目录
- 一、概述
- 1. 反压的理解
- 2. 反压的危害
- 二、定位反压节点
- 1. 利用 Flink Web UI 定位
- 2. 利用 Metrics 定位
- 三、反压的原因及处理
- 1. 查看是否数据倾斜
- 2. 使用火焰图分析
- 3. 分析 GC 情况
- 4. 外部组件交互
一、概述
Flink 网络流控及反压的介绍:https://flink-learning.org.cn/article/detail/138316d1556f8f9d34e517d04d670626
1. 反压的理解
简单来说,Flink 拓扑中每个节点(Task)间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,最终导致数据源的摄入被阻塞。
反压 (BackPressure) 通常产生于这样的场景:短时间的负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或遇到大促、秒杀活动导致流量陡增。
2. 反压的危害
反压如果不能得到正确的处理,可能会影响到 checkpoint 时长和 state 大小,甚至可能会导致资源耗尽甚至系统崩溃。
(1) 影响 checkpoint 时长:barrier 不会越过普通数据,数据处理被阻塞也会导致 checkpoint barrier 流经整个数据管道的时长变长,导致 checkpoint 总体时间(End to End Duration)变长。
(2) 影响 state 大小:barrier 对齐时,接受到较快的输入管道的 barrier 后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达,这些被缓存的数据会被放到 state 里面,导致 checkpoint 变大。
这两个影响对于生产环境的作业来说是十分危险的,因为 checkpoint 是保证数据一致性的关键,checkpoint 时间变长有可能导致 checkpoint 超时失败,而 state 大小同样可能拖慢 checkpoint 甚至导致 OOM (使用 Heap-based StateBackend)或者物理内存使用超出容器资源(使用 RocksDBStateBackend)的稳定性问题。因此,我们在生产中要尽量避免出现反压的情况。
二、定位反压节点
解决反压首先要做的是定位到造成反压的节点,排查的时候,先把 operator chain 禁用,方便定位到具体算子。
提交 UvDemo:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
1. 利用 Flink Web UI 定位
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,1.13 版本以前是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为 OK,0.1 至 0.5 为 LOW,而超过 0.5 则为 HIGH。
Flink 1.13 优化了反压检测的逻辑(使用基于任务 Mailbox 计时,而不在再于堆栈采样),并且重新实现了作业图的 UI 展示:Flink 现在在 UI 上通过颜色和数值来展示繁忙和反压的程度。
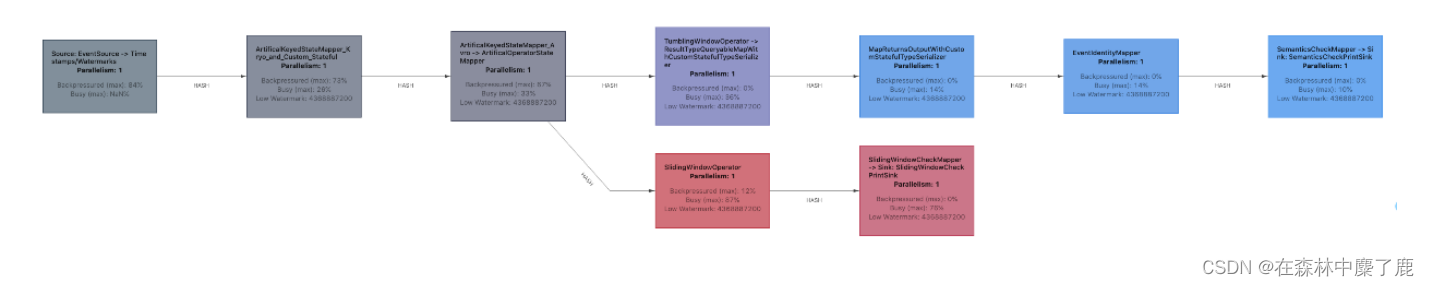
1)通过 WebUI 看到 Map 算子处于反压:
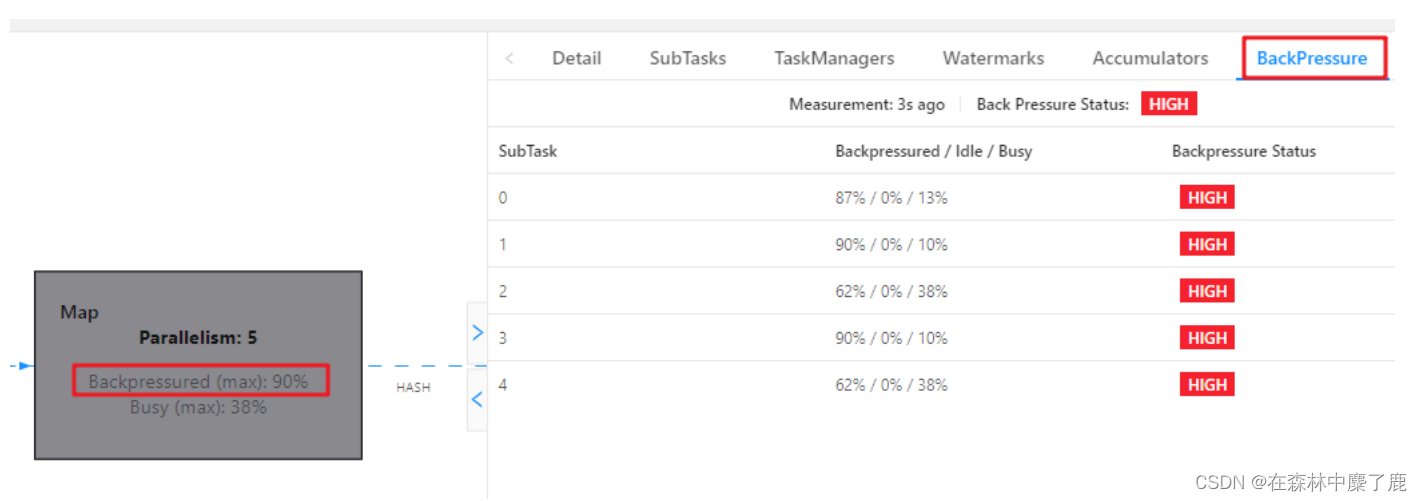
2)分析瓶颈算子
如果处于反压状态,那么有两种可能性:
(1)该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条输出的Operator(比如 flatmap)。这种情况,该节点是反压的根源节点,它是从 Source Task 到 Sink Task 的第一个出现反压的节点。
(2)下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。这种情况,需要继续排查下游节点,一直找到第一个为 OK 的一般就是根源节点。总体来看,如果我们找到第一个出现反压的节点,反压根源要么是就这个节点,要么是它紧接着的下游节点。
通常来讲,第二种情况更常见。如果无法确定,还需要结合 Metrics 进一步判断。
2. 利用 Metrics 定位
监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics:
| Metris | 描述 |
|---|---|
| outPoolUsage | 发送端 Buffer 的使用率 |
| inPoolUsage | 接收端 Buffer 的使用率 |
| floatingBuffersUsage(1.9 以上) | 接收端 Floating Buffer 的使用率 |
| exclusiveBuffersUsage(1.9 以上) | 接收端 Exclusive Buffer 的使用率 |
其中 inPoolUsage = floatingBuffersUsage + exclusiveBuffersUsage。
1)根据指标分析反压
分析反压的大致思路是:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。反压情况可以根据以下表格进行对号入座(1.9 以上):
| outPoolUsage 低 | outPoolUsage 高 | |
|---|---|---|
| inPoolUsage 低 | 正常 | ① 被下游反压,处于临时情况(还没传递到上游)②可能是反压的根源,一条输入多条输出的场景 |
| inPoolUsage 高 | ① 如果上游所有 outPoolUsage 都是低,有可能最终可能导致反压 (还没传递到上游) ②如果上游的 outPoolUsage 是高,则为反压根源 | 被下游反压 |
2)可以进一步分析数据传输
Flink 1.9及以上版本,还可以根据 floatingBuffersUsage/exclusiveBuffersUsage 以及其上游 Task 的 outPoolUsage 来进行进一步的分析一个 Subtask 和其上游Subtask 的数据传输。
在流量较大时,Channel 的 Exclusive Buffer 可能会被写满,此时 Flink 会向 BufferPool 申请剩余的 Floating Buffer。这些 Floating Buffer 属于备用 Buffer。
| exclusiveBuffersUsage 低 | exclusiveBuffersUsage 高 | |
|---|---|---|
| ① floatingBuffersUsage 低 ② 所有上游 outPoolUsage 低 | 正常 | |
| ① floatingBuffersUsage 低 ② 上游某个 outPoolUsage 高 | 潜在的网络瓶颈 | |
| ① floatingBuffersUsage 高 ② 所有上游 outPoolUsage 低 | 最终对部分 inputChannel 反压 (正在传递) | 最终对大多数或所有 inputChannel反压 (正在传递) |
| ① floatingBuffersUsage 高 ②上游某个 outPoolUsage 高 | 只对部分 inputChannel 反压 | 对大多数或所有inputChannel 反压 |
总结:
- floatingBuffersUsage 为高,则表明反压正在传导至上游
- 同时 exclusiveBuffersUsage 为低,则表明可能有倾斜
比如,floatingBuffersUsage 高、exclusiveBuffersUsage 低为有倾斜,因为少数channel 占用了大部分的 Floating Buffer。
三、反压的原因及处理
注意:反压可能是暂时的,可能是由于负载高峰、CheckPoint 或作业重启引起的数据积压而导致反压。如果反压是暂时的,应该忽略它。另外,请记住,断断续续的反压会影响我们分析和解决问题。
定位到反压节点后,分析造成原因的办法主要是观察 Task Thread。按照下面的顺序,一步一步去排查。
1. 查看是否数据倾斜
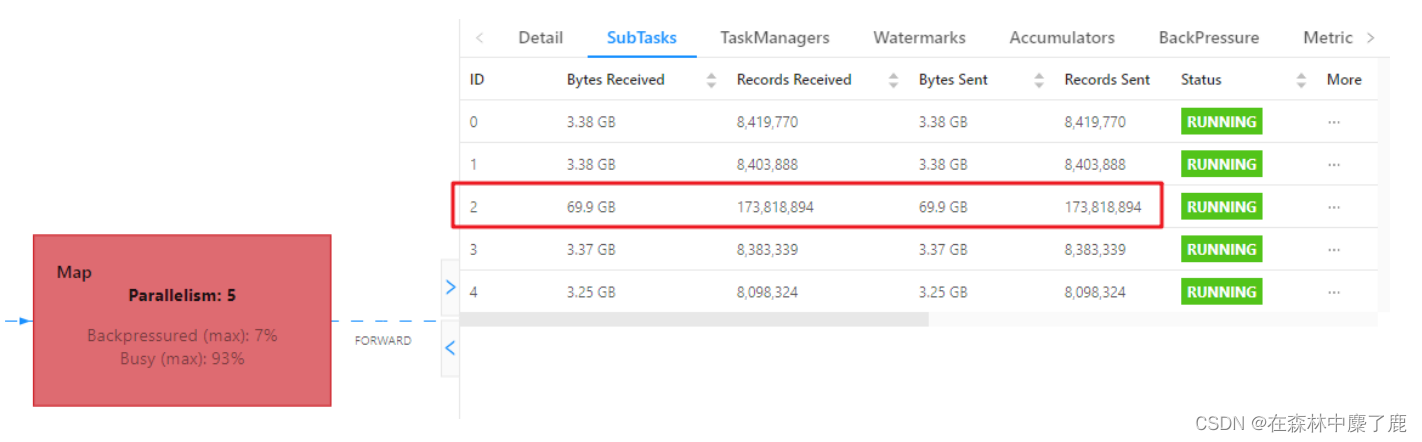
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
2. 使用火焰图分析
如果不是数据倾斜,最常见的问题可能是用户代码的执行效率问题 (频繁被阻塞或者性能问题),需要找到瓶颈算子中的哪部分计算逻辑消耗巨大。
最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到 Task Thread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面;如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
1)开启火焰图功能
Flink 1.13 直接在 WebUI 提供 JVM 的 CPU 火焰图,这将大大简化性能瓶颈的分析,默认是不开启的,需要修改参数:
rest.flamegraph.enabled: true #默认 false
也可以在提交时指定:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Drest.flamegraph.enabled=true \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
2)WebUI 查看火焰图
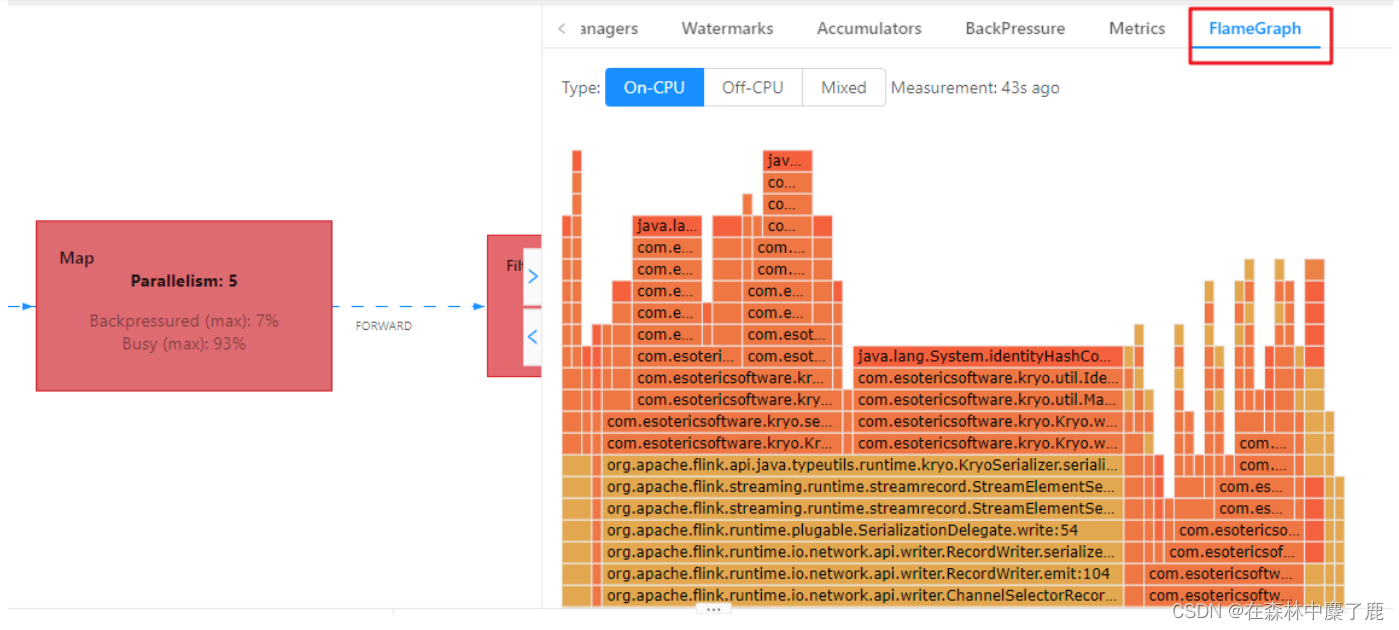
火焰图是通过对堆栈跟踪进行多次采样来构建的。每个方法调用都由一个条形表示,其中条形的长度与其在样本中出现的次数成正比。
- On-CPU: 处于 [RUNNABLE, NEW]状态的线程
- Off-CPU: 处于 [TIMED_WAITING, WAITING, BLOCKED]的线程,用于查看在样本中发现的阻塞调用。
3)分析火焰图
颜色没有特殊含义,具体查看:
➢ 纵向是调用链,从下往上,顶部就是正在执行的函数
➢ 横向是样本出现次数,可以理解为执行时长。
看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
如果是 Flink 1.13 以前的版本,可以手动做火焰图:
如何生成火焰图:http://www.54tianzhisheng.cn/2020/10/05/flink-jvm-profiler/
3. 分析 GC 情况
TaskManager 的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。通常建议使用默认的 G1 垃圾回收器。
可以通过打印 GC 日志(-XX:+PrintGCDetails),使用 GC 分析器(GCViewer 工具)来验证是否处于这种情况。
➢ 在 Flink 提交脚本中,设置 JVM 参数,打印 GC 日志:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Denv.java.opts="-XX:+PrintGCDetails -XX:+PrintGCDateStamps" \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
➢ 下载 GC 日志的方式:
因为是 on yarn 模式,运行的节点一个一个找比较麻烦。可以打开 WebUI,选择JobManager 或者 TaskManager,点击 Stdout,即可看到 GC 日志,点击下载按钮即可将 GC 日志通过 HTTP 的方式下载下来。

➢ 分析 GC 日志:
通过 GC 日志分析出单个 Flink Taskmanager 堆总大小、年轻代、老年代分配的内存空间、Full GC 后老年代剩余大小等,相关指标定义可以去 Github 具体查看。
GCViewer 地址:https://github.com/chewiebug/GCViewer
Linux 下分析:
java -jar gcviewer_1.3.4.jar gc.log
Windows 下分析:
直接双击 gcviewer_1.3.4.jar,打开 GUI 界面,选择 gc 的 log 打开
扩展:最重要的指标是 Full GC 后,老年代剩余大小这个指标,按照《Java 性能优化权威指南》这本书 Java 堆大小计算法则,设 Full GC 后老年代剩余大小空间为 M,那么堆的大小建议 3 ~ 4 倍 M,新生代为 1 ~ 1.5 倍 M,老年代应为 2 ~ 3 倍 M。
4. 外部组件交互
如果发现我们的 Source 端数据读取性能比较低或者 Sink 端写入性能较差,需要检查第三方组件是否遇到瓶颈,还有就是做维表 join 时的性能问题。
例如:
Kafka 集群是否需要扩容,Kafka 连接器是否并行度较低
HBase 的 rowkey 是否遇到热点问题,是否请求处理不过来
ClickHouse 并发能力较弱,是否达到瓶颈
……
关于第三方组件的性能问题,需要结合具体的组件来分析,最常用的思路:
1)异步 io+热缓存来优化读写性能
2)先攒批再读写
维表 join 参考:
https://flink-learning.org.cn/article/detail/b8df32fbc6542257a5b449114e137cc3
https://www.jianshu.com/p/a62fa483ff54
![[2019.01.24]JNI经验积累](https://img-blog.csdnimg.cn/7516100b75f446b29da86e26a5bf453f.png)