虽然我是不用微博的,但由于某种原因,手机端的微博会时不时地推送几条我必须看的消息过来。微博被看久了,前几天又看到 语亮 - 简书 一年前的的微博爬虫,就有了对某人微博深入挖掘的想法。
之前语亮的爬虫不能抓取用户一条微博的多张图片,一年后微博界面也发生了一些变化,决定还是参考语亮爬取手机端界面的方法更新下代码,同时加上一点小小的数据分析。
主要想法是抓取指定用户的全部微博原创内容和全部原创图片保存到本地,然后对原创微博进行分类,并统计用户最爱使用的表情、最常使用的词语和微博中提到的人名。
(经过验证妹子的微博大多集中在美食类、购物类、美妆类和旅游类)
下面说下爬取步骤、展示结果以及详细代码:
因为PC端的微博是JS内容不好爬取,所以还是选择了chrome打开微博手机版进行爬取,简单粗暴无障碍。
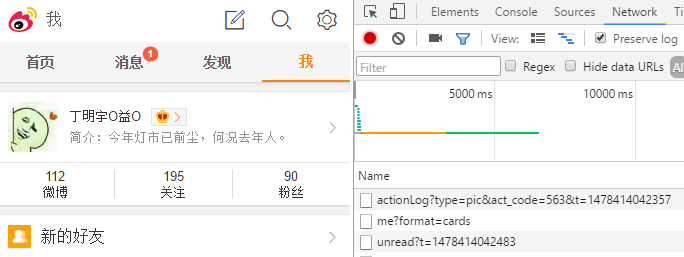
1、获取自己的cookie,利用chrome浏览器。
在chrome 中打开微博手机版,F12打开开发者工具,勾选Network的Preserve log项,然后输入账号密码登陆自己的微博。
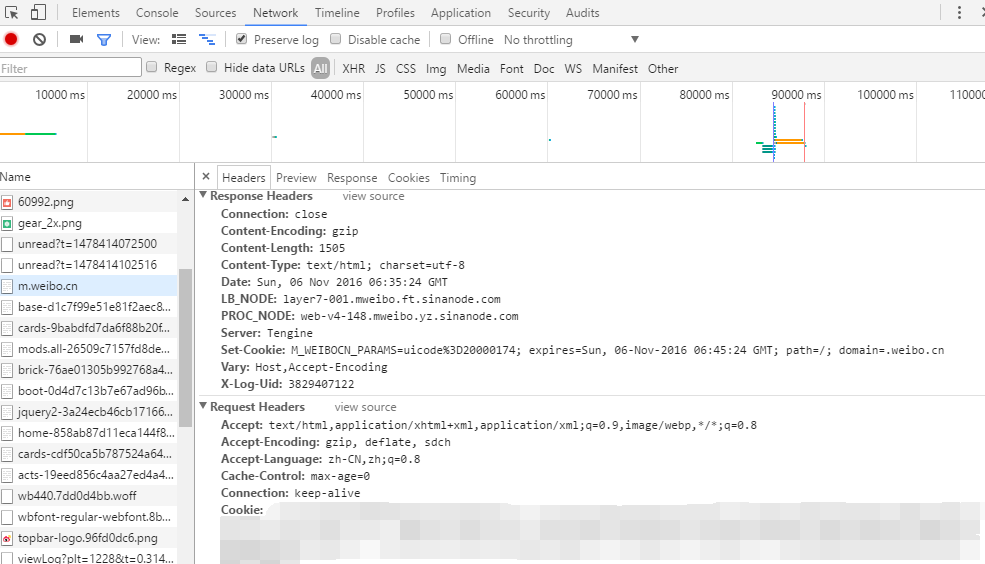
在m.weibo.cn->Headers->Cookie 复制下自己的cookie,一会需要粘贴到代码中运行。
2、获取你要爬取的用户的微博User_id。
依然在手机端找到你要爬取的用户,点进主页,这时浏览器后的ID就是User_id了。
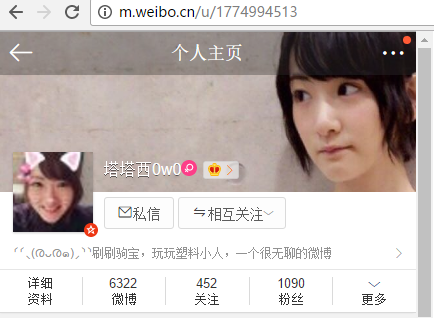
3、将获得的两项内容填入到weibo.py中,替换代码中的YOUR_USER_ID和#YOUR_COOKIE,运行代码就可以了。
在我的测试过程中,发现不停访问微博内容的话,访问25页后就会因为请求过于频繁被拒绝,所以我的代码中每访问一页就sleep一分钟,不着急得到结果的话就一直放在后台跑就可以了。嫌慢的话可以自行修改sleep时间或者利用多个账号的cookie轮流爬取。
爬取过程如下:

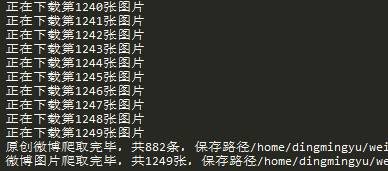
会生成两个文件,分别存有用户所有文字微博和微博图片的url,在weibo_image文件夹中会下载用户所有的微博图片。
(图片有时会下载失败,我的1249张里有4张失败,在日志中可以看到,再手动复制url下载一下即可)
抓取结果如下图所示:
4、下面我们对抓取到的微博内容进行分析,依然是将用户User_id填入代码analysis.py的YOUR_USER_ID处,运行代码即可。
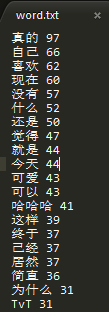
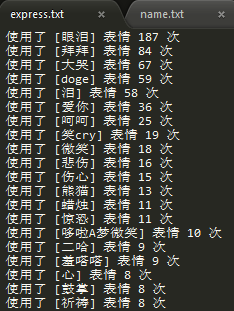
之后会自动生成四个文件,分别是:category.txt, word.txt, express.txt, name.txt. 分别存储了微博分类,常用词,常用表情,微博中的人名及出现次数。


到这里我们的分析基本结束啦,下一步就是将得到的结果用图表清晰的展示出来。
5、利用html5图表可视化结果
在我的github中给出了xita.html模板,套用模板就可以直观的展示我们的代码了,把html文件发给别人看也是可以的。
(这里调用了google的api,所以可能要FQ才能打开)
最后成品如下:
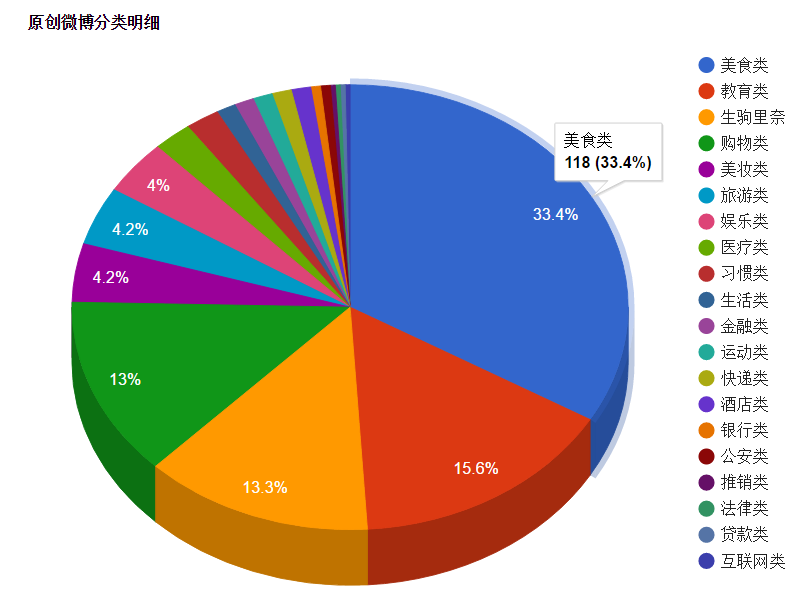
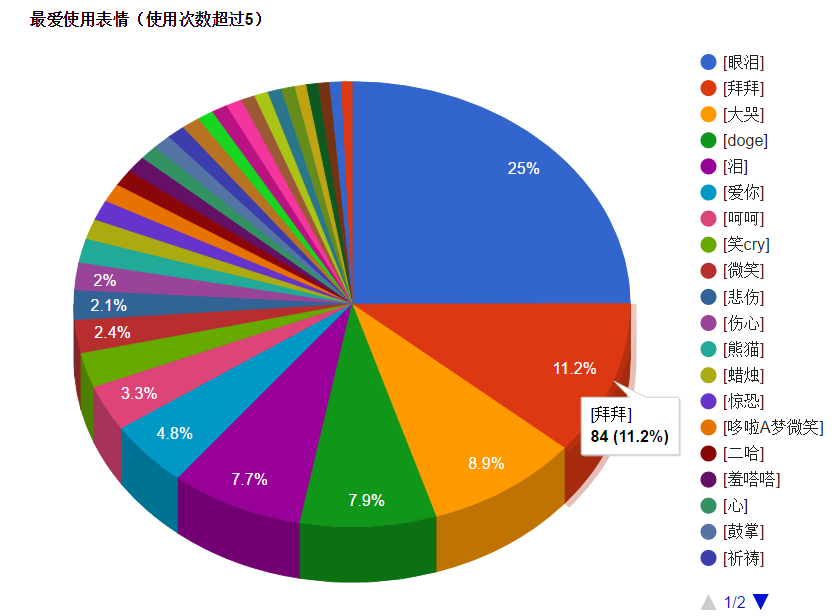

6、下面列出爬取微博和分析所用到的代码:
用到的库看代码中的 import 内容就可以了,安装过程都很简单,大家自行 baidu or google 即可。
weibo.py
1 #-*-coding:utf8-*- 2 3 import re 4 import string 5 import sys 6 import os 7 import urllib 8 import urllib2 9 from bs4 import BeautifulSoup 10 import requests 11 import shutil 12 import time 13 from lxml import etree 14 15 reload(sys) 16 sys.setdefaultencoding('utf-8') 17 #if(len(sys.argv)>=2): 18 # user_id = (int)(sys.argv[1]) 19 #else: 20 # user_id = (int)(raw_input(u"please_input_id: ")) 21 user_id = YOUR_USER_ID 22 cookie = {"Cookie": "#YOUR_COOKIE"} 23 url = 'http://weibo.cn/u/%d?filter=1&page=1'%user_id 24 html = requests.get(url, cookies = cookie).content 25 print u'user_id和cookie读入成功' 26 selector = etree.HTML(html) 27 pageNum = (int)(selector.xpath('//input[@name="mp"]')[0].attrib['value']) 28 29 result = "" 30 urllist_set = set() 31 word_count = 1 32 image_count = 1 33 34 print u'ready' 35 print pageNum 36 sys.stdout.flush() 37 38 times = 5 39 one_step = pageNum/times 40 for step in range(times): 41 if step < times - 1: 42 i = step * one_step + 1 43 j =(step + 1) * one_step + 1 44 else: 45 i = step * one_step + 1 46 j =pageNum + 1 47 for page in range(i, j): 48 #获取lxml页面 49 try: 50 url = 'http://weibo.cn/u/%d?filter=1&page=%d'%(user_id,page) 51 lxml = requests.get(url, cookies = cookie).content 52 #文字爬取 53 selector = etree.HTML(lxml) 54 content = selector.xpath('//span[@class="ctt"]') 55 for each in content: 56 text = each.xpath('string(.)') 57 if word_count >= 3: 58 text = "%d: "%(word_count - 2) +text+"\n" 59 else : 60 text = text+"\n\n" 61 result = result + text 62 word_count += 1 63 print page,'word ok' 64 sys.stdout.flush() 65 soup = BeautifulSoup(lxml, "lxml") 66 urllist = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I)) 67 urllist1 = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/picAll',re.I)) 68 for imgurl in urllist: 69 imgurl['href'] = re.sub(r"amp;", '', imgurl['href']) 70 # print imgurl['href'] 71 urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url) 72 image_count +=1 73 for imgurl_all in urllist1: 74 html_content = requests.get(imgurl_all['href'], cookies = cookie).content 75 soup = BeautifulSoup(html_content, "lxml") 76 urllist2 = soup.find_all('a',href=re.compile(r'^/mblog/oripic',re.I)) 77 for imgurl in urllist2: 78 imgurl['href'] = 'http://weibo.cn' + re.sub(r"amp;", '', imgurl['href']) 79 urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url) 80 image_count +=1 81 image_count -= 1 82 print page,'picurl ok' 83 except: 84 print page,'error' 85 print page, 'sleep' 86 sys.stdout.flush() 87 time.sleep(60) 88 print u'正在进行第', step + 1, u'次停顿,防止访问次数过多' 89 time.sleep(300) 90 91 try: 92 fo = open(os.getcwd()+"/%d"%user_id, "wb") 93 fo.write(result) 94 word_path=os.getcwd()+'/%d'%user_id 95 print u'文字微博爬取完毕' 96 link = "" 97 fo2 = open(os.getcwd()+"/%s_image"%user_id, "wb") 98 for eachlink in urllist_set: 99 link = link + eachlink +"\n" 100 fo2.write(link) 101 print u'图片链接爬取完毕' 102 except: 103 print u'存放数据地址有误' 104 sys.stdout.flush() 105 106 if not urllist_set: 107 print u'该用户原创微博中不存在图片' 108 else: 109 #下载图片,保存在当前目录的pythonimg文件夹下 110 image_path=os.getcwd()+'/weibo_image' 111 if os.path.exists(image_path) is False: 112 os.mkdir(image_path) 113 x = 1 114 for imgurl in urllist_set: 115 temp= image_path + '/%s.jpg' % x 116 print u'正在下载第%s张图片' % x 117 try: 118 # urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp) 119 r = requests.get(imgurl, stream=True) 120 if r.status_code == 200: 121 with open(temp, 'wb') as f: 122 r.raw.decode_content = True 123 shutil.copyfileobj(r.raw, f) 124 except: 125 print u"该图片下载失败:%s"%imgurl 126 x += 1 127 print u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count - 3,word_path) 128 print u'微博图片爬取完毕,共%d张,保存路径%s'%(image_count - 1,image_path)
analysis.py
1 # -*- coding: utf-8 -*- 2 import pandas as pd 3 import re 4 import jieba 5 import jieba.analyse 6 from collections import Counter 7 import sys 8 import time 9 import jieba.posseg as pseg 10 import keywords_new 11 reload(sys) 12 sys.setdefaultencoding('utf-8') 13 14 #sentence = "用知识的浪花去推动思考的风帆,用智慧的火星去点燃思想的火花,用浪漫的激情去创造美好的生活,用科学的力量去强劲腾飞的翅膀!只有使自己自卑的心灵自信起来,弯曲的身躯才能挺直;只有使自己懦弱的体魄健壮起来,束缚的脚步才能迈开;只有使自己狭隘的心胸开阔起来,短视的眼光才能放远;只有使自己愚昧的头脑聪明起来,愚昧的幻想才能抛弃不点燃智慧的火花,聪明的头脑也会变为愚蠢;不践行确立的目标,浪漫的理想也会失去光彩;不珍惜宝贵的时间,人生的岁月也会变得短暂;不总结失败的经验,简单的事情也会让你办砸。宠爱的出发点是爱,落脚点却是恨;嫉妒的出发点是进,落脚点却是退;梦幻的出发点是绚(烂),落脚点却是空;贪婪的出发点是盈,落脚点却是亏。没有激情,爱就不会燃烧;没有友情,朋就不会满座;没有豪情,志就难于实现;没有心情,事就难于完成。我们缺少的不是机遇,而是对机遇的把握;我们缺欠的不是财富,而是创造财富的本领;我们缺乏的不是知识,而是学而不厌的态度;我们缺少的不是理想,而是身体力行的实践。有了成绩要马上忘掉,这样才不会自寻烦恼;有了错误要时刻记住,这样才不会重蹈覆辙;有了机遇要马上抓住,这样才不会失去机会;有了困难要寻找对策,这样才能迎刃而解。你可以不高尚,但不能无耻;你可以不伟大,但不能卑鄙;你可以不聪明,但不能糊涂;你可以不博学,但不能无知;你可以不交友,但不能孤僻;你可以不乐观,但不能厌世;你可以不慷慨,但不能损人;你可以不追求,但不能嫉妒;你可以不进取,但不能倒退。生活需要游戏,但不能游戏人生;生活需要歌舞,但不需醉生梦死;生活需要艺术,但不能投机取巧;生活需要勇气,但不能鲁莽蛮干;生活需要重复,但不能重蹈覆辙。把工作当享受,你就会竭尽全力;把生活当乐趣,你就会满怀信心;把读书当成长,你就会勤奋努力;把奉献当快乐,你就会慷慨助人。" 15 16 f = open("YOUR_USER_ID", "r") 17 f1 = open("category.txt", "w") 18 f2 = open("express.txt", "w") 19 f3 = open("word.txt", "w") 20 f4 = open("name.txt", "w") 21 list1 = [] 22 record = {} # 记录命中信息 23 express = {} 24 name_set = {} 25 while True: 26 line = f.readline().strip().decode('utf-8') 27 if line: 28 item = line.split(' ', 1)[1] 29 ex_all = re.findall(u"\\[.*?\\]", item) 30 if ex_all: 31 for ex_item in ex_all: 32 express[ex_item] = express.get(ex_item, 0) + 1 33 for kw, keywords in keywords_new.keyword_dict.iteritems(): # kw是大类 34 flag = 0 # 大类命中的标志 35 for key, keyword in keywords.iteritems(): # key 是小类 36 if flag == 1: 37 break 38 for word in keyword: # 小类关键词 39 match_flag = 1 # 列表中关键词全部命中的标志 40 for small_word in word: # 关键词列表 41 # print small_word 42 match = re.search(re.compile(small_word, re.I), item) 43 if not match: 44 match_flag = 0 45 break 46 if match_flag == 1: #命中了一个小类 47 record[kw] = record.get(kw, 0) + 1 # 单次记录 48 flag = 1 49 break 50 item = re.sub(u"\\[.*?\\]", '', item) 51 list = jieba.cut(item, cut_all = False) 52 for ll in list: 53 list1.append(ll) # 分词 54 seg_list = pseg.cut(item) 55 for word, flag in seg_list: 56 if flag == 'nr': 57 name_set[word] = name_set.get(word, 0) + 1 58 else: 59 break 60 61 count = Counter(list1) 62 for item in sorted(dict(count).iteritems(), key=lambda d:d[1], reverse = True): 63 if len(item[0]) >= 2 and item[1] >= 3: 64 print >> f3, item[0],item[1] 65 66 for key, keywords in sorted(record.iteritems(), key=lambda d:d[1], reverse = True): 67 print >> f1, u'命中了', key, record[key], u'次' 68 69 for key, keywords in sorted(express.iteritems(), key=lambda d:d[1], reverse = True): 70 print >> f2, u'使用了', key, u'表情', express[key], u'次' 71 72 for key, keywords in sorted(name_set.iteritems(), key=lambda d:d[1], reverse = True): 73 print >>f4, u'使用了名字', key, name_set[key], u'次'
当然词语识别和人名识别还是不够准确的,仅供娱乐参考。
还想把收集到的微博图片识别归类一下,但是太杂乱了不好搞,以后有空可以试试识别下人脸。
此项目全部代码和结果都在我的github上,欢迎大家Star和Fork,嘿嘿。
最后说下,正直的我并没有用这个东西去抓小黄图!