本文结构:
一、那些年我们加过的QQ群
二、数据读入和整理(一)——来自蓝翔的挖掘机
二、 数据读入和整理(二) ——你不知道的事
三、聊天宏观(1)——寤寐思服
三、聊天宏观(2) 日月篇
三、聊天宏观(3)七曜 篇
四、聊天微观(1) ——黄金档和午夜频道
四、聊天微观(2) ——充电两小时聊天五分钟
四、聊天微观(3) ——幸存者偏差和沉默的羔羊
五、昵称(1) ——我们曾经的非主流
五、昵称(2) ——所爱隔山海
六、内容分词——爱在心口难开,你我之间隔了正无穷个表情包
好吧,我的来捣乱的,原谅我瞎取名字吧,最近真实超喜欢 小椴在他的作品里到处种诗啊,真是忍不住我也要到处放! ~UC震惊部我大概是去不了了
另,本文是在参考/模仿,甚至可以说是抄袭别人的基础上所作,希望原作者见谅
一梦江湖费五年。归来风物故依然。相逢一醉是前缘。
迁客不应常眊矂,使君为出小婵娟。翠鬟聊著小诗缠。
——苏轼《浣溪沙》
- 一、那些年我们加过的QQ群
如果标题要这么起的话,那我要想起“刹那芳华尽,弹指红颜老”,想起那个叫做刹那的群来,想起那些人儿来,我加入他们已经六载有余。你要说这是什么鬼名字——不知所踪的群主大概要说“情不知所起”,我想应该是自取《天龙八部》回三十有五,恰这恩怨情仇,也当如无崖子、天山童姥、李秋水之间外加一个李沧海一般复杂了。
每一个QQ群都有其消亡史, 只怨人在风中,聚散都不由你我
与其盖棺定论、盗墓考古,不如生前来晒晒太阳。
当然,我还是舍不得拿它开刀的,所以选择某活跃度适中的群开扒
如何导出可分析的QQ群聊天记录?
注意轻聊版没有此功能

选择群——右键——导出2 保存时选择为txt格式 (尘封旧物,应有戌时的光打着)

数据格式如下:
- 二、数据读入和整理(一)——来自蓝翔的挖掘机
寻龙点穴,翻山倒斗,蓝翔挖掘机不可或缺,大概总以蓝翔代山寨,本文既然是一通抄袭,那用这辍学少年必备,小朋友最爱的挖机来挖挖数据是最合适不过的。
# 1读入数据
- file_data <- read.table('数据分析1excel spss.txt',
stringsAsFactors = F,encoding = "UTF-8",sep='\n',quote=NULL)
stringsAsFactors = F字符不转为因子encoding = "UTF-8"是设置解码格式,为了防止中文乱码sep = '\n'按照行分隔,把txt中的每一行作为数据框 file_data 的一行注意,如果不加 quote = NULL ,则会出错(部分文件不需要加)
读到的数据如下:

(部分聊天数据后面居然还跟着/n,那我们到时候剔除掉好了)
#2定义数据框和变量
data <- data.frame(user_name = c(), datetime = c(), text = c())user_name <- character()datetime <- character()text <- character()
#分解数据为名字、时间、和文本(聊天内容)
for(i in 1:dim(file_data)[1]){dt_pattern <- regexpr('[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]+:[0-9]+:[0-9]+',file_data[i,])if(dt_pattern == 1) {user_begin <- dt_pattern+attr(dt_pattern,'match.length') + 1user_end <- nchar(file_data[i,])user_name <- substring(file_data[i,],user_begin,user_end)dt_begin <- dt_patterndt_end <- dt_pattern+attr(dt_pattern,'match.length')-1datetime <- substring(file_data[i,],dt_begin,dt_end)text <- file_data[i+1,]data <- rbind(data, data.frame(Name = user_name,datetime = datetime,text = text))}}
正则表达式: [0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]+:[0-9]+:[0-9]+年-月-日 时:分:秒———— 这作为一个整体关于regexpr函数
regexpr returns an integer vector of the same length astext giving the starting position of the first matchor -1 if there is none,with attribute "match.length",an integer vector giving the length of the matched text (or -1 for no match).The match positions and lengths are in characters unless useBytes = TRUEis used, when they are in bytes.If named capture is usedthere are further attributes "capture.start", "capture.length" and "capture.names".
亦即匹配则返回一个整型向量(这个向量中的值表示的是text中满足正则条件的那个串的第一个家伙在text中的位置), 不匹配则返回-1例子:
> pattern <- '[0-9]{4}-[0-9]{2}-[0-9]{2}'> strings <- "我 测试1 2016-07-12 14:13:45 测试2 2016-07-12 "> regexpr(pattern, strings,+ useBytes = FALSE)[1] 7 #返回值attr(,"match.length") #属性match.length[1] 10> length(strings)[1] 1
match.length属性的值存储所匹配的那个串的长度(感觉自己在撸串)
观察数据:

即年月日 时分秒 用户名消息内容
user_begin <- dt_pattern+attr(dt_pattern,'match.length') + 1user_end <- nchar(file_data[i,])user_name <- substring(file_data[i,],user_begin,user_end)
user_begin 是用户名起点attr (变量 ,属性名 )的意思本应是取/ 赋属性实际上应该是当 match.length 属性存在且右侧有<-时是赋值,否则就是取 match.length 属性的值user_end是用户名终点
nchar 就是得到一个字符串的长度(有多少个),举个例子
-
> x <- c("asfef", "qwerty", "yuiop[", "b", "stuff.blah.yech")> nchar(x)[1] 5 6 6 1 15> nchar(deparse(mean))[1] 18 17> deparse(mean)[1] "function (x, ...) " "UseMethod(\"mean\")"
deparse是一个可以将一个任意的R对象转化为字符串的的函数
nchar takes a character vector as an argument andreturns a vector whose elements contain the sizes ofthe corresponding elements of x.
user_name是发布 该条聊天记录的用户的用户名substring(被截取的字符串,截取起点,截取终点)datetime是该条聊天记录的发布的时间text是消息内容(从数据格式可以看到,紧随在下一行)
- 二、数据读入和整理(二)——你不知道的事
如果你听过这首《你不知道的事》,一定觉得它很温柔,但生活并不如歌——多的是你不知道的事。
上面的操作看起来很完美,但是问题出现了,如果该QQ账号发布的消息本身没有换行,那么就算他发布的消息内容很多也会被封装为一行,但如果消息本身就换行了呢?
比如下面这种:

以及,部分是系统消息,比如xxx分享了xxx文件

所以我将上述代码修改为:
file_data <- read.table('数据分析1excel spss.txt',stringsAsFactors = F,encoding = "UTF-8",sep='\n',quote=NULL)head(file_data)#2定义数据框和变量data <- data.frame(user_name = c(),datetime = c(), text = c(),stringsAsFactors = F)user_name <- character()datetime <- character()text <- character()user_name <- character()datetime <- character()text <- character()# file_data <- file_data[1:110,,drop=F]class(file_data)#分解数据为名字、时间、和文本(聊天内容)pattern <- '[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]+:[0-9]+:[0-9]+'j <- 1for(i in 1:dim(file_data)[1]){dt_pattern <- regexpr(pattern,file_data[i,])if(dt_pattern == 1) {if(i >5 & (i-j)>2){for(k in (j+2):(i-1)){last <- dim(data)[1]data[last,3] <-paste(data[last,3],file_data[k,],sep="")}}user_begin <- dt_pattern+attr(dt_pattern,'match.length') + 1user_end <- nchar(file_data[i,])user_name <- substring(file_data[i,],user_begin,user_end)dt_begin <- dt_patterndt_end <- dt_pattern+attr(dt_pattern,'match.length')-1datetime <- substring(file_data[i,],dt_begin,dt_end)text <- file_data[i+1,]data <- rbind(data, data.frame(Name = user_name,datetime = datetime,text = text,stringsAsFactors = F))j <- i}}datasave <- data
注意1两处stringsAsFactors = F的设置注意2新增了一个if判断,以避开连续
- 三、聊天宏观(1)——寤寐思服
渺万里层云,千山暮雪,只影向谁去
如果你暗恋一个妹纸,你一定会埋伏在她的在线时刻,乘隙找她聊几句,“ 求之不得,寤寐思服。悠哉悠哉,辗转反侧 ”,我们还是观察下她在什么时候发言较多吧(表明她有闲暇且有交流欲望)。以此类推,尽管,我们这里都是基佬或女汉子......但是但是!骚年如果你要提问,不也应该选择在人多的时候嘛?这样你获得答案的概率也更高。
那么就让我们来看看大家都喜欢在什么时候上线聊天吧
library(sqldf)# lubridate包是为了方便取日期数据的library(lubridate)library(ggplot2)library(ggthemes)#######################################################第二部分#每天的消息都有多少?time <- data$datetimep <- paste(year(time),month(time),day(time),sep = "-")tail(p,50)Timed <- data.frame(days = p)mydata1 <- sqldf('select days iddays,count() Freq fromTimed group by days')#不要加ASmydata1 <- mydata1[order(as.Date(mydata1$iddays)),]head(mydata1)ggplot(mydata1,aes(x=as.Date(iddays),y=Freq))+geom_area(fill='mediumpurple1',alpha=0.5)+geom_point(shape="♠",size=3,colour='salmon')+xlab("时间")+ylab("消息密集度")+theme_solarized_2()
1其中 sqldf 包可以 按照sql的方式来查询dataframe的内容2其中 lubridate 包是用来操作日期数据的(如month、day、hour等函数)3要想达到这样的效果,只要用搜狗插入(所有的符号大全里,并不是所有的符号都支 持,挑选几个试试就好啦~),通过alpha设置透明度。4 order ( as . Date ( mydata1$iddays )) 要先转化为日期格式再使用order,不然字符串是识别不了顺序的。5 回忆下:order给出升序排序时,应该排在第一位的那个数,在当前的第几个位置,其他的以此类推。比如 a[order(a)]就是对向量a升序排序。这个图画的是每一天的消息记录条数
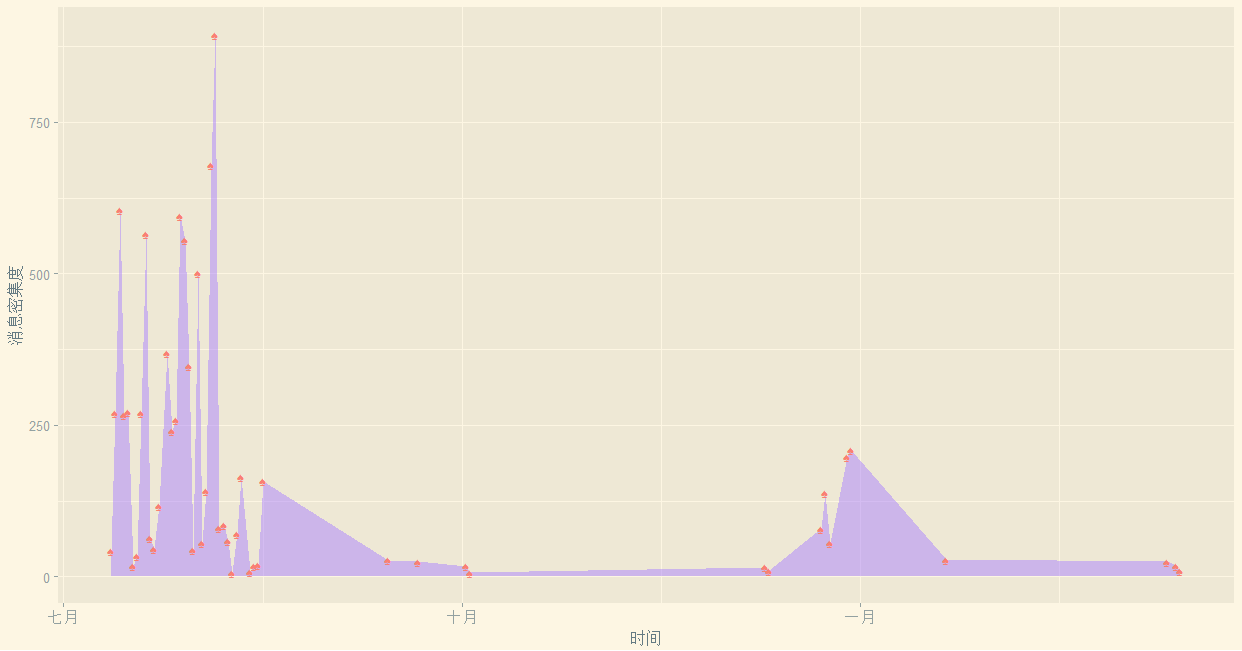
可见我的样本其实是不全的,基本上集中在7月至9月,而9月到12月的数据是空白,而1月-2月数据又重新开始出现,嗨,了解我的人大概知道为什么我那段时间不在的了。
- 三、聊天宏观(2)日月篇
日月忽其不淹兮,春与秋其代序
大家喜欢在哪几个月的哪些天扯淡呢?
Time <- data.frame(year = year(time),month = month(time),day = day(time),hour = hour(time))my.data2 <- sqldf('select month,day,count(*) Freq from Timegroup by month,day')head(my.data2)p2 <- ggplot(data = my.data2,mapping = aes(x = factor(day), y = factor(month),fill = Freq))p2 <-p2+geom_tile()+scale_fill_gradient(low = '#2ecc71',high = '#e74c3c')+xlab("所在天数")+ylab("所在月份")p2p2+theme_solarized_2()
tile在英语中的意思是地砖、瓦片,很形象吧?scale_fill_gradient函数作用是设置高频率和低频率各自的颜色
效果如下:
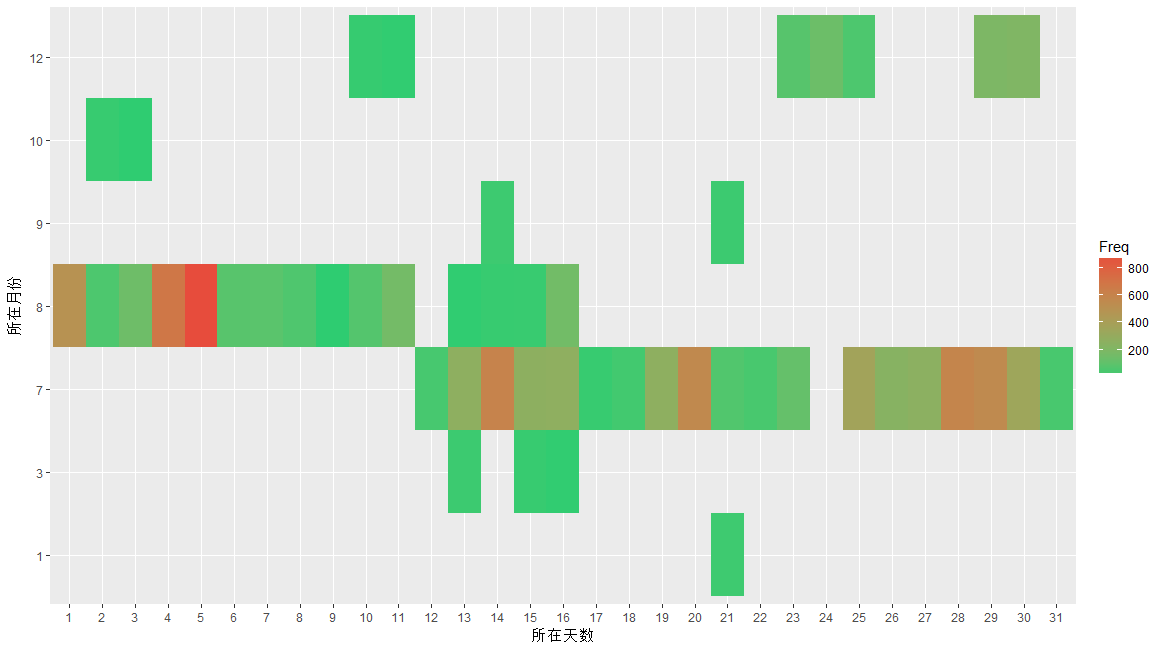
那些黑色的块,其实就是缺失值吧。由于缺失值的存在,让我觉得自己是卖狗皮膏药的,所以 上个主题吧
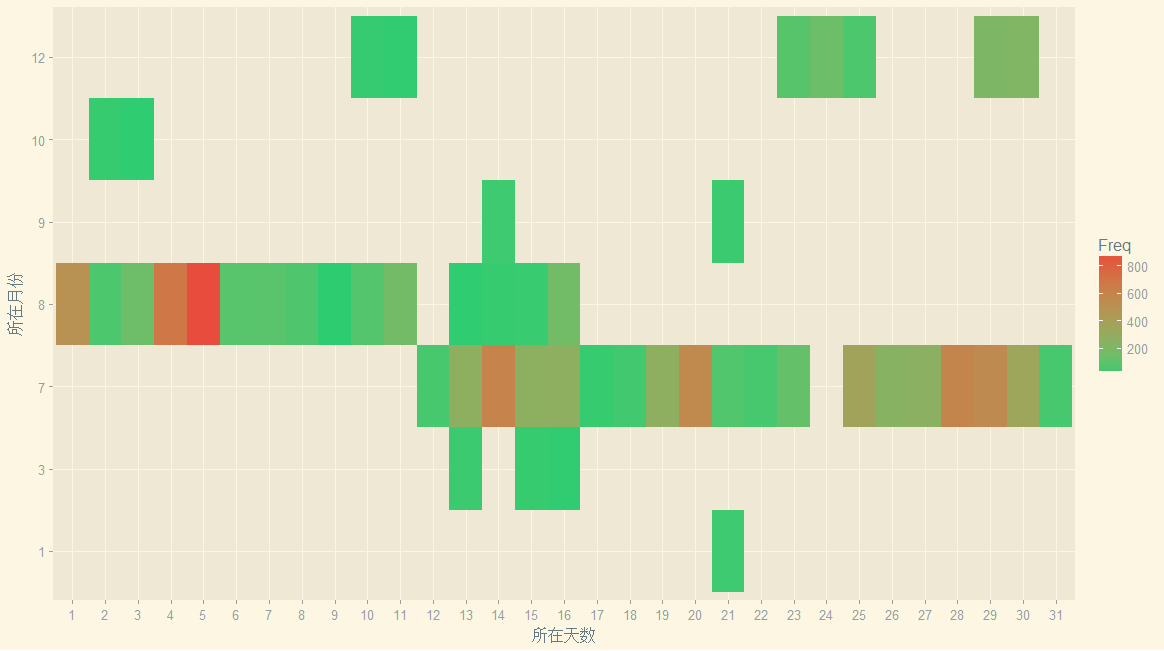
但是我又想起《晚秋》,总感觉自己像是吃软饭的....所以!
my.data2<- sqldf('select month,day,count(*) Freq from Timegroup by month,day')#方式一#生成序列date <- seq.Date(from=as.Date('2016-01-01'),to=as.Date('2016-12-31'), by='1 day')head(date)library(lubridate)months <-month(date)days<-day(date)#构建一个数据框dataf <- data.frame(month = c(),datetime = c(),text = c())all <- paste(months,days,sep = "")my.data2all <- paste(my.data2[,1],my.data2[,2],sep = "")pos <- match(all,my.data2all)for(i in 1:length(days)){dataf[i,1] <- months[i]dataf[i,2] <- days[i]if(!is.na(pos[i])){dataf[i,3] <- my.data2[pos[i],3]}else{dataf[i,3] <- NA}}colnames(dataf) <- c("month","day","Freq")library(ggplot2)p1 <- ggplot(data = dataf,mapping = aes(x = factor(day), y = factor(month),fill = Freq))p1 <-p1+geom_tile()+scale_fill_gradient(low = '#2ecc71',high = '#e74c3c',na.value="#ecf0f1")+xlab("所在天数")+ylab("所在月份")p1
效果如下:
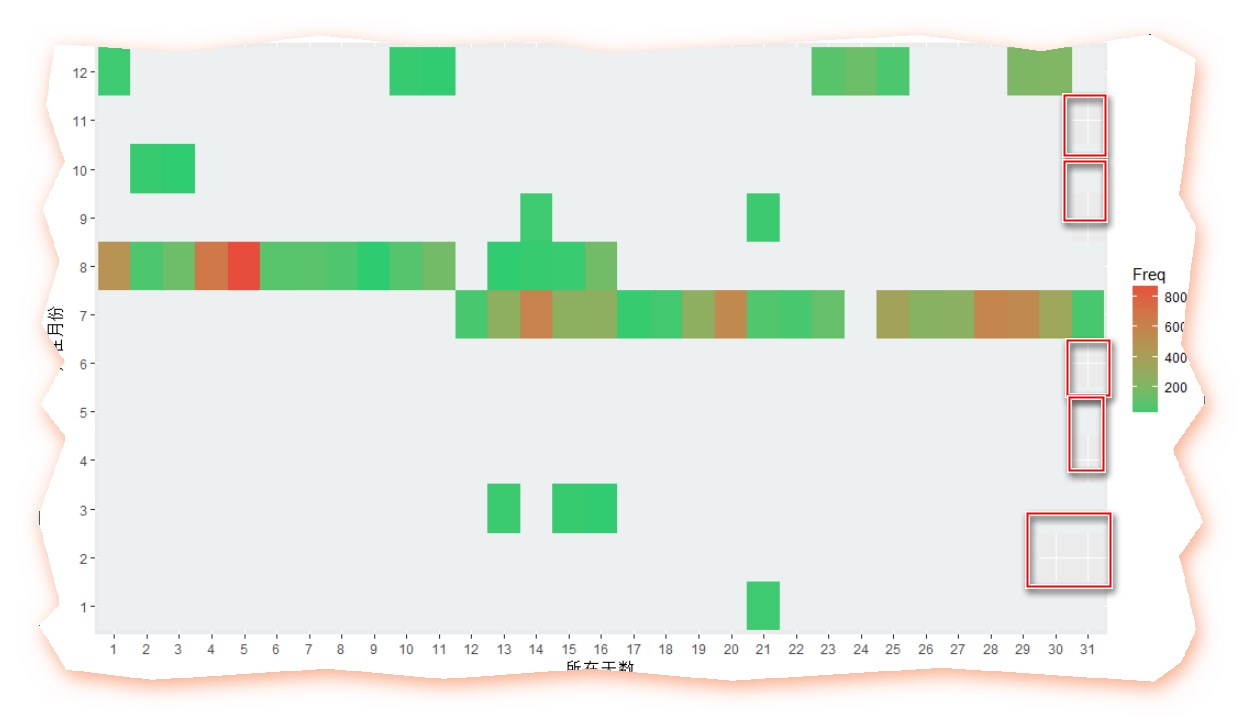
是的,你没看错, na . value 这个参数就是这么坑爹,只有当值为NA的时候才发挥作用(毕竟Freq可以是NA,但是x和y还是要存在才可以啊),所以我就用上述代码自己拼接了一个数据框出来可是,虽说箪食瓢饮回也不改其乐,但这个看脸的年代,脸上有几颗痘痘,衣服上有几块补丁,实在是苦啊~!所以,就别怪我整容了!
d <- rep(1:31,12)m <- rep(1:12,each =31)all <- paste(m,d,sep = "")allmy.data2all <- paste(my.data2[,1],my.data2[,2],sep = "")pos <- match(all,my.data2all)for(i in 1:length(d)){dataf[i,1] <- m[i]dataf[i,2] <- d[i]if(!is.na(pos[i])){dataf[i,3] <- my.data2[pos[i],3]}else{dataf[i,3] <- NA}}colnames(dataf) <- c("month","day","Freq")library(ggplot2)p1 <- ggplot(data = dataf,mapping = aes(x = factor(day), y = factor(month),fill = Freq))p1 <-p1+geom_tile(colour="papayawhip")+scale_fill_gradient(low = '#2ecc71',high = '#e74c3c',na.value="peachpuff")+xlab("所在天数")+ylab("所在月份")p1
虽然说有可能整残了,不过呢,不整一整,是不会死心哒
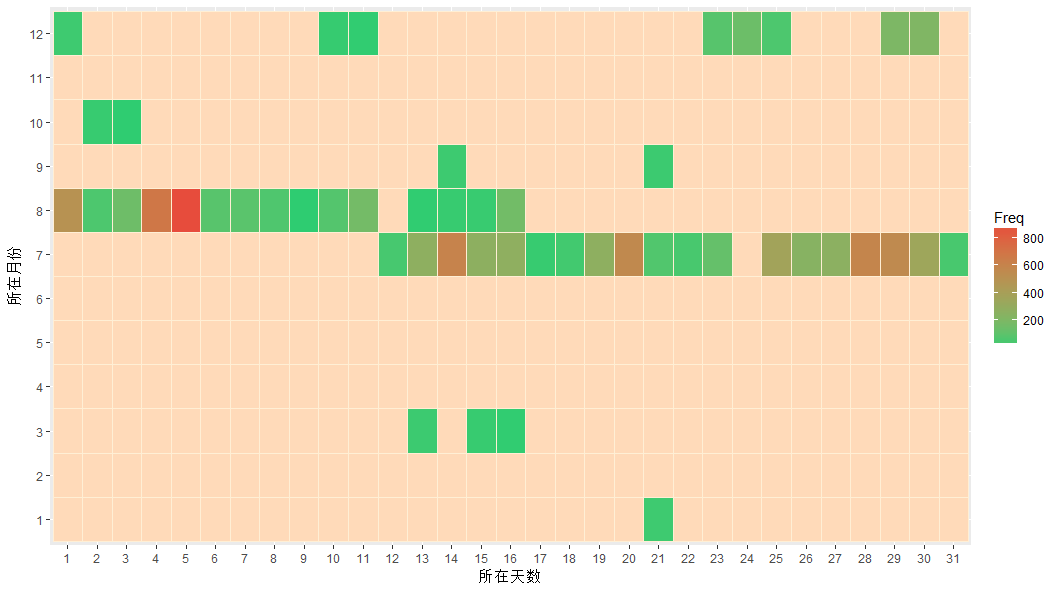
- 三、聊天宏观(3)七曜篇
阴阳为之愆度,七曜为之盈缩——“谓之七曜者,日月五星皆照天下,故谓之曜”
那么大家喜欢在星期几呢?
# 大家喜欢在星期几聊天呢?weekdays <- wday(data$datetime)p3 <- ggplot(data = NULL,mapping = aes(x = weekdays,fill = factor(weekdays)))labels <- c("周一","周二","周三","周四","周五","周六","周日")p3+geom_bar(show.legend = F,alpha=0.6)+scale_x_continuous(breaks = seq(1,7,by=1),labels = labels)+xlab('星期几')+ylab('消息条数')+theme_solarized_2()
设定了alpha, 通过labels设定了坐标轴标签,这里的breaks和labels的长度要一致
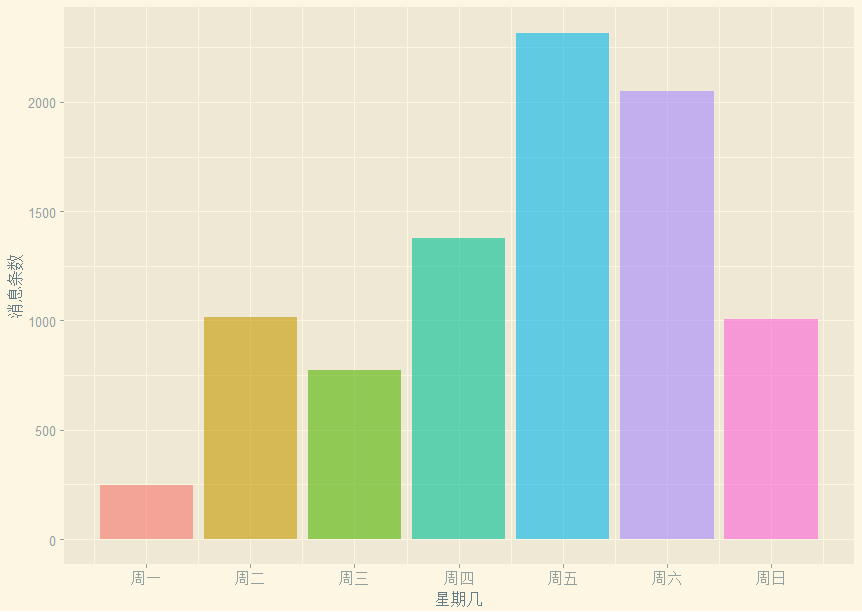
看来周一大家都忙着干活,嗯,第一天嘛,肯定是很多事情的了,周四就开始有怠工的情绪了,到周五,真是按耐不住周末到来的喜悦啊,喜迎工人阶级对资本家们的伟大胜利——终于放假啦!最大值就出现在工作日,老板你心里怎么想?我这是业务交流啊业务交流!....周六的消息也蛮多的,个人觉得,要么大家都是没有女票的死宅,要么...大概是在一把辛酸泪的加班吧。
- 四、聊天微观(1)——黄金档和午夜频道
小时候我们有的八点黄金档,后来我们学会了熬夜大家喜欢在一天里的那些时间扯淡呢?
- my.data3 <- sqldf('select hour,count(*) Freq from Time
group by month,day')#取得了小时的频率#(Freq的意思是计数后的频率存在名为Frequency的列)head(my.data3)#查看数据后发现有相同值#于是我们打算合并之mydata3 <- my.data3#需要这一步是因为如果写的是my.data3会识别不了my.data23 <- sqldf('select hour,SUM(Freq) Freq from mydata3group by hour')head(my.data3)
ggplot(my.data3,aes(x=hour,y=Freq))+geom_area(fill='cadetblue2',alpha=0.5)+geom_line(linetype = "dotdash",colour='brown2',size=1.2,alpha=0.9)+geom_point(shape="★",size=3,colour='brown1')+scale_x_continuous(breaks = seq(8,23,by=1),labels = seq(8,23,by=1))+xlab("时间")+ylab("消息密集度")+theme_solarized_2()
出图如下:
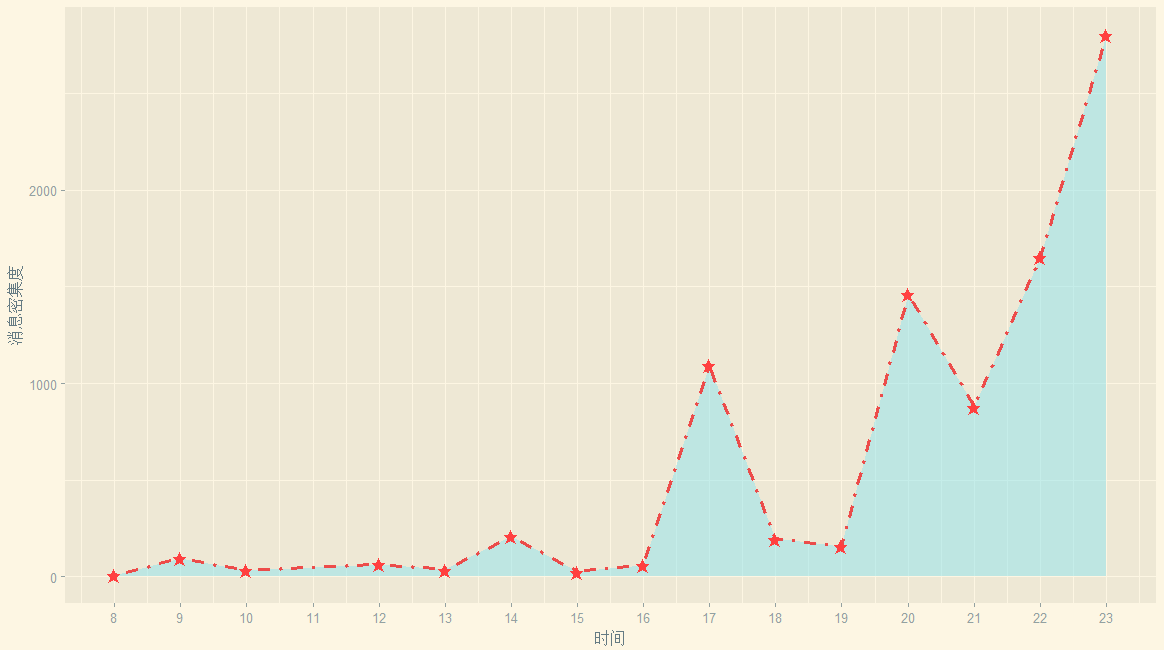
早上:你看,早起干活的人很少呐 (早于8点的消息记录是0,当然,对于有固定上班时间的白领们而言,早起是不合理的)早上大家基本上忙着干活(8点到12点),老板快发员工奖!中午:中午吃饭是没人扯淡的(12-13点之间)下午:吃完午饭闲扯个蛋(14点出现一个小浪尖)开始活跃起来了下午4点之后大家基本上开始怠工啦,消息开始增加,在下班前达到峰值。晚上:大家都得浪费时间在下班路上/吃饭(18--19点之间),这个点也没人。20点次峰开始出现,所以说黄金档 八点整 不是白叫的,看肥皂剧或者泡论坛闲扯都在这个时间段,聊天也在这个点也很合乎逻辑。21点的下降可以认为部分人已经开始准备洗漱和入睡,在东部对于第二天还要上班的同学把10点左右设为上床时间也蛮正常,不过具体是上床玩手机还是睡觉是个问题呐,反正不跟基友们瞎扯了,毕竟还有妹子/游戏/小说呢?夜猫子总是很顽强的.....大概是夜猫军团源源增兵,也许是没有女票的猿们上床了还是跟基友们扯淡,峰值居然出现在23点。好吧,不是跟老板说好了——感觉身体被掏空?不知道这个午夜频道有没有福利呢?
剧情反转:
上面我们提到聊天消息最多的日子出现在一周的周五,看起来好像大家是怠工了,但实际上未必如此,从这里的消息时间来看,大家还是很有职业道德的,赞一个,老板你感动吗?因为大家的聊天基本上集中在下午4点之后,所以相信大家还是在认真完成工作的前提下在群里灌灌水的。看来周五真是让人想来一个生命的大和谐。
- 四、聊天微观(2)——充电两小时聊天五分钟
充电五分钟,通话两小时,其实并没什么卵用,事实是我们很遇到愿意跟你持续沟通的对方,往往就是满格的电池容量,空荡荡的聊天列表。
如果一条消息五分钟都没有得到回应,那么就算是断裂了,这作为一组对话。
#连续聊天的次数# 连续对话的次数,以五分钟为间隔data$realtime <- strptime(data$datetime,'%Y-%m-%d %H:%M')# 时间排序没有问题# (毕竟我是读取txt后提取的,人家腾讯帮我搞好了)head(data)# 将数据按讨论来分组group <- rep(1,dim(data)[1])head(group)for (i in 2:dim(data)[1]) {d <- as.numeric(difftime(data$realtime[i],data$realtime[i-1],units='mins'))if ( d < 5) {group[i] <- group[i-1]#小于5分钟的,我们认为是同一组对话}else {group[i] <- group[i-1]+1}#大于5分钟,就是一组新的对话的看,所以连续对话的组数+1}head(group,20)tcon <- as.data.frame(table(group))head(tcon)p4 <- ggplot(data = tcon,mapping = aes(x =group,y=Freq))p4 +geom_bar(aes(x = group, y = Freq,col='red',alpha=0.5),show.legend=F,stat="identity")+xlab('连续聊天次数')+ylab(NULL)+theme(axis.text.x = element_blank(),axis.ticks.x = element_blank())
1 为什么需要 as . data . frame ( table ( group )) 呢?转化为数据框很有必要,虽然你查看class的时候,看到table函数的返回结果是一个数据框,但实际取数据的时候一些扯淡的问题就开始出现啦~
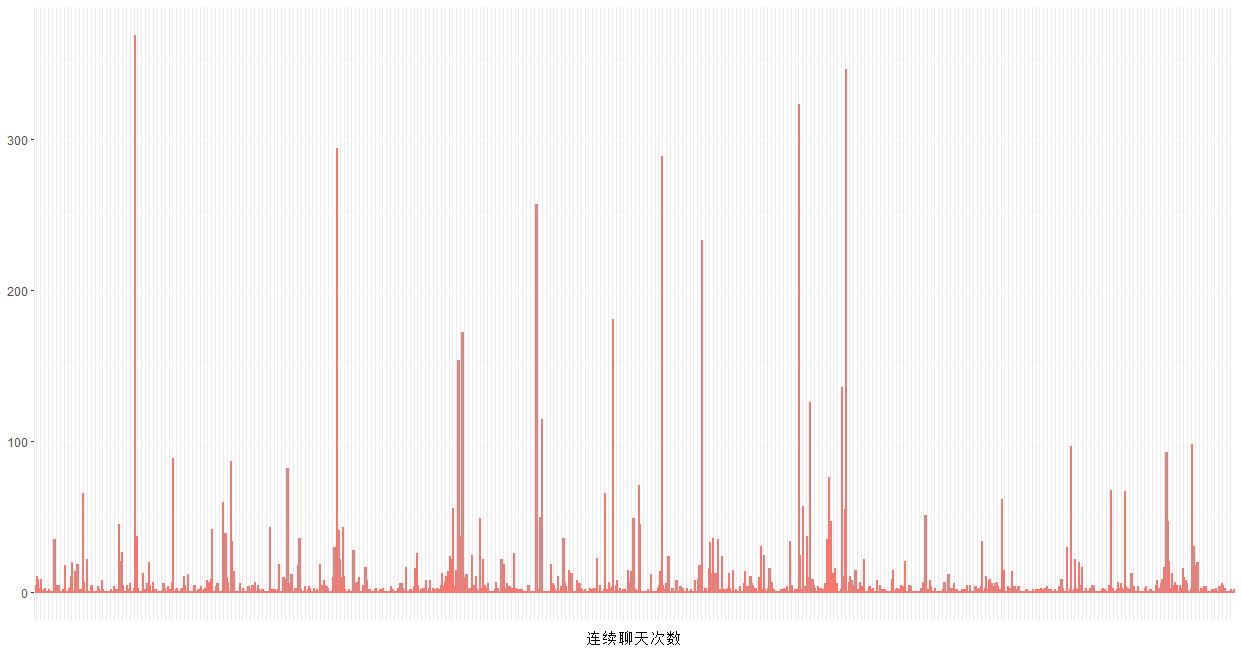
实际上,上述图形是毫无意义的。正确的做法是,选出一条内的聊天消息数大于均值的那些天,然后计算那些天的连续聊天组数一天才多少分钟?60*24=1440分钟,每5分钟为一组的话,有288组, 如果考虑到有效聊天时间集中在8点-234点,那么实际上最大值只有192组。连续聊天组数普遍较低,说明大家不会总是聊着聊着人就不见了,有些人呐,“吟安一个字,捻断数茎须”,回消息有一搭没一搭,也的确令人惊奇。
- 四、聊天微观(3)——幸存者偏差和沉默的羔羊
如果我告诉你整个群有近1800个成员,你是什么感受呢?茫茫人海,我们都是成群的羔羊,既不会相遇,还保持着沉默。哪些人最喜欢聊天?取出前20名
#活跃用户前20名#每个用户的说话频次(取前20名)mydf <- as.data.frame(table(data$Name))#前20名活跃的群成员names(mydf)[1]="Name"top20 <- mydf[order(mydf$Freq, decreasing = TRUE),][1:20,]#绘制没有排序后的条形图p5 <- ggplot(data = top20,mapping = aes(x = Name,weight = Freq,fill = Name)) +xlab(NULL) + ylab(NULL)p5 <- p5 +geom_bar(aes(x = reorder(Name, Freq),y = Freq, fill = Name,alpha=0.5),show.legend=F,stat="identity") +coord_flip()+theme_solarized_2()p5
出图如下:
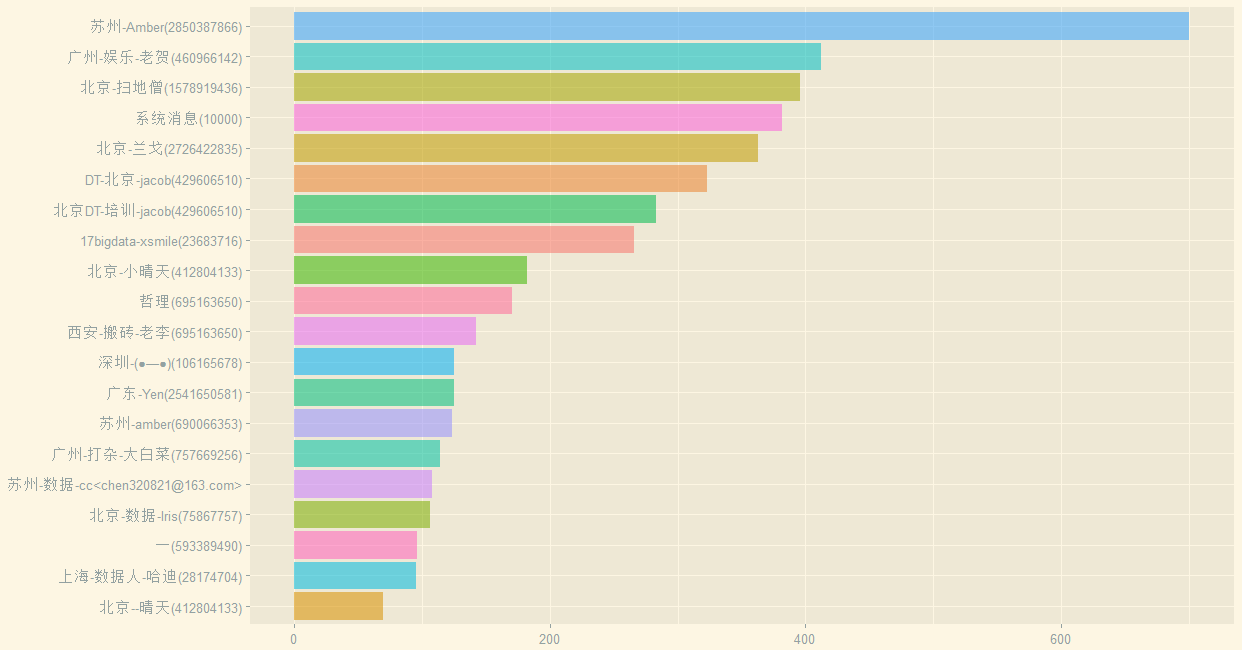
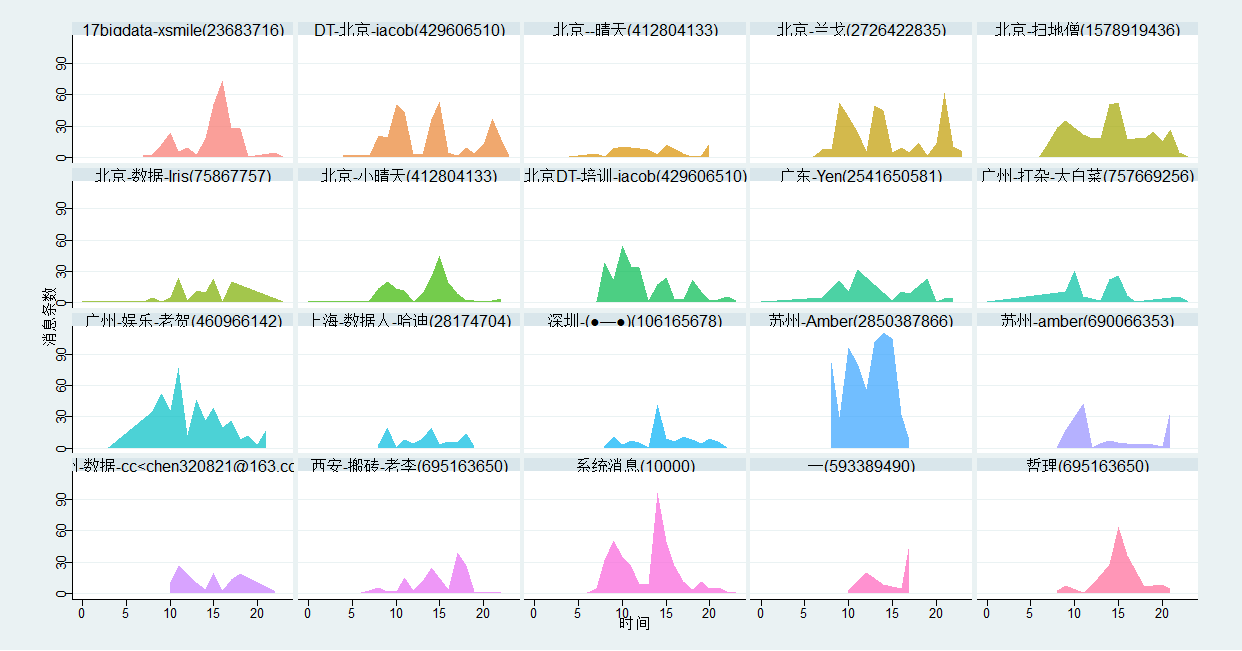
(抱歉,并未给大家打上马赛克)那么这些前20又喜欢在什么时候发言呢?
事实上,他们的发言量占据了52.13%
> head(sum(top20$Freq))/sum(all$Freq)[1] 0.5213432
所以说互联网上的的幸存者偏差严重吧?占据了一半的数量。我们注意到系统消息占据第四,所以刨掉系统消息
> head(sum(top20$Freq[-4]))/sum(all$Freq)[1] 0.47786
前20名仍然占据着消息流量的47.786%我想,知乎大概也是一样的,占据言论主导权的,基本上是敢于发言,有能力输出文字和表达的人吧? 何不食肉糜之类的问答屡见不鲜, 所以说知乎上的收入高么?我相信,如果没有知乎,不少所谓大V他们的收入可能要下降一个档次呢。
- 四、聊天微观(3)——英雄惜英雄,扼腕于墓道也
忆得歌翻肠断句,更惺惺言语大V抱团,跟英雄所见略同,英雄惺惺相惜,大概是一个道理然, 庄王未绝弦, 季子仍佩剑,不能墓道 扼腕 , 发其志士之悲,不过鸟兽尔# 前10名之间的关系(毕竟人多嘴杂,咱还是少分析点)说英雄谁是英雄,英雄惺惺相惜前10的社交网络关系
# 前10名之间的关系data$group <- groupdfName <- as.data.frame(table(data$Name))#前20名活跃的群成员names(dfName)[1]="Name"top10 <- dfName[order(dfName$Freq, decreasing = TRUE),][1:10,]head(top10)class(top10$Name)library(stringr)library(plyr)library(reshape2)library(igraph)netdata <- dcast(data, Name~group, sum,value.var='group',subset=.(Name %in% as.character(top10$Name)[1:10]))#value.var=指定值是来自group#subset=.指定来自子集netdata1 <- ifelse(netdata[,-1] > 0, 1, 0)#newdata1[,-1]就是去掉了ID后的rownames(netdata1) <- netdata[,1]relmatrix <- netdata1 %*% t(netdata1)# 很容易看出哪两个人聊得最多deldiag <- relmatrix-diag(diag(relmatrix))which(deldiag==max(deldiag),arr.ind=T)# 根据关系矩阵画社交网络画g <- graph.adjacency(deldiag,weighted=T,mode='undirected')g <-simplify(g)V(g)$label<-rownames(relmatrix)V(g)$degree<- degree(g)layout1 <- layout.fruchterman.reingold(g)egam <- (log(E(g)$weight)+1) / max(log(E(g)$weight)+1)V(g)$label.color <- rgb(79,148,205, 255,max = 255) #字体的颜色V(g)$label.degree <- piV(g)$label.dist <- 1.5V(g)$frame.color <- 'springgreen4' #圈子的颜色V(g)$shape <- 'sphere'V(g)$label.cex <- 0.7E(g)$width <- egamE(g)$color <- rgb(255, 181, 205, egam*255,max = 255)#线的颜色plot(g, layout=layout1,vertex.color= rgb(255, 181, 205, 197,max = 255))
效果如下:
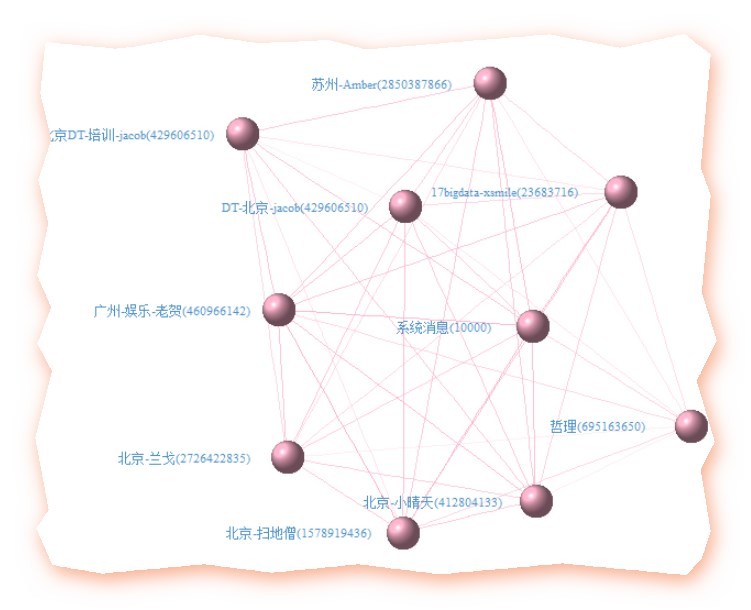
- 五、昵称(1)——我们曾经的非主流
打开你的QQ空间/人人/豆瓣,我们发过的内容和去过的昵称,谁没有非主流过呢?QQ群昵称的分析,分解下用户的群昵称由于许多群会要求大家修改备注为城市,职业,这样就可以看看大家所在地和行业分布当然,也有一些人是不改的
#提取用户名部分dfall <- as.data.frame(table(data$Name))names(dfall)[1]="Name"allUserFreq<- dfall[order(dfall$Freq, decreasing = TRUE),]write.csv(allUserFreq,"Users.csv")#设计数据框dataQQ <- data.frame(user_QQ = c(),nikename = c())user_QQ <- character()nikename <- character()#提取出昵称(群昵称)pattern2 <- '\\([0-9]{5,11}\\)'for(i in 1:length(allUserFreq$Name)){str <- as.character(allUserFreq$Name[i])reg <- regexpr(pattern2,str)qq_begin <- reg+1qq_end <- reg+(attr(reg,'match.length')-1)-1user_QQ <- substring(str,qq_begin,qq_end)# browser()nikename <- substring(str,1,reg-1)dataQQ <- rbind(dataQQ,data.frame(QQ = user_QQ,nikename = nikename))}dataQQwrite.csv(dataQQ,"QQ.csv")#保存一下
分词
#分词library(Rwordseg)library(tmcn)library(tm)#写出又读入write.table(dataQQ$nikename,"QQ.txt",row.names = F)segmentCN("QQ.txt",returnType="tm")nikename_text=readLines("QQ.segment.txt",encoding = "UTF-8")word = lapply(X = nikename_text, FUN = strsplit, "\\s")word1=unlist(word)#统计词频dfname=table(word1)dfname=sort(dfname,decreasing = T)head(dfname)#把词汇词频存入数据框namedf = data.frame("word" = names(dfname),"freq" = as.numeric(dfname))# 过滤掉1个字和词频小于10的记录d <- subset(namedf,nchar(as.character(namedf$word))>1 & namedf$freq >= mean(dfname))#加载包和清洗后的数据library(wordcloud2)head(d)wordcloud2(d, size = 1, shape='star',color = 'random-dark',backgroundColor = "white",fontFamily = "微软雅黑")write.csv(d,"分词1.csv")
出图如下:

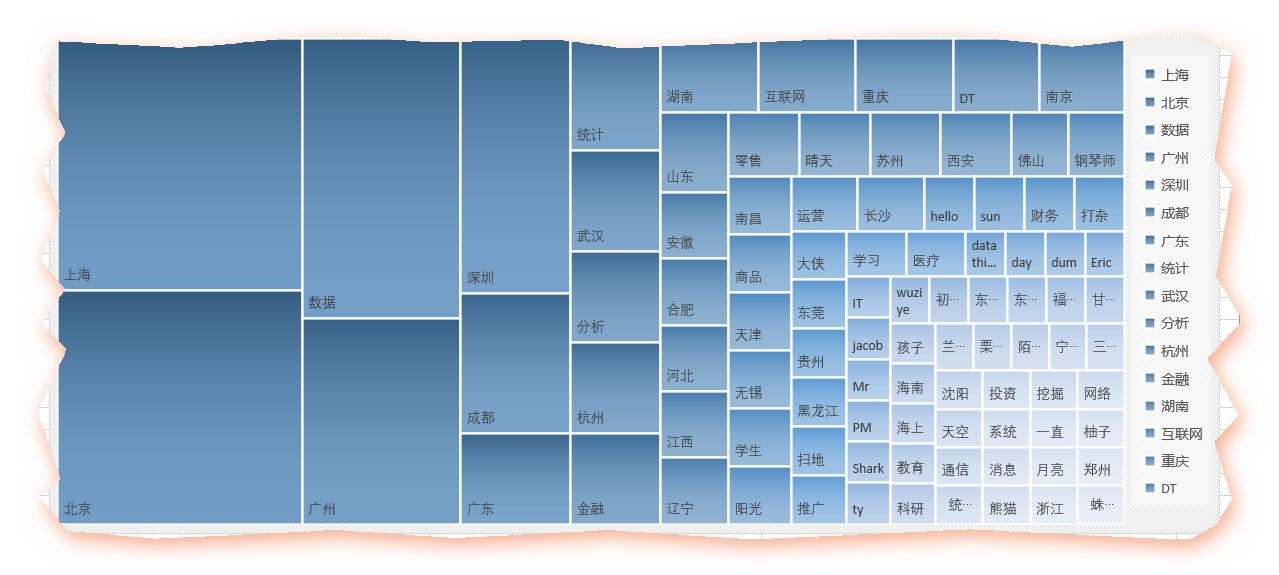
北上广深等主要城市赫然在列,其他主要省会城市也都不少。
而数据、互联网、金融这三个行业关键字也身在其中(真是到哪都能看见既然你),果然这是近两年很火爆的行业,尤其是数据,而零售、商品等行业也在列。统计、运维、DT、学生等职业信息也是一样的。
鉴于很多人的群昵称乱写,或者喜欢填一些奇怪的表情或符号,所以很可能在分词的失衡没有解析出来,变成空的,这个很难用代码去操作了,只能人为的 删掉了那么几个,得到如下的excel

容我偷个懒,用excel做两张图前8个关键字就占据了一半
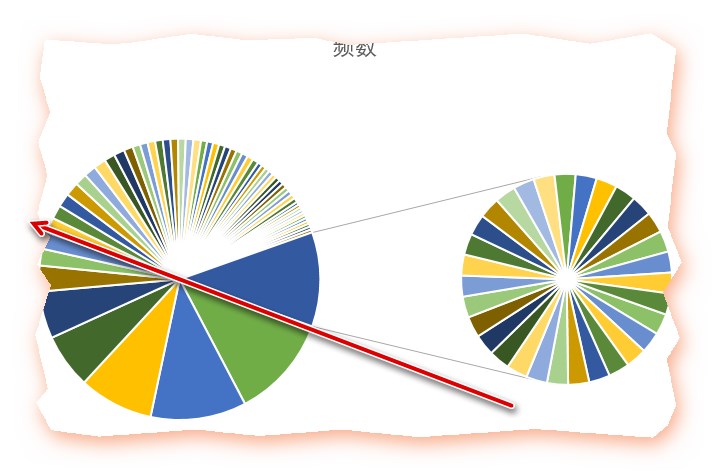
图1
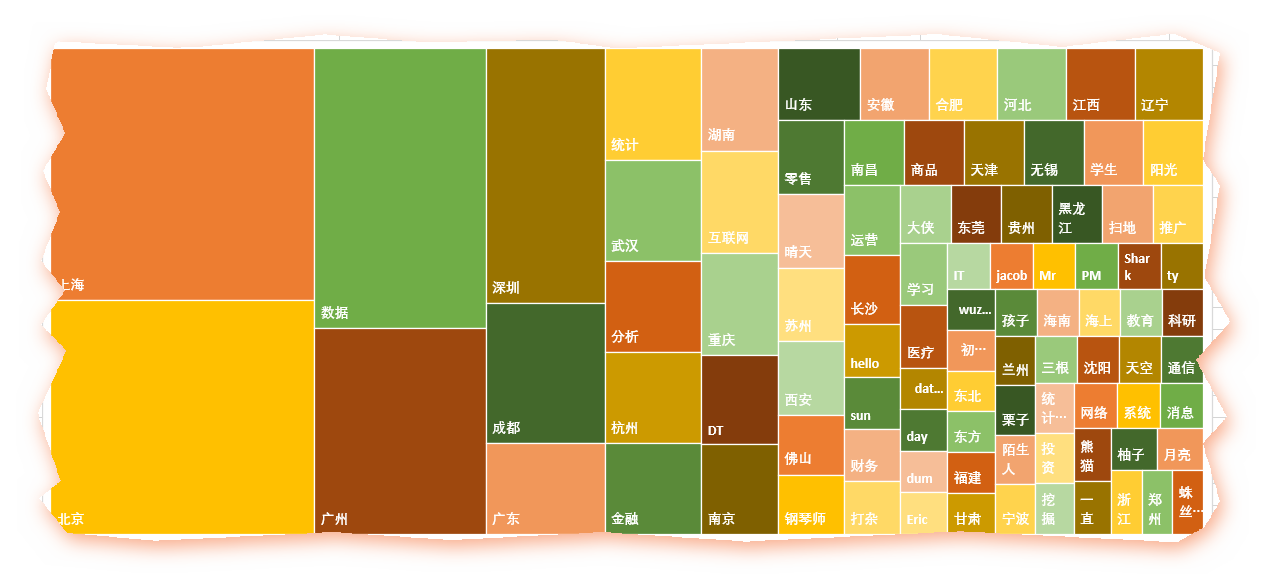
图2
- 五、昵称(2)——所爱隔山海啊~
一望可相见,一步如重城。所爱隔山海,山海不可平
为了表示群里来自五湖四海的基友们互相之间满满的基情,我也只有这么肉麻他们了取出里面所有的地名然后作图
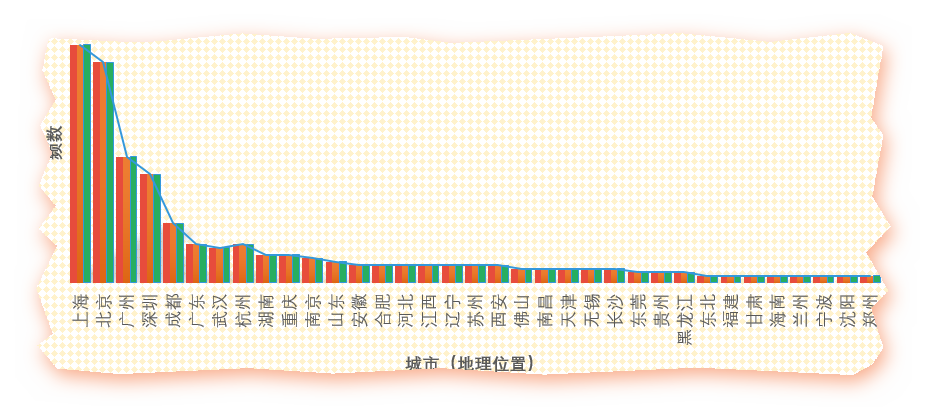
不行不行还是不能偷懒
偷懒可以用地图慧——:领导,您办公室的地图已经到货了,这就给您挂上:什么?怎么少了高丽行省?
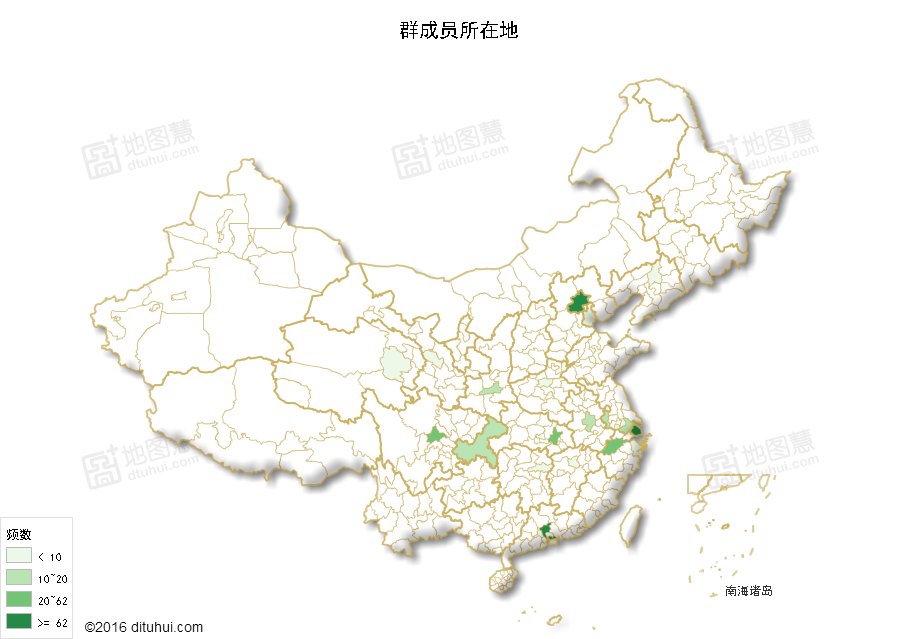
我都懒得去水印!但是!
鉴于REmap不能识别省分和城市混排的,所以我就全部合并为省份
所以我整理了下数据,将之合并为省份
library(REmap)mymap <- read.csv("city.csv",header=T)head(mymap)remapC(data=mymap,title='群成员分布图',maptype = "china",color=c('#CD3333'),theme=get_theme("Bright"))
其中REmap(在github上)的安装方式为:
library(devtools)install_github('lchiffon/REmap')
这样不就实现大和谐了嘛?
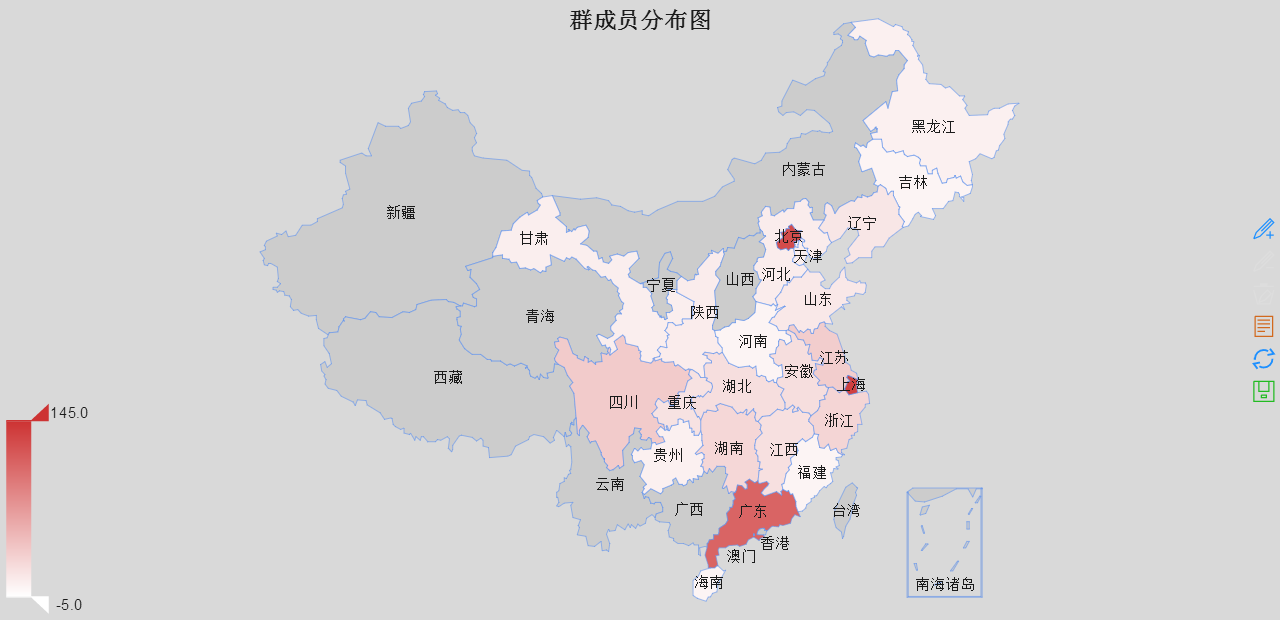
北上广(深圳被合并在广)依然遥遥领先,当然,这仅是填写了城市的数据,并不能反映全部,感觉主要还是在高校聚集区相对容易出现从业人员集中现象,遗憾的是浙江和江苏未能扛起东部的大旗,而西部的四川遥遥领先,贵州喊了几年大数据,大概也有点从业人员?比起西部几个省也算不太打脸了。
广东省各个市的数据
gd <- read.csv("guangdong.csv",header=T)remapC(data=gd,title='广州群成员分布图',maptype = "广东")
注意要在每个市后面加“ 市 ”字,否则无法识别,比如说要写深圳市,而不是深圳。我们还是搞一个美食地图吧。。。
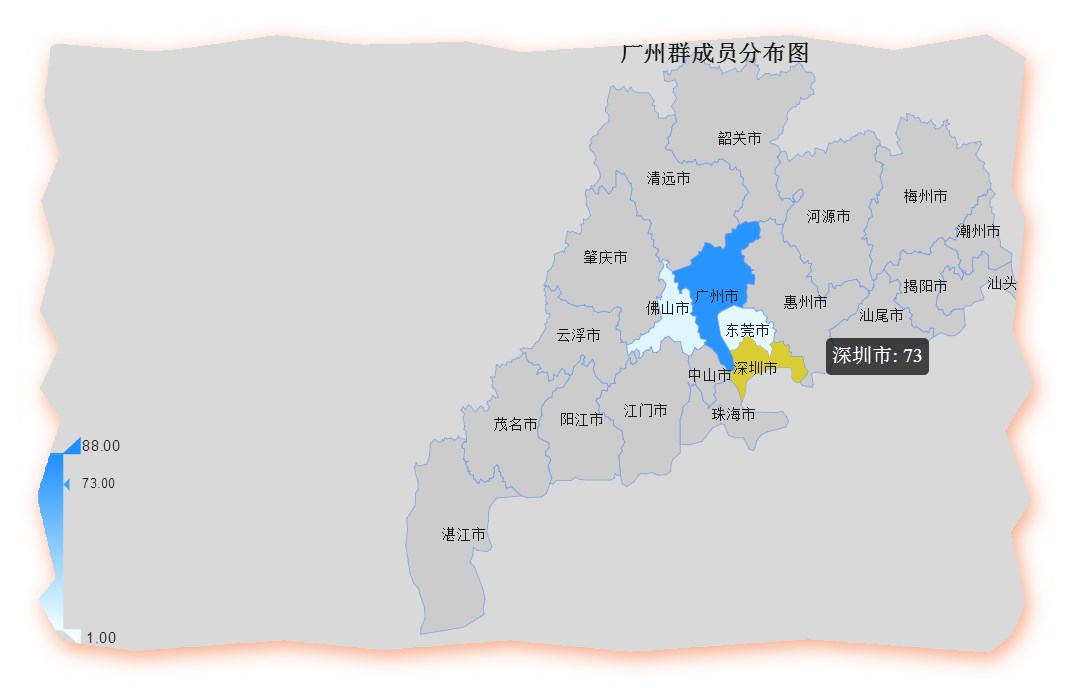
数据如下: 广州的发展水平的区域差异可见一斑,貌似广州的从业人员比深圳的还多点。比如我还可以看看北上广深各自是那些人最活跃,选出区域明星,不过我真的没力气倒腾了。
广州的发展水平的区域差异可见一斑,貌似广州的从业人员比深圳的还多点。比如我还可以看看北上广深各自是那些人最活跃,选出区域明星,不过我真的没力气倒腾了。
- 六、内容分词——爱在心口难开,你我之间隔了正无穷个表情包
就你图多系列,你们到底有多喜欢喜欢发图和表情呢?连这群基佬们都不能例外
看看大家都用喜欢聊些什么
library(Rwordseg)library(tmcn)library(tm)#群消息分词#分词write.table(data$text,"text.txt",row.names = F)segmentCN("text.txt",returnType="tm")text1=readLines("text.segment.txt",encoding = "UTF-8")word = lapply(X = text1, FUN = strsplit, "\\s")word1=unlist(word)#统计词频df=table(word1)df=sort(df,decreasing = T)# 把词汇词频存入数据框df1 = as.data.frame(df)# 转为数据框的时候中文开始抽风,也是奇怪的很(变成/u的形式)# 这种情况不定期出现,所以我干脆在这部分写了重新导入数据head(df1)#对列命名datafreq <- data.frame(word = as.character(df1$word),freq = df1$Freq,stringsAsFactors = F)
#过滤掉数字或者3个以下的字母a <- integer()for(i in 1:dim(datafreq)[1]){dreg <- regexpr('^[0-9]{1,15}$|^[a-zA-Z]{1,3}$',datafreq[i,1])if(dreg == 1)a <- c(a,i)}datafreq <- datafreq[-a,]#去掉频率低于均值的mean(datafreq$freq)datafreq <- datafreq[datafreq$freq >= mean(datafreq$freq),]
wordcloud2(datafreq, size = 1, shape='star',color = 'random-dark',backgroundColor = "white",fontFamily = "微软雅黑")

看到了吧?这么多表情和图片,这么多单个的无意义的词,我们还是在后面删掉好了
先删除最多的那四个单个汉字
head(datafreq)#删去1:4这几个单词的汉字wordcloud2(datafreq[-seq(1:4),], size = 1, shape='star',color = 'skyblue',backgroundColor = "white",fontFamily = "微软雅黑")

表情跟图片真是派大星的两个大盾牌啊.... 该配合我演出的演出的时候你视而不见,绵宝宝,我是你的派大星...注意,skyblue是可以的,但是skyblue1....后面加上数据就不行啦
#删掉单个汉字
aa <- integer()for(i in 1:dim(datafreq)[1]){dreg <- regexpr('^[\u4e00-\u9fa5]{1}$',datafreq[i,1])if(dreg == 1)aa <- c(aa,i)}datafreq2 <- datafreq[-aa,]wordcloud2(datafreq2, size = 1, shape='star',color = 'yellow',backgroundColor = "white",fontFamily = "微软雅黑")head(datafreq2)

派大星应该是这个颜色才对(在太阳下脱水晒晒之后)那么,你是玩游戏输了贴纸条变僵尸?
#去掉图片和表情
a <- datafreq2[c(-1,-2),]awordcloud2(a, size = 1, shape='star',color = 'random-dark',backgroundColor = "white",fontFamily = "微软雅黑")

哦,这是基佬们的表白墙啊~
“数据”占据最大头,可见聊天内容还是正常的,处在业务范围呢,
当然,"签到"这种无聊的行为占据大头,“问题”关键字还没法超过他,也是有点无语, 毕竟大家的目的是交流学习,而不是灌水。
“加入”说明信任还是不少的,
excel,spss的关键字也出现了,其他一些专业词汇也不少,大家自己看吧
当然,有趣的是,“工资”也出现了,说明大家还是会在群里吐槽下工资水平的。
“简单”这两个字出现的频率还不算太高,不然的话是很糟糕的,个人觉得,有问题就回 答问题不要装逼嘲笑新手,
#以下部分纯属娱乐。(感觉不准确)
#图标放在 D:\RSets\R-3.3.2\library\wordcloud2\examples
安卓图标

360图标

QQ图标

最后要感谢这么多人提供这么多资料和工具,帮助我完成这篇消遣之作所有代码:
主要参考:
http://www.cnblogs.com/NaughtyBaby/p/5497714.html
https://zhuanlan.zhihu.com/p/25171755
null
附件列表