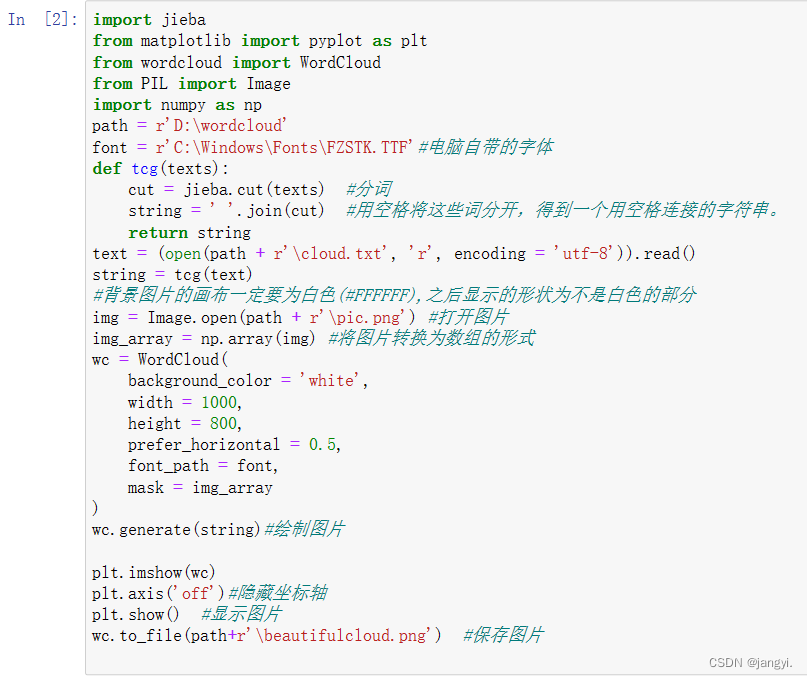
词云图wordcloud
1.安装第三方库
j i e b a 库、 m a t p l o t l i b 、 w o r d c l o u d 库 jieba库、matplotlib、wordcloud库 jieba库、matplotlib、wordcloud库
2.过程
1.使用 j i e b a jieba jieba 库对数据进行分词整理,转为 t x t txt txt文件,转变为以空格分隔的词语字符串 s t r i n g string string。
2.调用 w o r d c o l u d wordcolud wordcolud等函数绘制。
3.wordcloud的常用方法函数参数
参数:
1. f o n t _ p a t h : s t r i n g font\_path : string font_path:string : 字体路径,格式:字体路径+后缀名,
如 C : \ w i n d o w s \ F o n t \ w h i t e . t t f C:\backslash windows\backslash Font \backslash white.ttf C:\windows\Font\white.ttf
2. w i d t h : i n t ( d e f a u l t = 400 ) width : int(default=400) width:int(default=400) : 输出的画布宽度
3. h e i g h t : i n t ( d e f a u l t = 200 ) height : int (default =200) height:int(default=200) : 输出的画布高度
4. p r e f e r _ h o r i z o n t a l : f l o a t ( d e f a u l t = 0.90 ) prefer\_horizontal : float(default=0.90) prefer_horizontal:float(default=0.90) : 词语水平方向排版出现的频率,垂直方向做差。
5. s c a l e : f l o a t ( d e f a u l t = 1 ) scale : float(default=1) scale:float(default=1) : 按照比例放大画布,如设置 s c a l e = 2 scale=2 scale=2,则长宽都是原来的 2 2 2倍。
6. m i n _ f o n t _ s i z e : i n t ( d e f a u l t = 4 ) min\_font\_size : int(default=4) min_font_size:int(default=4) : 显示的最小字体的大小。
7. m a x _ w o r d s : i n t ( d e f a u l t = 200 ) max\_words : int(default=200) max_words:int(default=200) : 显示的词的最大个数。
8. b a c k g r o u n d _ c o l o r : ( d e f a u l t = ′ b l a c k ′ ) background\_color : (default='black') background_color:(default=′black′) :背景颜色。
9. m a x _ f o n t _ s i z e : i n t ( d e f a u l t = N o n e ) max\_font\_size : int(default=None) max_font_size:int(default=None) : 显示的最大字体的大小。
10. m a s k : n p . a r r a y 、 N o n e mask : np.array 、None mask:np.array、None :参数为空,默认词云形状为长方形。
函数:
1. g e n e r a t e _ f r o m _ t e x t ( t e x t ) generate\_from\_text(text) generate_from_text(text):根据文本生成词云。
2. g e n e r a t e ( t e x t ) generate(text) generate(text) : 根据文本生成词云。
3. g e n e r a t e _ f r o m _ f r e q u e n c i e s ( f r e q u e n c i e s [ , . . . ] ) generate\_from\_frequencies(frequencies[, ...]) generate_from_frequencies(frequencies[,...]) : 根据词频生成词云。
4. t o _ f i l e ( f i l e n a m e ) to\_file(filename) to_file(filename) : 输出到文件。
def generate(self, text):"""Generate wordcloud from text.The input "text" is expected to be a natural text. If you pass a sortedlist of words, words will appear in your output twice. To remove thisduplication, set ``collocations=False``.Alias to generate_from_text.Calls process_text and generate_from_frequencies.Returns-------self"""return self.generate_from_text(text)def generate_from_text(self, text):"""Generate wordcloud from text.The input "text" is expected to be a natural text. If you pass a sortedlist of words, words will appear in your output twice. To remove thisduplication, set ``collocations=False``.Calls process_text and generate_from_frequencies...versionchanged:: 1.2.2Argument of generate_from_frequencies() is not return ofprocess_text() any more.Returns-------self"""words = self.process_text(text)self.generate_from_frequencies(words)return self调用过程:
g e n e r a t e ( s e l f , t e x t ) ⇒ s e l f . g e n e r a t e _ f r o m _ t e x t ( t e x t ) ⇒ w o r d = s e l f . p r o c e s s _ t e x t s e l f . g e n e r a t e _ f r o m _ t e x t ( w o r d ) generate(self, text) \Rightarrow self.generate\_from\_text(text) \Rightarrow \\word=self.process\_text \\ self.generate\_from\_text(word) generate(self,text)⇒self.generate_from_text(text)⇒word=self.process_textself.generate_from_text(word)
实例