啊?━━( ̄ー ̄*|||━━
小傻瓜,其实不是的,这里我们只是用一个baa作为演示,假设我们有多个文件,不就是需要它实际的值+增量来计算了吗,大概就是:
// 伪代码...
function getNewFileList(fileList, serialNum, increment, range) {
// 起始序号
let start = [...serialNum].reduce(
(res, val, idx) => res + calculate(convertArr, val, complement - 1 - idx),
0
);
return fileList.map((file) => {
// 得出后缀
const suffer = convert(start, range);
// 根据increment增量自增
start += increment;
return {
...file,
name: file.name + suffer,
};
});
}
到这里,我们基本上对序号处理已经完成了,剩下来就是比较简单的了,也就是对文件名和后缀名进行处理。还记得我们之前定义的正则,接下来我们就是使用它的时候了。
处理文件名和后缀名
先书写我们觉得比较容易处理的方法,比如获取文件和文件后缀名和根据指定字符替换文件名,在utils/index.js文件书写如下代码:
import { extReg } from "./regexp";
/**
* 获取文件和文件后缀名
* @param { string } filename 原始文件名
* @return { array } 返回的文件和文件后缀名
*/
const splitFilename = (filename) =>
filename.replace(extReg, "$1,$2").split(",");
/**
* 替换文件名
* @param { string } filename 文件名
* @param { string } preReplaceWord 需要替换的字符
* @param { string } replaceWord 替换的字符
* @return { string } 返回替换后的文件名
*/
const replaceFilename = (filename, preReplaceWord, replaceWord) =>
filename.replace(preReplaceWord, replaceWord);
还记得我们之前我们的fileSettings这个配置吗?他有很多一个对象,而我们只需要获取到这对象下的value值,但是一个个解构赋值比较麻烦,所以我们也可以写一个方法在获取到它的value值在结构赋值,即:
/**
* 获取文件名设置
* @param { Object } fileSettings 文件名设置
*/
const getFileSetting = (fileSettings) =>
Object.values(fileSettings).map((setting) => setting.value);
const fileSettings = {
filename: {
value: "test",
},
serialNum: {
value: "aaa",
},
};
const [filename, serialNum] = getFileSetting(fileSettings);
console.log(filename, serialNum); // test aaa
这样子就能很方便的解构赋值了,再然后就是根据输入的后缀名获得新的后缀名,这里有个有个暴力的配置,所以单独拿出来讲讲。
因为我们需要对*这个字符串进行全局的替换,同时也需要对后缀名,比如png;或者点+后缀名,比如.png。这两种情况处理。所以代码是:
import { startsWith } from "lodash";
/**
* 根据输入的后缀名,获取修改文件名的的后缀名
* @param { array } fileExt => 文件后缀名数组
* @return { array } [oldExt, newExt] => 返回文件的后缀名
*/
const getFileExt = (fileExt) =>
// 如果 i 不存在,返回""
// 如果 i 是以 "." 开头的返回i,即‘.png‘返回‘.png‘
// 如果 i === "*" 的返回i,即‘*‘返回‘*‘
// 如果是 i 是 ‘png‘,则返回 ‘.png‘
fileExt.map((i) =>
i ? (startsWith(i, ".") || i === "*" ? i : "." + i) : ""
);
ps:提一点,如果不知道startsWith这个方法的,建议阅读字符串的方法的总结和使用,当然我这里用的是lodash的startsWith,但实际上一样的
这里代码翻译成中文就是:
如果后缀名不存在,返回""(空字符串)
如果后缀名是以.开头的返回后缀名,即.png返回.png
如果后缀名是* 的返回*,即*返回*
如果是后缀名不是以.开头的返回png,则返回.png
写完获取后缀名之后就是修改啦,这里单独拿出来谈主要也是因为有个小坑,因为有些文件比较奇葩,他是.+名字,比如我们常常见到的.gitignore文件
所以我们需要针对这种.+名字这类型的文件进行一个区分,即没有后缀名的文件的处理:
/**
* 获取修改后的后缀名
* @param { string } fileExt => 匹配的文件后缀名
* @param { string } oldExt => 所有文件后缀名
* @param { string } newExt => 修改后文件后缀名
* @param { boolean } enable => 是否启用修改后缀名
* @return { string } 返回修改后的后缀名
*/
const getNewFileExt = (fileExt, oldExt, newExt, enable) => {
if ((oldExt === "*" || fileExt === oldExt) && enable) {
return newExt;
} else {
// 避免没有后缀名的bug,比如 .gitignore
return fileExt || "";
}
};
写到这里,基本上逻辑要写完了,但是还有一个最最最小的问题,就是他可能会输入001,而我们之前的代码会把001转为数字,即会直接转为1。这不是我们想要的,那么我们怎么让他还是字符串形式,但是还是按照数字计算呢?
ps:因为转换值需要+增量,不可能用字符串相加的,所以必须转成数字
所以这里就要需要用到es6的padStart方法啦,通过他来进行序号的补位,然后把之前的方法整理下,定义为getOptions函数,获取通用的配置:
import { range, padStart } from "lodash";
import { testWord } from "./regexp";
import { calculate, isUpper } from "./helpers";
let convertArr = range(26).map((i) => String.fromCharCode(65 + i));
/**
* 获取起始位置、补位字符和自定义数组
* @param { string } serialNum 文件序号
* @param { number } complement 需要补的位数
* @param { array } range 自定义序号数组
* @return { object } 返回起始位置、补位字符和自定义数组
*/
const getOptions = (serialNum, complement, range) => {
// 起始序号的值,补位序号
let start, padNum;
// 字母和自定义序号的情况
if (testWord(serialNum) || range) {
if (!range) {
// 转换大小写
if (!isUpper(serialNum[0])) {
convertArr = convertArr.map((str) => str.toLocaleLowerCase());
}
range = convertArr;
}
// 补位字符
padNum = range[0];
start = [...serialNum].reduce(
(res, val, idx) => res + calculate(range, val, complement - 1 - idx),
0
);
} else {
// 纯数字的情况
start = serialNum ? ~~serialNum : NaN;
// 补位字符
padNum = "0";
}
return {
start,
padNum,
convertArr: range,
};
};
let { start, padNum } = getOptions("001", 3);
console.log(padStart(convert(start) + "", 3, padNum)); // 001
如果不知道padStart这个方法的,建议阅读字符串的方法的总结和使用,当然我这里用的是lodash的padStart,但实际上一样的
写好这一对方法之后,我们就可以实现刚刚那个伪代码了,而我们最终vue里面也就需要这一个方法,所以直接导出就行了。
utils/index.js最终代码如下:
import {
extReg,
testWord,
isDefaultSerialNum,
isEmpty,
testDot,
} from "./regexp";
import { calculate, isUpper, convert } from "./helpers";
import { range, padStart, startsWith } from "lodash";
// 创建一个[0-25]的数组,并转换为[A-Z]数组供默认字母序号使用
let convertArr = range(26).map((i) => String.fromCharCode(65 + i));
/**
* 获取修改后的后缀名
* @param { string } fileExt => 匹配的文件后缀名
* @param { string } oldExt => 所有文件后缀名
* @param { string } newExt => 修改后文件后缀名
* @param { boolean } enable => 是否启用修改后缀名
* @return { string } 返回修改后的后缀名
*/
const getNewFileExt = (fileExt, oldExt, newExt, enable) => {
if ((oldExt === "*" || fileExt === oldExt) && enable) {
return newExt;
} else {
// 避免没有后缀名的bug
return fileExt || "";
}
};
/**
* 根据输入的后缀名,获取修改文件名的的后缀名
* @param { array } fileExt => 文件后缀名数组
* @return { array } [oldExt, newExt] => 返回文件的后缀名
*/
const getFileExt = (fileExt) =>
// 如果 i 不存在,返回""
// 如果 i 是以 "." 开头的返回i,即‘.png‘返回‘.png‘
// 如果 i === "*" 的返回i,即‘*‘返回‘*‘
// 如果是 i 是 ‘png‘,则返回 ‘.png‘
fileExt.map((i) =>
i ? (startsWith(i, ".") || i === "*" ? i : "." + i) : ""
);
/**
* 获取文件和文件后缀名
* @param { string } filename 原始文件名
* @return { array } 返回的文件和文件后缀名
*/
const splitFilename = (filename) =>
filename.replace(extReg, "$1,$2").split(",");
/**
* 替换文件名
* @param { string } filename 文件名
* @param { string } preReplaceWord 需要替换的字符
* @param { string } replaceWord 替换的字符
* @return { string } 返回替换后的文件名
*/
const replaceFilename = (filename, preReplaceWord, replaceWord) =>
filename.replace(preReplaceWord, replaceWord);
/**
* 获取文件名设置
* @param { Object } fileSettings 文件名设置
*/
const getFileSetting = (fileSettings) =>
Object.values(fileSettings).map((setting) => setting.value);
/**
* 获取起始位置、补位字符和自定义数组
* @param { string } serialNum 文件序号
* @param { number } complement 需要补的位数
* @param { array } range 自定义序号数组
* @return { object } 返回起始位置、补位字符和自定义数组
*/
const getOptions = (serialNum, complement, range) => {
// 起始序号的值,补位序号
let start, padNum;
// 字母和自定义序号的情况
if (testWord(serialNum) || range) {
if (!range) {
// 转换大小写
if (!isUpper(serialNum[0])) {
convertArr = convertArr.map((str) => str.toLocaleLowerCase());
}
range = convertArr;
}
// 补位字符
padNum = range[0];
start = [...serialNum].reduce(
(res, val, idx) => res + calculate(range, val, complement - 1 - idx),
0
);
} else {
// 纯数字的情况
start = serialNum ? ~~serialNum : NaN;
// 补位字符
padNum = "0";
}
return {
start,
padNum,
convertArr: range,
};
};
/**
* 获取文件名
* @param { string } filename 旧文件名
* @param { string } newFilename 新文件名
* @return { string } 返回最终的文件名
*/
const getFileName = (filename, newFilename) =>
isEmpty.test(newFilename) ? filename : newFilename;
/**
* 根据配置,获取修改后的文件名
* @param { array } fileList 原文件
* @param { object } fileSettings 文件名设置
* @param { array } extArr 修改的后缀名
* @param { boolean } enable 是否启用修改后缀名
* @return { array } 修改后的文件名
*/
export default function getNewFileList(
fileList,
fileSettings,
extArr,
enable,
range
) {
const [
newFilename,
serialNum,
increment,
preReplaceWord,
replaceWord,
] = getFileSetting(fileSettings);
// 如果不符合默认序号规则,则不改名
if (isDefaultSerialNum(serialNum) && !range) {
return fileList;
}
// 获取文件修改的后缀名
const [oldExt, newExt] = getFileExt(extArr);
// 补位,比如输入的是001 补位就是00
const padLen = serialNum.length;
// 获取开始
let { start, padNum, convertArr } = getOptions(serialNum, padLen, range);
return fileList.map((item) => {
// 获取文件名和后缀名
let [oldFileName, fileExt] = splitFilename(item.name);
// 获取修改后的文件名
let filename = replaceFilename(
getFileName(oldFileName, newFilename),
preReplaceWord,
replaceWord
);
// 获取修改后的后缀名
fileExt = getNewFileExt(fileExt, oldExt, newExt, enable);
const suffix =
(padLen && padStart(convert(start, convertArr) + "", padLen, padNum)) ||
"";
filename += suffix;
start += increment;
// 文件名+后缀名不能是.
let name = testDot(filename + fileExt) ? item.name : filename + fileExt;
return {
...item,
basename: filename,
name,
ext: fileExt,
};
});
}
看到这里,你会发现,我多数方法只做一件事,通常也建议只做一件事(单一职责原则),这样有利于降低代码复杂度和降低维护成本。希望大家也能养成这样的好习惯哦~~ ??
ps:函数应该做一件事,做好这件事,只做这一件事。 —代码整洁之道
优化相关
预加载(preload)和预处理(prefetch)
preload与prefetch不同的地方就是它专注于当前的页面,并以高优先级加载资源,prefetch专注于下一个页面将要加载的资源并以低优先级加载。同时也要注意preload并不会阻塞window的onload事件。
即preload加载资源一般是当前页面需要的, prefetch一般是其它页面有可能用到的资源。
明白这点后,就是在vue.config.js写我们的配置了:
module.exports = {
// ...一堆之前配置
chainWebpack(config) {
// 建议打开预加载,它可以提高第一屏的速度
config.plugin("preload").tap(() => [
{
rel: "preload",
// to ignore runtime.js
// https://github.com/vuejs/vue-cli/blob/dev/packages/@vue/cli-service/lib/config/app.js#L171
fileBlacklist: [/\.map$/, /hot-update\.js$/, /runtime\..*\.js$/],
include: "initial",
},
]);
// 去除预读取,因为如果页面过多,会造成无意义的请求
config.plugins.delete("prefetch");
},
};
ps:优化网站性能的 pre 家族还有dns-prefetch、prerender和preconnect,有兴趣的可以进一步了解
提取 runtime.js
因为打包生成的runtime.js非常的小,但这个文件又经常会改变,它的http耗时远大于它的执行时间了,所以建议不要将它单独拆包,而是将它内联到我们的index.html之中,那么则需要使用到script-ext-html-webpack-plugin这个插件,我们安装一下,同样是开发依赖-D:
npm i script-ext-html-webpack-plugin -D
接下来就是在vue.config.js写我们的配置了:
const isProduction = process.env.NODE_ENV !== "development";
module.exports = {
// ...一堆之前配置
chainWebpack(config) {
// 只在生成环境使用
config.when(isProduction, (config) => {
// html-webpack-plugin的增强功能
// 打包生成的 runtime.js非常的小,但这个文件又经常会改变,它的 http 耗时远大于它的执行时间了,所以建议不要将它单独拆包,而是将它内联到我们的 index.html 之中
// inline 的name 和你 runtimeChunk 的 name保持一致
config
.plugin("ScriptExtHtmlWebpackPlugin")
.after("html")
.use("script-ext-html-webpack-plugin", [
{
inline: /runtime\..*\.js$/,
},
])
.end();
// 单独打包runtime
config.optimization.runtimeChunk("single");
},
};
对第三方库进行拆包
实际上默认我们会讲所有的第三方包打包在一个文件上,这样的方式可行吗?实际上肯定是有问题的,因为将第三方库一块打包,只要有一个库我们升级或者引入一个新库,这个文件就会变动,那么这个文件的变动性会很高,并不适合长期缓存,还有一点,我们要提高首页加载速度,第一要务是减少首页加载依赖的代码量,所以我们需要第三方库进行拆包。
module.exports = {
publicPath: "./",
outputDir: "../public",
productionSourceMap: false,
devServer: {
open: true,
proxy: {
"/upload": {
target: "http://localhost:3000",
changeOrigin: true,
pathRewrite: {
"^/upload": "/upload",
},
},
},
},
css: {
loaderOptions: {
less: {
javascriptEnabled: true,
},
},
},
chainWebpack(config) {
// 拆分模块
config.optimization.splitChunks({
chunks: "all",
cacheGroups: {
libs: {
name: "chunk-libs", // 输出名字
test: /[\\/]node_modules[\\/]/, // 匹配目录
priority: 10, // 优先级
chunks: "initial", // 从入口模块进行拆分
},
antDesign: {
name: "chunk-antd", // 将antd拆分为单个包
priority: 20, // 权重需要大于libs和app,否则将打包成libs或app
test: /[\\/]node_modules[\\/]_?ant-design-vue(.*)/, // 为了适应cnpm
},
commons: {
name: "chunk-commons",
test: resolve("src/components"),
minChunks: 3,
priority: 5,
reuseExistingChunk: true, // 复用其他chunk内已拥有的模块
},
},
});
});
},
};
其他优化
当然其实还有很多的优化方式,我们这里没有提及,比如:
(伪)服务端渲染,通过prerender-spa-plugin在本地模拟浏览器环境,预先执行我们的打包文件,这样通过解析就可以获取首屏的 HTML,在正常环境中,我们就可以返回预先解析好的 HTML 了。
FMP(首次有意义绘制),通过vue-skeleton-webpack-plugin制作一份Skeleton骨架屏
使用cdn
其它等等...
编写后端
最后,到了编写后端了,为了符合MVC的开发模式,这里我们创建了controllers文件夹处理我们的业务逻辑,具体目录结构如下:
|-- batch-modify-filenames
├─batch-front-end # 前端页面
├─utils # 工具库
| └index.js
├─uploads # 存放用户上传的文件
├─routes # 后端路由(接口)
| ├─index.js # 路由入口文件
| └upload.js # 上传接口路由
├─controllers # 接口控制器,处理据具体操作
| └upload.js # 上传接口控制器
├─package.json # 依赖文件
├─package-lock.json # 依赖文件版本锁
├─app.js # 启动文件
因为这次我们的后端只有一个接口,而koa-router的使用也十分简单,所以我只会讲我觉得相对有用的东西 (;′д `)ゞ(因为再讲下去,篇幅就太长了)
路由的使用
koa-router使用非常简单,我们在routes/upload.js书写如下代码:
// 导入控制器
const { upload } = require("../controllers/upload");
// 导入路由
const Router = require("koa-router");
// 设置路由前缀为 upload
const router = new Router({
prefix: "/upload",
});
// post请求,请求地址为 ip + 前缀 + ‘/‘,即‘/upload/‘
router.post("/", upload);
// 导出路由
module.exports = router;
这样子就是写了一个接口了,你可以先upload理解为一个空方法,什么都不知,只返回请求成功,即ctx.body="请求成功"
上文中间件那里有说,upload的第一个参数为上下文,不理解的翻阅前面内容。
为了方便以后我们导入接口,而不需要每个route都调用一次app.use(route.routes()).use(route.allowedMethods()),我在routes/index.js(即入口文件),书写了一个方法,让他可以自动引入除index.js的其他文件,之后我们只需要新建接口文件就可以而不需要我们手动导入了,代码如下:
const { resolve } = require("path");
// 用于获取文件
const glob = require("glob");
module.exports = (app) => {
// 获取当前文件夹下的所有文件,除了自己
glob.sync(resolve(__dirname, "!(index).js")).forEach((item) => {
// 添加路由
const route = require(item);
app.use(route.routes()).use(route.allowedMethods());
});
};
文件上传
为啥使用 koa-body 而不是 koa-bodyparser?
因为koa-bodyparser不支持文件上传,想要文件上传还必须安装koa-multer,所以我们这里直接使用koa-body一劳永逸。
文件上传优化
很显然,我们上传的文件都在uploads目录下,如果日积月累,这个目录文件会越来越多。但同一目录下文件数量过多的时候,就会影响文件读写性能,这样子是我们最不想看到的了。那么有没有什么方法可以优化这个问题呢?当然是有的,我们可以文件上传前的进行一些操作,比如根据日期创建文件夹,然后把文件保存在当前日期的文件夹下。
这样既可以保证性能,又不会导致文件夹的层次过深。而koa-body刚到又有提供onFileBegin这个函数来实现我们的需求,闲话不多说了,开始写代码吧
ps:不建议层次太深,如果层次过深也会影响性能的- -
为了更好的实现我们的需求,我们需要封装了两个基本的工具方法。
根据日期,生成文件夹名称
检查文件夹路径是否存在,如果不存在则创建文件夹
即utils/index.js代码如下:
const fs = require("fs");
const path = require("path");
/**
* 生成文件夹名称
*/
const getUploadDirName = () => {
const date = new Date();
let month = date.getMonth() + 1;
return `${date.getFullYear()}${month}${date.getDate()}`;
};
/**
* 确定目录是否存在, 如果不存在则创建目录
* @param {String} pathStr => 文件夹路径
*/
const confirmPath = (dirname) => {
if (!fs.existsSync(dirname)) {
if (confirmPath(path.dirname(dirname))) {
fs.mkdirSync(dirname);
return true;
}
}
return true;
};
module.exports = {
getUploadDirName,
confirmPath,
};
写完工具函数后,我们就可以处理我们的koa-body这个中间件啦,具体代码如下:
const Koa = require("koa");
// uuid,生成不重复的文件名
const { v4: uuid } = require("uuid");
// 工具函数
const { getUploadDirName, confirmPath } = require("./utils/");
const app = new Koa();
// 解析post请求,
const koaBody = require("koa-body");
// 处理post请求的中间件
app.use(
koaBody({
multipart: true, // 支持文件上传
formidable: {
maxFieldsSize: 10 * 1024 * 1024, // 设置上传文件大小最大限制,默认2M
keepExtensions: true, // 保持拓展名
uploadDir: resolve(__dirname, `uploads`),
// 文件上传前的一些设置操作
onFileBegin(name, file) {
// 生成文件夹
// 最终要保存到的文件夹目录
const dirName = getUploadDirName();
// 生成文件名
const fileName = uuid();
const dir = resolve(__dirname, `uploads/${dirName}`);
// 检查文件夹是否存在如果不存在则新建文件夹
confirmPath(dir);
// 重新覆盖 file.path 属性
file.path = join(dir, fileName);
// 便于后续中间件使用
// app.context.uploadPath = `${dirName}/${fileName}`;
},
},
})
);
ps: 针对于uuid的版本问题,建议看:UUID 是如何保证唯一性的?,这里我们使用的是v4版本,也是最常用的一个版本。。
文件下载
和之前讲的一样,后端只需要设置Content-Type和Content-Disposition这两个响应头就可以实现下载了。但是archiver这个库搭配Koa返回流给前端,确让我措手不及。
我参考了官方Express 这个例子,但是发现在Koa身上不顶用,于是我就- -一直翻issue,发现很多人和我有同样的问题,最后终于在stackoverflow找到了想要的答案。我们可以通过new Stream.PassThrough()创建一个双向流,让archiver通过pipe把数据流写入到双向流里,再通过Koa返回给前端即可,具体实现如下(controllers/upload.js):
// 压缩文件
const archiver = require("archiver");
const Stream = require("stream");
// 判断是否为数组,如果不是,则转为数组
const isArray = (arr) => {
if (!Array.isArray(arr)) {
arr = [arr];
}
return arr;
};
// 上传接口
exports.upload = async (ctx) => {
// 获取上传的文件
let { files } = ctx.request.files;
// 获取上传的文件名
let filenames = isArray(ctx.request.body.name);
// 将文件转为数组
files = isArray(files);
// 设置响应头,告诉浏览器我要下载的文件叫做files.zip
// attachment用于浏览器文件下载
ctx.attachment("files.zip");
// 设置响应头的类型
ctx.set({ "Content-Type": "application/zip" });
// 定义一个双向流
const stream = new Stream.PassThrough();
// 把流返回给前端
ctx.body = stream;
// 压缩成zip
const archive = archiver("zip", {
zlib: { level: 9 }, // Sets the compression level.
});
archive.pipe(stream);
for (let i = 0; i < files.length; i++) {
const path = files[i].path;
archive.file(path, { name: filenames[i] });
}
archive.finalize();
};
这个处理也特别简单,就是根据前端传过来的文件名,把文件重命名即可。最后我们整理一下,app.js的代码如下:
const { resolve, join } = require("path");
const Koa = require("koa");
// 解析post请求,
const koaBody = require("koa-body");
// 静态服务器
const serve = require("koa-static");
// uuid,生成不重复的文件名
const { v4: uuid } = require("uuid");
// 工具函数
const { getUploadDirName, confirmPath } = require("./utils/");
// 初始化路由
const initRoutes = require("./routes");
const app = new Koa();
// 处理post请求的中间件
app.use(
koaBody({
multipart: true, // 支持文件上传
formidable: {
maxFieldsSize: 10 * 1024 * 1024, // 设置上传文件大小最大限制,默认2M
keepExtensions: true, // 保持拓展名
uploadDir: resolve(__dirname, `uploads`),
// 文件上传前的一些设置操作
onFileBegin(name, file) {
// 最终要保存到的文件夹目录
const dirName = getUploadDirName();
const fileName = uuid();
const dir = resolve(__dirname, `uploads/${dirName}`);
// 检查文件夹是否存在如果不存在则新建文件夹
confirmPath(dir);
// 重新覆盖 file.path 属性
file.path = join(dir, fileName);
// 便于后续中间件使用
// app.context.uploadPath = `${dirName}/${fileName}`;
},
},
})
);
// 静态服务器
app.use(
serve(resolve(__dirname, "public"), {
maxage: 60 * 60 * 1000,
})
);
// 初始化路由
initRoutes(app);
app.listen(3000, () => {
console.log(`listen successd`);
console.log(`服务器运行于 http://localhost:${3000}`);
});
到这里,基本上本次本章就结束了。当然,其实我们前端界面还可以做的更加可控一点的,比如我可以修改新文件列表的某个文件,使他可以单独自定义而不根据我们的配置走,而根据用户输入的自定义名称走。不过,这个就留给各位当作小作业啦~~~
顺便提一嘴,因为我们是在浏览器上操作的,没有操作文件的权限,所以写起来会比较麻烦- -如果用Electron编写的话,就方便多了。??
最后
感谢各位观众老爷的观看 O(∩_∩)O 希望你能有所收获 ??