pandas在处理Excel/DBs中读取出来,处理为DataFrame格式的数据时,处理方式和性能上有很大差异,下面是一些高效,方便处理数据的方法。
- map/apply/applymap
- transform
- agg
- 遍历
- 求和/求平均
- shift/diff
- 透视表
- 切片,索引,根据字段值取数据
数据准备:
import pandas as pd
from datetime import date
import numpy as np
begin_date = date(2023, 3, 1)
end_date = date(2023, 3, 7)
time_list = [d_date.date() for d_date in pd.date_range(begin_date, end_date)]
print(time_list)
# 小黄,小红,小绿三个员工,3月1号到7号之间的销售额数据
df2 = pd.DataFrame({'name': ['小黄', '小黄', '小黄', '小黄', '小黄', '小黄', '小黄', '小红', '小红', '小红', '小红', '小红', '小红', '小红', '小绿', '小绿', '小绿', '小绿', '小绿', '小绿'], 'd_date': [*time_list, *time_list, *time_list[:6]], 'value': np.random.randint(500, 5000, size=20)})
- map/apply/applymap的用法介绍
# 计算每个员工,在当天的总销售额的占比
sell_money_sum_s = df2.groupby('d_date')['value'].sum()
df3 = sell_money_sum_s.reset_index().rename(columns={'value': 'sum'})
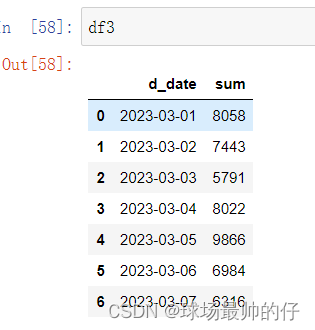
df4 = pd.merge(df2, df3, on='d_date', how='left')
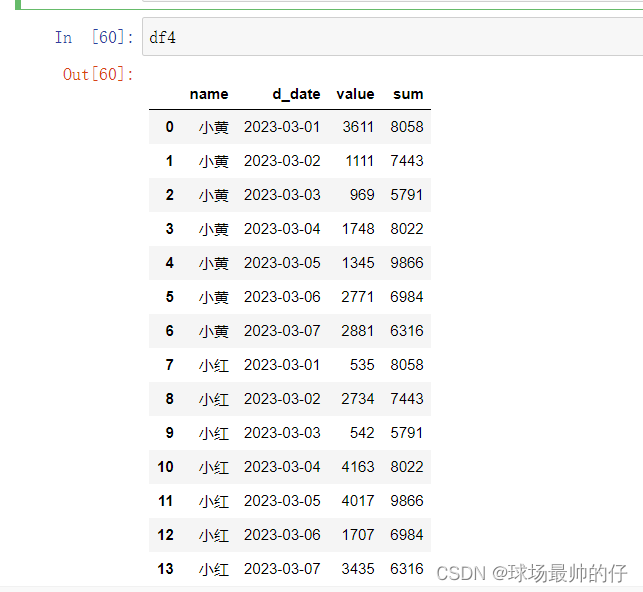
df4['ratio'] = df4['value'] / df4['sum']
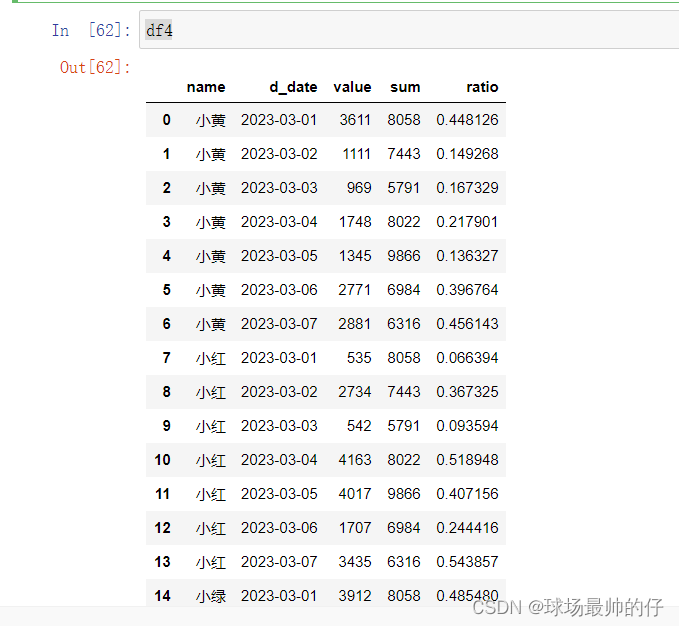
# Series.map:针对列元素进行操作,处理完之后还是返回一个Series
# 将销售额占比格式化成百分数并保留两位小数
df4['ratio_percent'] = df4['ratio'].map(lambda x: '%.2f%%' % (x * 100))
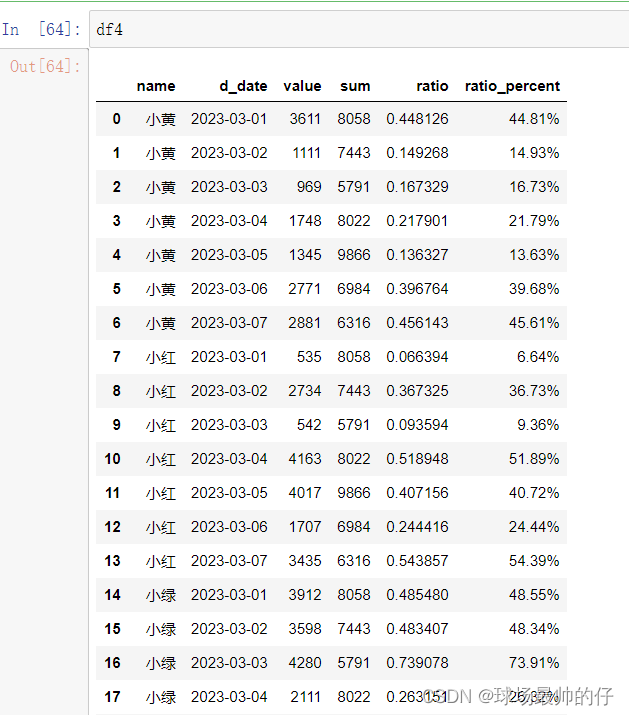
# apply:对DataFrame的多列进行操作
# 对每个元素进行以万元为单位进行展示
df4[['value(万元)', 'sum(万元)']] = df4[['value', 'sum']].apply(lambda x: x / 10000)
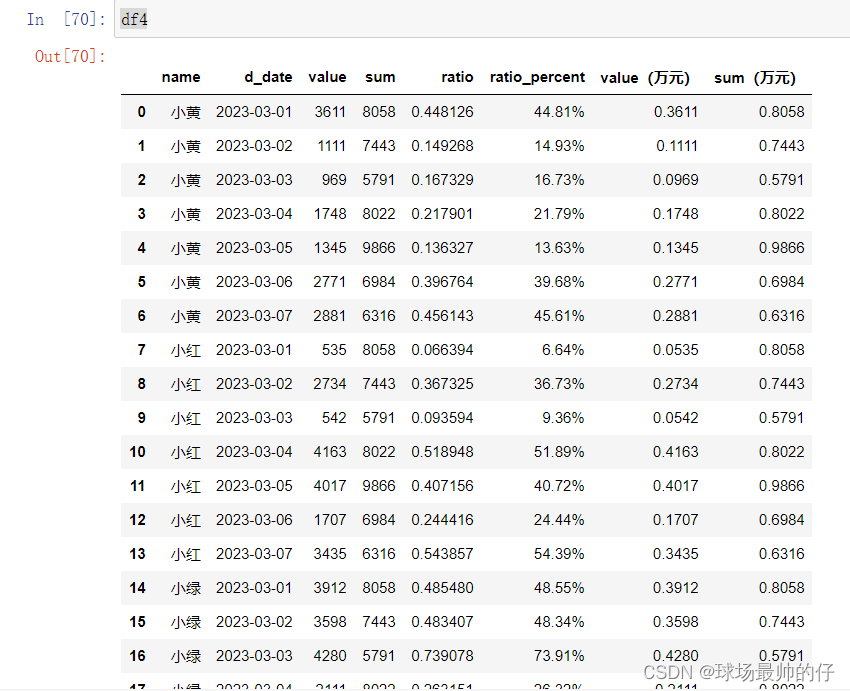
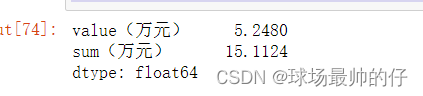
# 将销售数据(万元),按列汇总,使用参数axis=0
df4[['value(万元)', 'sum(万元)']].apply(lambda x: x.sum(), axis=0)
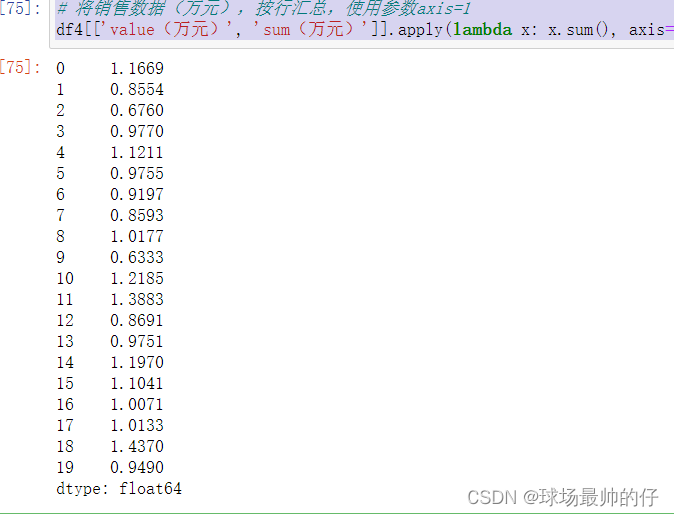
# 将销售数据(万元),按行汇总,使用参数axis=1
df4[['value(万元)', 'sum(万元)']].apply(lambda x: x.sum(), axis=1)
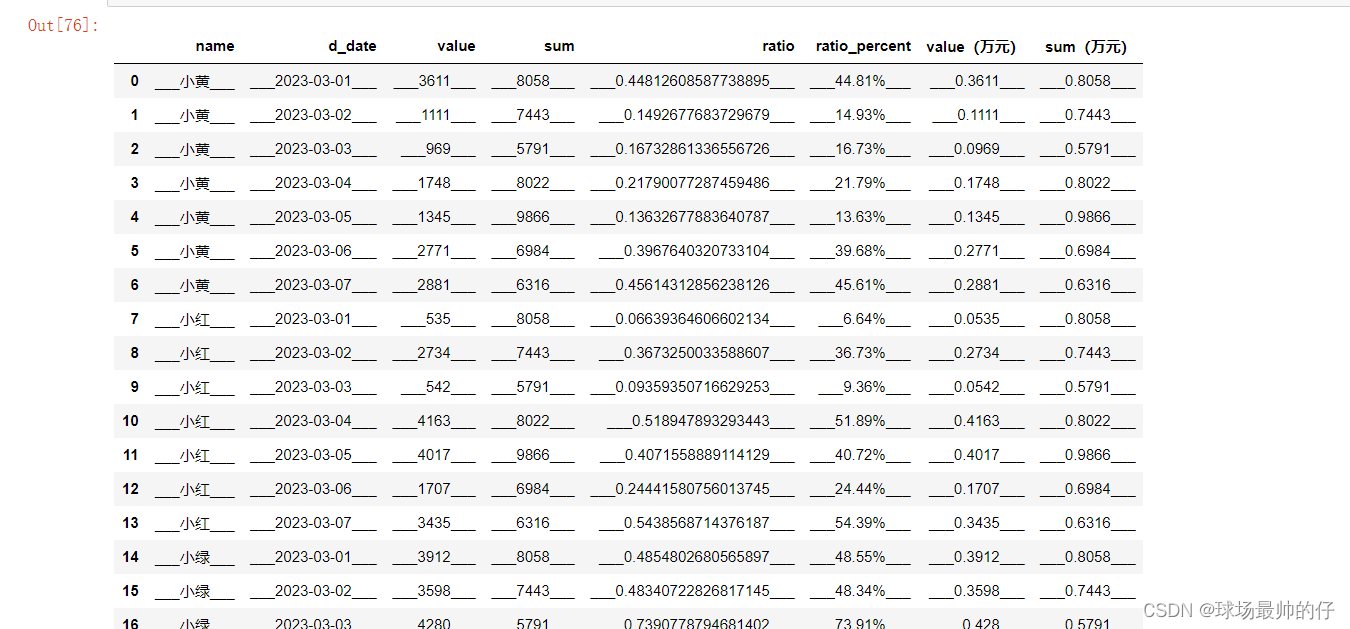
# applymap函数是df的函数,对比于Series.map,针对处理数据集中每一个元素
df4.applymap(lambda x: f'___{x}___')
2. transform
通常如果像上述那样,计算每日销售额占比数据,需要先分组求和,再通过一些字段,比如d_date,将两组数据merge,通过列计算,得到占比。但是transform有更简洁的操作。
df6 = df2.copy()
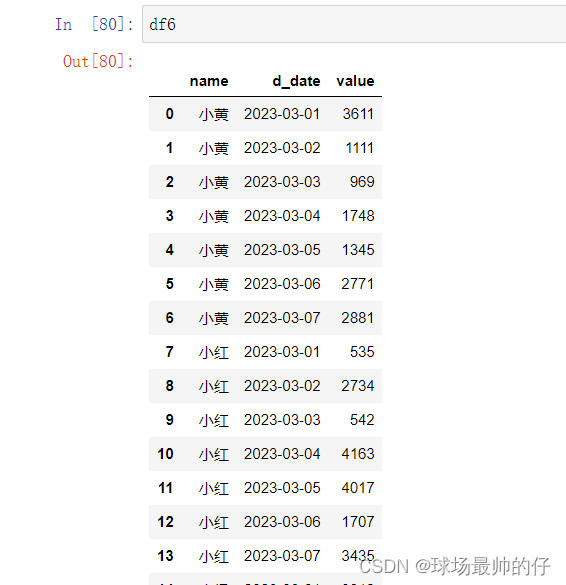
df6['sum'] = df6.groupby('d_date')['value'].transform('sum')
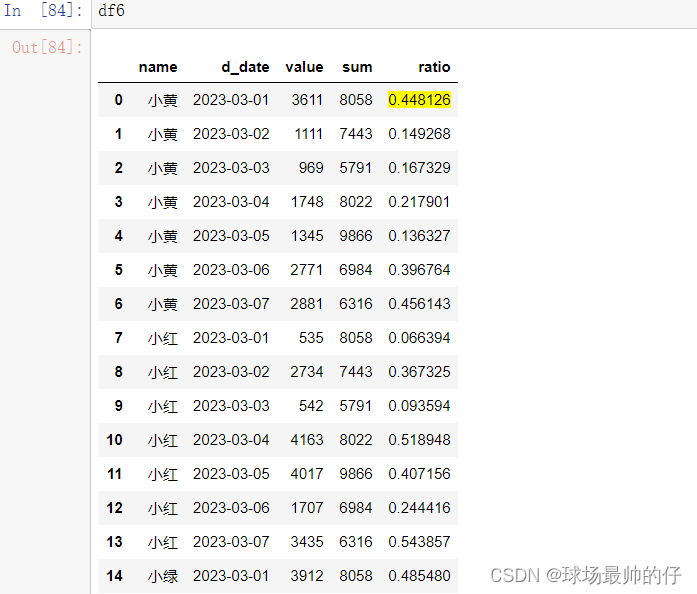
df6['ratio'] = df6['value'] / df6['sum']
可以得到每个人,每天销售额的占比情况
3. agg
在指定轴上对一列或多列进行聚合
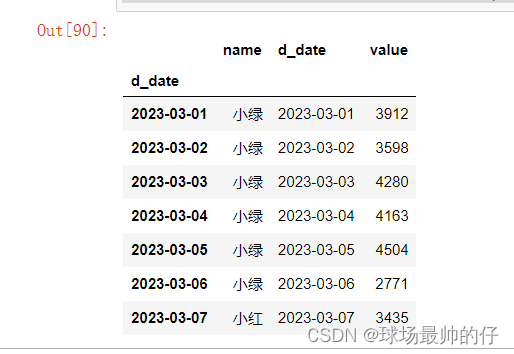
df7 = df2.copy()
# agg函数比较常见的使用场景,分组,对每组数据的聚合(求和/最大值/最小值/均值等)运算
df7.groupby('d_date').agg({'name': 'last', 'd_date': 'last', 'value': 'max'})
# agg同样可以对一列或者多列进行求和
df7['value'].agg('sum', axis=0)

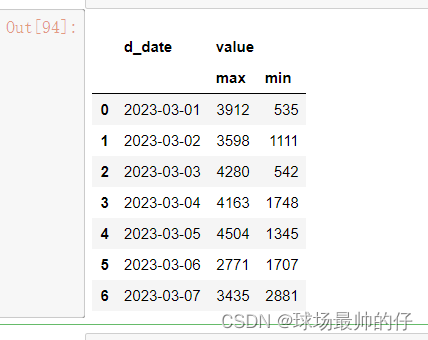
# 如果我们想一次求出每天的销售额的最大值和最小值
df7.groupby('d_date').agg({'value': ['max', 'min']}).reset_index()
4. 遍历
iterrows(): 将DataFrame迭代为(insex, Series)对。
itertuples(): 将DataFrame迭代为元祖。
iteritems(): 将DataFrame迭代为(列名, Series)对
5. 求和/求平均
数据准备:
df_sum_mean = df2.copy()
# 分组求和,只保留分组字段和求和数据
df_sum_mean.groupby('d_date')['value'].sum().reset_index()
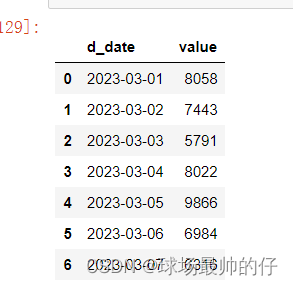
# 分组求和,保留原始记录的条数
df_sum_mean['sum'] = df_sum_mean.groupby('d_date')['value'].transform('sum')
df_sum_mean
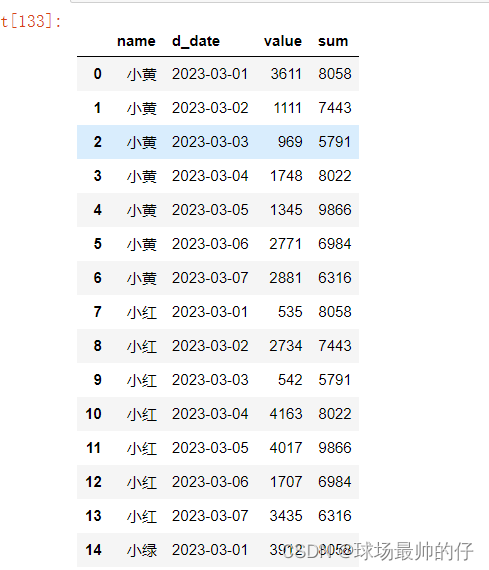
# 对多列进行聚合操作
df_sum_mean.groupby('d_date').agg({'name': 'last', 'value': 'max', 'sum': 'last'}).reset_index()
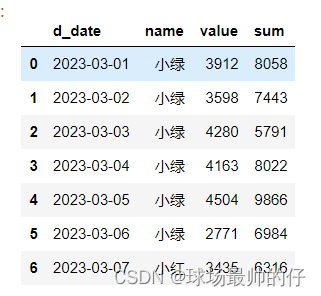
6. shift/diff
shift:可以使用shift()方法对DataFrame对象的数据进行位置的前滞、后滞移动。
语法:
DataFrame.shift(periods=1, freq=None, axis=0)
periods可以理解为移动幅度的次数,shift默认一次移动1个单位,也默认移动1次(periods默认为1),则移动的长度为1 *
periods。 periods可以是正数,也可以是负数。负数表示前滞,正数表示后滞。
freq是一个可选参数,默认为None,可以设为一个timedelta对象。适用于索引为时间序列数据时。
freq为None时,移动的是其他数据的值,即移动periods*1个单位长度。
freq部位None时,移动的是时间序列索引的值,移动的长度为periods * freq个单位长度。
axis默认为0,表示对列操作。如果为行则表示对行操作。 移动滞后没有对应值的默认为NaN。
diff:dataframe.diff()用于查找对象在给定axis上的第一个离散差值。我们可以提供一个周期值来转移,以形成差异。
语法:
DataFrame.diff(periods=1, axis=0)
periods:形成差异的时期,要进行转移。
axis:在行(0)或列(1)上取差。
数据准备:
df_shift = df2.copy()
df_sell_amount = df_shift.groupby('d_date')['value'].sum().reset_index()
df_sell_amount.rename(columns={'value': 'amount'}, inplace=True)
# 查看每日销售额相较于前一天的变化幅度
df_sell_amount['amplification'] = df_sell_amount['amount'] / df_sell_amount.shift()['amount'] - 1
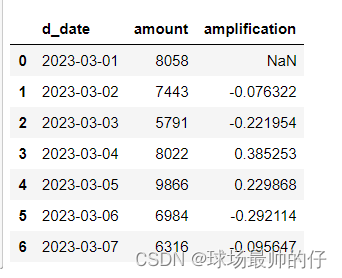
# 更简单的方法
df_sell_amount['amount'].pct_change()
透视表
切片,索引,根据字段值取数据