针对图像的语义分割网络,本节将介绍PyTorch中已经预训练好网络的使用方式,然后使用VOC2012数据集训练一个FCN语义分割网络。
一、使用预训练好的语义分割网络
PyTorch提供了已预训练好的图像语义分割网络,已经预训练好的可供使用的网络模型如下表所示:
| 网络类 | 描述 |
| segmentation.fcn_resnet50() | 具有Resnet-50结构的全卷积网络模型 |
| segmentation.fcn_resnet101() | 具有Resnet-101结构的全卷积网络模型 |
| segmentation.deeplabv3_resnet50() | 具有Resnet-50结构的DeepLabV3网络模型 |
| segmentation.deeplabv3_resnet101() | 具有Resnet-101结构的DeepLabV3网络模型 |
下面以segmentation.fcn_resnet101()为例,介绍如何使用这些已经预训练好的网络结构进行图像的语义分割任务。
针对语义分割的分类器,需要输入图像使用了相同的预处理方式,即先将每张图像的像素值预处理到0 ~ 1之间,然后对图像进行标准化处理,使用的均值为[0.485,0.456,0.406],标准差为[0.229,0.224,0.225]。。数据集使用Pascal VOC 数据集,该数据集中存在20个类别和1个背景类,预训练好的模型在COCO train2017的子集上进行了预训练。这20个类别分为4个大类,分别为人、动物(鸟、猫、牛、马、羊)、交通工具(飞机、自行车、船、大巴、轿车、摩托车、火车)、室内物品(瓶子、椅子、餐桌、盆栽、沙发、显示器)等。
import torch
import torchvision
from torchvision import transforms
import numpy as np
import pandas as pd
import PIL
import PIL.Image as Image
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
model=torchvision.models.segmentation.fcn_resnet101(pretrained=True)
model.eval()#设置为验证模式
#下面从文件中读取一张图片进行预测
image=Image.open(r'C:\Users\zex\Downloads\VOCdevkit\VOC2012\JPEGImages\2012_001460.jpg')
image_trans=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]),])
image_tensor=image_trans(image).unsqueeze(0)
output=model(image_tensor)['out']
#将输出转化为二维图像
outputarg=torch.argmax(output.squeeze(),dim=0).numpy()
上述程序对一整幅图像的预测结果,只需要使用网络输出的"out"对应的预测矩阵即可,该输出是一个三维矩阵,该三维矩阵可以使用torch.argmax()将其转化为二维矩阵,并且该二维矩阵中的每个取值均代表图像中对应位置像素点的预测类别。为了更直观地查看网络的图像分割结果,可以将像素值的每个预测类别分别编码为不同的颜色,然后将图像可视化,用于直观地观察图像的结果。
定义一个编码颜色的函数decode_segmaps(),程序如下所示:
def decode_segmaps(image,label_colors,nc=21):
"""函数将输出的2D图像,会将不同的类编码为不同的颜色"""r=np.zeros_like(image).astype(np.uint8)g=np.zeros_like(image).astype(np.uint8)b=np.zeros_like(image).astype(np.uint8)for cla in range(0,nc):idx=image==clar[idx]=label_colors[cla,0]g[idx]=label_colors[cla,1]b[idx]=label_colors[cla,2]rgbimage=np.stack([r,g,b],axis=2)return rgbimage该函数通过参数label_colors来指定所有的颜色编码,然后对图像image中的不同像素点取值并定义一种颜色,nc参数指定数据的类别。下面对图像分割的结果进行可视化,程序如下所示:
label_colors=np.array([(0,0,0),(128,0,0),(0,128,0),(128,128,0),(0,0,128),(128,0,128),(0,128,128),(128,128,128),(64,0,0),(192,0,0),(64,128,0),(192,168,0),(64,0,128),(192,0,128),(64,128,128),(192,128,128),(0,64,0),(128,64,0),(0,192,0),(128,192,0),(0,64,128)])
outputrgb=decode_segmaps(outputarg,label_colors)
plt.figure(figsize=(20,8))
plt.subplot(1,2,1)
plt.imshow(image)
plt.axis("off")
plt.subplot(1,2,2)
plt.imshow(outputrgb)
plt.axis("off")
plt.subplots_adjust(wspace=0.05)
plt.show()
上面的程序中label_colors参数定义了每种类别需要使用的颜色编码,图像分割结果如下所示:

二、训练自己的语义分割网络
前面介绍的是使用预训练好的语义分割网络segmentation.fcn_resnet101(),对任意输入图像进行语义分割,该模型是以101层的ResNet网络为基础,全卷积语义分割模型。下面将基于VGG19网络,搭建、训练和测试自己的图像全卷积语义分割网络。
由于资源有限,将基于2012年VOC数据集对网络进行训练,主要使用该数据集的训练集和验证集,训练集用于训练网络,验证集防止网络过拟合。每个数据集约有1000张图片,并且图像之间的尺寸不完全相同,数据集共有21类需要学习的目标类别。
1.数据准备
针对VOC2012数据集,一共需要分割出的目标类别有21类,其中一类为背景。在标注好的图像中,每类对应的名称和颜色值如下:
classes=['background','aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable','dog','horse','motorbike','person','potted plant','sheep','sofa','train','tv/monitor']
colormap=[[0,0,0],[128,0,0],[0,128,0],[128,128,0],[0,0,128],[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],[64,128,0],[192,128,0],[64,0,128],[192,0,128],[64,128,128],[192,128,128],[0,64,0],[128,64,0],[0,192,0],[128,192,0],[0,64,128]]数据预处理需要对每张图像进行如下几个操作:
(1)将原始图像和标记好的图像所对应的图片路径一一对应。
(2)将图像统一切分为固定的尺寸时,需保持原始图像和其对应的标记好的图像,在切分后每个像素也仍然是一一对应的,所以需要对原始图像和目标的标记图像从相同的位置进行切分。在切分之前还需要过滤掉尺寸小于给定切分尺寸的图像。
(3)对原始图像进行数据标准化。
(4)针对标记好的图像,每张图像均是RGB图像,将RGB值对应的类重新定义,把3D的RGB图像转化为一个二维数据,并且数组中每个位置的取值对应着图像在该像素点的类别。
为了完成上述的图像预处理操作,定义下面几个图像数据预处理的辅助函数。
#给一个标定好的图片,将像素值对应的物体类别找出来
def image2label(image,colormap):# 将标签转化为每个像素值为一类cm2lbl=np.zeros(256**3)for i,cm in enumerate(colormap):cm2lbl[(cm[0]*256+cm[1]*256+cm[2])]=i#对一张图像转换image=np.array(image,dtype='int64')ix=(image[:,:,0]*256+image[:,:,1]*256+image[:,:,2])image2=cm2lbl[ix]return image2image2label函数可以将一张标记好的图像转化为类别标签图像。该函数完成的任务对应着上述操作(4)。
#随机裁剪图像数据
def rand_crop(data,label,high,width):im_width,im_high=data.size#生成图像随机点的位置left=np.random.randint(0,im_width-width)top=np.random.randint(0,im_high-high)right=left+widthbottom=top+highdata=data.crop((left,top,right,bottom))label=label.crop((left,top,right,bottom))return data,label
rand_crop函数完成对原始图像数据和被标注的标签图像进行随机裁剪的任务,随机裁剪后的原图像和标签的每个像素一一对应。可通过参数high和width指定图像裁剪后的高和宽。
#单组图像的转换操作
def img_transforms(data,label,high,width,colormap):data,label=rand_crop(data,label,high,width)data_tfs=transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])data=data_tfs(data)label=torch.from_numpy(image2label(label,colormap))return data,labelimg_transforms函数是对一组图像数据进行相关变换和预处理操作,包括数据的随机裁剪、将图像数据进行标准化、将标记图像数据进行二维标签化的操作,并且最后输出原始图像和类别标签的张量数据。
#定义读取数据路径的函数
def read_image_path(root=r"C:\Users\zex\Downloads\VOCdevkit\VOC2012\ImageSets\Segmentation\train.txt"):'''保存指定路径下的所有需要读取的图像文件路径'''image=np.loadtxt(root,dtype=str)n=len(image)data,label=[None]*n,[None]*nfor i,fname in enumerate(image):data[i]="C:/Users/zex/Downloads/VOCdevkit/VOC2012/JPEGImages/%s.jpg"%(fname)label[i]='C:/Users/zex/Downloads/VOCdevkit/VOC2012/SegmentationClass/%s.png'%(fname)return data,labelread_image_path函数是从给定的文件路径中定义出对应的原始图像和标记好的目标图像的存储路径列表。原始图像路径输出为data,标记好的目标图像路径输出为label。
为了将数据定义为数据加载器Data.DataLoader()函数可以接受的数据格式,在定义好上述几个辅助函数后,则需要定义一个类操作,该类需要继承torch.utils.data.Dataset类,这样就可以将自己的数据定义为数据加载器操作Data.DataLoader()函数可以接受的数据格式。程序如下所示:
#定义一个MyDataset
class MyDataset(Data.Dataset):"""用于读取图像,并进行相应的裁剪"""def __init__(self,data_root,high,width,imtransform,colormap):# data_root:数据所对应的文件名,high\width:图像剪裁后的尺寸# imtransform:预处理操作# colormap:颜色self.data_root=data_rootself.high=highself.width=widthself.imtransform=imtransformself.colormap=colormapdata_list,label_list=read_image_path(root=data_root)self.data_list=self._filter(data_list)self.label_list=self._filter(label_list)def _filter(self,images):#过滤掉图片大小小于指定high\width的图片return [im for im in images if (Image.open(im).size[1]>high and Image.open(im).size[0]>width)]def __getitem__(self, idx):img=self.data_list[idx]label=self.label_list[idx]img=Image.open(img)label=Image.open(label).convert('RGB')img,label=self.imtransform(img,label,self.high,self.width,self.colormap)return img,labeldef __len__(self):return len(self.data_list)在上面定义的类MyDataset包含了一个_filter方法,该方法用于过滤掉图像的尺寸小于固定切分尺寸的样本。在类中每张图像的读取通过Image.open()函数完成。
下面使用MyDataset()函数读取数据集的原始数据和对应的标签数据,然后使用Data.DataLoader()函数建立数据加载器,并且每个batch中包含8张图像,程序如下所示:
#读取数据
high,width=320,480
voc_train=MyDataset(r"C:\Users\zex\Downloads\VOCdevkit\VOC2012\ImageSets\Segmentation\train.txt",high,width,img_transforms,colormap)
voc_val=MyDataset(r"C:\Users\zex\Downloads\VOCdevkit\VOC2012\ImageSets\Segmentation\val.txt",high,width,img_transforms,colormap)
#创建数据加载器每个batch使用4张图像
train_loader=Data.DataLoader(voc_train,batch_size=8,shuffle=True,pin_memory=True)
val_loader=Data.DataLoader(voc_val,batch_size=8,shuffle=True,pin_memory=True)#检查一个训练集的batch的样本的维度是否正确
for step,(b_x,b_y) in enumerate(train_loader):if step>0:break
print("b_x.shape",b_x.shape)
print('b_y.shape',b_y.shape)
从一个batch的图像尺寸输出中可以看出,训练数据中的b_x包含8张320×480的RGB图像,而b_y则包含8张320×480的类别标签数据。下面可以将一个batch的图像和其标签进行可视化,以检查数据是否预处理正确,在可视化之前需要定义两个预处理函数,即inv_normalize_image()和label2image()。
#将标准化后的图像转化为0-1之间
def inv_normalize_image(data):rgb_mean=np.array([0.485,0.456,0.406])rgb_std=np.array([0.229,0.224,0.225])data=data.astype('float32')*rgb_std+rgb_meanreturn data.clip(0,1)
#从预测的标签转化为图像的操作
def label2image(prelabel,colormap):#预测到的标签转化为图像,针对一个标签图h,w=prelabel.shapeprelabel=prelabel.reshape(h*w,-1)image=np.zeros((h*w,3),dtype='int32')for i in range(len(colormap)):index=np.where(prelabel==i)image[index,:]=colormap[i]return image.reshape(h,w,3)
在上面的两个函数中,inv_normalize_image函数用于将标准化后的原始图像进行逆标准化操作,可方便对图像数据进行可视化;而label2image函数则是将二维的类别标签数据转化为三维的图像分割后的数据,不同的类别转化为特定的RGB值。下面针对一个batch的图像进行可视化操作,程序如下所示:
#可视化一个batch的图像
b_x_numpy=b_x.data.numpy()
b_x_numpy=b_x_numpy.transpose(0,2,3,1)
b_y_numpy=b_y.data.numpy()
plt.figure(figsize=(32,12))
for i in range(8):plt.subplot(2,8,i+1)plt.imshow(inv_normalize_image(b_x_numpy[i]))plt.axis('off')plt.subplot(2,8,i+9)plt.imshow(label2image(b_y_numpy[i],colormap))plt.axis("off")
plt.subplots_adjust(wspace=0.5,hspace=0.5)
plt.show()
2.搭建网络
搭建全卷积语义分割时,基础网络是预训练的VGG19网络,而且不需要使用全连接层,该网络可以直接从torchvision库中导入。下面导人VGG19网络,并对其网络结构进行简单的分析,程序如下:
model_vgg19=vgg19(pretrained=True)
base_model=model_vgg19.features下面搭建基于FCN-8s的语义分割网络,通过将网络中间的输出联合起来进行转置卷积,从而获得更多有用的语义分割信息,所以可以得到更好的语义分割结果。其操作方式可以使用下图展示。
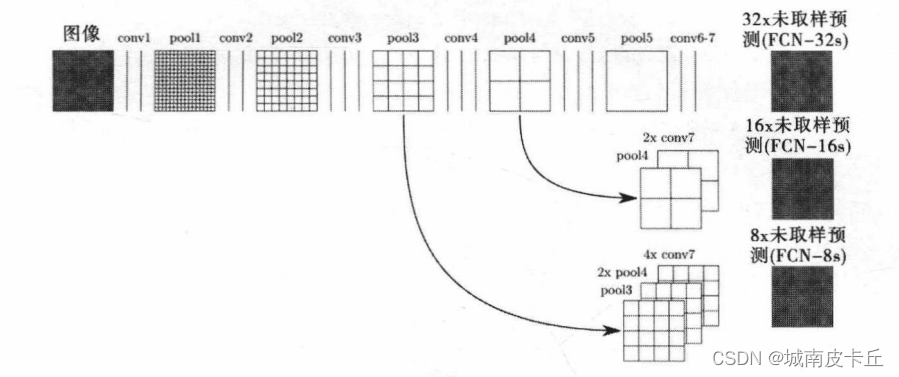
上图展示了不同的FCN语义分割操作方法,其中FCN-32s就是将最后的卷积或池化结果通过转置卷积,直接将特征映射的尺寸扩大32倍进行输出,而FCN-16s则是联合前面一次的结果将特征映射进行16倍的放大输出,而FCN-8s是联合前面两次的结果,通过转置卷积将特征映射的尺寸进行8倍的放大输出。在FCN-8s中将进行以下的操作步骤:
(1)将最后一层的特征映射P5(在VGG19中是第5个最大值池化层)通过转置卷积扩大2倍,得到新的特征映射T5,并和pool4的特征映射P4相加可得到T5+P4。
(2)将T5+P4通过转置卷积扩大2倍得到T4,然后与pool3的特征映射P3相加得到T4+P3。
(3)通过转置卷积,将特征映射T4+P3的尺寸扩大8倍,得到和输入形状一样大的结果。
下面搭建语义分割网络FCN-8s,用于图像的语义分割,程序如下所示:
#定义FCN分割网络
class FCN8s(nn.Module):def __init__(self,num_classes):super(FCN8s, self).__init__()#num_classes:训练数据的类别self.num_classes=num_classesmodel_vgg19=vgg19(pretrained=True)#不使用VGG19网络中后面的AdaptiveAvgPool2d和Linear层self.base_model=model_vgg19.features#定义几个需要的层操作,并且使用转置卷积将特征映射进行升维度self.relu=nn.ReLU(inplace=True)self.deconv1=nn.ConvTranspose2d(512,512,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1)self.bn1=nn.BatchNorm2d(512)self.deconv2=nn.ConvTranspose2d(512,256,3,2,1,1,1)self.bn2=nn.BatchNorm2d(256)self.deconv3=nn.ConvTranspose2d(256,128,3,2,1,1,1)self.bn3=nn.BatchNorm2d(128)self.deconv4=nn.ConvTranspose2d(128,64,3,2,1,1,1)self.bn4=nn.BatchNorm2d(64)self.deconv5=nn.ConvTranspose2d(64,32,3,2,1,1,1)self.bn5=nn.BatchNorm2d(32)self.classifier=nn.Conv2d(32,num_classes,kernel_size=1)#VGG19中MaxPool2D层self.layers={'4':'maxpool_1','9':'maxpool_2','18':'maxpool_3','27':'maxpool_4','36':'maxpool_5'}def forward(self,x):output={}for name,layer in self.base_model._modules.items():# 从第一层开始获取图像特征x=layer(x)#如果是layers参数指定的特征,那就保存到output中if name in self.layers:output[self.layers[name]]=xx5=output['maxpool_5']x4=output['maxpool_4']x3=output['maxpool_3']#对特征进行相关的卷积操作score=self.relu(self.deconv1(x5))score=self.bn1(score+x4)score=self.relu(self.deconv2(score))score=self.bn2(score+x3)score=self.bn3(self.relu(self.deconv3(score)))score=self.bn4(self.relu(self.deconv4(score)))score=self.bn5(self.relu(self.deconv5(score)))score=self.classifier(score)return score上述的语义分割网络类FCN-8s是基于VGG19建立的,且在网络的前向传播中,分别保存网络在最大值池化层的输出,方便后面对相应层输出的使用,该类使用时需要输入一个参数num_classes,用于表示网络需要分类的数量。
3、网络训练和测试
使用训练集对网络FCN-8s进行训练,使用验证集监督网络的训练过程,定义train_model()函数,该函数按照指定的优化方法,使用相关数据对网络模型训练一定的次数,并输出训练过程中最优的网络模型。函数的程序如下所示:
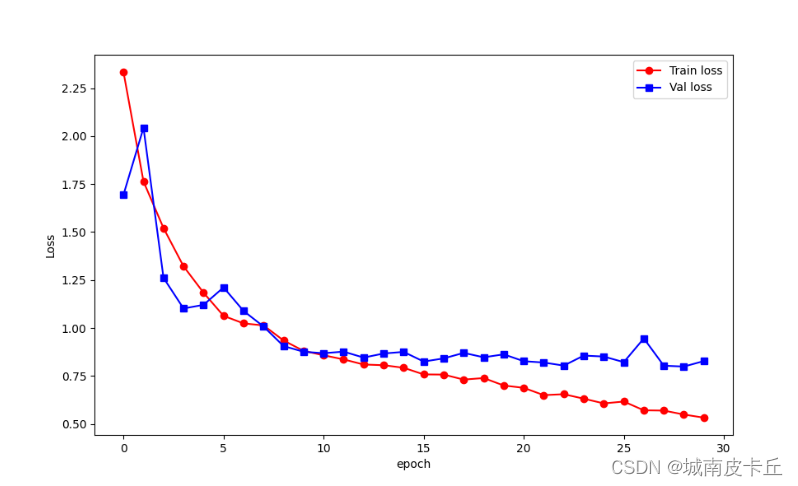
def train_model(model,criterion,optimizer,traindataloader,valdataloader,num_epochs=25):since=time.time()best_model_wts=copy.deepcopy(model.state_dict())best_loss=1e10train_loss_all=[]train_acc_all=[]val_loss_all=[]val_acc_all=[]since=time.time()for epoch in range(num_epochs):print("Epoch {} / {}".format(epoch,num_epochs-1))print('-'*10)train_loss=0.0train_num=0val_loss=0.0val_num=0#每个epoch包括训练和验证阶段model.train()#设置模型为训练模式for step,(b_x,b_y) in enumerate(traindataloader):optimizer.zero_grad()b_x=b_x.float().to(device)b_y=b_y.long().to(device)out=model(b_x)out=F.log_softmax(out,dim=1)pre_lab=torch.argmax(out,1)#预测的标签loss=criterion(out,b_y)loss.backward()optimizer.step()train_loss += loss.item() * len(b_y)train_num += len(b_y)#计算一个epoch在训练集上的损失和精度train_loss_all.append(train_loss / train_num)print('{} Train loss : {:.4f}'.format(epoch,train_loss_all[-1]))#计算一个epoch训练后在验证集上的损失model.eval()#设置模式为评估模式for step,(b_x,b_y) in enumerate(valdataloader):b_x=b_x.float().to(device)b_y=b_y.long().to(device)out=model(b_x)out=F.log_softmax(out,dim=1)pre_lab=torch.argmax(out,1)loss=criterion(out,b_y)val_loss+=loss.item() * len(b_y)val_num+=len(b_y)val_loss_all.append(val_loss /val_num)print('{} Val loss : {:.4f}'.format(epoch,val_loss_all[-1]))#保存最好的网络参数if val_loss_all[-1]<best_loss:best_loss=val_loss_all[-1]best_model_wts=copy.deepcopy(model.state_dict())#每个epoch的花费时间time_use=time.time()-sinceprint("Train and val complete in {:.0f}m {:.0f}s".format(time_use // 60,time_use % 60))train_process=pd.DataFrame(data={'epoch':range(num_epochs),'train_loss_all':train_loss_all,'val_loss_all':val_loss_all,})model.load_state_dict(best_model_wts)return model,train_process下面定义优化方法和损失函数,并调用函数对网络进行训练,在网络训练结束后,通过折线图将网络在训练过程中的损失函数变化情况进行可视化,程序如下所示。
criterion=nn.NLLLoss()
optimizer=optim.Adam(fcn8s.parameters(),lr=0.0003,weight_decay=1e-4)
#对模型进行迭代训练,对所有数据训练epoch轮
fcn8s,train_process=train_model(fcn8s,criterion,optimizer,train_loader,val_loader,num_epochs=30)
#保存训练好的网络fcn8s
torch.save(fcn8s,'fcn8s.pkl')
#可视化训练过程
plt.figure(figsize=(10,6))
plt.plot(train_process.epoch,train_process.train_loss_all,'ro-',label='Train loss')
plt.plot(train_process.epoch.train_process.val_loss_all,'bs-',label="Val loss")
plt.legend()
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.show()
下面使用训练好的网络,从验证集中获取一个batch的图像,对其进行语义分割,将得到的结果和人工标注的结果进行对比,可使用下面的程序进行可视化,得到如下图所示的结果。

上图第一行所示为原始的RGB图像,第二行所示为人工标注的语义分割图像,第三行所示为网络对图像的分割结果。从对比图中可以看出网络虽然可以分割出一些目标,但是在精度上并不是很高,还有很大的提升空间。这与我们使用的基础网络深度不够、使用的训练数据较少有关。
![[学习笔记]计算机图形学(一)](https://img-blog.csdnimg.cn/img_convert/1460cdbf0d4754eca14b73389e9564c9.png)