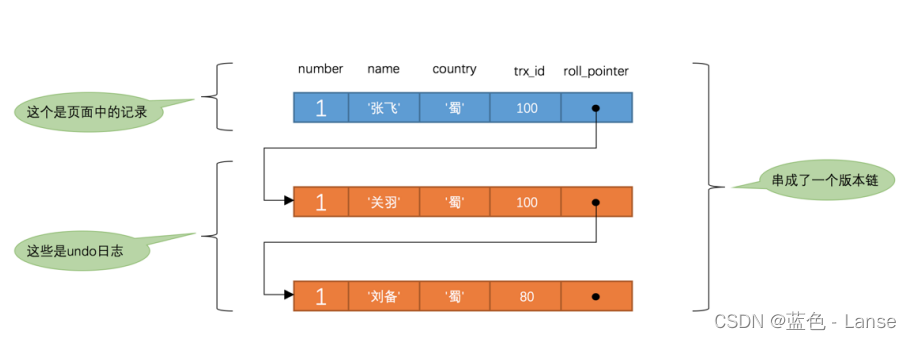
更多内容请查看 www.laowubiji.com
以下是一个简单的 PyCuda 示例程序。
import pycuda.driver as drv
import pycuda.autoinit
import numpy as np#设置GPU设备并获取当前设备信息
drv.init()
dev = drv.Device(0)
print('设备名称: ' + dev.name())
print('设备计算能力: ' + str(dev.compute_capability()))# 创建输入和输出数组
a = np.array([1, 2, 3, 4, 5, 6]).astype(np.float32)
b = np.array([1, 0, 1, 0, 1, 0]).astype(np.float32)
c = np.empty_like(a)#使用 CUDA 加速程序
from pycuda.compiler import SourceModule
mod = SourceModule("""__global__ void add(int n, float *a, float *b, float *c){int i = threadIdx.x;if (i<n) {c[i] = a[i] + b[i];}}""")
func = mod.get_function("add")# 执行 CUDA 函数
func(np.int32(len(a)), drv.In(a), drv.In(b), drv.Out(c), block=(len(a), 1, 1), grid=(1, 1))#输出结果
print("输入数据 a: " + str(a))
print("输入数据 b: " + str(b))
print("输出数据 c: " + str(c))该示例程序演示了如何使用 PyCuda 实现向量加法功能。在该示例程序中:
我们首先导入 PyCuda 相关的模块。
然后,我们使用 a 和 b 数组创建了一个空的输出数组 c。
接下来,我们使用 pycuda.compiler 模块的 SourceModule 函数创建了一个包含 CUDA 核函数的代码,这个核函数实现了向量加法的功能。
最后,我们调用 func 函数执行核函数,并使用 drv.In 和 drv.Out 函数将 a、b 和 c 传递给核函数。我们使用 block 和 grid 参数指定了内核的执行方式。
执行该示例程序后,将输出以下结果:
设备名称: Tesla P100-PCIE-16GB
设备计算能力: (6, 0)
输入数据 a: [1. 2. 3. 4. 5. 6.]
输入数据 b: [1. 0. 1. 0. 1. 0.]
输出数据 c: [2. 2. 4. 4. 6. 6.]这表明 c 数组的每个元素都是 a 数组和 b 数组中对应元素之和。