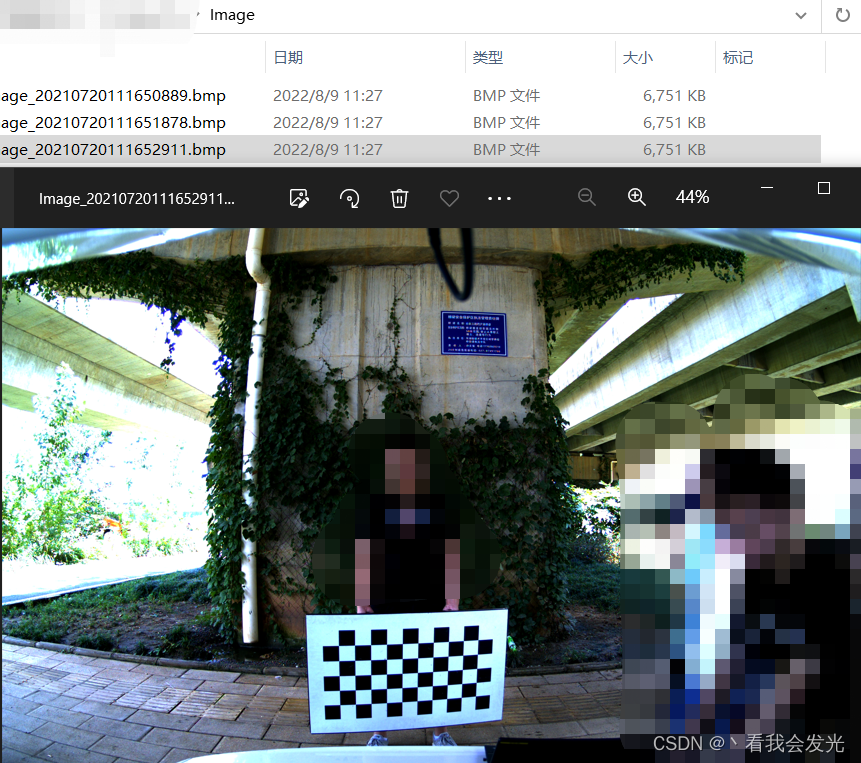
效果图
文章中采用的是棋盘格数据,这张图里面用的是开源的模型,可以用于测试,此图为最终效果,加载mp4视频,通过opencv读取图像,传递到infer接口,进行推理识别,利用opencv显示出来

文章目录
- 效果图
- 前言
- 一、数据集生成
- 1.图像准备
- 2.图像标注
- 3.标注成果转换为yolo格式
- 3.1.开源的python脚本
- 3.2.自己写脚本转换
- 二、模型训练
- 1.安装yolo
- 2.配置train.yaml
- 3.执行训练
- 4.导出onnx
- 三、TensorRT推理
- 1.环境安装
- 2.engine模型转换
- 3.TensorRT C++ 集成
- 3.1 tensorRT_Pro
- 3.2 infer
- 4.yolo样例数据
- 总结
- 过程中遇到的问题
- 1.执行train.py时提示的错误,这个问题是由于安装了Anaconda后,Anaconda的环境每次启动命令行后自动激活的问题导致,现象表现为打开控制台后,出现命令行前出现 *(base)* 字样
- 2.使用TensorRT 7.x版本转换生成engine文件时失败,但是8.x正常
- 3.执行pt转换onnx脚本时,不需要指定 --device ,转化engine才需要
前言
作为一个没有接触过深度学习的码农,此篇文章记录一下自己深度学习入门的一些经验分享,从数据集准备到模型训练生成pt文件,然后通过yolo将模型导出为onnx,通过tensorrt将模型转化为engine规格给tensorrt的infer使用。
一、数据集生成
1.图像准备
准备一些带有目标物体的影像例程中采用相机内标定的棋盘格数据,放在一个目录下。
2.图像标注
一般采用开源的软件来做图像标注,如labelme(https://github.com/wkentaro/labelme),在release页面找对应平台的可执行文件。
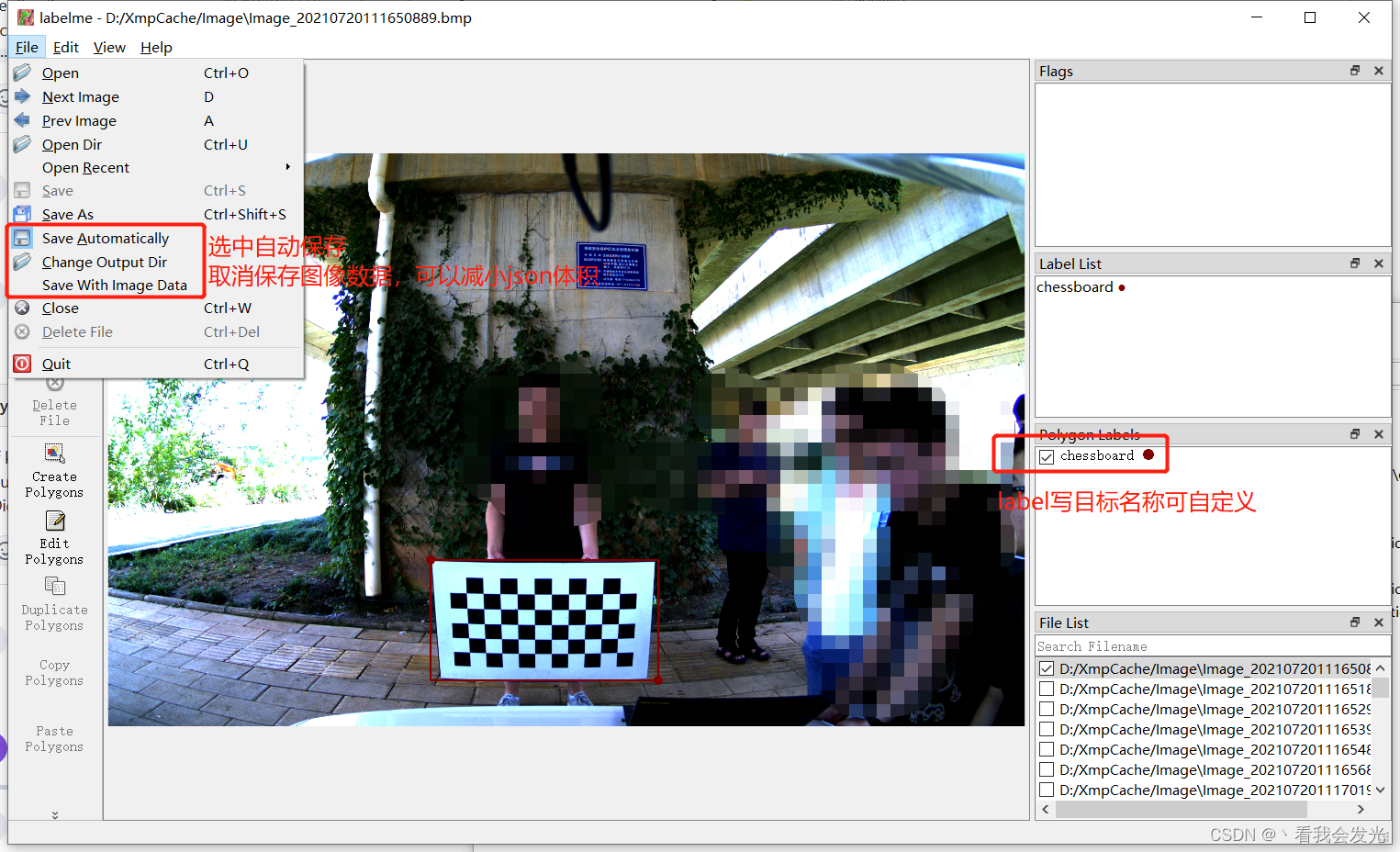
labelme标注软件使用方法:标注完成后点击 上一张 下一张 可以切换图像,会在图像目录生成对应json文件
3.标注成果转换为yolo格式
labelme出来的成果为json格式,图片和json在1个目录,记录的是标注框的左上和右下角点
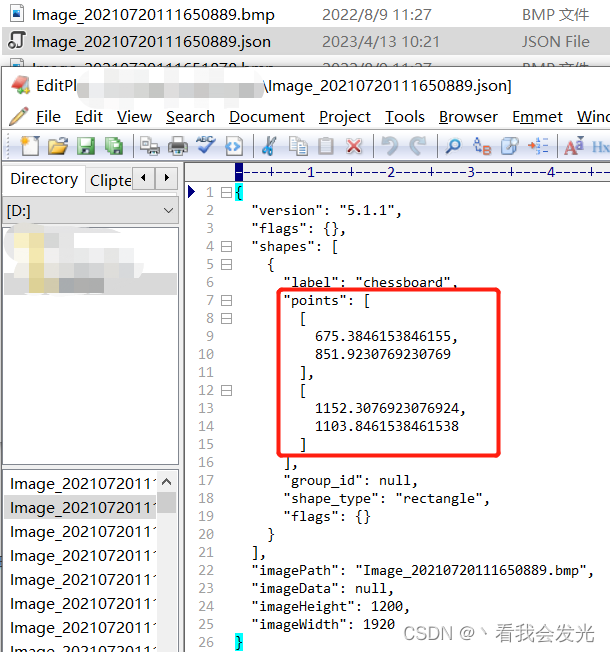
yolo需要的成果为txt格式,分images和labels目录,train.txt和val.txt分别记录用于训练的样本和用于验证的样本,一般比例为8:2。文件格式为labelId cx cy w h,空格 分隔,值为归一化的值
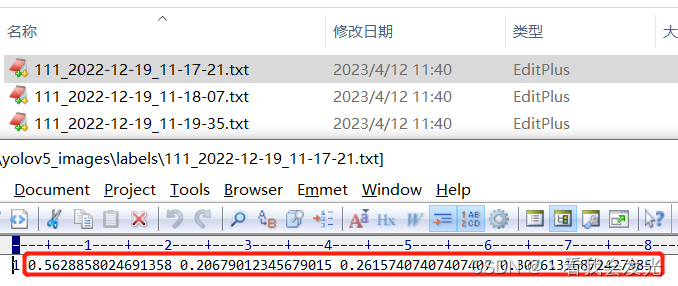
yolo数据集转化方法
3.1.开源的python脚本
Labelme2YOLO(https://github.com/rooneysh/Labelme2YOLO)
3.2.自己写脚本转换
到此位置样本数据准备完成,可以进行后续训练和检测操作了
TODO.
二、模型训练
1.安装yolo
前提:pycharm已安装,python > 3.7
源码:https://github.com/ultralytics/yolov5.git,参考readme.md安装依赖
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
2.配置train.yaml
在yolo源码的data目录新建1个train.yaml,内容如下
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/XmpCache/yolov5_images
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images# Classes
names:0: chessboard1: fisheye_chessboard

3.执行训练
通过传递参数,就不用去动yolo源码脚本了
python train.py --cfg models/yolov5s.yaml --data data/train.yaml --batch-size 4
4.导出onnx
通过传递参数,就不用去动yolo源码脚本了
#yolo训练的模型在yolo/runs/expX/weights目录下,X为执行次数,best.pt为最好的那次结果,last.pt为最新的那次结果
python .\export.py --weights .\runs\train\exp5\weights\best.pt --include onnx --opset 12
三、TensorRT推理
1.环境安装
cudNN、TensorRT版本需要和CUDA版本对应,目前cuda-11.1、cuDNN-8.0.5、TensorRT-8.0.1.6/7.2.3.4测试通过
安装 CUDA:https://developer.nvidia.com/cuda-downloads
安装 cuDNN:https://developer.nvidia.com/nvidia-tensorrt-8x-download
安装 TensorRT:https://developer.nvidia.com/rdp/cudnn-download
2.engine模型转换
tensorrt pathto\trtexec --onnx=best.onnx --saveEngine=chessboard.engine
3.TensorRT C++ 集成
目前比较好用的C++ Infer的SDK
3.1 tensorRT_Pro
源码:(https://github.com/shouxieai/tensorRT_Pro.git)
3.2 infer
源码:(https://github.com/shouxieai/infer.git)
4.yolo样例数据
总结
过程中遇到的问题
1.执行train.py时提示的错误,这个问题是由于安装了Anaconda后,Anaconda的环境每次启动命令行后自动激活的问题导致,现象表现为打开控制台后,出现命令行前出现 (base) 字样
报错OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方案:关闭Anaconda的base环境自动激活功能#在Anaconda的prompt中输入: config --set auto_activate_base false此时再打开pycharm命令行可以看到环境提示为venv
2.使用TensorRT 7.x版本转换生成engine文件时失败,但是8.x正常
Input dimensions [1,3,80,80,6] have volume 115200 and output dimensions [1,1]
解决方案:此时注意onnx的opset版本为17或更高,需要在yolo执行export.py时将他的opset版本修改为12左右即可
3.执行pt转换onnx脚本时,不需要指定 --device ,转化engine才需要
以上就是本次要写的内容,本文仅仅简单介绍了yolo+tensorrt入门级的使用。