机器学习笔记之Sigmoid信念网络——KL散度角度观察醒眠算法
引言
上一节介绍了MCMC以及平均场理论变分推断方法的弊端并介绍了醒眠算法(Weak-Sleep Algorithm)。本节将介绍从KL散度(KL Divergence)角度观察醒眠算法的两个迭代步骤。
回顾: 醒眠算法过程
这里以一个比较简单的 Sigmoid \text{Sigmoid} Sigmoid信念网络概率图结构为例:
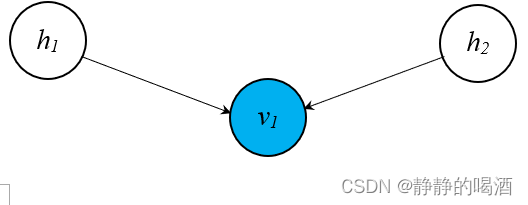
醒眠算法包括两个步骤:
- Weak Phase : \text{Weak Phase :} Weak Phase : 其本质上是通过采样的方式得到一个关于 P ( h ∣ v ) \mathcal P(h \mid v) P(h∣v)的近似后验。以某具体样本 v ( i ) = v 1 ( i ) v^{(i)} = v_1^{(i)} v(i)=v1(i)为例,它关于隐变量的后验概率分布表示如下:
这里的示例比较简单,样本中仅包含一个随机变量。
P ( h ( i ) ∣ v ( i ) ) = P ( h 1 ( i ) , h 2 ( i ) ∣ v 1 ( i ) ) \mathcal P(h^{(i)} \mid v^{(i)}) = \mathcal P(h_1^{(i)},h_2^{(i)} \mid v_1^{(i)}) P(h(i)∣v(i))=P(h1(i),h2(i)∣v1(i))
这明显是关于 h 1 ( i ) , h 2 ( i ) h_1^{(i)},h_2^{(i)} h1(i),h2(i)的 联合后验分布——那么 Weak Phase \text{Weak Phase} Weak Phase是如何实现近似后验的呢? Weak Phase \text{Weak Phase} Weak Phase具体过程表示如下(红色线):
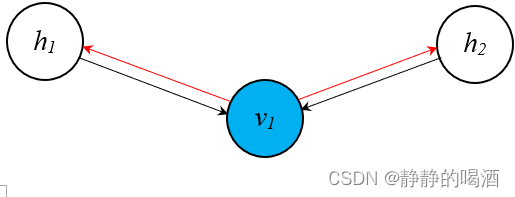
以具体样本 v ( i ) = v 1 ( i ) v^{(i)} = v_1^{(i)} v(i)=v1(i)为基础,对隐变量的后验进行采样。根据概率图模型——贝叶斯网络结构表示红色线部分明显是一个同父结构(Common Parent)。因而在给定(可观测) v 1 ( i ) v_1^{(i)} v1(i)的条件下, h 1 ( i ) , h 2 ( i ) h_1^{(i)},h_2^{(i)} h1(i),h2(i)之间相互独立:
P ( h 1 ( i ) , h 2 ( i ) ∣ v 1 ( i ) ) = P ( h 1 ( i ) ∣ v 1 ( i ) ) ⋅ P ( h 2 ( i ) ∣ v 1 ( i ) ) \mathcal P(h_1^{(i)},h_2^{(i)} \mid v_1^{(i)}) = \mathcal P(h_1^{(i)} \mid v_1^{(i)}) \cdot \mathcal P(h_2^{(i)} \mid v_1^{(i)}) P(h1(i),h2(i)∣v1(i))=P(h1(i)∣v1(i))⋅P(h2(i)∣v1(i))
h 1 ( i ) , h 2 ( i ) h_1^{(i)},h_2^{(i)} h1(i),h2(i)各自的后验概率分布分别表示为:
这里用R \mathcal R R替代上一节的r r r,更容易分辨些~
P ( h 1 ( i ) ∣ v 1 ( i ) ) = { σ ( R v 1 ( i ) → h 1 ( i ) ⋅ v 1 ( i ) ) h 1 ( i ) = 1 1 − σ ( R v 1 ( i ) → h 1 ( i ) ⋅ v 1 ( i ) ) h 1 ( i ) = 0 P ( h 2 ( i ) ∣ v 1 ( i ) ) = { σ ( R v 1 ( i ) → h 2 ( i ) ⋅ v 1 ( i ) ) h 2 ( i ) = 1 1 − σ ( R v 1 ( i ) → h 2 ( i ) ⋅ v 1 ( i ) ) h 2 ( i ) = 0 \mathcal P(h_1^{(i)} \mid v_1^{(i)}) = \begin{cases} \sigma \left(\mathcal R_{v_1^{(i)} \to h_1^{(i)}} \cdot v_1^{(i)}\right) \quad h_1^{(i)} = 1 \\ 1 - \sigma \left(\mathcal R_{v_1^{(i)} \to h_1^{(i)}} \cdot v_1^{(i)}\right) \quad h_1^{(i)} = 0 \\ \end{cases} \\ \mathcal P(h_2^{(i)} \mid v_1^{(i)}) = \begin{cases} \sigma \left(\mathcal R_{v_1^{(i)} \to h_2^{(i)}} \cdot v_1^{(i)}\right) \quad h_2^{(i)} = 1 \\ 1 - \sigma \left(\mathcal R_{v_1^{(i)} \to h_2^{(i)}} \cdot v_1^{(i)}\right) \quad h_2^{(i)} = 0 \\ \end{cases} P(h1(i)∣v1(i))=⎩ ⎨ ⎧σ(Rv1(i)→h1(i)⋅v1(i))h1(i)=11−σ(Rv1(i)→h1(i)⋅v1(i))h1(i)=0P(h2(i)∣v1(i))=⎩ ⎨ ⎧σ(Rv1(i)→h2(i)⋅v1(i))h2(i)=11−σ(Rv1(i)→h2(i)⋅v1(i))h2(i)=0
至此,已经求出 P ( h 1 ( i ) ∣ v 1 ( i ) ) ⋅ P ( h 2 ( i ) ∣ v 1 ( i ) ) \mathcal P(h_1^{(i)} \mid v_1^{(i)}) \cdot \mathcal P(h_2^{(i)} \mid v_1^{(i)}) P(h1(i)∣v1(i))⋅P(h2(i)∣v1(i))结果了,但为什么称它为近似后验呢?很简单,因为 Weak Phase \text{Weak Phase} Weak Phase过程的那两条红色线是自己假设的,真实模型中是不存在的。
因此,使用因子分解的方式将 P ( h 1 ( i ) , h 2 ( i ) ∣ v 1 ( i ) ) \mathcal P(h_1^{(i)},h_2^{(i)} \mid v_1^{(i)}) P(h1(i),h2(i)∣v1(i))分解成 P ( h 1 ( i ) ∣ v 1 ( i ) ) ⋅ P ( h 2 ( i ) ∣ v 1 ( i ) ) \mathcal P(h_1^{(i)} \mid v_1^{(i)}) \cdot \mathcal P(h_2^{(i)} \mid v_1^{(i)}) P(h1(i)∣v1(i))⋅P(h2(i)∣v1(i))的形式并分别求解的结果是近似结果,必然会影响精度。但 Weak Phase \text{Weak Phase} Weak Phase过程并不是追求精度,而是追求效率。这种近似方式所采集的样本仅需要 一次采样过程 即可近似出来,而不是像MCMC要等到平稳分布才可以停止采样。
虽然‘基于平均场假设变分推断’没有涉及采样,但同样相比不动点方程收敛过程要效率的多。 - Sleep Phase : \text{Sleep Phase : } Sleep Phase : 该过程整个是 Sigmoid \text{Sigmoid} Sigmoid信念网络信息的正常传递过程,这个过程是基于模型产生的。也称生成过程。
按照这个顺序得到的结果自然是关于‘观测变量后验概率的结果’P ( v ′ ∣ h ) \mathcal P(v' \mid h) P(v′∣h),相当于通过模型生成新的样本,自然是生成过程。
这里的v ′ v' v′表示从模型中产生的样本结果,这个样本不同于v v v,因为v v v是从真实分布中产生的样本:v ⇒ P d a t a v \Rightarrow \mathcal P_{data} v⇒Pdata;而v ′ v' v′是从模型中产生的样本v ′ ⇒ P m o d e l v' \Rightarrow \mathcal P_{model} v′⇒Pmodel.
关于生成模型建模, P ( v ∣ h ) \mathcal P(v \mid h) P(v∣h)还是 P ( v , h ) \mathcal P(v,h) P(v,h)均可以。关于联合概率分布 P ( v , h ) \mathcal P(v,h) P(v,h)建模更加熟悉。如EM算法等:
log P ( v ) = log ∑ h P ( v , h ) \log \mathcal P(v) = \log \sum_{h} \mathcal P(v,h) logP(v)=logh∑P(v,h)
KL Divergence \text{KL Divergence} KL Divergence观察醒眠算法
这里将 Sleep Phase \text{Sleep Phase} Sleep Phase的生成过程(Generative Connection)看作生成模型的步骤,并使用联合概率分布进行建模:
这里的 θ \theta θ指的就是 Sigmoid \text{Sigmoid} Sigmoid信念网络中表示随机变量结点之间关联关系的模型参数集合 W \mathcal W W.
例如上图中的 W \mathcal W W就表示 { W h 1 ( i ) → v 1 ( i ) ; W h 2 ( i ) → v 1 ( i ) } \left\{\mathcal W_{h_1^{(i)} \to v_1^{(i)}};\mathcal W_{h_2^{(i)} \to v_1^{(i)}}\right\} {Wh1(i)→v1(i);Wh2(i)→v1(i)}
Generative Model : P ( v , h ; θ ) θ ⇒ W \text{Generative Model : } \mathcal P(v,h;\theta) \quad \theta \Rightarrow \mathcal W Generative Model : P(v,h;θ)θ⇒W
同理,将 Weak Phase \text{Weak Phase} Weak Phase的认知过程(Recognization)将其视作模型的形式。通过上面对认知过程的描述,它本质上是对后验概率分布 P ( h ∣ v ) \mathcal P(h \mid v) P(h∣v)的一个近似。这里使用 Q ( h ∣ v ) \mathcal Q(h \mid v) Q(h∣v)进行表示,并对它进行建模:
同上,符号 ϕ \phi ϕ表示模型 Q ( h ∣ v ) \mathcal Q(h \mid v) Q(h∣v)的模型参数,也就是上图中反向关联(红色线)的模型参数集合 R \mathcal R R.
上图中的 R \mathcal R R则表示 { R v 1 ( i ) → h 1 ( i ) ; R v 1 ( i ) → h 2 ( i ) } \left\{\mathcal R_{v_1^{(i)} \to h_1^{(i)}};\mathcal R_{v_1^{(i)} \to h_2^{(i)}}\right\} {Rv1(i)→h1(i);Rv1(i)→h2(i)}
Recognization Model : Q ( h ∣ v ; ϕ ) ϕ ⇒ R \text{Recognization Model : } \mathcal Q(h \mid v;\phi) \quad \phi \Rightarrow \mathcal R Recognization Model : Q(h∣v;ϕ)ϕ⇒R
观察醒眠算法是如何学习模型参数的:
- Weak-Phase : \text{Weak-Phase : } Weak-Phase :
-
Bottom-up : \text{Bottom-up : } Bottom-up : 给定真实样本条件下,从隐变量的后验概率分布中进行采样:
{ h ( 1 ) , ⋯ , h ( N ) } ∼ Q ( h ∣ v ; ϕ ) \{h^{(1)},\cdots, h^{(N)}\} \sim \mathcal Q(h \mid v;\phi) {h(1),⋯,h(N)}∼Q(h∣v;ϕ) -
Learning Generative Connection : \text{Learning Generative Connection : } Learning Generative Connection : 基于 Q ( h ∣ v ; ϕ ) \mathcal Q(h \mid v;\phi) Q(h∣v;ϕ)产生的样本,去近似学习生成过程 的参数信息。那么对应的目标函数可表示为:
就是使用‘蒙特卡洛方法’进行近似。添加一个log \log log,不影响最值取值的变化。这里P ( v , h ( i ) ; θ ) \mathcal P(v,h^{(i)};\theta) P(v,h(i);θ)中的v v v是真实的训练样本。在近似求解模型参数θ \theta θ的过程中,也就是Weak Phase \text{Weak Phase} Weak Phase过程中,关于Q ( h ∣ v ; ϕ ) \mathcal Q(h \mid v;\phi) Q(h∣v;ϕ)是给定的。即求解W \mathcal W W步骤中,R \mathcal R R是给定的。初始状态下自然需要一个随机初始化的R \mathcal R R.
E Q ( h ∣ v ; ϕ ) [ log P ( v , h ; θ ) ] ≈ 1 N ∑ i = 1 N log P ( v , h ( i ) ; θ ) \mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \mathcal P(v,h;\theta)\right] \approx \frac{1}{N} \sum_{i=1}^{N} \log \mathcal P(v,h^{(i)};\theta) EQ(h∣v;ϕ)[logP(v,h;θ)]≈N1i=1∑NlogP(v,h(i);θ)
那么关于模型参数 θ \theta θ的最优解 θ ^ \hat \theta θ^可表示为:
θ ^ = arg max θ E Q ( h ∣ v ; ϕ ) [ log P ( v , h ; θ ) ] \begin{aligned} \hat \theta & = \mathop{\arg\max}\limits_{\theta} \mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \mathcal P(v,h;\theta)\right] \\ \end{aligned} θ^=θargmaxEQ(h∣v;ϕ)[logP(v,h;θ)]
这实际上就是求解 证据下界(Evidence Lower Bound,ELBO) 的最优解:
H [ Q ( h ∣ v ; ϕ ) ] \mathcal H \left[\mathcal Q(h \mid v;\phi)\right] H[Q(h∣v;ϕ)]表示近似后验分布Q ( h ∣ v ; ϕ ) \mathcal Q(h \mid v;\phi) Q(h∣v;ϕ)的熵。
{ log P ( v ) = ELBO + KL [ Q ( h ∣ v ; ϕ ) ∣ ∣ P ( v , h ; θ ) ] ELBO = ∑ h Q ( h ∣ v ; ϕ ) ⋅ log P ( h , v ; θ ) Q ( h ∣ v ; ϕ ) = E Q ( h ∣ v ; ϕ ) [ log P ( h , v ; θ ) Q ( h ∣ v ; ϕ ) ] = E Q ( h ∣ v ; ϕ ) [ log P ( h , v ; θ ) ] + H [ Q ( h ∣ v ; ϕ ) ] \begin{cases} \log \mathcal P(v) = \text{ELBO} + \text{KL} \left[\mathcal Q(h \mid v;\phi)||\mathcal P(v,h;\theta)\right] \\ \begin{aligned}\text{ELBO} & = \sum_{h} \mathcal Q(h \mid v;\phi) \cdot \log \frac{\mathcal P(h,v;\theta)}{\mathcal Q(h \mid v;\phi)}\\ & = \mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \frac{\mathcal P(h,v;\theta)}{\mathcal Q(h \mid v;\phi)}\right] \\ & = \mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \mathcal P(h,v;\theta)\right] + \mathcal H \left[\mathcal Q(h \mid v;\phi)\right] \end{aligned} \end{cases} ⎩ ⎨ ⎧logP(v)=ELBO+KL[Q(h∣v;ϕ)∣∣P(v,h;θ)]ELBO=h∑Q(h∣v;ϕ)⋅logQ(h∣v;ϕ)P(h,v;θ)=EQ(h∣v;ϕ)[logQ(h∣v;ϕ)P(h,v;θ)]=EQ(h∣v;ϕ)[logP(h,v;θ)]+H[Q(h∣v;ϕ)]
由于在Weak Phase \text{Weak Phase} Weak Phase步骤中ϕ \phi ϕ是已知参数,因而可以将H [ Q ( h ∣ v ; ϕ ) ] \mathcal H\left[\mathcal Q(h \mid v;\phi)\right] H[Q(h∣v;ϕ)]看作是一个已知的常量。而求解最值时,常量对最值结果不影响。
θ ^ = arg max θ ELBO = arg max θ { E Q ( h ∣ v ; ϕ ) [ log P ( h , v ; θ ) ] + H [ Q ( h ∣ v ; ϕ ) ] ⏟ = C } = arg max θ { E Q ( h ∣ v ; ϕ ) [ log P ( h , v ; θ ) ] } \begin{aligned} \hat \theta & = \mathop{\arg\max}\limits_{\theta} \text{ELBO} \\ & = \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \mathcal P(h,v;\theta)\right] + \underbrace{\mathcal H \left[\mathcal Q(h \mid v;\phi)\right]}_{=\mathcal C} \right\} \\ & = \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\mathcal Q(h \mid v;\phi)} \left[\log \mathcal P(h,v;\theta)\right] \right\} \end{aligned} θ^=θargmaxELBO=θargmax⎩ ⎨ ⎧EQ(h∣v;ϕ)[logP(h,v;θ)]+=C H[Q(h∣v;ϕ)]⎭ ⎬ ⎫=θargmax{EQ(h∣v;ϕ)[logP(h,v;θ)]}
将最初始的期望求解最值问题转化为 ELBO \text{ELBO} ELBO求解最值问题,其作用是什么?
自然是将 求解 θ \theta θ最优解转化为概率分布 Q ( h ∣ v ; ϕ ) \mathcal Q(h \mid v;\phi) Q(h∣v;ϕ)和分布 P ( h , v ; θ ) \mathcal P(h,v;\theta) P(h,v;θ)之间的相关性比较。 ELBO \text{ELBO} ELBO最大,意味着 KL [ Q ( h ∣ v ; ϕ ) ∣ ∣ P ( h ∣ v ; θ ) ] \text{KL} \left[\mathcal Q(h \mid v;\phi)|| \mathcal P(h \mid v;\theta)\right] KL[Q(h∣v;ϕ)∣∣P(h∣v;θ)]达到最小,此时分布 Q ( h ∣ v ; θ ) \mathcal Q(h \mid v;\theta) Q(h∣v;θ)和分布 P ( h ∣ v ; θ ) \mathcal P(h \mid v;\theta) P(h∣v;θ)是最相似的。
-
- Sleep Phase : \text{Sleep Phase : } Sleep Phase :
- Top-Down \text{Top-Down} Top-Down与 Weak Phase \text{Weak Phase} Weak Phase步骤相对应,上一步骤求解出的 θ ^ \hat \theta θ^结果进行固定,并从 P ( h , v ; θ ^ ) \mathcal P(h,v;\hat {\theta}) P(h,v;θ^)中进行采样:
此时已经不仅仅采样隐变量了,并且还会采样出‘虚拟的观测变量’。
{ h ( 1 ) , v ′ ( 1 ) , ⋯ , h ( N ) , v ′ ( N ) } ∼ P ( v , h ∣ θ ^ ) \{h^{(1)},v^{'(1)},\cdots,h^{(N)},v^{'(N)}\} \sim \mathcal P(v,h \mid \hat \theta) {h(1),v′(1),⋯,h(N),v′(N)}∼P(v,h∣θ^) - 基于 P ( h ( i ) , v ( i ) ; θ ^ ) \mathcal P(h^{(i)},v^{(i)};\hat \theta) P(h(i),v(i);θ^)中采出的样本,去近似学习认知过程的参数信息。具体目标函数可表示为:
对应步骤和Weak Phase \text{Weak Phase} Weak Phase相似,需要注意Q ( h ( i ) ∣ v ′ ( i ) ∣ ; ϕ ) \mathcal Q(h^{(i)} \mid v^{'(i)} \mid ;\phi) Q(h(i)∣v′(i)∣;ϕ)
E P ( h , v ; θ ^ ) [ log Q ( h ∣ v ; ϕ ) ] ≈ 1 N ∑ i = 1 N log Q ( h ( i ) ∣ v ′ ( i ) ; ϕ ) \begin{aligned} \mathbb E_{\mathcal P(h,v; \hat \theta)} \left[\log \mathcal Q(h \mid v;\phi)\right] \approx \frac{1}{N} \sum_{i=1}^N \log \mathcal Q(h^{(i)} \mid v^{'(i)};\phi) \end{aligned} EP(h,v;θ^)[logQ(h∣v;ϕ)]≈N1i=1∑NlogQ(h(i)∣v′(i);ϕ)
对应的最优参数 ϕ ^ \hat \phi ϕ^可表示为:
ϕ ^ = arg max ϕ { E P ( h , v ; θ ^ ) [ log Q ( h ∣ v ; ϕ ) ] } \hat \phi = \mathop{\arg\max}\limits_{\phi} \left\{\mathbb E_{\mathcal P(h,v; \hat \theta)} \left[\log \mathcal Q(h \mid v;\phi)\right]\right\} ϕ^=ϕargmax{EP(h,v;θ^)[logQ(h∣v;ϕ)]}
观察,上述表达式和 ELBO \text{ELBO} ELBO之间是否存在关联关系?对上式进行化简:- 首先将期望展开:
关于这里确实存在一些个人疑问:为什么不去对v v v进行积分。因为在Sleep Phase \text{Sleep Phase} Sleep Phase中,v v v也是从P ( h , v ; θ ^ ) \mathcal P(h,v;\hat \theta) P(h,v;θ^)中生成出来的虚拟样本,不同于Weak Phase \text{Weak Phase} Weak Phase的真实样本,为什么它可以不用积分?
ϕ ^ = arg max ϕ ∑ h P ( h , v ; θ ^ ) log Q ( h ∣ v ; ϕ ) \hat \phi = \mathop{\arg\max}\limits_{\phi} \sum_{h} \mathcal P(h,v;\hat \theta) \log \mathcal Q(h \mid v;\phi) ϕ^=ϕargmaxh∑P(h,v;θ^)logQ(h∣v;ϕ) - 使用条件概率公式对 P ( h , v ; θ ^ ) \mathcal P(h,v;\hat \theta) P(h,v;θ^)展开,并转换成如下形式:
分解出的P ( v ; θ ) \mathcal P(v;\theta) P(v;θ)明显是不含参数ϕ \phi ϕ,并且也不含隐变量h h h,将其从积分号中提出来,并视作常数,忽略掉。
ϕ ^ = arg max ϕ ∑ h P ( v ; θ ) ⋅ P ( h ∣ v ; θ ) log Q ( h ∣ v ; ϕ ) = arg max ϕ [ P ( v ; θ ) ⋅ ∑ h P ( h ∣ v ; θ ) log Q ( h ∣ v ; ϕ ) ] = arg max ϕ [ ∑ h P ( h ∣ v ; θ ) log Q ( h ∣ v ; ϕ ) ] \begin{aligned} \hat \phi & = \mathop{\arg\max}\limits_{\phi} \sum_{h} \mathcal P(v;\theta) \cdot \mathcal P(h \mid v;\theta) \log \mathcal Q(h \mid v;\phi)\\ & = \mathop{\arg\max}\limits_{\phi} \left[\mathcal P(v;\theta) \cdot \sum_{h} \mathcal P(h \mid v;\theta) \log \mathcal Q(h \mid v;\phi)\right] \\ & = \mathop{\arg\max}\limits_{\phi} \left[\sum_{h} \mathcal P(h \mid v;\theta) \log \mathcal Q(h \mid v;\phi)\right] \end{aligned} ϕ^=ϕargmaxh∑P(v;θ)⋅P(h∣v;θ)logQ(h∣v;ϕ)=ϕargmax[P(v;θ)⋅h∑P(h∣v;θ)logQ(h∣v;ϕ)]=ϕargmax[h∑P(h∣v;θ)logQ(h∣v;ϕ)] - 在步骤2的基础上,加入一个辅助项 [ − ∑ h P ( h ∣ v ; θ ) log P ( h ∣ v ; θ ) ] \left[-\sum_h \mathcal P(h \mid v;\theta) \log \mathcal P(h \mid v;\theta)\right] [−∑hP(h∣v;θ)logP(h∣v;θ)]:
因为该项中根本不包含任何关于参数ϕ \phi ϕ的信息,可以将其视作常数,不影响ϕ \phi ϕ的取值。
这里将符号和argmax \text{argmax} argmax合并了~
ϕ ^ = arg max ϕ [ ∑ h P ( h ∣ v ; θ ) log Q ( h ∣ v ; ϕ ) − ∑ h P ( h ∣ v ; θ ) log P ( h ∣ v ; θ ) ] = arg max ϕ [ ∑ h P ( h ∣ v ; θ ) log Q ( h ∣ v ; ϕ ) P ( h ∣ v ; θ ) ] = arg min ϕ KL [ P ( h ∣ v ; θ ) ∣ ∣ Q ( h ∣ v ; ϕ ) ] \begin{aligned} \hat \phi & = \mathop{\arg\max}\limits_{\phi} \left[\sum_{h} \mathcal P(h \mid v;\theta) \log \mathcal Q(h \mid v;\phi) - \sum_h \mathcal P(h \mid v;\theta) \log \mathcal P(h \mid v;\theta)\right] \\ & = \mathop{\arg\max}\limits_{\phi} \left[\sum_h \mathcal P(h \mid v;\theta) \log \frac{\mathcal Q(h \mid v;\phi)}{\mathcal P(h \mid v;\theta)}\right] \\ & = \mathop{\arg\min}\limits_{\phi} \text{KL} \left[\mathcal P(h \mid v;\theta) || \mathcal Q(h \mid v;\phi)\right] \end{aligned} ϕ^=ϕargmax[h∑P(h∣v;θ)logQ(h∣v;ϕ)−h∑P(h∣v;θ)logP(h∣v;θ)]=ϕargmax[h∑P(h∣v;θ)logP(h∣v;θ)Q(h∣v;ϕ)]=ϕargminKL[P(h∣v;θ)∣∣Q(h∣v;ϕ)]
- 首先将期望展开:
- Top-Down \text{Top-Down} Top-Down与 Weak Phase \text{Weak Phase} Weak Phase步骤相对应,上一步骤求解出的 θ ^ \hat \theta θ^结果进行固定,并从 P ( h , v ; θ ^ ) \mathcal P(h,v;\hat {\theta}) P(h,v;θ^)中进行采样:
比对一下 Weak Phase \text{Weak Phase} Weak Phase和 Sleep Phase \text{Sleep Phase} Sleep Phase之间关于模型参数的描述:
{ θ ^ = arg min θ KL [ Q ( h ∣ v ; ϕ ) ∣ ∣ P ( h ∣ v ; θ ) ] ϕ ^ = arg min ϕ KL [ P ( h ∣ v ; θ ) ∣ ∣ Q ( h ∣ v ; ϕ ) ] \begin{cases} \hat \theta = \mathop{\arg\min}\limits_{\theta} \text{KL} \left[\mathcal Q(h \mid v;\phi)|| \mathcal P(h\mid v;\theta)\right] \\ \hat \phi = \mathop{\arg\min}\limits_{\phi} \text{KL} \left[\mathcal P(h \mid v;\theta) || \mathcal Q(h \mid v;\phi)\right] \end{cases} ⎩ ⎨ ⎧θ^=θargminKL[Q(h∣v;ϕ)∣∣P(h∣v;θ)]ϕ^=ϕargminKL[P(h∣v;θ)∣∣Q(h∣v;ϕ)]
很明显,这两个步骤对于模型参数的优化分别基于不同的 KL Divergence \text{KL Divergence} KL Divergence。也就是说,这两个参数的更新并没有共用同一个目标函数。
注意 KL Divergence \text{KL Divergence} KL Divergence中分布顺序与结果之间存在差异。没有什么交换律~
这也是该算法被称为启发式算法的原因,无法确定参数 ϕ , θ \phi,\theta ϕ,θ是否能够收敛成稳定形式。因而这种方式只能适用于某些模型。
如果将醒眠算法与广义 EM \text{EM} EM算法的迭代思路进行对比的话,发现EM算法无论是E步还是M步,它们均有相同的目标函数——使 ELBO \text{ELBO} ELBO达到最大。
但醒眠算法不同。求解 θ ^ \hat \theta θ^中的 v v v是真实样本;而 ϕ ^ \hat \phi ϕ^中的 v v v是模型生成的虚拟样本,实际上在 Sleep Phase \text{Sleep Phase} Sleep Phase步骤中,参数更新已经在发生偏移了。
关于 Sleep Phase \text{Sleep Phase} Sleep Phase的另一层含义是,不同于 Weak Phase \text{Weak Phase} Weak Phase以真实样本作为条件, Sleep Phase \text{Sleep Phase} Sleep Phase最初始状态是以入度为零的隐变量结点作为条件。而隐变量就是认人为假定模型中的变量信息。因而都是虚拟样本。
在花书P371页下方也称其为‘幻想粒子’(Fantasy Particle)。在配分函数——随机最大似然中也提到过这个词。
至此,关于 Sigmoid \text{Sigmoid} Sigmoid信念网络部分介绍到此结束。下一节将介绍深度玻尔兹曼机(Deep Boltzmann Machine,DBM)。
相关参考:
(系列二十六)Sigmoid Belief Network5-醒眠算法-KL Divergence
(系列二十六)Sigmoid Belief Network5-醒眠算法-KL Divergence续