作者 | 杨阳
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/365662727
在深度学习时代,训练数据特别大的时候想要单卡完成训练基本是不可能的。所以就需要进行分布式深度学习。在此总结下个人近期的研究成果,欢迎大佬指正。
主要从以下几个方面进行总结:
分布式训练的基本原理
TensorFlow的分布式训练
PyTorch的分布式训练框架
Horovod分布式训练
1、分布式训练的基本原理
无论哪种机器学习框架,分布式训练的基本原理都是相同的。本文主要从 并行模式、架构模式、同步范式、物理架构、通信技术 等五个不同的角度来分类。
1.1 并行模式
分布式训练的目的在于将原本巨大的训练任务拆解开撑多个子任务,每个子任务在独立的机器上单独执行。大规模深度学习任务的难点在于:
训练数据巨大:这种情况我们需要将数据拆解成多个小模型分布到不同的node上
训练模型的参数巨大(NLP的预训练模型实在太大了):这种情况我们需要将数据集拆解分布到不同的node上。
前者我们称之为数据并行,后者我们称之为模型并行。
1.1.1 数据并行
数据并行相对简单, N个node(也称为worker)构成一个分布式集群,每个worker处理1/N的数据。理论情况下能达到线性的加速效果。TF、torch、Horovod都可以在原生支持或者微小的改动实现数据并行模式。
数据并行是在每个worker上存储一个模型的备份,在各个worker 上处理不同的数据子集。然后需要规约(reduce)每个worker的结果,在各节点之间同步模型参数。这一步会成为数据并行的瓶颈,因为如果worker很多的情况下,worker之间的数据传输会有很大的时间成本。参数同步后,需要采用不同的方法进行参数更新:
参数平均法
更新式方法
参数平均法是最简单的一种数据平均化。若采用参数平均法,训练的过程如下所示:基于模型的配置随机初始化网络模型参数
将当前这组参数分发到各个工作节点
在每个工作节点,用数据集的一部分数据进行训练
将各个工作节点的参数的均值作为全局参数值
若还有训练数据没有参与训练,则继续从第二步开始
更新式方法 与参数平均化类似,主要区别在于,在参数服务器和工作服务器之间传递参数时,更新式方法只传递更新信息(梯度和张量)。
1.1.2 模型并行
模型并行 相对复杂,原理是分布式系统中的不同worker负责网络模型的不同部分。
例如说,神经网络的不同层被分布到不同worker或者同一层的不同参数被分配到不同worker上。对于TF这种框架,可以拆分计算图成多个最小依赖子图到不同的worker上。同时在多个子图之间通过通信算子来实现模型并行。但是这种实验 起来比较复杂。工业界还是以数据并行为主。
Model Parallel主要分两种:intra-layer拆分 和inter-layer拆分
intranet-layer拆分 :深度学习的网络结构基本都是一层一层的。常规的卷积、池化、BN等等。如果对某一层进行了拆分,那么就是intra-layer拆分。对单层的拆分其实就是拆分这一层的matrix运算。参考论文: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
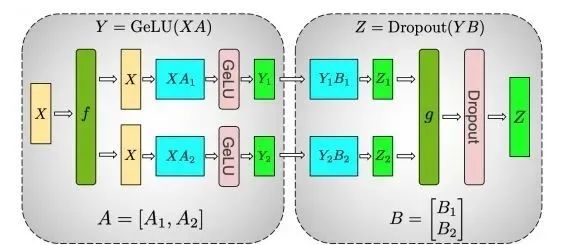
如上图,这两层的运算是 , ,matrix运算有一个重要的性质是矩阵运算可以分块运算。因此如上可以拆分成:
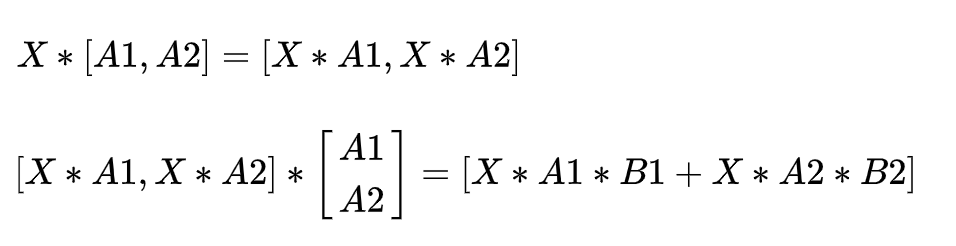
因此拆分为一个worker计算 ,一个worker计算 ,最后再累加两个worker的结果。这在一定程度上减少了模型对计算资源的需求。
inter-layer拆分 :这中更好理解,对模型做网络上的拆分。将每一层或者某几层放在一个worker上单独训练。这种拆分的问题在于,模型训练是串行的,整个模型的效率取决于最慢的那一层,存在资源浪费。参考论文: PipeDream: Fast and Efficient Pipeline Parallel DNN Training

但是随着训练设备的增加,多个worker之间的通信成本增加,模型Reduce的成本也越来越大,数据并行的瓶颈也随之出现。故有学者提出混合并行(数据并行+模型并行)。本人对此暂无研究,感兴趣可自行摸索,参考此链接[1]
强推这篇paper,DP(Data Parallel)、MP(MOdel Parallel)、PP(Pipeline Parallel)各个方面讲的很透彻: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
1.2 架构模式
分布式训练上会频繁的应用到规约(AllReduce)操作。主流的分布式架构主要分为 参数服务器(ParameterServer) 和 基于规约(Reduce) 两种模式。早期还有基于MPI的方式,不过现在已经很少用了。
ParameterServer模式是一种基于reduce和broadcat算法的经典架构。其中一个/一组机器作为PS架构的中心节点,用来存储参数和梯度。在更新梯度的时候,先全局reduce接受其他worker节点的数据,经过本地计算后(比如参数平均法),再broadcast回所有其他worker。PS架构的问题在于多个worker与ps通信,PS本身可能存在瓶颈。随着worker数量的增加,整体通信量也线性增加,加速比也可能停滞在某个点位上。
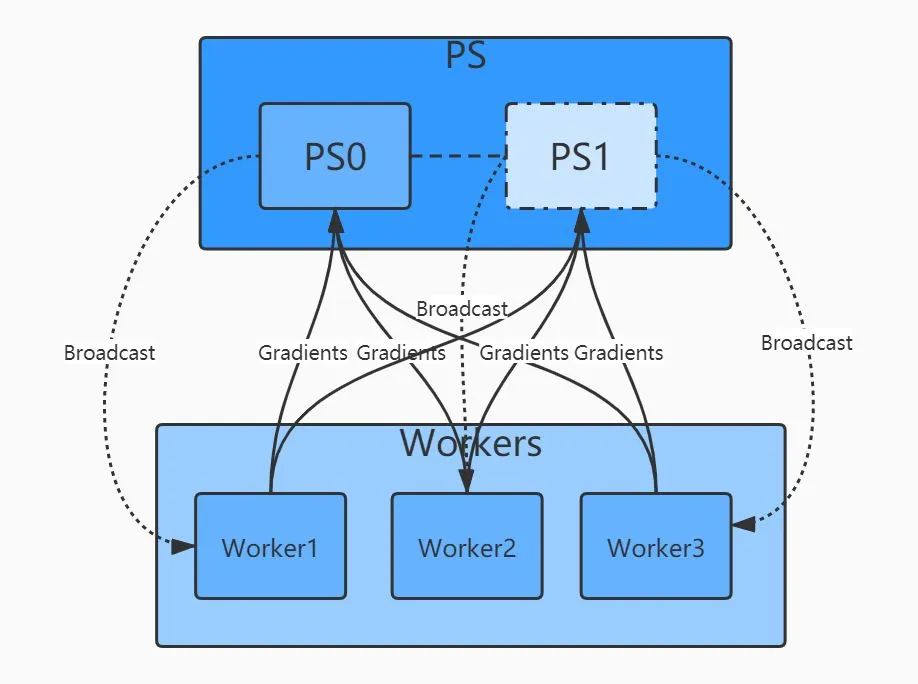
基于规约的模式解决了上述的问题,最典型的是百度提出的Ring-AllRuduce。多个Worker节点连接成一个环,每个Worker依次把自己的梯度同步给下一个Worker,经过至多2*(N-1)轮同步,就可以完成所有Worker的梯度更新。这种方式下所有节点的地位是平等的,因此不存在某个节点的负载瓶颈,随着Worker的增加,整体的通信量并不随着增加。加速比几乎可以跟机器数量成线性关系且不存在明显瓶颈。目前,越来越多的分布式训练采用Reduce这种模式。Horovod中主要就是用的这种分布式架构。
更多关于reduce的算法[2]可参照进一步学习
1.3 同步范式
在实际的训练过程中可能各种问题,比如:部分节点资源受限、卡顿、网络延时等等,因此再梯度同步时就存在“木桶”效应,即集群中的某些worker比其他worker更慢,导致整个训练pipeline需要等待慢的worker,整个集群的训练速度受限于最慢机器的速度。
因此梯度的同步有 同步(sync) 、 异步(Async) 和 混合 三种范式。
同步范式就是上述提到的,只有所有worker完成当前的计算任务,整个集群才会开始下一次迭代。(TF中同步范式使用SyncReplicasOptimizer优化器)
异步模式刚好相反,每个worker只关心知己的进程,完成计算后就尝试更新,能与其他多个worker同步梯度完成取决于各worker当前时刻的状态。其过程不可控,有可能出现模型正确性问题。(可在训练时logging对比)
混合范式结合以上两种情况,各个worker都会等待其他worker的完成,但不是永久等待,有timeout的机制。如果超时了,则此情况下相当于异步机制。并且没来得及完成计算的worker,其梯度则被标记为“stale”而抛弃或另做处理。
1.4 物理架构
物理架构主要是“GPU”架构,就是常说的(单机单卡、单机多卡、多机单卡、多机多卡)
单机单卡:常规操作
单机多卡:利用一台GPU上的多块GPU进行分布式训练。数据并行和模型并行皆可。整个训练过程一般只有一个进程,多GPU之间的通信通过多线程的方式,模型参数和梯度在进程内是共享的(基于NCCL的可能不大一样)。这种情况下基于Reduce的架构比PS架构更合适一些,因为不需要一个显式的PS,通过进程内的Reduce即可完成梯度同步。
多机单卡:操作上与多机多卡基本一致
多机多卡:多机多卡是最典型的分布式架构,所以它需要较好的进程间的通讯机制(多worker之间的通信)。
1.5 通信技术
分布式条件下的多进程、多worker之间的通信技术,常见的主要有:MPI、NCCL,GRPC等。
MPI主要是被应用在超算等大规模计算领域,机器学习场景下使用较少。主要是openMPI原语等。
NCCL是NVIDIA针对GPU设计的一种规约库,可以实现多GPU间的直接数据同步,避免内存和显存的,CPU和GPU间的数据拷贝成本。当在TensorFlow中选择单机多卡训练时,其默认采用的就是NCCL方式来通信。
GRPC是比较成熟的通信技术了,spark等框架内也都有用到。
这一部分暂无研究,有兴趣的大佬自行学习。
OK,讲完了理论部分,那就开始实践吧。
2、TensorFlow的分布式训练
TensorFlow主要的分布式训练的方法有三种:
Customer Train Loop
Estimator + Strategy
Keras + Strategy
在实际的开发工作中,分布式的工作最好是交给框架,而工程师本身只需要关注任务模型的pipeline就行了。最经典的是Spark框架,工程师只需要关注数据处理的workflow,分布式的大部分工作都交给框架。深度学习的开发同样如此。
第一种方式太过原生,整个分布式的训练过程完全交给工程师来处理,代码模块比较复杂,这里不做赘述。
第二种方式,Estimator是TF的一个高级API,在分布式场景下,其最大的特点是单机和分布式代码一致,且不需要考虑底层的硬件设施。在这里不多做介绍。Strategy是tensorflow根据分布式训练的复杂性,抽象出的多种分布式训练策略。TF1.x和TF2.x接口变化较大,不同版本名字可能不一样,以实际使用版本为准。用的比较多的是:
MirroredStrategy:适用于单机多卡、数据并行、同步更新的分布式训练,采用Reduce的更新范式,worker之间采用NCCL进行通信。
MultiWorkerMirroredStrategy:与上面的类似,不同的是这种策略支持多机多卡、数据并行、同步更新的分布式策略、Reduce范式。在TF 1.15版本里,这个策略叫CollectiveAllReduceStrategy。
ParameterServerStrategy:经典的PS架构,多机多卡、数据并行、同步/异步更新
使用Estimator+Strategy 实现分布式训练[3],参考代码
第三种方式 Keras + Strategy[4] 是Tensorflow最新官方推荐的方案。主要是利用keras的高级API,配合Strategy实现多模式的分布式训练。
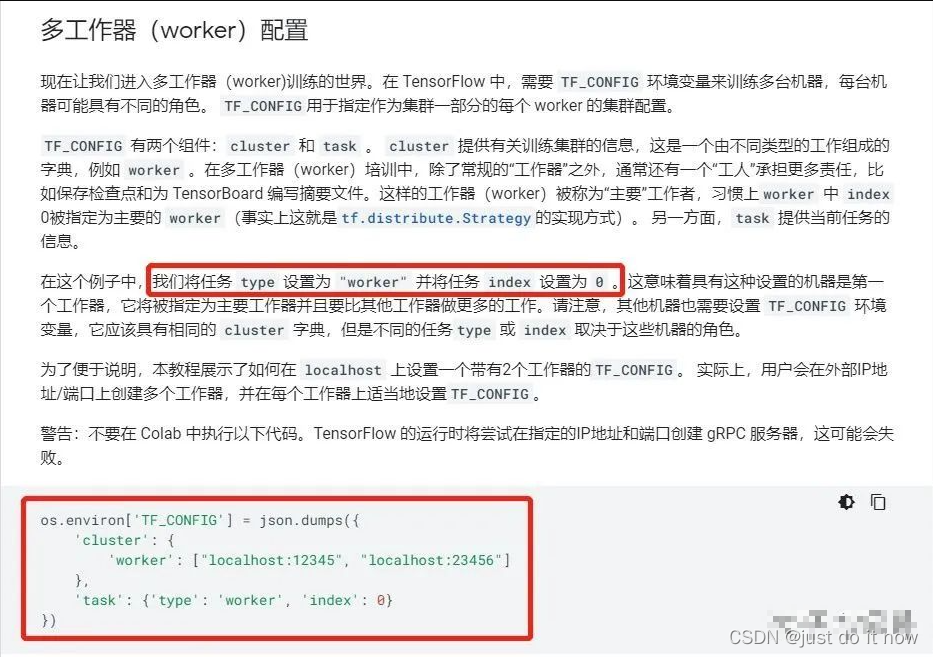
后两种方法都需要传入TF_CONFIG参数,没有就是单机的训练方式。Strategy会自动读取环境变量并应用相关信息。TF_CONFIG的配置如下:
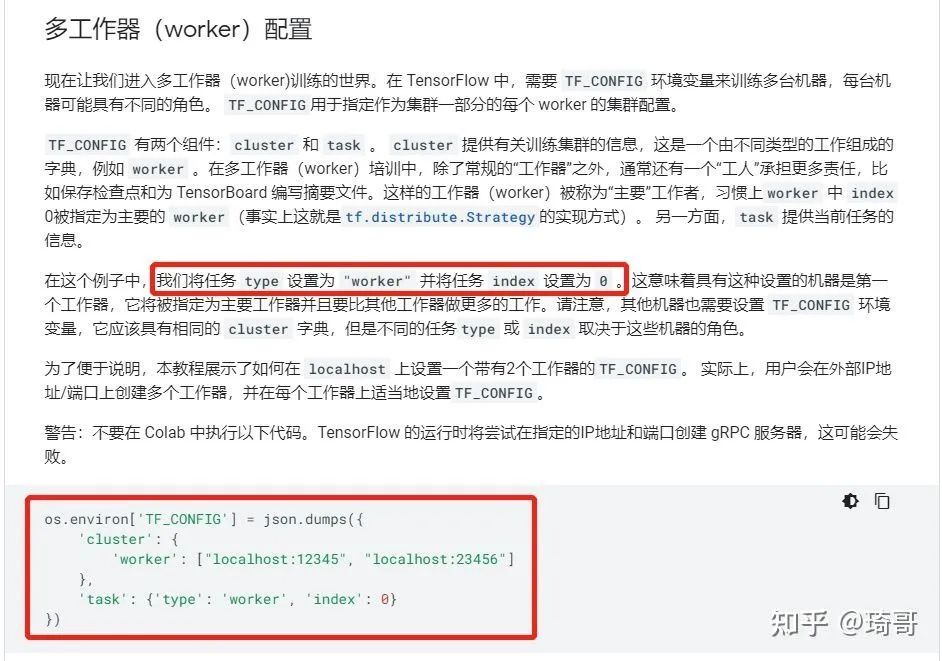
执行脚本示例:
# 分别在各个worker上执行对应的脚本
TF_CONFIG='{"cluster":{"worker":["172.26.0.124:9920","172.26.0.126:9920","172.26.0.127:9920"]},"task":{"index":0,"type":"worker"}}' python multi_worker_with_estimator.py
TF_CONFIG='{"cluster":{"worker":["172.26.0.124:9920","172.26.0.126:9920","172.26.0.127:9920"]},"task":{"index":1,"type":"worker"}}' python multi_worker_with_estimator.py
TF_CONFIG='{"cluster":{"worker":["172.26.0.124:9920","172.26.0.126:9920","172.26.0.127:9920"]},"task":{"index":2,"type":"worker"}}' python multi_worker_with_estimator.py3、Pytorch的分布式训练
相对Tensorflow,Pytorch简单的多。分布式训练主要有两个API:
DataParallel(DP):PS模式,会有一张卡为reduce(parame server),实现简单,就一行代码
DistributedDataParallel(DDP):All-Reduce模式,单机多卡/多级多卡皆可。官方建议API
1、DP:会将数据分割到多个GPU上。这是数据并行的典型,需要将模型复制到每个GPU上,并且一但GPU0计算出梯度,则需要同步梯度,这需要大量的GPU数据传输(类似PS模式);2、DDP:在每个GPU的进程中创建模型副本,并只让数据的一部分对改GPU可用。因为每个GPU中的模型是独立运行的,所以在所有的模型都计算出梯度后,才会在模型之间同步梯度(类似All-reduce)。DDP每个batch只需要一次数据传输;而DP可能存在多次数据同步(不用worker之间可能快慢不一样)。
3.1、DataParallel
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import osinput_size = 5
output_size = 2
batch_size = 30
data_size = 30class RandomDataset(Dataset):def __init__(self, size, length):self.len = lengthself.data = torch.randn(length, size)def __getitem__(self, index):return self.data[index]def __len__(self):return self.lenrand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),batch_size=batch_size, shuffle=True)class Model(nn.Module):# Our modeldef __init__(self, input_size, output_size):super(Model, self).__init__()self.fc = nn.Linear(input_size, output_size)def forward(self, input):output = self.fc(input)print(" In Model: input size", input.size(),"output size", output.size())return output
model = Model(input_size, output_size)if torch.cuda.is_available():model.cuda()if torch.cuda.device_count() > 1:print("Let's use", torch.cuda.device_count(), "GPUs!")# 就这一行!!!!model = nn.DataParallel(model)for data in rand_loader:if torch.cuda.is_available():input_var = Variable(data.cuda())else:input_var = Variable(data)output = model(input_var)print("Outside: input size", input_var.size(), "output_size", output.size())3.2、DDP
官方建议使用DDP,采用All-Reduce架构,单机多卡、多机多卡都能用。
需要注意的是:DDP并不会自动shard数据
如果自己写数据流,得根据torch.distributed.get_rank()去shard数据,获取自己应用的一份
如果用Dataset API,则需要在定义Dataloader的时候用 DistributedSampler去shard
sampler = DistributedSampler(dataset) # 这个sampler会自动分配数据到各个gpu上
DataLoader(dataset, batch_size=batch_size, sampler=sampler)完整代码如下:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
from torch.utils.data.distributed import DistributedSampler
# 1) 初始化
torch.distributed.init_process_group(backend="nccl")input_size = 5
output_size = 2
batch_size = 30
data_size = 90# 2) 配置每个进程的gpu
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)class RandomDataset(Dataset):def __init__(self, size, length):self.len = lengthself.data = torch.randn(length, size).to('cuda')def __getitem__(self, index):return self.data[index]def __len__(self):return self.lendataset = RandomDataset(input_size, data_size)
# 3)使用DistributedSampler
rand_loader = DataLoader(dataset=dataset,batch_size=batch_size,sampler=DistributedSampler(dataset))class Model(nn.Module):def __init__(self, input_size, output_size):super(Model, self).__init__()self.fc = nn.Linear(input_size, output_size)def forward(self, input):output = self.fc(input)print(" In Model: input size", input.size(),"output size", output.size())return outputmodel = Model(input_size, output_size)# 4) 封装之前要把模型移到对应的gpu
model.to(device)if torch.cuda.device_count() > 1:print("Let's use", torch.cuda.device_count(), "GPUs!")# 5) 封装model = torch.nn.parallel.DistributedDataParallel(model,device_ids=[local_rank],output_device=local_rank)for data in rand_loader:if torch.cuda.is_available():input_var = dataelse:input_var = dataoutput = model(input_var)print("Outside: input size", input_var.size(), "output_size", output.size())执行脚本:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 torch_ddp.pyapex加速(混合精度训练、并行训练、同步BN)[5] 可参考:https://zhuanlan.zhihu.com/p/158375055
4、Horovod分布式训练
Horovod是Uber开源的跨平台的分布式训练工具,名字来自于俄国传统民间舞蹈,舞者手牵手围成一个圈跳舞,与Horovod设备之间的通信模式很像,有以下几个特点:
兼容TensorFlow、Keras和PyTorch机器学习框架。
使用Ring-AllReduce算法,对比Parameter Server算法,有着无需等待,负载均衡的优点。
实现简单,五分钟包教包会。
Horovod环境准备以及示例代码[6],可参考作者另一篇文章
本文参考资料
[1]
此链接: https://help.aliyun.com/document_detail/194800.html
[2]reduce的算法: https://zhuanlan.zhihu.com/p/79030485
[3]使用Estimator+Strategy 实现分布式训练: https://github.com/kubeflow/tf-operator/blob/master/examples/v1/distribution_strategy/estimator-API/keras_model_to_estimator.py
[4]Keras + Strategy: https://github.com/kubeflow/tf-operator/blob/master/examples/v1/distribution_strategy/keras-API/multi_worker_strategy-with-keras.py
[5]apex加速(混合精度训练、并行训练、同步BN): https://zhuanlan.zhihu.com/p/158375055
[6]Horovod环境准备以及示例代码: https://zhuanlan.zhihu.com/p/351693076
[7]分布式机器学习系统笔记: https://www.cnblogs.com/yihaha/p/7265280.html
[8]炼丹师的工程修养之四:TensorFlow的分布式训练和K8S: https://zhuanlan.zhihu.com/p/56699786
[9]分布式训练】单机多卡的正确打开方式(三):PyTorch: https://zhuanlan.zhihu.com/p/74792767
往期精彩回顾适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码