目录
1. 介绍
2. 创建混淆矩阵
2.1 update 方法
2.2 compute 方法
2.3 str 方法
3. 测试
4. 完整代码
1. 介绍
语义分割中,性能指标可以利用混淆矩阵进行计算
这里实现的方法和图像分类中不一样,需要的可以参考:混淆矩阵Confusion Matrix
这里采用的测试数据如下:

2. 创建混淆矩阵
混淆矩阵的实现如下
init 是初始化混淆矩阵
update 更新混淆矩阵的数值
reset 将矩阵的值清零
compute 根据update 算出来的混淆矩阵计算相应的性能指标
str 是返回的字符串,就是实例化混淆矩阵后,print的值

这里讲解混淆矩阵类的测试数据都是上面的:
2.1 update 方法
如下:

a传入的是真实的label,b传入的是网络预测的值,注:这里的预测值也是和label一样的整型数组
首先通过init初始化方法将混淆矩阵的大小赋值给n(分类类别的个数+1 背景),然后创建混淆矩阵mat,先初始化为0
接下来,k在真正标签a中找到对应的索引,
这里目的是为了将不感兴趣的区域设为False,其余的具体分割标签应该为1,2,3这样的排序方式。因为通常0为背景,255为不感兴趣的区域。
例如,当分割类别为2(1,2),那么加上背景传入的n就是3(0,1,2),同时不感兴趣的区域设置为255(0,1,2,255)。那么在k在真实标签a(0,1,2,255)中的索引,就会将a>=0 & a<n ,也就是0,1,2 的区域设置为True,从而满足了分割要求且拍出来255不感兴趣的
所以,dataset加载数据中,要将前景从1,2,3这样排序

然后,通过下面的操作就能将横坐标为true,纵坐标为pred的混淆矩阵update
中间的inds大概是将a和b变为一维向量,那么n*a就会将一维向量变为n个为一组的样子,然后在里面进行计算,最后reshape成n*n的矩阵就行了。具体的可以自己调试一下

例如,true = 1,pred = 0 的个数是一个,同样在混淆矩阵的值也是1(第0行,第1列)
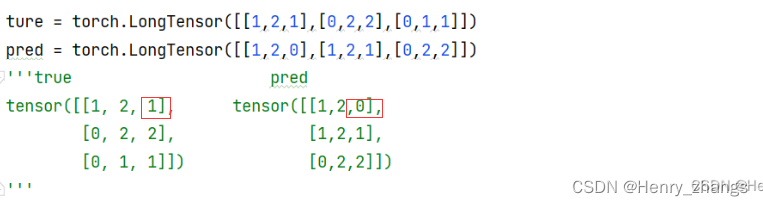
2.2 compute 方法
compute 是利用update产生的混淆矩阵,计算分割任务中的性能指标,关于分割任务的性能指标,可以查看:关于语义分割常见的评价指标
混淆矩阵:横坐标为true,纵坐标为pred
像素准确率 = 混淆矩阵对角线 / 混淆矩阵的sum
acc 这里是指各个类别的召回率 = 各个对角线的值 / 真实值(矩阵的行为ture,所以对行求和)
recall 召回率就是在...召回的个数,...就是label,召回的个数就是预测正确的个数。所以召回率就是在label中,预测正确个数的占比
iou 就是各个对角线的值 / (对应行 + 对应列 - 重复的对角线的值)

2.3 str 方法
python类中str方法,是返回实例化类的print的值
因此混淆矩阵类中的str方法返回的是compute计算出的性能指标。
因为这里的str方法自动调用了compute,而compute是根据update计算的。所以调用str之前,一定要先调用update方法,更新混淆矩阵的值
这里的recall和iou都是针对不同类别的,所以返回是个列表

3. 测试
测试的代码如下:

测试的样本为:
这里手动计算分割的参数,验证混淆矩阵
首先是像素准确率:4 / 9 = 0.4444

然后是各个类别的召回率:这里是三个类别0 1 2

然后是iou:
对于0:1 / 3 =0.3333
对于1:1 / 6 =0.1667
对于2:2 / 5 =0.4
最后mean iou就是iou的均值:(0.3333+0.1667+0.4) / 3 = 0.9 / 3 = 0.3
4. 完整代码
混淆矩阵的代码:
import torch# 混淆矩阵
class ConfusionMatrix(object):def __init__(self, num_classes):self.num_classes = num_classes # 分类个数(加了背景之后的)self.mat = None # 混淆矩阵def update(self, a, b): # 计算混淆矩阵,a = Ture,b = Predictn = self.num_classesif self.mat is None: # 创建混淆矩阵self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)with torch.no_grad():k = (a >= 0) & (a < n)inds = n * a[k].to(torch.int64) + b[k] # 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)def reset(self):if self.mat is not None:self.mat.zero_()def compute(self): # 计算分割任务的性能指标h = self.mat.float()acc_global = torch.diag(h).sum() / h.sum() # 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)acc = torch.diag(h) / h.sum(1) # 计算每个类别的 recalliou = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h)) # 计算ioureturn acc_global, acc, ioudef __str__(self):acc_global, acc, iou = self.compute()return ('global correct: {:.4f}\n''recall: {}\n''IoU: {}\n''mean IoU: {:.4f}').format(acc_global.item() ,['{:.4f}'.format(i) for i in acc.tolist()],['{:.4f}'.format(i) for i in iou.tolist()],iou.mean().item())
测试的代码:
confmat = ConfusionMatrix(num_classes=3) # 实例化混淆矩阵ture = torch.LongTensor([[1,2,1],[0,2,2],[0,1,1]])
pred = torch.LongTensor([[1,2,0],[1,2,1],[0,2,2]])confmat.update(ture, pred) # update 混淆矩阵的值
print(confmat)
'''
global correct: 0.4444
recall: ['0.5000', '0.2500', '0.6667']
IoU: ['0.3333', '0.1667', '0.4000']
mean IoU: 0.3000
'''