文章目录
- 一,案例分析
- (一)TopN分析法介绍
- (二)案例需求
- 二,案例实施
- (一)准备数据文件
- (1)启动hadoop服务
- (2)在虚拟机上创建文本文件
- (3)上传文件到HDFS指定目录
- (二)Map阶段实现
- (1)创建Maven项目:TopN
- (2)添加相关依赖
- (3)创建日志属性文件
- (4)创建前N成绩映射器类:TopNMapper
- (三)Reduce阶段实现
- (1)创建前N归并器类:TopNReducer
- (四)Driver程序主类实现
- (1)创建前N驱动器类:TopNDriver
- (五)运行前N驱动器类,查看结果
- (1)运行TopNDriver类,查看结果
- (2)下载结果文件并查看
一,案例分析
(一)TopN分析法介绍
TopN分析法是指从研究对象中按照某一个指标进行倒序或正序排列,取其中所需的N个数据,并对这N个数据进行重点分析的方法。
(二)案例需求
现假设有数据文件num.txt,现要求使用MapReduce技术提取上述文本中最大的5个数据,并最终将结果汇总到一个文件中。
先设置MapReduce分区为1,即ReduceTask个数一定只有一个。我们需要提取TopN,即全局的前N条数据,不管中间有几个Map、Reduce,最终只能有一个用来汇总数据。
在Map阶段,使用TreeMap数据结构保存TopN的数据,TreeMap默认会根据其键的自然顺序进行排序,也可根据创建映射时提供的 Comparator进行排序,其firstKey()方法用于返回当前集合最小值的键。
在Reduce阶段,将Map阶段输出数据进行汇总,选出其中的TopN数据,即可满足需求。这里需要注意的是,TreeMap默认采取正序排列,需求是提取5个最大的数据,因此要重写Comparator类的排序方法进行倒序排序。
二,案例实施
(一)准备数据文件
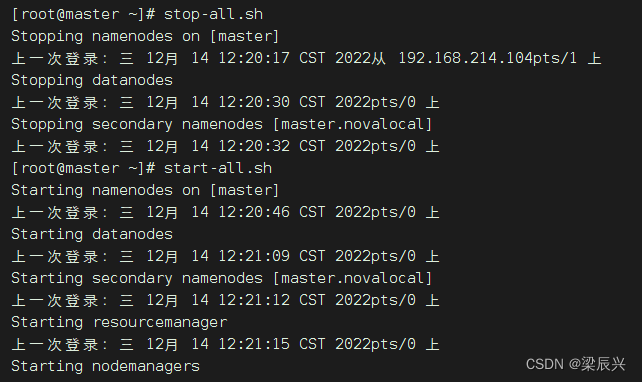
(1)启动hadoop服务
输入命令:start-all.sh
(2)在虚拟机上创建文本文件
1.expor目录下创建topn目录,输入命令:mkdir /export/topn

2.在topn目录下创建num.txt文件,输入命令:touch /export/topn/num.txt

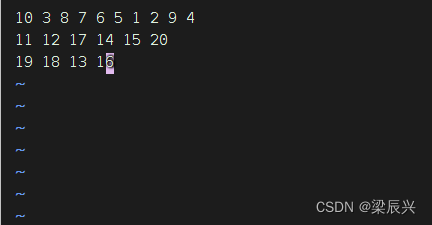
3.向num.txt文件添加如下内容:
10 3 8 7 6 5 1 2 9 4
11 12 17 14 15 20
19 18 13 16
输入命令:vim /export/topn/num.txt

(3)上传文件到HDFS指定目录
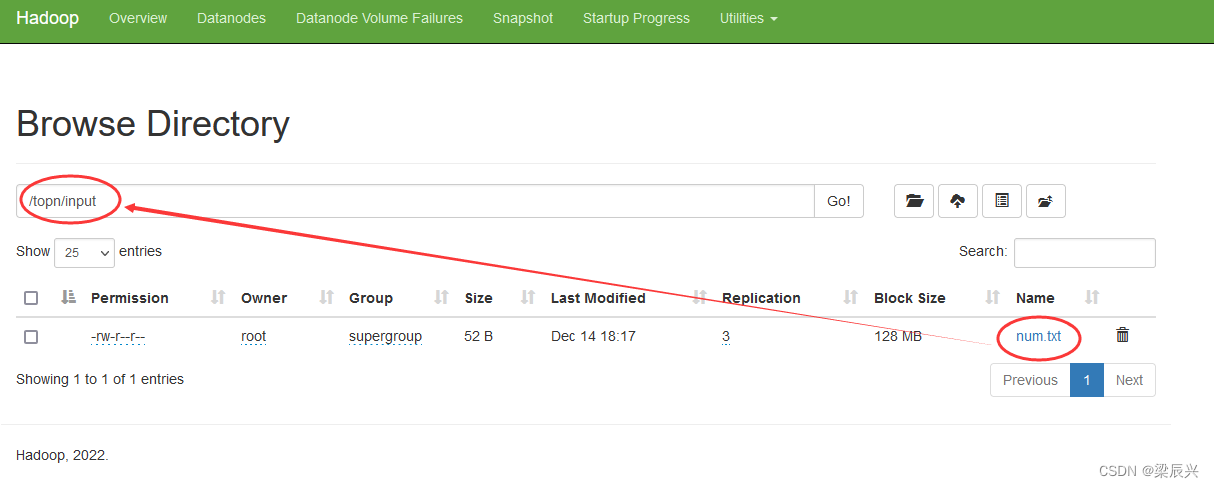
1.创建/topn/input目录,输入命令:hdfs dfs -mkdir -p /topn/input

2.将文本文件num.txt,上传到HDFS的/topn/input目录,输入命令:hdfs dfs -put /export/topn/num.txt /topn/input

3.在hadoop webui查看文件是否上传成功
(二)Map阶段实现
使用IntelliJ开发工具创建Maven项目TopN,并且新建net.hw.mr包,在该路径下编写自定义Mapper类TopNMapper,主要用于将文件中的每行数据进行切割提取,并把数据保存到TreeMap中,判断TreeMap是否大于5,如果大于5就需要移除最小的数据。TreeMap保存了当前文件最大5条数据后,再输出到Reduce阶段。
(1)创建Maven项目:TopN
1.配置好如下图,单击【Create】按钮
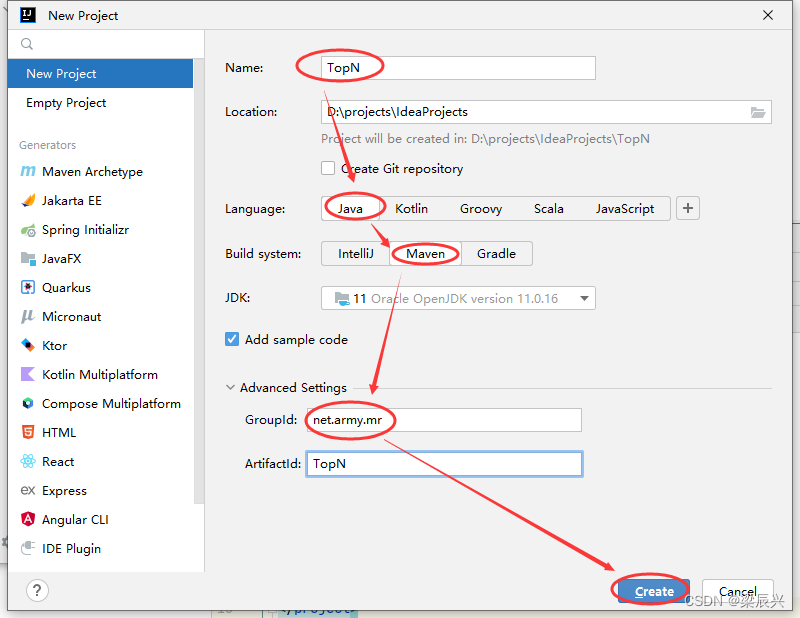 2.创建成功
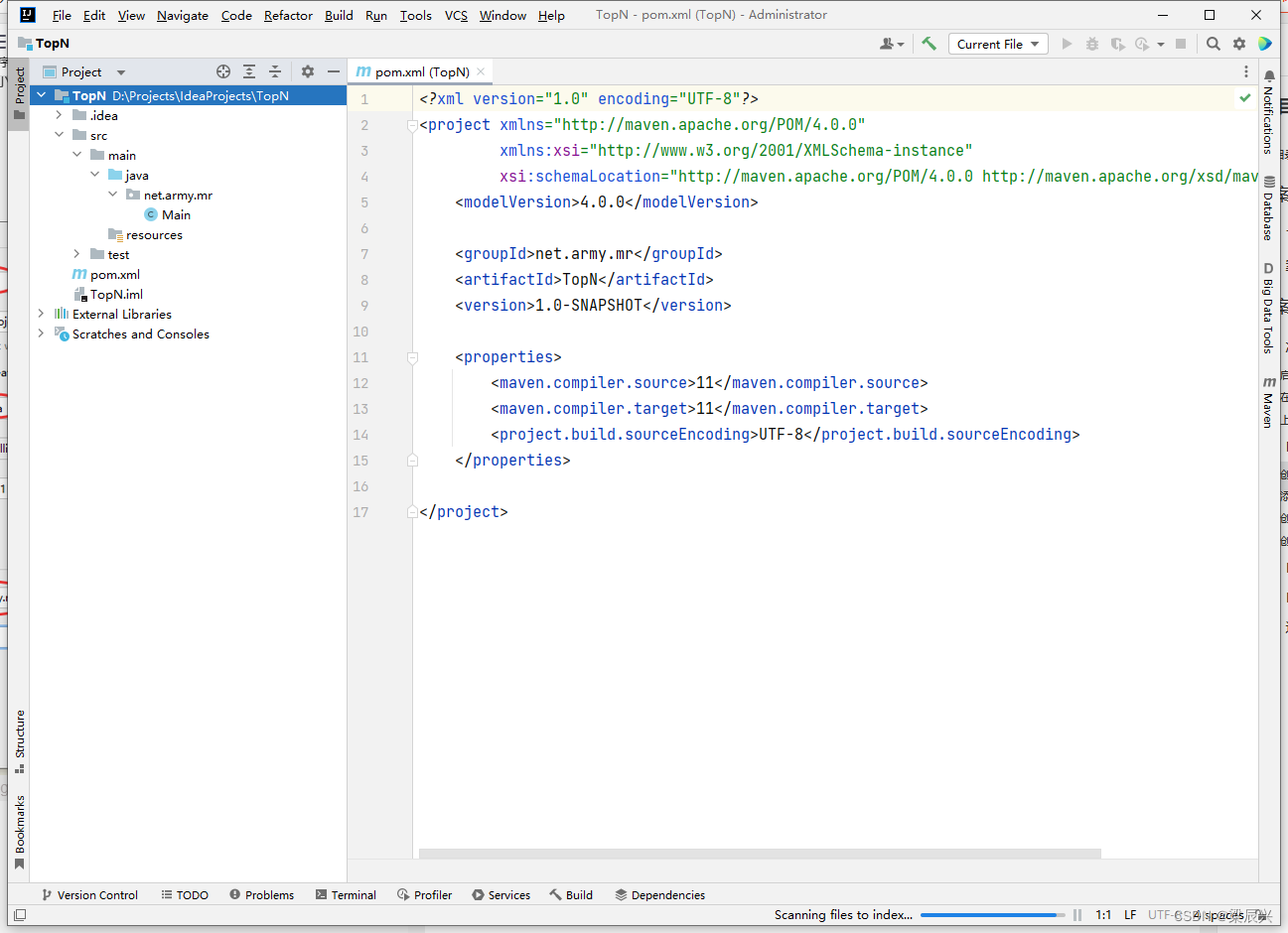
2.创建成功
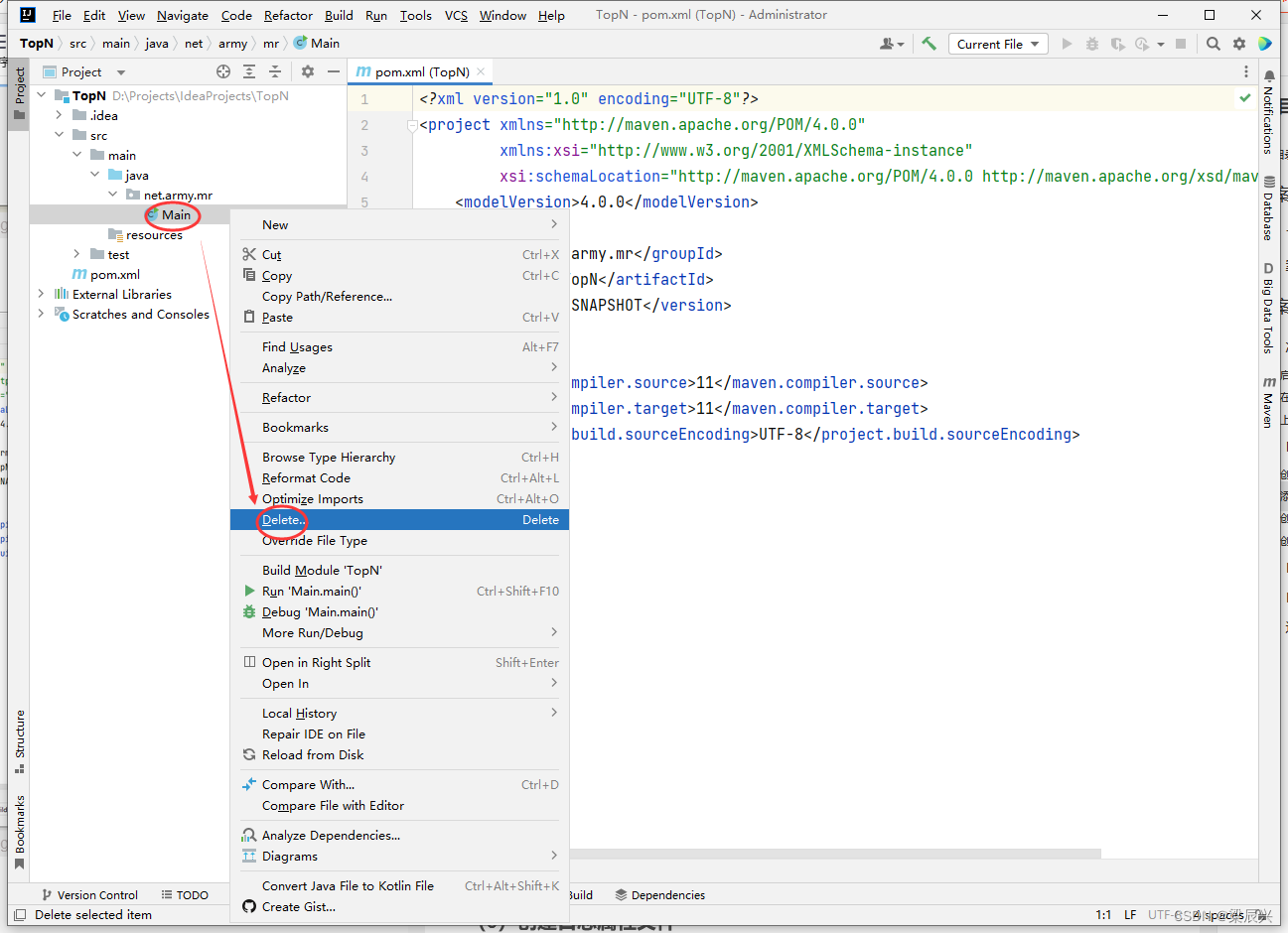
 3.删除【Main】主类:右击【Main】类,单击【Delete】
3.删除【Main】主类:右击【Main】类,单击【Delete】
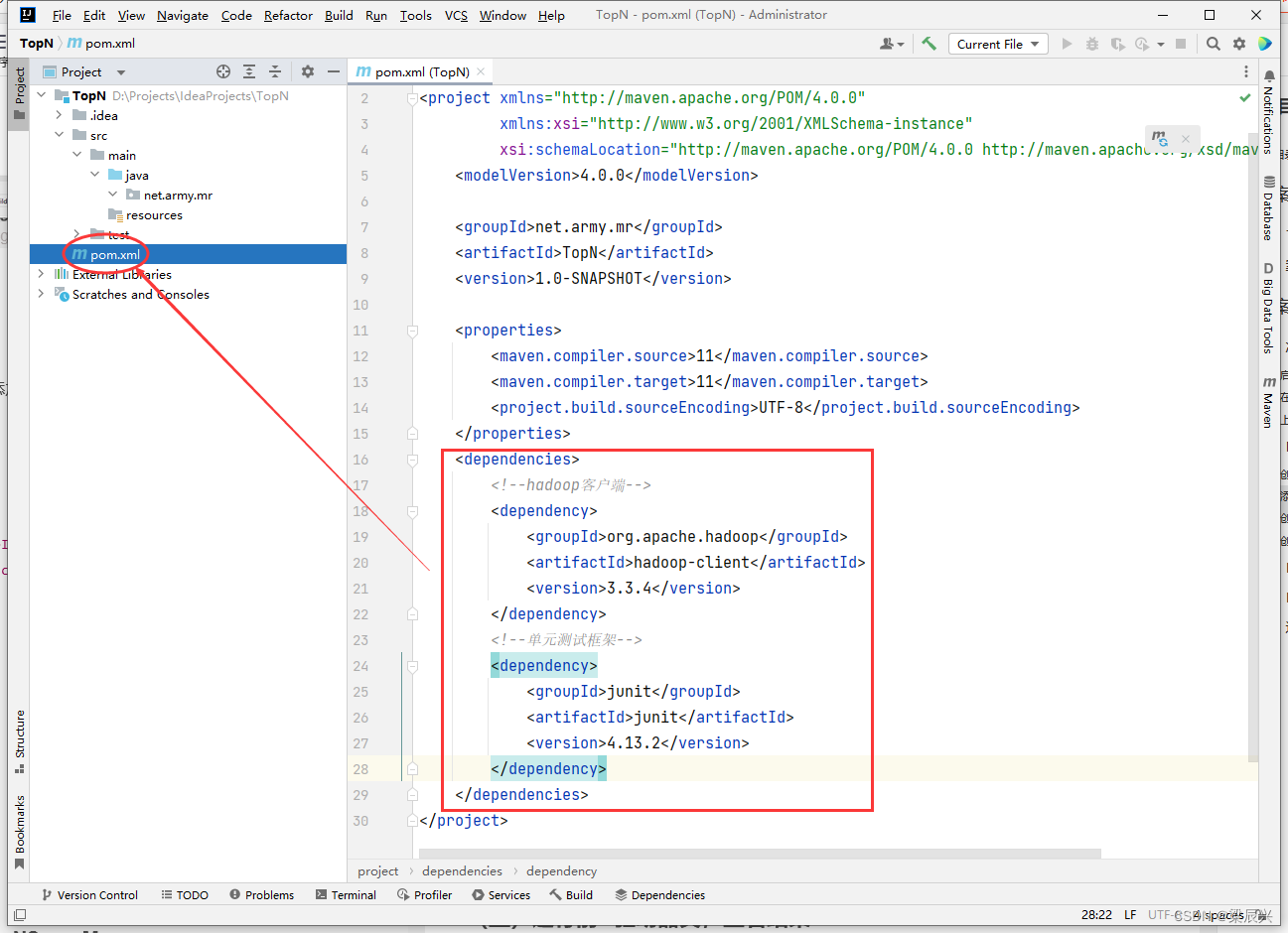
(2)添加相关依赖
1.在pom.xml文件里添加hadoop和junit依赖,添加内容如下:
<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
2.刷新本地的maven仓库,如果没有下载,会自动下载依赖到本地:单击【Maven】,单击【刷新】按钮
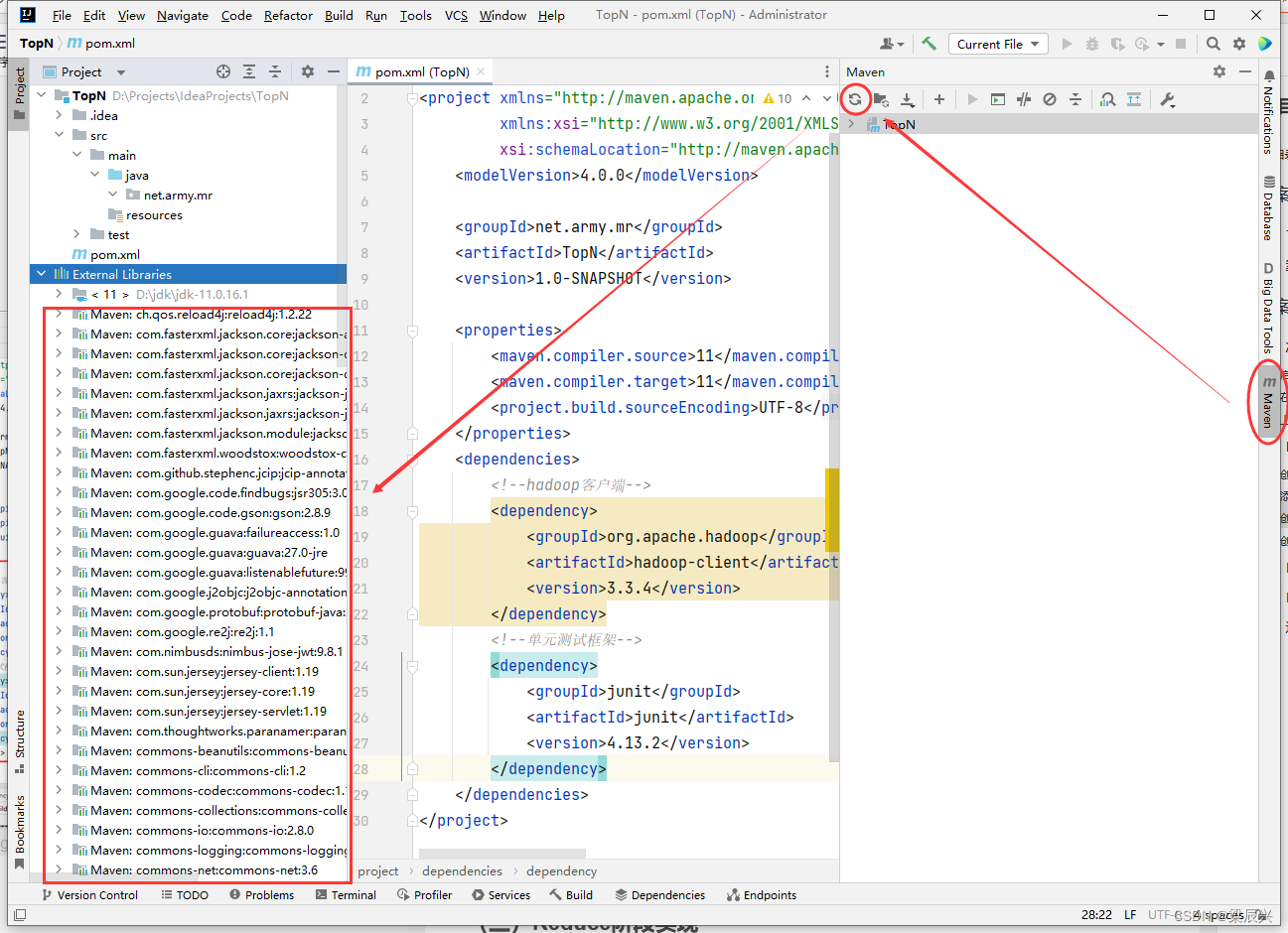
(3)创建日志属性文件
1.在resources目录里创建log4j.properties文件,右击【resources】,选择【New】,单击【Resource Bundle】
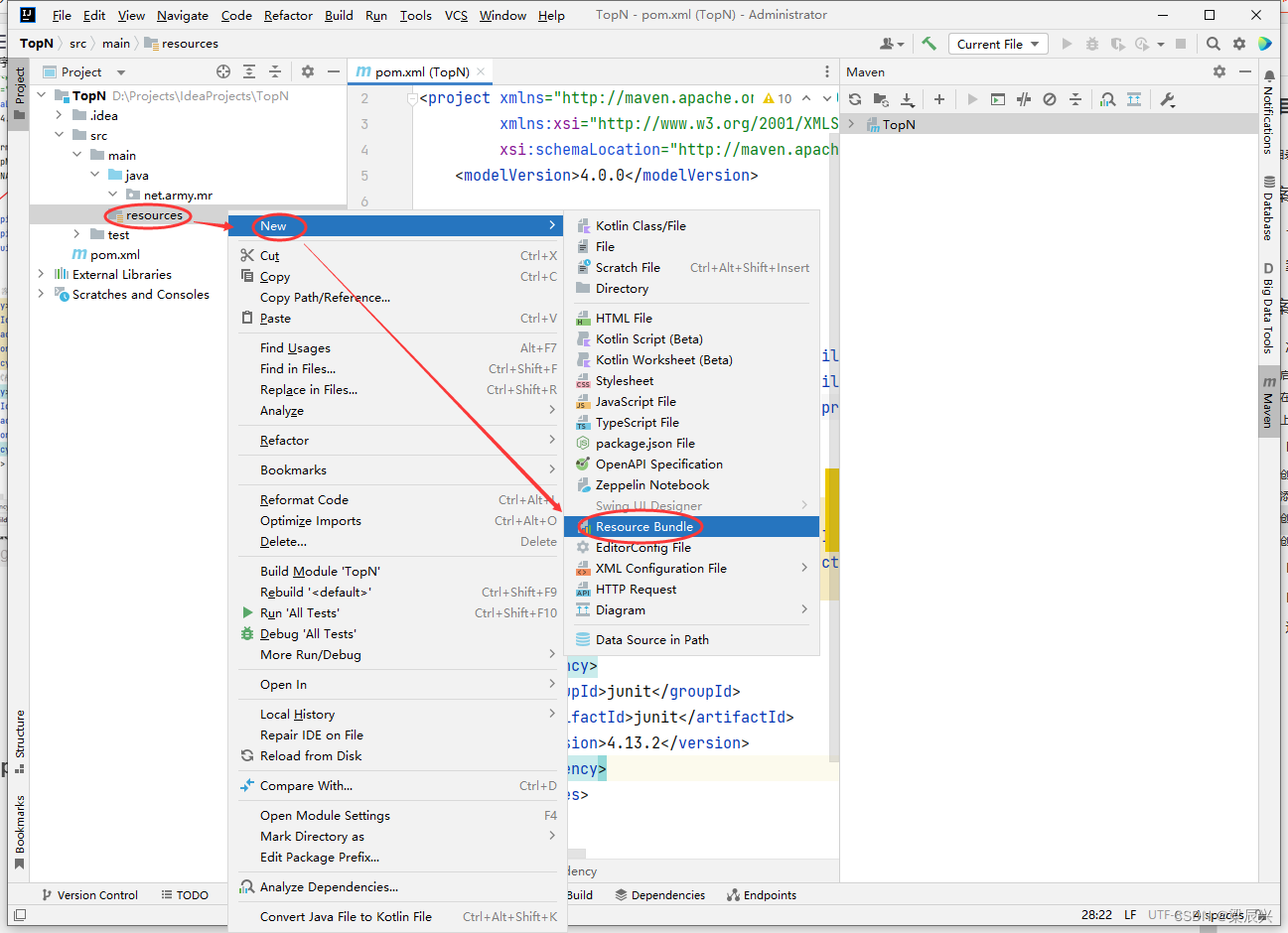
2.在弹出的对话框中输入:log4j,按【OK】按钮,成功创建
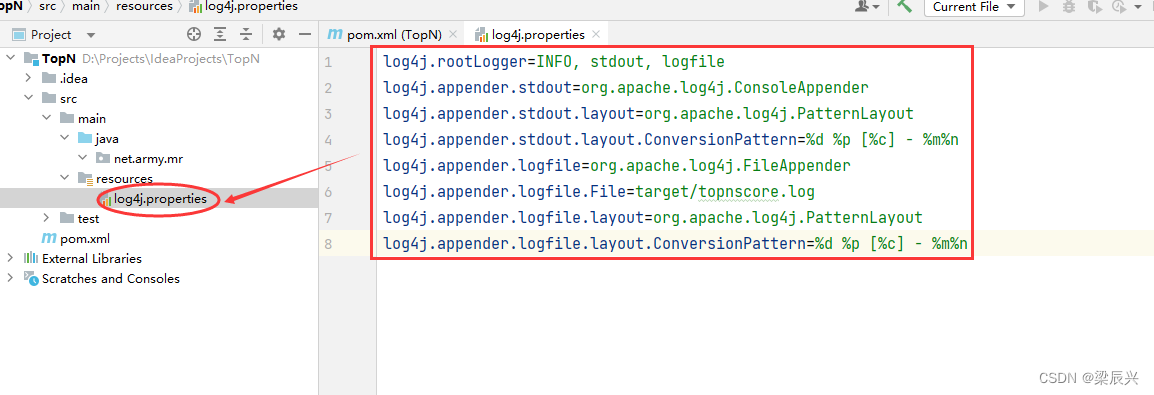
3.向log4j.properties文件添加如下内容:
log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/topnscore.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(4)创建前N成绩映射器类:TopNMapper
1.右击【net.army.mr】,选择【New】,单击【Java Class】
 2.在弹出的对话框中输入:TopNMapper,按下回车键,成功创建
2.在弹出的对话框中输入:TopNMapper,按下回车键,成功创建
3.编写代码
package net.army.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.util.TreeMap;/*** 作者:梁辰兴* 日期:2022/12/14* 功能:前N映射器类*/public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>();// <0,10 3 8 7 6 5 1 2 9 4>// <xx,11 12 17 14 15 20>@Overridepublic void map(LongWritable key, Text value, Context context) {String line = value.toString();String[] nums = line.split(" ");for (String num : nums) {repToRecordMap.put(Integer.parseInt(num), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}}@Overrideprotected void cleanup(Context context) {for (Integer i : repToRecordMap.keySet()) {try {context.write(NullWritable.get(), new IntWritable(i));} catch (Exception e) {e.printStackTrace();}}}
}
(三)Reduce阶段实现
编写MapReduce程序运行主类TopNDriver,主要用于设置MapReduce工作任务的相关参数,对HDFS上/topn/input目录下的源文件求前N数据,并将结果输入到HDFS的/topn/output目录下。
(1)创建前N归并器类:TopNReducer
1.右击【net.army.mr】,选择【New】,单击【Java Class】
2.在弹出的对话框中输入:TopNReducer,按下回车键,成功创建
3.编写代码
package net.army.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;/*** 作者:梁辰兴* 日期:2022/12/14* 功能:前N归并器类*/public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>(new Comparator<Integer>() {/*** 谁大排后面** @param a* @param b* @return 一个整数*/public int compare(Integer a, Integer b) {return b - a;}});public void reduce(NullWritable key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable value : values) {repToRecordMap.put(value.get(), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}for (Integer i : repToRecordMap.keySet()) {context.write(NullWritable.get(), new IntWritable(i));}}
}
(四)Driver程序主类实现
(1)创建前N驱动器类:TopNDriver
1.右击【net.army.mr】,选择【New】,单击【Java Class】
2.在弹出的对话框中输入:TopNDriver,按下回车键,成功创建
3.编写代码
package net.army.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 作者:梁辰兴* 日期:2022/12/14* 功能:前N驱动类*/public class TopNDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(TopNDriver.class);// 设置Mapper类job.setMapperClass(TopNMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(NullWritable.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class);// 设置Reducer类job.setReducerClass(TopNReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(NullWritable.class);// 设置reduce任务输出值类型job.setOutputValueClass(IntWritable.class);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/topn/input");// 创建输出目录Path outputPath = new Path(uri + "/topn/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录fs.delete(outputPath, true);// 给作业添加输入目录FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
(五)运行前N驱动器类,查看结果
(1)运行TopNDriver类,查看结果

(2)下载结果文件并查看
1.下载结果文件
进入/export/topn目录,输入命令:cd /export/topn/

下载文件,输入命令:hdfs dfs -get /topn/output/part-r-00000

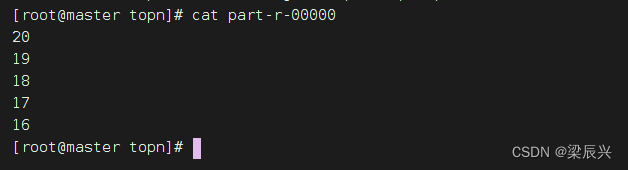
2.查看结果文件,输入命令:cat part-r-00000

![[C++]类和对象【中】](https://img-blog.csdnimg.cn/fb7efb77258e4cef80c5f2616d527f4e.png)