Title: Mitigating knowledge imbalance in AI-advised decision-making through collaborative user involvement
From: International Journal of Human - Computer Studies
Link: https://doi.org/10.1016/j.ijhcs.2022.102977

目录
- 1 绪论
- 2 方法
- 2.1 假设
- 2.2. 实验任务及研究设计
- 2.3. 评估
- 3.实验结果
- 3.1对于知识失衡的验证
- 3.2 用户对AI建议的回应分布
- 3.3 在与AI交互时,不同级别的用户参与是否会影响非专家用户对AI建议的认同?
- 3.4 在与AI交互时,不同程度的用户参与是否会影响非专家过度信任和过度信任的发展?
- 3.5.不同的交互模式如何影响用户对联合决策的贡献?
- 4.结论
本文介绍一篇近期发表在International Journal of Human - Computer Studies上的利用用户协作参与来缓解人工智能(AI)决策中的知识失衡问题。在决策任务中,AI系统试图通过增强或补充用户的能力来提供帮助,并最终提高任务性能。但是对用户来说,当接收到“黑盒模型”的建议时,用户仍面临着接受或者推翻AI建议的决定。当用户和AI系统之间存在严重的知识失衡时,即当人们缺乏必要的任务知识,因此无法准确地独自完成任务时,做出这些决定就更具挑战性。
在该论文里,作者旨在了解人们在面临知识失衡挑战时在人工智能辅助决策任务中的行为,并探索让用户参与人工智能的预测生成过程是否会让他们更愿意遵循人工智能的建议,并增强他们的协作感。实证研究表明,在具有显著知识失衡的任务中,用户参与生成AI推荐会使他们更信任AI,更认同人工智能的建议。
1 绪论
人工智能驱动的系统可以帮助人类完成现实世界中的任务,或者向人类提供推荐,人类用户负责做出最终决定,这种情况通常称为人工智能建议下的人类决策(AI-advised human decision-making)。
人机合作的成功取决于多个方面,例如AI给出建议的时机——在人类决策前先展示其预测正确性会影响人对AI的信任度;更重要的是,用户自身的水平和专业知识也会影响人机交互——新手用户更有可能盲目遵循AI的建议从而产生自动化偏见(automation bias),进而影响决策。在理想情况下,专家用户会参与关键决策,但在实践中很难保证专家随时有空,而且可用于培训专家的资源有限。因此,在人机交互过程中,很有可能AI系统比用户具有更高的准确性,作者把这种情况称为知识失衡(knowledge imbalance)。例如,在AI系统辅助人类进行一些对人类来说很棘手、没有明确解决方向的任务时,可以看到巨大的知识失衡现象。
在知识不平衡的环境中, AI-advised human decision-making面临着巨大挑战。因为即使是高质量的机器学习模型,在意外的数据变化下也容易做出错误的决策。而外行可能无法识别AI何时做出正确或错误的建议,因此可能会采用简单且协作性较差的启发式方法。最常见的AI-advised human decision-making范式包括AI给出建议,用户决定是否遵循建议。这种单向交互不允许用户向模型提供任何输入,无论是细化其输出、提供附加标签还是以另一种方式改进它。在这种单向交互中,如果AI系统足够准确,用户如果接受其所有建议,就可以实现卓越的任务性能,但这种情况下,用户无法在决策过程中积极感知自己与AI的互动。或者,用户可能会拒绝AI的所有建议,并发现自己面临着不理想的任务结果。
受到人在回路(Human-in-the-loop)方法的启发,在这项工作中,探讨了当人类和人工智能主体之间存在显著的知识失衡时,互动在人工智能建议的人类决策中的作用;具体来说,让用户提供他们可以从任务中理解的信息,作为指导人工智能模型预测的特征。该文的中心假设是,让用户作为积极贡献者参与生成人工智能建议的过程,可以缓解知识失衡带来的挑战。
2 方法
本节描述了所进行的用户研究,以了解缺乏实验任务必要知识的人如何使用AI系统来完成该任务。
2.1 假设
该文研究了在知识失衡条件下,人机联合决策的不同范式如何影响信任校准、信任行为指标和用户对AI的感知,并提出了以下假设:
- 假设1:当参与者更多地参与到与AI的互动中时,他们将越来越多地遵循AI的建议,而不是仅限于直接向AI寻求建议。
- 假设2:当参与者更多地参与人工智能交互时,他们区分何时信任或不信任AI的能力会提高(即,他们不太容易受到过度信任和不信任的影响)。
- 假设3:对AI的信任发展将反映在用户与AI交互过程中的行为中。与H1相关,当用户更多地参与与AI的交互时,信任的行为指标会增加。
- 假设4:当用户更多地参与互动时,他们对AI的信任、合作和能力的感知将得到改善。
2.2. 实验任务及研究设计
为了验证假设,作者设计了一项用户研究,要求参与者在AI的帮助下完成基于图像的鸟类分类任务。图像来自UCSD Birds 200数据集。
作者仔细选择了与不常见鸟类相对应的图像,所描绘的鸟类的名称与它们的外表无关,以避免给参与者额外的线索(如图1)。另外,所选择的每张图像只包含一只鸟。

作者设计了三种具有不同用户参与水平的交互范式(如图2所示),以探索在具有高度知识失衡的任务中人工智能辅助决策:
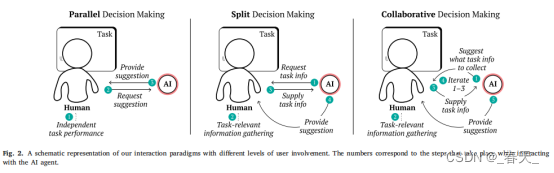
①并行决策Parallel decision-making (PDM)
该范式代表了传统的人机交互,其中用户和AI并行做出决策;AI仅根据请求提供建议。在作者的实现中,用户在在单独处理任务(例如,查看任务图像)后请求AI推荐。这种模式通常应用于累犯司法援助、风险评估和辅助医疗诊断等领域。
②分开决策Split decision-making (SDM)
在这种范式中,用户和AI共同分担决策的工作;例如,用户可以根据他们对任务的理解来准备任务相关信息,以便AI进行推荐。在作者的实现中,向用户展示了一张任务图像,并要求用户描述他们认为相关的鸟类的物理特征(例如,身体部位的颜色和图案),以便AI模型做出准确的预测。如果需要,AI可以要求额外的输入。一旦用户描述了至少三个物理属性,AI就会建议与所提供的属性相对应的鸟类类别。
③协同决策Collaborative decision-making (CDM)
在这种模式下,用户和AI通过迭代AI提供最终预测所需的任务相关信息,在整个决策过程中更紧密地合作。在作者的实现中,AI提出了哪些属性与用户描述最相关,并根据用户的输入做出了最终的鸟类类别建议。如果需要,AI可以要求额外的输入。一旦用户输入了至少三个属性,AI就会提出该鸟所属类别的建议。这种范式与SDM形成对比:SDM中用户和AI轮流为决策任务做出贡献。
- 实验过程
在PDM交互模式中,参与者只需在查看任务图像后点击“询问AI助手”按钮,请求AI的推荐,如图3所示。
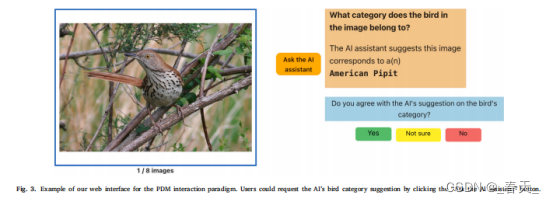
对于SDM和CDM交互模式,参与者首先必须通过从下拉菜单提供的一组固定选项中选择相关的物理属性(来自十八个身体部位和颜色、图案和形状特征)及其相应的值来描述所呈现的图像中的鸟;他们在描述图像时可以访问详细的鸟的部分信息。一旦他们选择了身体部位、特征和值,他们就可以一次一个地将属性添加到当前的累积描述中,如图4所示。AI可以要求用户描述更多鸟的物理属性,以提供最终类别(见图4中右上角的框)。

- 实验细节
为了模拟真实的分类模型,AI给出的鸟类分类建议是预先确定好的,总体分类准确率为63%(24张图像中有15张),这对所有交互范式都是一样的(即,对8张图像,有5个正确预测和3个不正确预测)。
在受试者内部设计中,每个参与者都接触到所有三种互动范式。交互模式的顺序和每个条件下分配的图像是随机的。在上述三种交互模式中,AI推荐的鸟类类别后,会询问用户是否同意该推荐;参与者从三个回答中选择:是、不确定或否。
2.3. 评估
该文使用了一组客观和主观指标来了解当合作方之间存在高度知识失衡时,人们如何与AI交互。客观指标旨在捕捉参与者与AI的一致程度,他们对AI建议的信任是否得到了适当的校准,以及是否存在与信任AI相关的行为。观指标旨在捕捉参与者在完成任务时对AI的感知。指标包括:
与AI的一致性。 使用了参与者关于他们是否同意AI提出的鸟类类别建议的最终答案;答案选项为:是、否和不确定。
过度信任和信任不足。 当用户对不正确的建议回答“是”时,决策会导致过度信任,而当用户对正确的建议回答“否”或“不确定”时,则会导致不信任。每个变量(过度信任或过度信任)是二元的;即用户对AI对每个图像的推荐进行了过度/不充分信任。
信任的行为指标。 作者定义了两个指标,第一个指标比较SDM和CDM条件下每个图像的最终描述中包括的鸟类属性的数量。第二个指标是用户提供的最终描述中最初由AI在CDM范式中建议的物理属性的百分比。
决策时间。 测量的决策时间是从AI的预测出现到参与者选择同意或不同意的最终反应的时间。
**其他主观指标。**发放问卷进行调查,使用Likert量表进行评分。
3.实验结果
该文对每个二分变量使用混合效应模型来解释参与者水平的效应和重复测量的实验设计。同样,对于连续变量,使用了单向重复测量方差分析(ANOVA)模型。所有事后配对比较都是使用带有Bonferroni校正的成对配对t检验进行的,报告了调整后的p值。当比较涉及两组时,使用配对t检验。分别用Shapiro-Wilke和Levene检验检验方差的正态性和同质性假设,并使用四分位间距确定异常值,去除统计检验的极值。
3.1对于知识失衡的验证
为了验证人工智能系统和人类参与者之间存在很大的知识差距,该文对参与者的鸟类类别知识进行了研究前测试,其中正确识别的鸟类的平均数量为0.79只。用户对“如果没有AI,我就无法成功完成任务”这一说法的高度认同。此外,在实验期间,没有向用户提供任何关于AI性能或每次试验正确性的培训或即时反馈,以防止参与者进行学习。
3.2 用户对AI建议的回应分布
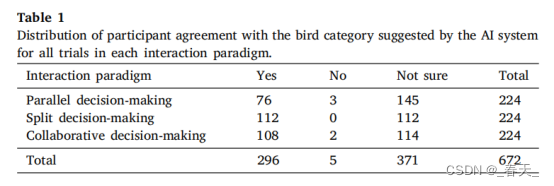
在总共672项试验中,作者分析了用户对他们同意AI建议的反应分布(28名参与者中的每一位都有8项试验,针对三种互动模式)。表1给出了每个交互范例的响应分布和总计数。从回答的分布中观察到如下结果:
- 在PDM和CDM交互范式中,“不确定”是最常见的回答,其次是“是”,然后是极少数的“否”。在PDM交互范式中,参与者回答“是”的可能性小于回答“不确定”的可能性;
- 在SDM交互范式中,“是”和“不确定”的回答数量相等,用户在任何试验中都没有回答“否”。
- 在所有三种交互范式中参与者几乎没有回答“否”,可能是因为他们最初对鸟类分类知之甚少。
因此,在以下分析中,作者将“否”和“不确定”的回答结合起来,表示不同意AI的建议,而“是”的回答表示同意;换句话说,该研究认为同意AI建议是一个二元因变量。
3.3 在与AI交互时,不同级别的用户参与是否会影响非专家用户对AI建议的认同?
表2显示了混合效应逻辑回归的详细结果(因变量[DV]:用户反应是否与AI一致;自变量[IV]:交互范式PDM、SDM或CDM),其中PDM范式被设置为基线组。
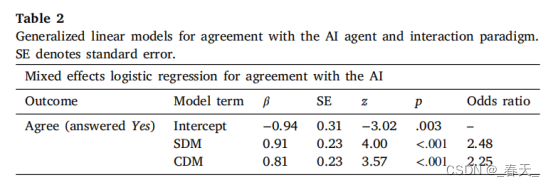
结果表明,SDM和CDM交互范式对用户与AI的一致性有显著的积极影响,表明参与者在这些条件下比在PDM交互范式下更可能与AI达成一致。更具体地说,研究发现,与标准PDM相比,SDM和CDM交互范式的参与者同意AI的几率分别增加了148%和125%。
3.4 在与AI交互时,不同程度的用户参与是否会影响非专家过度信任和过度信任的发展?
-
过度信任
为了评估过度信任,只考虑了AI提供错误建议的试验,即每个交互范式中八个试验中的三个,即总共252个试验。表3总结了回归的详细结果。
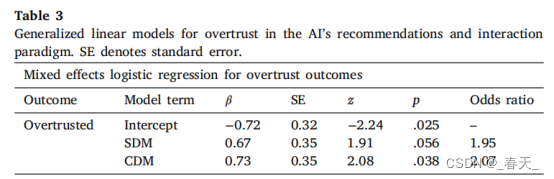
作者观察到SDM(41/84过度信任试验)和CDM(42/84过度信赖试验)相互作用范式对AI过度信任有积极影响,但与PDM范式相比较,只有后一种影响是显著的。这一发现表明,与标准PDM范式相比,CDM交互范式的参与者接受AI的错误建议,使其过度信任的几率高107%。
-
信任不足
为了评估信任不足,只考虑了AI提供正确建议的试验,即每个交互范式中八个试验中的五个,即总共420个试验。表4总结了回归的详细结果。
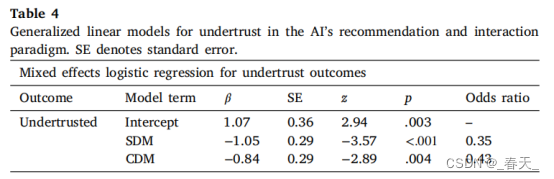
结果表明,与PDM范式相比,SDM和CDM相互作用范式的系数表明,对AI的信任不足有显著的负面影响,这意味着参与者在前一种情况下不太可能信任AI。SDM交互范式中的参与者对AI的信任不足的几率是PDM范式中参与者的0.35。同样,CDM交互范式中的参与者对AI信任不足的几率是PDM范式中参与者的0.43。这一观察结果也与参与者在SDM和CDM交互范式中遵循AI建议的可能性更高一致,无论正确性如何;由于参与者不太可能拒绝可能正确的AI建议,因此他们总体上不太可能对AI进行过度信任。
3.5.不同的交互模式如何影响用户对联合决策的贡献?
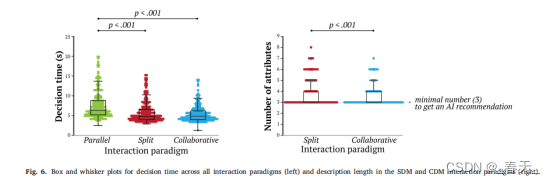
比较SDM和CDM交互范例之间提供的属性数量的配对t检验发现,在每个条件下描述的属性平均数量存在显著差异。平均而言,用户在SDM范式中描述的属性比在CDM范式中更多,如图6所示。此外,在CDM范式中,参与者平均遵循AI关于描述哪些属性的270条建议,这些建议平均占最终鸟类描述中存在的属性的84.44%。
4.结论
当存在知识失衡时,人与机器的交互设计尤其具有挑战性。以前的研究表明,当用户缺乏领域专业知识时,提供解释的益处会减少,因为他们无法提取任何有意义的见解,并且即使在简单的任务中,提供额外的信息也会误导用户,或者可能无法提高信任或绩效。研究结果表明,让用户参与决策过程,赋予他们积极的角色,有可能增强用户对人工智能系统的感知,但适当调整他们对成功团队合作结果的信任仍然是一个挑战。
该解读首发于CS conference 公众号。