本文转载自IT之家
一直以来,x86 和 ARM 各自分占 PC 和移动市场的局面造成了一种“刻板印象”——x86 更适合高性能的应用场景,而 ARM 更适合低功耗领域,一旦一方入侵另一方的领地,就可以称之为“革命性突破”。因此,不少人将基于 ARM 的苹果 M1 视为“革命者”,并给予极大的褒奖。但事实真的如此吗?苹果 M1 是否存有过度炒作的嫌疑?围绕这一话题,外媒作者 Arne Verheyde 进行了全面而深入的解读。
在过去一两年中,苹果 Mac 的自研芯片转型,以及 ARM 在数据中心的一些胜利,引发了业界对 x86 和 ARM 的广泛争论 —— 其中,有不少观点认为,x86 注定会失败。
事实上,与大多数无法开箱即用的 ARM CPU 相比,x86 的软件生态系统(在 PC 和数据中心领域)庞大,拥有绝对的竞争优势;而且它是建立在 Intel 和 AMD 两家的支持之上,非并是 Intel 一家。
问题来了:几乎没有什么内在缺点的 x86,真的注定会失败吗?

近几个季度以来,苹果新款 Mac 在市场上的确表现良好,部分功劳是:基于台积电 5nm 工艺,苹果 M1 芯片的运行速度很快。但同样不可否认,远程办公的兴起和芯片的短缺也在苹果最新一代 Mac 的销售中起到了助推作用。
对苹果而言,或许最主要的收获在于,未来不再需要在其最高端 CPU 上向英特尔支付超过 60% 的毛利率。
此前,一些投资者,如 Ark Invest 或其他投资人,根据 x86 和 ARM 指令集之间的技术二分法发表了一些文章。本文将挑战这些文章所提出的观点:ARM 和 x86 只是指软件与 CPU 交流时必须使用的“语言”,最终性能还是取决于每个 CPU 的执行情况。
因此,对于投资者而言,ARM 与 x86 之间的争论是没有意义的。
本文的观点可概括为两个层面:
-
首先,苹果拥有世界一流的芯片工程团队,这毋庸置疑,这也是除了英特尔工艺制程延期之外,苹果 M1 芯片好评如潮唯一真正的原因 —— 但并非是因为它使用了 ARM 指令集。
-
其次,苹果 M1 的重要性被过分夸大了。苹果的营销所打造的热度远远超过该芯片能够做出的保证;例如最新 iPad 的 M1 芯片也可以被称为 A14X,因为芯片本身带来的创新相对不多。
ARM VS x86:被弄错的重点
如上文所述,苹果 M1 引发了新一轮关于 x86 与 ARM 的讨论。对于包括 Ark Invest 和其他一些看好苹果的公司来说,苹果 M1 为结束 x86 时代提供了有力证据 —— 但这一讨论实际上并不新鲜,甚至有点过时。
简而言之,大约十年前,当英特尔错过移动业务时,完全相同的讨论持续了很长一段时间。很多人声称或认为 x86 生来就在功耗能效方面表现不佳,而在移动领域功耗极其重要,这意味着 x86 永远无法在移动领域竞争。
当时,“x86 功耗之谜”被 AnandTech 以及其他一些媒体平台彻底揭开,它们实际测量了基于 x86 架构芯片的功耗与能效,并撰写了题为《 破解 x86 功耗之谜》的文章 —— 值得注意的是,当时 AnandTech 的高级编辑 Anand Shimpi 自 2014 年以来一直在苹果工作。
实际上,x86 之所以没有在移动设备中得以广泛使用,其真正原因是英特尔和 AMD 并没有在该市场进行足够多投资。正如英特尔投资者如今可能意识到的那样,英特尔试图进入移动领域为时已晚,缺乏投资动力,便不再白费力气。
不过,英特尔在试图进入移动领域的过程中,也曾取得过一些成绩。比如说在 2014 年,英特尔计划基于更低功耗和更高能效的 Atom 架构打造 CPU 与高通等公司展开竞争,最终推出了面向无风扇设备(如平板电脑)的高性能架构 Core M。

以上基准测试中,Llama Mountain 是英特尔概念验证的(基于 Core M 的)极薄无风扇平板电脑,其运行速度几乎是苹果的 iPad Air 的 3 倍,而现如今被称之为具有革命性意义的 M1,也只比英特尔或 AMD 最新的 x86 芯片快 10% 左右。
这意味着,英特尔 Core M 彻底击败了苹果当时最好的芯片。这也可以被视为证明争论“x86 和 ARM,究竟谁更占优势?”这一问题毫无意义的另一个有力论据。
总之,这确实证明了任何芯片都不具有先天优势。基于 ARM 的 CPU 可以从微型微控制器发展到类似 M1 的芯片,而 x86 也可以从低功耗移动 CPU 发展到大型服务器芯片。
无论是 x86 还是 ARM,设计和制造都需要持续的研发,才能跟上时代的步伐。
x86 与 ARM,本质是语言种类的比较
读到这里,你可能对本文的观点和结论并不满意,因为上文并没有更详细地解释为什么 x86 与 ARM 的竞争比拼毫无意义,也没有解释英特尔是如何从比苹果快 3 倍发展到落后于苹果的。
不过不要着急,下面我们展开更加深刻的分析:
首先,让我们从指令集架构(如 x86、ARM 或 RISC-V)的基础知识开始,这应该有助于进一步理解为什么对于投资者来说 x86 和 ARM 的区别无关紧要。
简而言之,指令集定义了计算机可以执行的二进制机器指令,定义了软硬件接口 —— 计算机无法理解 C 语言或 Java 或 Python 语言,它只理解属于其指令集的指令。
这些指令从简单的基本数学计算指令(加法等)到更复杂的指令(如安全或虚拟化)。不过前者是关键指令 —— 几乎所有应用程序大部分时间都会使用基本数学指令。
这些基本指令对于任何芯片来说都是相同的,无论其基于何种架构。更重要的是,指令集只是定义了指令,它的作用只是定义一种机器语言,并没有定义这些指令如何在芯片中执行,最终是软件用这种机器语言来指示芯片执行指令。例如,有多种方法可以在芯片中实现加法器或乘法器等功能。
因此,在计算机体系结构中,必须做出两个区分:
-
指令集定义了芯片支持的所有指令。
-
芯片设计的第二部分是基于任何指令集的芯片架构实际运行的问题。在上面的实例中,执行指令涉及使用晶体管来创建一些有形的东西,比如加法器或乘法器。
过去 20 年,CPU 性能的进步主要归功于第二部分中流水线、乱序执行、分支预测器、多级缓存和许多其他技巧,大大提高了 CPU 的运行速度。
最重要的是,刚才提到的所有这些“技巧”相对指令集都是完全独立的,它们可以在 ARM、x86、RISC-V 或其他指令集中实现。
几十年前的软件无需重写就能在现代 CPU 上运行得更快,开箱即用 —— 这也是第二个区分的主要优点之一。
即使在新指令导致性能大幅提升的情况下,这些技巧也会简单地复制到其他指令集中。这方面的主要示例是向量指令或单指令流多数据流(SIMD),即在一组向量数据上使用一条指令。在 x86 中,这被称为数据流单指令多数据扩展(SSE,Streaming SIMD Extensions)和高级向量扩展指令集(AVX,Advanced Vector Extensions)。
例如,最新版本 AVX-512 在 512 位向量上运行,因此与之前的 AVX 版本(256 位)相比,性能提高了一倍。在 ARM 中,等效项称之为 SVE2,它可以在芯片运行中从 128 位扩展到 2048 位,这也再一次表明了芯片性能对指令执行的依赖程度。
因此,决定 CPU 速度以及功耗和能效等其他属性的,只是架构设计的选择,这实际上取决于芯片的应用目标 —— 这些选择属于前文中所提到的两个区别中的第二个,即独立于指令集的那些技巧。
例如,英特尔和 AMD 一直致力于确保它们的芯片达到 5GHz 量级的高频;如果苹果想要实现这一点,它可能需要完全重新设计其架构。
不过,苹果更专注于提高其 CPU 每个时钟周期可以执行的指令数量。这样,苹果的 3GHz 架构可能比 4GHz 的 AMD 或英特尔内核更快。由于功耗往往随电压频率成二次方甚至三次方地增加,因此这种设计选择让苹果芯片的性能和功耗备受赞誉。
但同样,这只是一个设计和创新的问题,正如所讨论的那样,设计与创新同指令集互补,甚至在很大程度上独立于指令集。
另一个例子是 big.Little 架构,也称之为混合架构,由同一指令集的两个(或多个)实现方式组成。其中一组内核主要针对性能进行了优化,另一组则倾向于针对功耗进行优化。指令集相同,但两种不同的实现方式导致两种微架构在功耗-性能曲线上有两个不同的点。
最后一点,可以用人类语言类比指令集。人类的语言种类繁多,但是语言仅用作底层概念的表示,原则上任何概念都能够用任何语言表达,如果没有对应的表述也可以自行添加。以此类推,CPU 语言即指令集种类繁多,但也只是用作基本数学的表示,任何基本数学都可以用任何指令集表示,这与对人类语言的理解是相通的。
性能方面,一部分人的语速可能比另一部分人的语速更快或更慢,但这并不是语言本身造成的 —— 类似地,某些 CPU 可能比另一些 CPU 更快或更慢(或耗电更多或更少),但这同样不是由于指令集,而是由于影响这些特性的架构设计选择造成的。
x86 强大的竞争优势
从上文提到的 x86 的反面来看,显然,外界对 x86 的“常识”是:往好里说,它是遗留下来的麻烦,往坏里说,它因为能效太低而劣势严重。
然而,我们完全忽略了基于 x86,英特尔对其架构体系的演进有绝对的控制权,这可以被称之为 x86 以及英特尔的强大竞争优势。因为行业中的其他企业都依赖于他人来定义自己所需要用到的架构,虽然这一情况在 x86 领域反过来也成立 ——AMD 的大多数芯片都必须跟随英特尔的变化而变化,而且 ARM 世界中的成员可能未来需要依赖英伟达(目前英伟达正在寻求收购 Arm)。
不过,RISC-V 是开源的,不属于某一家公司,因此不存在依赖与被依赖的关系。
最近,英特尔的两个动作说明了它可以多么轻松地向其 x86 架构添加新指令进行创新。首先,英特尔宣布了用于 AI 加速的下一代 AMX DLBoost,其性能将比当前的 AVX-512 高 4 至 8 倍。其次,英特尔公布了将近 76 条新指令,为当前的 AVX-512 提供附加功能。
芯片大神 Jim Keller:争论指令集是一件悲哀的事
为了让本文的观点更加具有说服力,我们可以看看这个行业中最受尊敬的人 —— 吉姆・凯勒 (Jim Keller) 最近在接受 AnandTech 采访时阐述的观点。
吉姆・凯勒曾在苹果、AMD 和英特尔工作过,显然他的立场更加中立。最近,吉姆・凯勒在 Tenstorrent 与 RISC-V 合作。
总结一下他提出的观点:尽管他认为 x86 在维护向后兼容性的遗留膨胀增加了一些复杂性,但他实际上也给出了一些 ARM 架构中遗留膨胀的例子。此外,这种复杂性主要体现在 CPU 的设计中,可能会给芯片开发人员带来一些麻烦,但不会严重影响最终的性能。值得注意的是,实际上只有少数指令负责执行大部分代码。
特别是,吉姆・凯勒毫不夸张地驳斥了去年年底一篇广为流传的媒体文章中反复提到的一个论点:与 ARM 的固定长度指令相比,x86 由于其可变长度指令而无法扩展到与 ARM 相同的性能。
事实上,吉姆・凯勒指出这些细节只会给芯片开发商带来一些麻烦,但不会对最终用户的整体芯片性能或功耗产生实质性影响。
最后,吉姆・凯勒还表示现在的 CPU 性能受到本文前面所描述的与指令集无关的问题(分支预测、缓存等功能)的限制,同时吉姆・凯勒还批评了英伟达使用其重新调整用途的 GPU 来处理 AI 的方法。
以下是吉姆・凯勒采访节选:
在指令集上做争论是一件非常悲哀的事情。它甚至不是几十个操作代码 ——80% 的核心执行只有 6 条指令 —— 加载、存储、加法、减法、比较和分支。这些几乎涵盖了所有。如果你使用 Perl 或其他语言编写代码,则“调用”和“返回”可能比“比较”和“分支”更重要。但是指令集的影响很小,你可能会因为丢失指令而损失 10% 或 20% 的性能。
有一段时间我们认为 X86 可变长度指令真的很难解码,但我们一直在想办法解决。我们基本上可以预测所有指令在表格中的位置,一旦有了好的预测器,就可以很好地预测这些内容。
因此,如果是打造小型计算机,固定长度的指令似乎是不错的选择,但是如果是要打造一台真正的大型计算机,要预测或找出所有指令的位置,固定长度的指令就不占优势,所以这没有那么重要。
苹果“过度炒作”M1
讨论到此为止,让我们回到苹果芯片本身,本文仍然没有完全解释,苹果是如何从“某种程度上落后于英特尔”到如今“或多或少地领先于英特尔”的(这里所谓的落后和领先,取决于如何比较)。
上面引用的 AnandTech 图片和文章已经解释了苹果与英特尔之间的故事,与其说苹果超越了英特尔,倒不如说是英特尔停滞不前,而苹果则保持着一年一度的更新节奏稳步前进。
英特尔为何停滞不前是一个悲伤的故事,至少对英特尔的粉丝和投资者而言如是。
简而言之,英特尔在制造方面遇到了一些问题,10nm 延期了三年多,然后 7nm 又延期了一年。正如 AMD 股东所知,英特尔的延期对其竞争对手非常有利。然而,正如新上任的英特尔 CEO Pat Gelsinger 所阐释的那样,随着 EUV 的相对成熟,英特尔已经完全接受了 EUV,并在未来几年重新走向工艺领先轨道,甚至更快地回到产品领先地位。
这或多或少解释了为什么说苹果 M1 是在过度炒作。
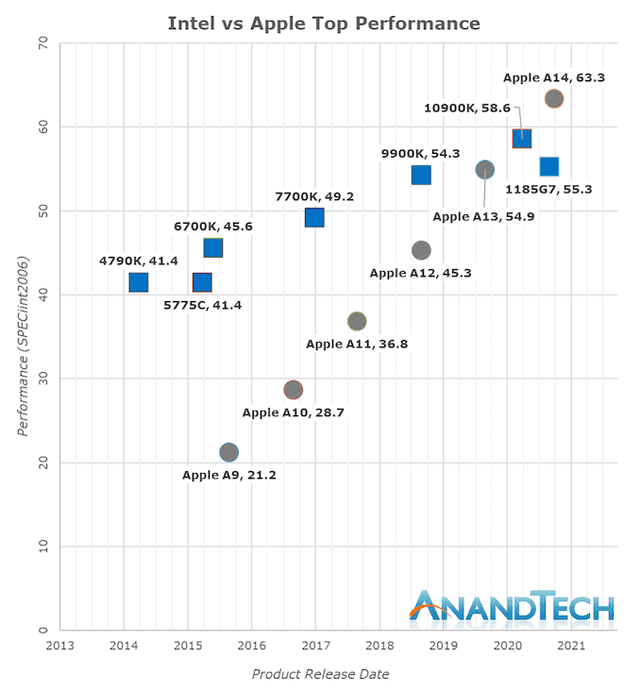
人们称赞苹果 M1,就好像它是自切片面包以来最好的科技产品 —— 但事实并非如此,这只是苹果之前芯片的进化产品。相关评估表明,在相同的时钟频率下,将一个 A14 内核与一个 A13 内核进行比较时,A14 的速度快了不到 10%,它也不比英特尔或 AMD 在市场的产品速度快多少。
因此,苹果在 M1 上并没有取得任何堪称非凡的成就。苹果也许根本不应该称它为 M1,因为这个名字表明这款芯片是全新的,或许 M14 更加贴切。换句话说,M1 芯片是具有两个更多高性能内核的 A14(从双核改进为四核)。
事实上,苹果最新的 iPad 使用的也是相同的 M1 芯片,一些观点忽视了 M1 只是带有两个额外内核的 A14,并且过度称赞那些使用 M1 的 iPad。
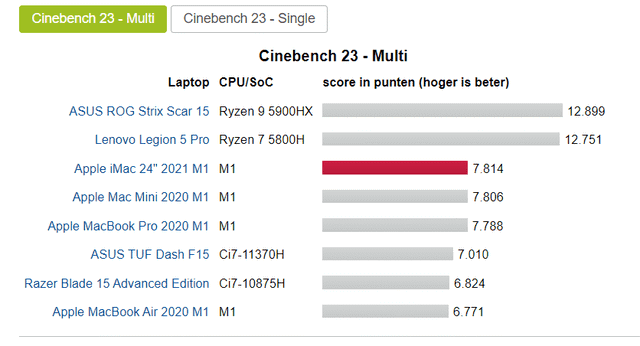
不过可以肯定的是,除了名称之外,该芯片本身确实运行速度快且功耗低,但这主要归功于文章开头所提到的那一点:世界一流的苹果开发团队选择了一种每时钟性能更高、频率更低的架构,然后结合台积电最新的 5nm 节点制造芯片。
为证实这一观点,可以观察上面的基准测试图,该芯片比英特尔最新的四核 Tiger Lake 芯片快一点。这可能是最恰当的比较,因为 M1 也有 4 个快核心。显然,就像英特尔一样,这意味着 M1 无法与速度更快的 8 核 AMD 芯片相匹敌。
值得注意的是,英特尔最近通过推出自己的 8 核 Tiger Lakes 赶上了 AMD。
在某些方面,这可能意味着苹果已经落后了。苹果需要其下一代 M2(又名 A15X)才能真正保持竞争力。
综上所述,苹果 M1 所取得的成绩不在于指令集的差异,部分原因的确是因为使用了台积电的 5nm。
添加更多的加速器是苹果的优势
尽管设计仍然非常重要,但有关 x86 与 Arm 的讨论也忽略了制造。假设苹果的 M1 采用 28nm 之类的制程制造,是否会有人认为 28nm M1 会比任何基于 7nm 工艺制程的 CPU(包括 x86)更节能。
同样,这篇文章提到的内容太多,我们只需要看 Arm 就够了。但实际上,与众多 7nm 芯片相比较,M1 和 A14 都是台积电最新 5nm 工艺的首批芯片。
此外,由于目标市场的差异,时钟速度的差异也起着重要作用 —— 英特尔或 AMD 不会突然向台式机市场推出 3GHz 芯片, 两家公司可能会继续进行一些不同的权衡以实现各自的目标。
虽然设计具有极高频率和每时钟高性能的芯片有点困难,但并非不可能。例如,英特尔的一篇研究论文提到,与 14nm Skylake 相比,它们的每时钟性能仅通过扩展其一些架构结构就实现了 2 倍以上的性能。这种扩展属于上文提到的 "技巧"。
除了研究论文之外,吉姆・凯勒本人也表示英特尔正致力于更大的 CPU。
最后,还有另一个常见的误解值得注意。在苹果的话语体系中 ,它有一个独特的优势 —— 控制着“完整的小部件”,因此它能够在其芯片上添加其他加速器,M1 不是英特尔和 AMD 等传统公司设计出来的 CPU,而是一个 SoC。
不过,查看英特尔最新的 Tiger Lake SoC 的框图(下图),就会发现 Tiger Lake 与 M1 一样是多加速器 SoC,这实际上也是去年技术分析师称赞 Tiger Lake 的亮点之一:
英特尔采用 CPU、GPU、NPU 和 ISP 的全新整体计算方法更像是智能手机而不是经典 PC,尤其是当你考虑该公司正在使用代号为 Lakefield 的混合 CPU 等产品时。这是一件好事。十多年来,PC 一直梦想有一个更加异构的计算环境,使得智能手机也能在其上运行。也许 Tiger Lake 和第 11 代酷睿才是开始。现在,我们需要更多利用所有 NPU、DSP 和 FPGA 的 PC 软件。
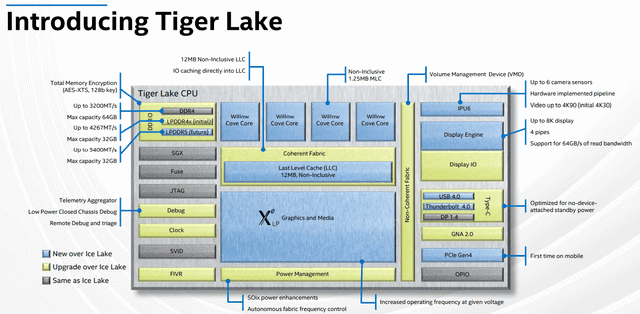
人们甚至可以尝试在 M1 中寻找不在 Tiger Lake 中的东西,很明显,这样的东西并不存在,它们都有 CPU、GPU、显示、I/O、图像处理、AI 加速、安全、媒体加速、音频、Wi-Fi、供电和管理控制器等。
唯一可以争论的点是,英特尔缺少一个 multi-tera-ops 专用 AI 加速器,不过英特尔选择通过集成其所谓的 DLBoost 来利用其 CPU 和 GPU,而不是神经引擎。因此,在 multi-tera-ops 方面,英特尔在 AI 能力方面实际上并不落后于苹果。
事实上,英特尔发现了一些真实世界的人工智能应用程序,在这些应用程序中,Tiger Lake 完全击败 M1—— 目前,英特尔的说法已经得到一些外媒证实。
关于这些基准,需要强调的是,无论它们是否是英特尔精心挑选的都并不重要,如果苹果 M1 在所有方面都出色,那么它应该在每项基准测试中都以较大优势获胜。事实并非如此,这一显而易见的事实证明 M1 被炒作夸大了:该芯片可能速度很快,但这一基准可能并不在英特尔基准测试的范围内。
写在后面
X86 永不过时。
正如 Pat Gelsinger 在重新加入英特尔担任 CEO 时所说的那样,因为有 1 万亿行代码针对 X86 进行了优化,而软件生态系统才是指令集真正的护城河。
当然,即使是软件生态系统也只能走到这一步,任何人都可以编写 Java 或其他代码,然后在 Arm 或 x86 CPU 上运行它们。
不少人认为,苹果的 Mac 销量是因为苹果 M1 芯片的推出而蓬勃发展。但是这一点值得怀疑,因为芯片短缺和远程办公热潮同时掀起,PC 整体迎来了有史以来最好的一年,该行业每天销售 100 万台个人电脑,大约十年或永远不会再看到这种情况。
尽管苹果的整体表现强劲,但苹果 M1 带来的任何额外需求都不能孤立存在,而且不是主要需求。
无论如何,对于一家本质上是售卖消费设备的公司来说,内部开发芯片可被视为真正的优势。在竞争方面,苹果与台积电(作为第一个 5nm 客户)的合作伙伴关系以及英特尔的许多延期带来了一些优势。
展望未来,相当激烈的竞争将继续或加剧 —— 例如英特尔已经号称在几年内重返工艺和产品领先地位,另外,在英特尔工艺延期之前,苹果实际上获取的相对于领先优势离 2-3 倍还差得远。
总之一句话:苹果没有赢,而 Intel 也没有输 ——x86 与 ARM 之间的大战仍在继续,并且将旷日持久地继续下去。