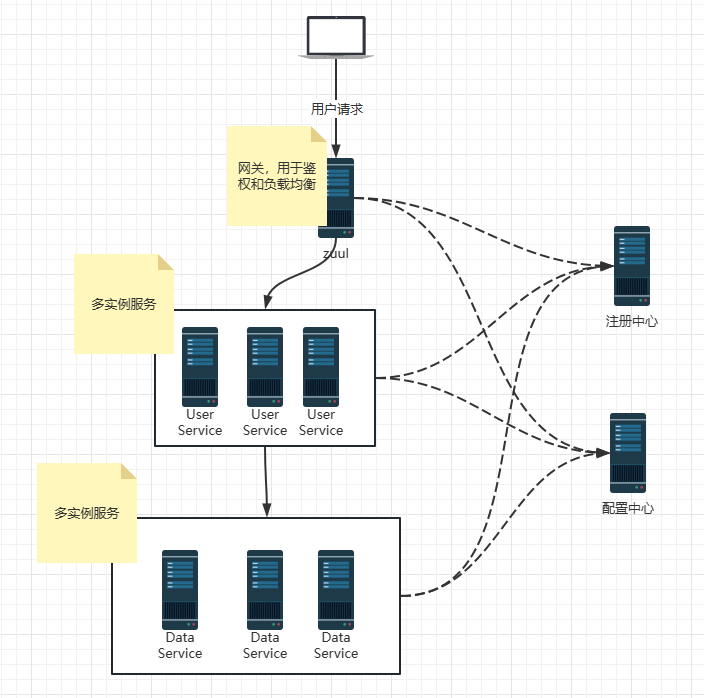
今天早上睡起来刷了这么一道题,二叉树的序列化和反序列化
大概意思就是给你一个二叉树,把他转成一个字符串,中间的自定义规则由你定,再根据这个字符串去还原这个二叉树,这道题的话思路不难,写起来有的细节要处理,反正我也是搞了好一会搞出来了。
要把他转成字符串,考察的就是遍历顺序,在这里前序 后序 层序都是可以的,为什么中序不行。因为中序拿不到根节点,懂我意思吧。
这道题要反序列化,其实就是恢复二叉树嘛。学过二叉树肯定写过前中序去恢复二叉树,后中序去恢复二叉树。为什么呢?前序遍历出来第一个总是根,然后我们根据这个根去划分中序和前序的区间去恢复二叉树。同理后序总能拿到最后一个是根。
因此这个反序列化,拿到根尤为重要。相当于你是依靠一种遍历去恢复二叉树的。
前序遍历从上到下遍历完之后,拿到结果后从下往上递归着去恢复二叉树。
我是拿前序遍历写的,就前序讲一些细节吧
首先自定义规则,遇到空结点我们用'#'去代替,每次结点之间拿空格去分开' '
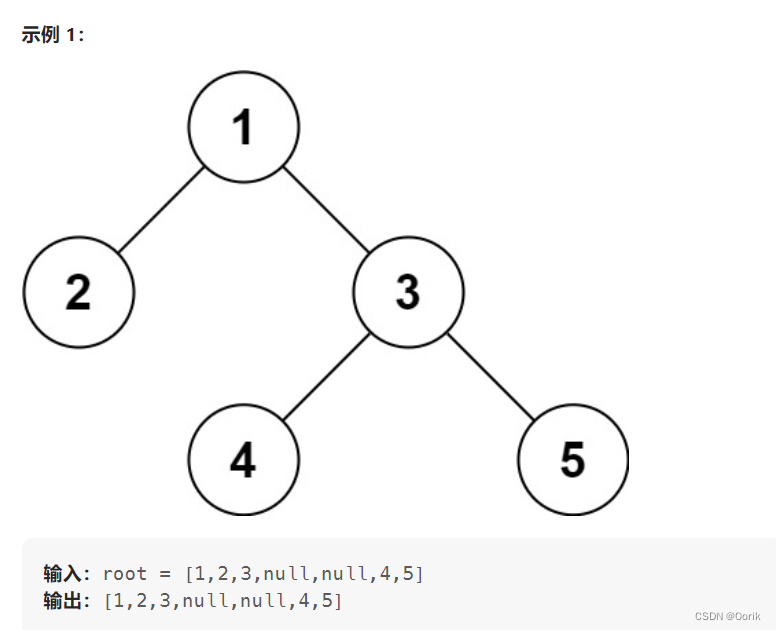
就会有如下的字符串 :1 2 '#' 3 4 '#'
遍历搞成字符串应该不难,c++的话了解用to_string这个api
下面关键是1 2 '#' 3 4 '#'恢复成二叉树
这块就需要我们去分割字符串了,我们用下标去分割
遇到'#'下标跳过,遇到结点跳过,这样的每次都会跳到' ',因此进入递归前下标还得++一次。
奇葩的是leco测试用例新加了负数进去,我们在恢复的时候要加个标记,判断是正负数来正确恢复
大概就是这样了~~代码我给了详细注释,看一遍应该能看懂
代码示例:
class Codec {
private://前序遍历转成字符串void traverse(TreeNode*root,string &res){if(!root){res+='#'; //用#代表nullreturn;}res+=to_string(root->val)+' '; //1 2 # 3...traverse(root->left,res);traverse(root->right,res);}//把这个字符串返还成树TreeNode* oppositeTraverse(string &res,int &index)//index是这个字符串的下标{if(index>=res.size())return nullptr;if(res[index]=='#')//说明走到空结点了{index++; //下标移到下一个位置,越过'#'return nullptr;//返回空}int val=0,flag=1;//sign用来分正负数的,lecod测试用例加了负数进去if (res[index] == '-') {flag = -1;index++ ;}while(res[index]!=' '){val=val*10+res[index]-'0';index++;}val*=flag;//正数就是正,负数就是负的index++;//越过' 'TreeNode* root=new TreeNode(val);root->left=oppositeTraverse(res,index);root->right=oppositeTraverse(res,index);return root;}
public:// Encodes a tree to a single string.string serialize(TreeNode* root) {string res="";traverse(root,res);return res;}// Decodes your encoded data to tree.TreeNode* deserialize(string data) {int index=0;return oppositeTraverse(data,index);}
};ok~继续保持自律,每天给自己洗脑。唉好想躺平
![[C++]类和对象【中】](https://img-blog.csdnimg.cn/fb7efb77258e4cef80c5f2616d527f4e.png)