AV1,目前业界最新的开源视频编码格式,对标专利费昂贵的H.265。它由思科、谷歌、网飞、亚马逊、苹果、Facebook、英特尔、微软、Mozilla等组成的开放媒体联盟(Alliance for Open Media,简称AOMedia)开发。而当前中文资料较少,IEEE一篇论文:An Overview of Core Coding Tools in the AV1 Video Codec
AV1是一种新兴的开源、版权免费的视频压缩格式,由开放媒体联盟(AOMedia)行业联盟于2018年初联合开发并最终定稿。AV1开发的主要目标是在当前的编解码器基础上获得可观的压缩率提升,同时确保解码的复杂性和硬件的实际可行性。本文简要介绍了AV1中的关键编码技术,并与VP9和HEVC进行了初步的压缩性能比较。
索引:视频压缩,AV1,开放媒体联盟,开源视频编码
在过去的十年里,智能设备推动着高分辨率、高质量内容消费的高速增长,使得视频应用在互联网上已经变得无处不在。视频点播和视频通话等服务是消费者主要使用的服务,它们对传输的基础设施提出了严峻的挑战,因此更需要高效的视频压缩技术。另一方面,互联网成功的一个关键因素是它所使用核心技术,例如HTML、web浏览器(Firefox、Chrome等)和操作系统(如Android),都是开放和可自由实现的。因此,为了创建一个与主流商用视频格式相当的开源视频编码格式,在2013年年中,谷歌推出并部署了VP9视频编解码器。VP9的编码效率与最先进的收费HEVC编解码器相当,同时大大优于最常用的格式H.264及它的前身VP8。
然而,随着对高压缩视频应用需求的增加和多样化,压缩性能的不断提高很快变得迫在眉睫。为此,在2015年底,谷歌成立了开放媒体联盟(AOMedia),一个由30多家领先的高科技公司共同组成的联盟,致力于下一代开源视频编码格式—AV1。
AV1开发的着重点包括但不限于以下目标:一致的高质量实时视频传输、对各种带宽的智能设备的兼容性、易处理的计算占用空间、对硬件的优化以及对商业和非商业内容的灵活性。编解码器最初使用的是VP9工具和增强功能,然后AOMedia的编解码器、硬件和测试工作组被提出、测试、讨论和迭代产生新的编码工具。到今天为止,AV1代码库已经到了最后的bug修复阶段,并且已经合并了各种新的压缩工具,以及为特定用例设计的高级语法和并行化特性。本文将介绍AV1中的关键编码工具,与同等质量的高性能libvpx VP9编码器相比,AV1的平均比特率降低了近30%。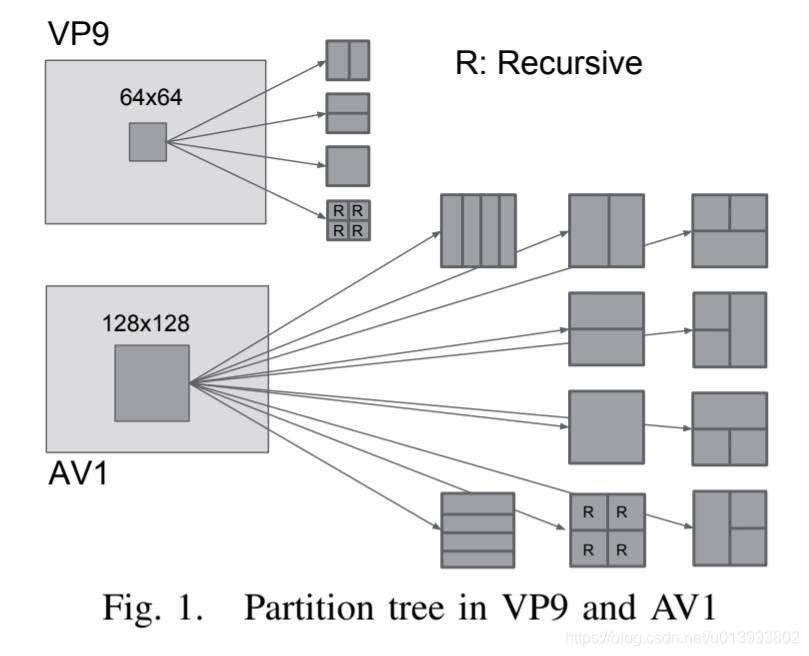
VP9的分区树有4种分块方式,从最大的64×64开始,一直到4×4层,对于8×8及以下的分块则有一些额外的限制,如图1的上半部分所示。注意,图中标有为R的分块是递归的,因此R分块可以重复再分块,直到达到最低的4×4级。
AV1不仅将分区树扩展为如图所示的10种结构,还将最大的分块尺寸(在VP9/AV1中称为superblock)增大至128×128。注意,在VP9中并不存在这种的4:1/1:4矩形分块,而这些分块没有一个可以再细分。此外,AV1增加了使用8×8级以下分区的灵活性,在某种意义上,2×2的色度帧间预测现在在某些情况下成为可能。
VP9支持10种帧内预测模式,其中8种方向模式,角度45-207度,2个非方向预测模式:DC和true motion ™模式。AV1,潜在的帧内编码进一步探索了不同的方法:方向预测的粒度进一步升级,而非方向性的预测,纳入了梯度和相关性,亮度的一致性和色度信号也得到充分利用,并开发出针对人造视频内容特殊优化的工具。
1)帧内预测方向的增强:为了在方向纹理中实现更多种类的空间冗余,在AV1中,将方向帧内模式扩展到更具精细粒度的角度集。 将最初的8个角度设为名义角度,基于这些角度引入步长为3度的精细角度微调,即预测角度由名义内角度加上角度增量表示,该角度以-3〜3的倍数为步长。 为了以通用方式在AV1中实现定向预测模式,这48个扩展模式由统一的定向预测器实现,该预测器将每个像素链接到像素边缘的一个参考像素位置,并通过2-tap双线性插值对参考像素进行插值。 所以,在AV1中总共启用了56个定向内部模式。
2)无方向平滑的帧内预测器:AV1通过添加3个新的平滑预测器SMOOTHV,SMOOTHH和SMOOTH扩展了无方向帧内模式,它们在垂直或水平方向,使用二次插值或其平均值预测了像素块。此外,TM模式已被PAETH预测器取代:对于每个像素,我们从顶部、左侧和顶部左边缘参考复制出一份,其值最接近(top+left-topleft),表示采用从具有较低坡度的方向进行参考。
3)基于递归滤波的帧内预测器:为了捕获边缘参考块的衰减空间相关性,FILTERINTRA模式通过将亮度块使用二维不可分离的马尔可夫过程。 为AV1预设计的五个滤波器帧内模式中,每个模式用一组八个7-tap滤波器表示,反映了4×2色块中的像素与相邻的7个像素之间的相关性。 一个内部块可以选择一种帧内滤波模式,并以一批4×2补丁进行预测。 通过选中的7-tap滤波器组预测每个补丁,在8个相邻像素位置上的权重。 对于那些未完全附加到边缘块上参考的补丁,将直接相邻的预测值用作参考,这意味着在补丁之间递归计算预测,以便合并更多较远位置上的边缘像素。
4)从亮度预测色度:Chroma from Luma(CfL)是仅用于色度的帧内预测器,通过以重建后亮度像素的线性函数建模得到色度像素。重建的亮度像素被二次采样为色度分辨率,然后去除直流分量以得到交流分量。 为了从交流分量中估计色度的交流分量,而不是像某些现有技术那样要求解码器提供缩放参数,AV1CfL根据原始色度像素确定参数并在比特流中用信号发送。 这降低了解码器的复杂性并得到了更精确的预测。 对于DC预测,它是使用内部DC模式计算的,该模式对于大多数色度内容来说已经足够,并且具有成熟并能快速实现的方法。 有关AV1CfL工具的更多详细信息,请参见[6]。
5)调色板作为预测指标:有时,尤其是对于诸如屏幕截图和游戏之类的人造视频,可以用少量唯一颜色的近似块来替代。因此,AV1将调色板模式引入到帧内编码器中作为通用的额外编码工具。块的每个平面的调色板预测器由(i)一个调色板,拥有2~8种颜色(ii)这些颜色指定了块中所有像素的索引。基色的数量决定了保真度和紧密度之间的平衡。颜色索引基于相邻上下文进行熵编码。
6)帧内块拷贝:AV1允许其帧内编码器参考同一帧中先前重建的块,其方式类似于帧间编码器引用前一帧中块的方式,这对于通常包含重复纹理的屏幕内容视频非常有用。具体来说,一种名为IntraBC的新预测模式被引入,它将在当前帧中拷贝一个重建的块作为预测。参考块的位置由位移矢量指定,其方式类似于运动补偿中的运动矢量压缩。位移矢量属于亮度平面的整个像素,并且可以引用对应色度平面上的半像素位置,其中双线性滤波被应用于子像素插值。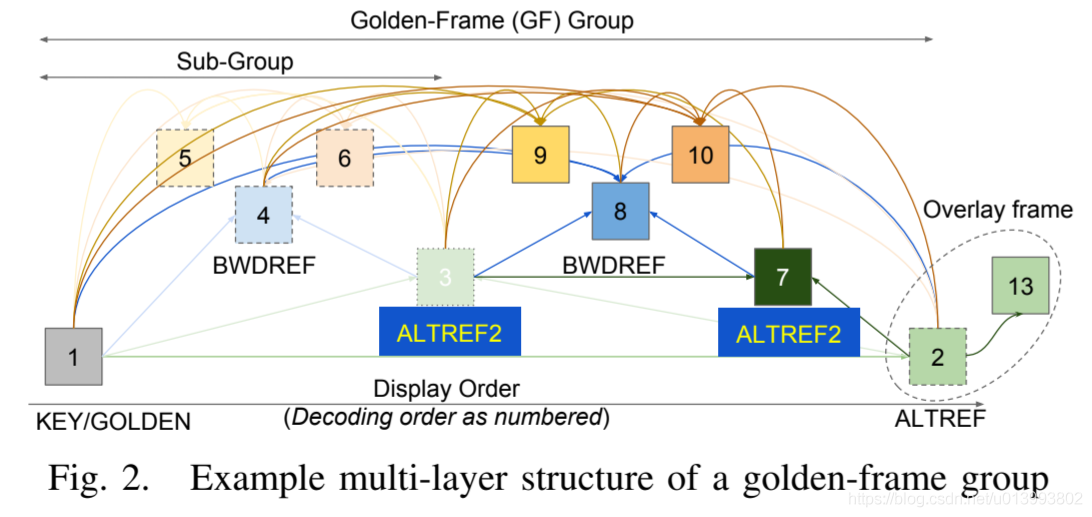
帧间预测运动补偿是视频编码中必不可少的模块。在VP9中,最多允许3个候选参考帧中的2个参考,然后预测器将进行基于块平移的运动补偿,或者如果有两个参考信号则取这两次预测的平均值。 AV1具有更强大的帧间编码器,可大大扩展参考帧和运动矢量的池,它打破了基于块平移预测的局限性,并通过使用高自适应加权算法和源,增强了复合预测。
1)扩展参考帧:AV1将每个帧的参考数从3扩展到7。除了VP9的LAST(最近过去的)帧,GOLDEN(遥远过去的)帧和ALTREF(临时过滤将来的)帧之外,我们在帧附近添加了两个过去的帧(LAST2和LAST3)以及两个将来的帧(BWDREF和ALTREF2)[7]。图2展示了黄金帧组的多层结构,其中自适应数量的帧共享相同的GOLDEN和ALTREF帧。 BWDREF是一种直接编码的超前帧,无需应用时域滤波,因此更适合用作相对距离较短的后向参考。 ALTREF2用作GOLDEN和ALTREF之间的中间过滤的将来参考。所有的新参考都可以通过单个预测模式使用,也可以被组合成复合模式使用。 AV1提供了丰富的参考帧对集合,既提供了双向复合预测又提供了单向复合预测,因此可以以更灵活和更优的方式,对具有动态时域特性的各种视频进行编码。
2)动态空间与时间运动矢量参考:有效的运动矢量(MV)编码对于视频编解码器至关重要,因为它占帧间码率消耗的很大一部分。为此,AV1结合了复杂的MV参考选择方案通过搜索空间和时间候选,获得给定块较好的MV参考。 AV1不仅搜索比VP9更深的空间邻域来构建空间候选池,而且还利用时间运动场估计机制生成时间候选。运动场估计过程分为三个阶段:运动矢量缓冲,运动轨迹创建和运动矢量投影。首先,对于编码后的帧,我们存储参考帧索引以及相关的运动矢量。在解码当前帧之前,我们检查运动轨迹,例如图3中的MVRef2,将Ref2帧中的一个块指向Ref0Ref2中的某个位置,可能会通过每个64×64处理单元,检查最多3个参考中并列的192×128缓冲运动矢量场。这样,对于任何8×8块,其所属的所有轨迹都将被记录。接下来,在编码块级别,一旦确定了参考帧,则通过将运动轨迹线性地投影到期望的参考帧上来生成运动矢量候选,例如,将图3中的MVRef2转换为MV0或MV1。一旦所有的空间和时间候选都聚集在池中,就对其进行分类,合并和排序,以获得最多4个最终候选者[8]。计分方案取决于计算当前块具有特定候选MV的可能性。为了编码MV,AV1从列表中发出选定参考MV索引的信号,然后根据需要编码增量。在实际使用中,参考MV和其增量的组合是通过模态发出信号,这点和VP9一样。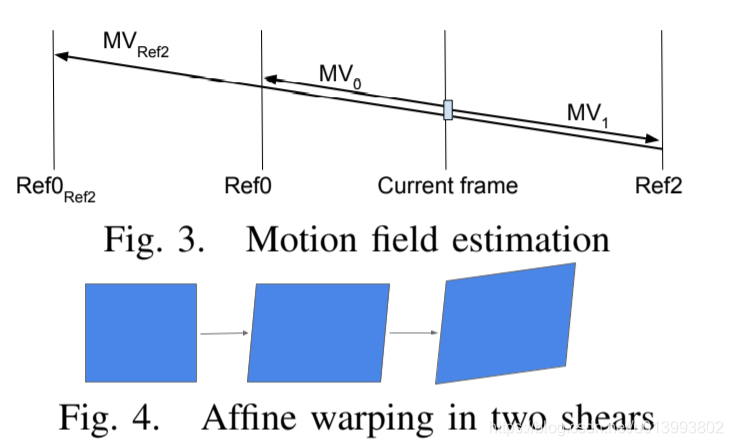
3)重叠块运动补偿(OBMC):OBMC通过平滑地组合从邻近运动矢量创建的预测,可以大大减少块边缘附近的预测误差。在AV1中,设计了一种两面因果重叠算法,以使OBMC轻松适合高级分块框架[9]。通过在垂直和水平方向上应用预定义的一维平滑滤波器,它逐步将基于块的预测与二次帧间预测器结合在上方边缘和左侧边缘。二次预测变量仅在当前块的受限重叠区域中操作,因此它们不会在同一侧彼此出现混淆。 AV1 OBMC仅对单个参考帧的宏块启用,并且仅与具有两个参考帧的任何相邻中的第一个预测器同时工作,因此,最坏情况下,所要求的存储带宽与传统复合预测器是相同的。
4)扭曲运动补偿:通过启用两种仿射预测模式,全局和局部扭曲运动补偿,在AV1中开发了扭曲运动模型[10]。全局运动工具旨在处理相机运动,并允许在帧级别显式运用运动模型,主要用于当前帧与其任何参考之间的运动。局部扭曲运动工具旨在通过从分配给因果邻域的运动矢量信号的二维位移中推导块级模型参数,从而以最小的开销隐式描述变化的局部运动。通过比较两种编码工具在块级别转换模式,只有在RD成本方面有优势时才选择它。更重要的是,AV1中的仿射扭曲受到的限制较小,因此可以在SIMD和硬件中通过水平剪切和垂直剪切来有效地实现仿射扭曲(图4),其中每个剪切点使用1/64像素精度的8-tap插值滤波器。
5)高级复合预测:为AV1开发的一系列新的复合预测工具,使得其帧间编码器更加通用。在本节中,可以将任何复合预测操作针对像素(i,j)概括为:: pf (i, j) = m(i, j)p1(i, j)+(1 − m(i, j))p2(i, j),其中p1和p2是两个预测变量,而pf是最终的复合预测,其中[0,1]中的加权系数m(i,j)专为不同的用例而设计,可以很容易从预定义表中生成。 [11]
•复合楔形预测:移动物体的边界通常很难通过网格块来近似分区。 AV1中的解决方案是预定义16个可能的楔形分区的代码簿,当编码单元选择同样以这种方式进一步分区时,在位流中发信号通知楔形索引。如图5所示,针对正方形和矩形块设计了16个形状的代码簿,其中包含水平,垂直或倾斜度为±2或±0.5的分区方向。为了减轻由两个预测变量直接并置而产生的寄生高频分量,采用软悬崖形的二维楔形遮罩对目标分区周围边缘进行平滑处理,即m(i,j)接近于0.5边缘,并逐渐在两端转换为二进制权重。
•差异调制的掩盖预测:楔形之类的直线分区并不总是有效地分离对象。因此,AV1复合预测变量还可以通过从两个预测变量的值不同的内容来创建非均匀加权。具体来说,p1和p2之间的像素差用于在基值之上调制权重。掩码通过m(i, j) = b+a|p1(i, j)−p2(i, j)|生成,其中b控制的是在不同区域内一个预测变量对另一个加权变量的加权强度,其中比例因子a则是为了实现平滑调制。
•基于帧距离的复合预测:除了权重不均匀以外,AV1还通过考虑帧距离来改进统一的加权方案。帧距离定义为两个帧的时间戳之间的绝对差。它自然表示从不同参考之间复制的运动补偿块的可靠性。当选择基于帧距离的复合模式时,令d1和d2(d1≥d2)代表从当前帧到参考帧的距离,并据此计算p1和p2,整个块使用同一个固定的权重值m。和直接线性加权不同,AV1定义了由d1/d2调制的量化权重,它平衡了重建参考的时间相关性和量化噪声。
•复合帧内预测:为了处理新内容和旧对象混杂的区域,AV1将帧内预测p1和单参考帧间预测p2结合在一起形成了复合帧内预测模式。对于帧内部分,支持4种常用帧内模式。遮罩m(i,j)包含两种类型的平滑功能:(i)类似于为楔间交互模式设计的平滑遮罩,(ii)依赖于模式的遮罩,其中权重p1,以内部模式的主方向为导向的衰减模式。
1)变换块分区:AV1无需像VP9中那样强制固定变换单元大小,而是允许亮度间编码块划分为多种大小的变换单元,这些递归分区最多可递减2级。为了合并AV的扩展编码块分区,我们支持从4×4到64×64的正方形,2:1/1:2和4:1/1:4比例也都可以。此外,色度转换单元总是要尽可能地大。
2)扩展的转换内核:为AV1中的帧内和帧间块定义了一组更丰富的转换内核。完整的2-D内核集由DCT,ADST,flipADST和IDTX [12]的16个水平/垂直组合组成。除了已在VP9中使用的DCT和ADST之外,flipADST则以相反的顺序应用ADST,并且身份变换(IDTX)意味着沿某个方向跳过变换编码,因此对于编码锐利边缘特别有用。随着块大小变大,某些内核开始发挥类似作用,因此,随着变换大小的增加,内核集会逐渐减少。
1)多符号熵编码:VP9使用基于树的布尔非自适应二进制算术编码器对所有语法元素进行编码。 AV1转而使用符号间自适应多符号算术编码器。 AV1中的每个语法元素都是N个元素的特定字母,上下文由一组N的概率以及一个为前期快速适应的计数之一。概率存储在15位累积分布函数(CDF)。与二进制算术编码器相比,精度更高,从而可以准确地跟踪字母表中不太常见的元素的概率。概率通过简单的递归缩放进行调整,其中更新因子基于字母大小。由于符号比特率是由编码系数、运动矢量和预测模式共同决定的,所有这些都使用大于2的字母,因此对于典型的编码方案,与纯二进制算术编码相比,这种设计实际上使吞吐量降低2倍以上。
在硬件方面,复杂度由核心乘法器的吞吐量和大小所决定,并且核心乘法器会重新调整算术编码状态间隔。编码实际上并不需要跟踪概率所需的较高精度。这允许通过从16×15位舍入到8×9位乘法器,来从根本上缩小乘法器的大小。通过强制执行最小间隔大小,来简化此舍入,这进一步简化的概率更新直至其值变为零。在软件层面,操作次数比复杂度更重要,并且减少吞吐量和简化更新相应地减少了每次编码/解码操作的固定开销。
2)电平图系数编码:在VP9中,编码引擎按照扫描顺序依次处理每个量化的变换系数。其中用于每个系数的概率模型,又与先前编码的系数级别、频带、及其变换块大小等相关。为了正确捕获广阔基数空间中的系数分布,AV1改而使用电平图设计以实现可观变换系数建模和压缩[13]。这一设计建立在以下研究基础之上:较低的系数水平通常占据了最主要的费率成本。
对于每个变换单元,AV1系数编码器从略过标志的编码开始,如果无需略过变换编码,则这一标志其后紧跟着的是变换内核类型和所有非零系数的结束位置。然后,对于系数值,并没有采用为所有系数级别统一分配上下文的模型,而是将级别分为不同的平面。较低级别的平面对应于0到2之间的系数级别,而较高级别的平面负责2以上的级别。这种分离允许我们将丰富的上下文模型分配给较低级别的平面,而这一平面充分考虑了变换维、块大小、以及邻近系数信息,以适度的上下文模型大小提高压缩效率。较高级别的平面对3到15之间的级别使用简化的上下文模型,并使用ExpGolomb代码直接对15级以上的残差进行编码。
AV1允许将多个环路滤波工具相继应用于解码帧数据的过程。第一级是解块滤波器,它与VP9中使用的解块滤波器大致相同,只是做了些微小改动。最长的滤波器从VP9中的15抽头减少到13抽头。此外,在亮度和每个色度平面的水平和垂直信号分量上,单独的信号过滤级别方面,有了更大的灵活性,以及将超级块级别的能力方面。 AV1中的其他过滤工具如下所述。
1)受约束的方向增强滤波器(CDEF):CDEF是一种保留细节的去环滤波器,应用于解块之后,其工作原理是估算边缘方向,然后使用大小为5×5的不可分离的具有12个非零权重的非线性低通定向滤波器[14]。为了避免额外的信令,解码器使用标准化快速搜索算法计算每8×8块的方向,该算法将来自理想方向图的二次误差最小化。该滤波器仅应用于具有编码预测残差的块。滤波器可以表示为: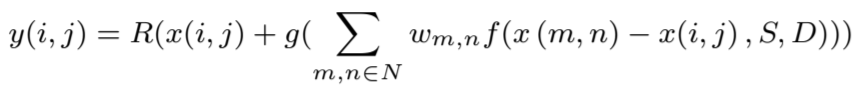
其中N包含x(i,j)附近的像素,权重wm,n,f()和g()是下面描述的非零非线性函数,R(x)将x舍入为最接近零的整数。 f()函数修改要过滤的像素与相邻像素之间的差异,并由分别在64×64块级别和帧级别指定的两个参数(强度S和阻尼值D)确定。强度S钳位允许的最大差值减去D所控制的削减。g()函数将要过滤的像素x的修改值限制为x与支撑区域中x(m,n)之间的最大差值保持滤波器的低通特性。
2)循环恢复过滤器:AV1在CDEF之后添加了一组用于循环应用的工具,这些工具的使用是相互斥的,其可选大小为64×64、128×128、或256×256的被称之为循环恢复单元(LRU)。具体来说,对于每个LRU,AV1允许在如下两个滤波器[15]之一之间进行选择。
•可分离对称归一化Wiener滤波器:使用7×7可分离Wiener滤波器对像素进行滤波,其系数用比特流中的信号表示。由于归一化和对称性约束,每个水平/垂直滤波器仅需要发送三个参数。编码器通过智能优化,选择正确滤波器抽头,但是解码器只使用从位流接收到的滤波器抽头。
•双自导滤波器:对于每个LRU,解码器首先应用两个简易的整数化自导滤波器,其支持大小分别为3×3和5×5,并通过比特流中的信号通知噪声参数。 (注意,自我引导意味着引导图像与要过滤的图像相同)。接下来,将两个滤波器r1和r2的输出与同样在比特流中用信号发送的权重(α,β)组合,以获得最终恢复的LRU为x + α(r1 − x) + β(r2 − x),其中x是原始降级的LRU。即使r1和r2本身不一定是好的,但在编码器端适当选择权重可使最终组合版本更接近于未降级的源。
3)帧超分辨率:AV1添加了一种新的帧超分辨率编码模式,该模式允许以较低的空间分辨率对帧进行编码,然后在更新参考缓冲区之前将其超解析地循环内完整解析为全分辨率。尽管这种方法有着非常低的比特率可感知优势,但是图像处理文献中,大多数超分辨率方法在视频编解码器中的环内操作,过于复杂。在AV1中,为了使操作在计算上易于处理,将超分辨过程分解为线性放大,然后以更高的空间分辨率应用循环恢复工具。特别地,维纳滤波器特别擅长超分辨和恢复丢失的高频。然后,唯一的附加规范操作是在使用循环恢复之前进行线性升频。此外,为了实现具有成本效益的硬件实现而在行缓冲器中没有任何开销,将上/下缩放限制为仅水平操作。图6描述了使用帧超分辨率时环路滤波管道的总体架构,其中CDEF以编码(较低)分辨率运行,但是在线性升频器水平扩展图像以解决部分分辨率后,环路恢复运行较高的频率丢失。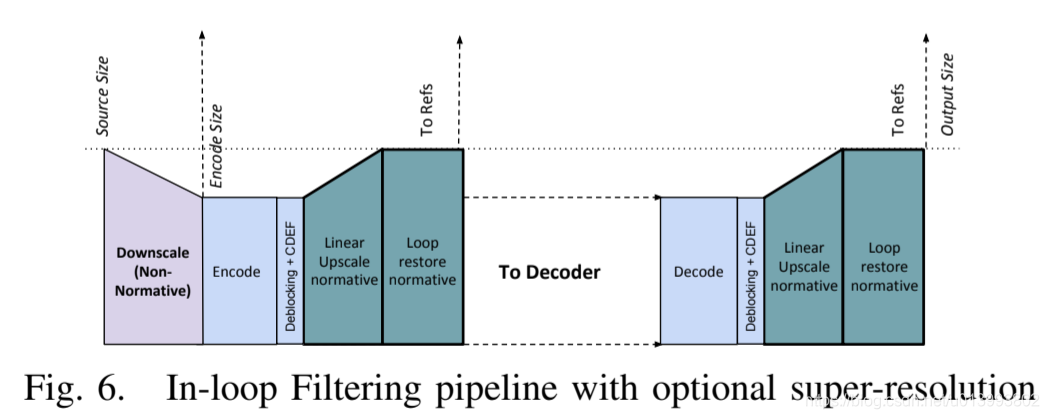
4)胶片颗粒合成:AV1中的胶片颗粒合成是在编码/解码循环之外进行的规范性后处理。电视和电影内容中丰富的电影颗粒通常是创作意图的一部分,在编码时需要保留。但是,胶片颗粒的随机性使其很难用传统的编码工具进行压缩。取而代之的是,在压缩之前将颗粒从内容中删除,然后估算其参数并在AV1比特流中发送。在解码器中,根据接收到的参数合成颗粒,并将其添加到重建的视频中。颗粒被建模为自回归(AR)过程,其中亮度的最高AR系数为24,每个色度分量的AR系数为25。这些系数用于生成64×64亮度颗粒模板和32×32色度模板。然后从模板中的随机位置获取小颗粒补丁并将其应用于视频。补丁之间的不连续性可以通过可选的重叠来缓解。薄膜的颗粒强度也随信号强度而变化,因此每个颗粒样品都按比例缩放[16]。
对于颗粒含量,薄膜颗粒的合成显著降低了以够用的质量重建颗粒所需的比特率。由于在重建图片中单个晶粒位置可能不匹配,因此该工具通常不会改善客观质量度量标准(例如PSNR),因此无法在第三节的比较中使用。
我们对比了在AOMedia的开放式测试平台AWCY [17]上使用AV1(2018年1月4日版)获得的编码性能与libvpx VP9编码器(2018年1月4日版)以及最新的x265版本(v2.6)的编码性能。这三个编解码器在AWCY Objective-1快速测试仪上运行,其中包括各种分辨率和类型的4:2:0 8位视频:12个普通1080p剪辑,4个1080p屏幕内容剪辑,7 720p剪辑和7 360p剪辑,都是60帧。在我们的测试中,AV1和VP9使用恒定质量(CQ)速率控制以2遍模式进行压缩,通过该模式,编解码器使用单个目标质量参数运行,该参数控制编码质量而未指定任何比特率约束。 AV1和VP9编解码器使用以下参数运行:
•–frame-parallel = 0 --tile-columns = 0 --auto-alt-ref = 2 --cpuused = 0 --passes = 2 --threads = 1 --kf-min-dist = 1000- kf-maxdist = 1000-lag-in-frames=25 --end-usage=q --cq-level = {20,32,43,55,63}和无限制的关键帧间隔。
需要说明的是,AV1 / VP9 2通道模式的第一通道只负责收集统计信息,而不是实际的编码。 x265,用于将视频编码为HEVC格式的库,还使用恒定速率因子(crf)速率控制,以其最佳质量模式(placebo)进行了测试。 x265编码器使用以下参数运行:
• --preset placebo --no-wpp --tune psnr --frame-threads 1 --minkeyint 1000 --keyint 1000 --no-scenecut with --crf ={15, 20, 25, 30, 35} 和无限制的关键帧间隔。
请注意,使用上述cq级别和crf值会使三个编解码器生成的RD曲线在有意义的范围内彼此接近,以进行BDRate计算。编码性能的差异显示在表I和表II中,以BDRate表示。负的BDRate意味着使用更少的位来达到相同的质量。 PSNR-Y,PSNR-Cb和PSNR-Cr是用于计算BDRate的客观指标。不幸的是,在撰写本文时,在AWCY测试台上,还没有实现PSNR度量来平均Y,Cb,Cr平面上的PSNR,我们将在以后的文献中更新结果。表I将AV1与VP9进行了比较,表明AV1在所有平面上的性能均比VP9实质上高出30%。同样,与x265相比,表II显示了当考虑主要质量因子PSNR-Y时,一致的22.75%编码增益,并且在Pb和Cr度量中,-40%的BDRate显示了Cb和Cr平面上更出色的编码能力。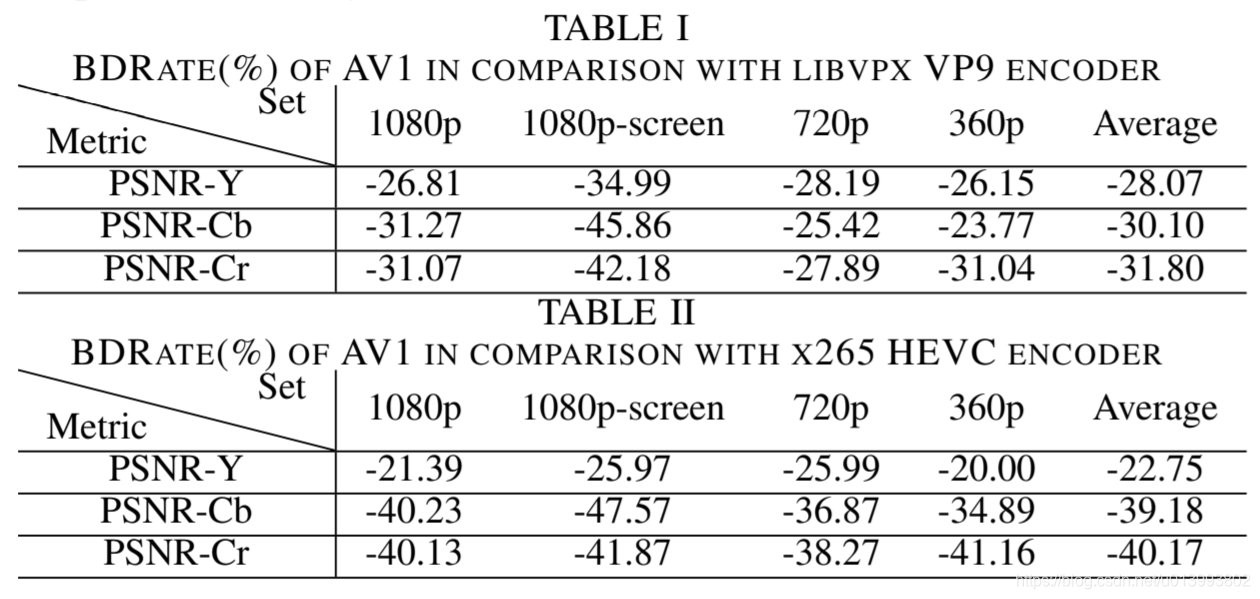
致谢
特别感谢所有AOMedia成员和AV1项目的个人贡献者的努力和奉献。由于篇幅所限,我们只列出参与起草本文的作者。
参考文献
[1] D. Mukherjee, J. Bankoski, A. Grange, J. Han, J. Koleszar, P. Wilkins,
Y. Xu, and R.S. Bultje, “The latest open-source video codec VP9 - an
overview and preliminary results,” Picture Coding Symposium (PCS),
December 2013.
[2] G. J. Sullivan, J. Ohm, W. Han, and T. Wiegand, “Overview of the
high efficiency video coding (HEVC) standard,” IEEE Transactions on
Circuits and Systems for Video Technology, vol. 22, no. 12, 2012.
[3] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of
the H.264/AVC video coding standard,” IEEE Transactions on Circuits
and Systems for Video Technology, vol. 13, no. 7, 2003.
[4] J. Bankoski, P. Wilkins, and Y. Xu, “Technical overview of VP8, an open
source video codec for the web,” IEEE Int. Conference on Multimedia
and Expo, December 2011.
[5] “Alliance for Open Media,” http://aomedia.org.
[6] L. N. Trudeau, N. E. Egge, and D. Barr, “Predicting chroma from luma
in AV1,” Data Compression Conference, 2018.
[7] W. Lin, Z. Liu, D. Mukherjee, J. Han, P. Wilkins, Y. Xu, and K. Rose,
“Efficient AV1 video coding using a multi-layer framework,” Data
Compression Conference, 2018.
[8] J. Han, Y. Xu, and J. Bankoski, “A dynamic motion vector referencing
scheme for video coding,” IEEE Int. Confernce on Image Processing,
2016.
[9] Y. Chen and D. Mukherjee, “Variable block-size overlapped block
motion compensation in the next generation open-source video codec,”
IEEE Int. Confernce on Image Processing, 2017.
[10] S. Parker, Y. Chen, and D. Mukherjee, “Global and locally adaptive
warped motion comprensationin video compression,” IEEE Int. Confernce on Image Processing, 2017.
[11] U. Joshi, D. Mukherjee, J. Han, Y. Chen, S. Parker, H. Su, A. Chiang,
Y. Xu, Z. Liu, Y. Wang, J. Bankoski, C. Wang, and E. Keyder, “Novel
inter and intra prediction tools under consideration for the emerging AV1
video codec,” Proc. SPIE, Applications of Digital Image Processing XL,
2017.
[12] S. Parker, Y. Chen, J. Han, Z. Liu, D. Mukherjee, H. Su, Y. Wang,
J. Bankoski, and S. Li, “On transform coding tools under development
for VP10,” Proc. SPIE, Applications of Digital Image Processing XXXIX,
2016.
[13] J. Han, C.-H. Chiang, and Y. Xu, “A level map approach to transform
coefficient coding,” IEEE Int. Confernce on Image Processing, 2017.
[14] S. Midtskogen and J.-M. Valin, “The AV1 constrained directional
enhancement filter (CDEF),” IEEE Int. Conference on Acoustics, Speech,
and Signal Processing, 2018.
[15] D. Mukherjee, S. Li, Y. Chen, A. Anis, S. Parker, and J. Bankoski,
“A switchable loop-restoration with side-information framework for the
emerging AV1 video codec,” IEEE Int. Confernce on Image Processing,
2017.
[16] A. Norkin and N. Birkbeck, “Film grain synthesis for AV1 video codec,”
Data Compression Conference, 2018.
[17] “AWCY,” arewecompressedyet.com.