提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、neo4j是什么?
- 二、安装步骤
- 1.启动
- 2.使用
- 2.简单命令
- 二、使用springboot集成neo4j
- 1.引入依赖
- 2.功能实现
- 3.查询关系节点
- 4. 查询指定评委和指定选手中,存在指定关系,并返回关系集合
前言
使用neo4j来完成人员关系
公司项目有一个功能需要将各个人员关系列出,在参加评选的时候,进行展示和筛选
一、neo4j是什么?
neo4j是高性能的NOSQL图形数据库,在neo4j中,社区版本只能使用一个database。在neo4j中不存在表的概念,我们只需要注意两个东西,一个是节点,一个是关系。不同节点和相同节点都可以产生关系。
二、安装步骤
https://neo4j.com/download-center/
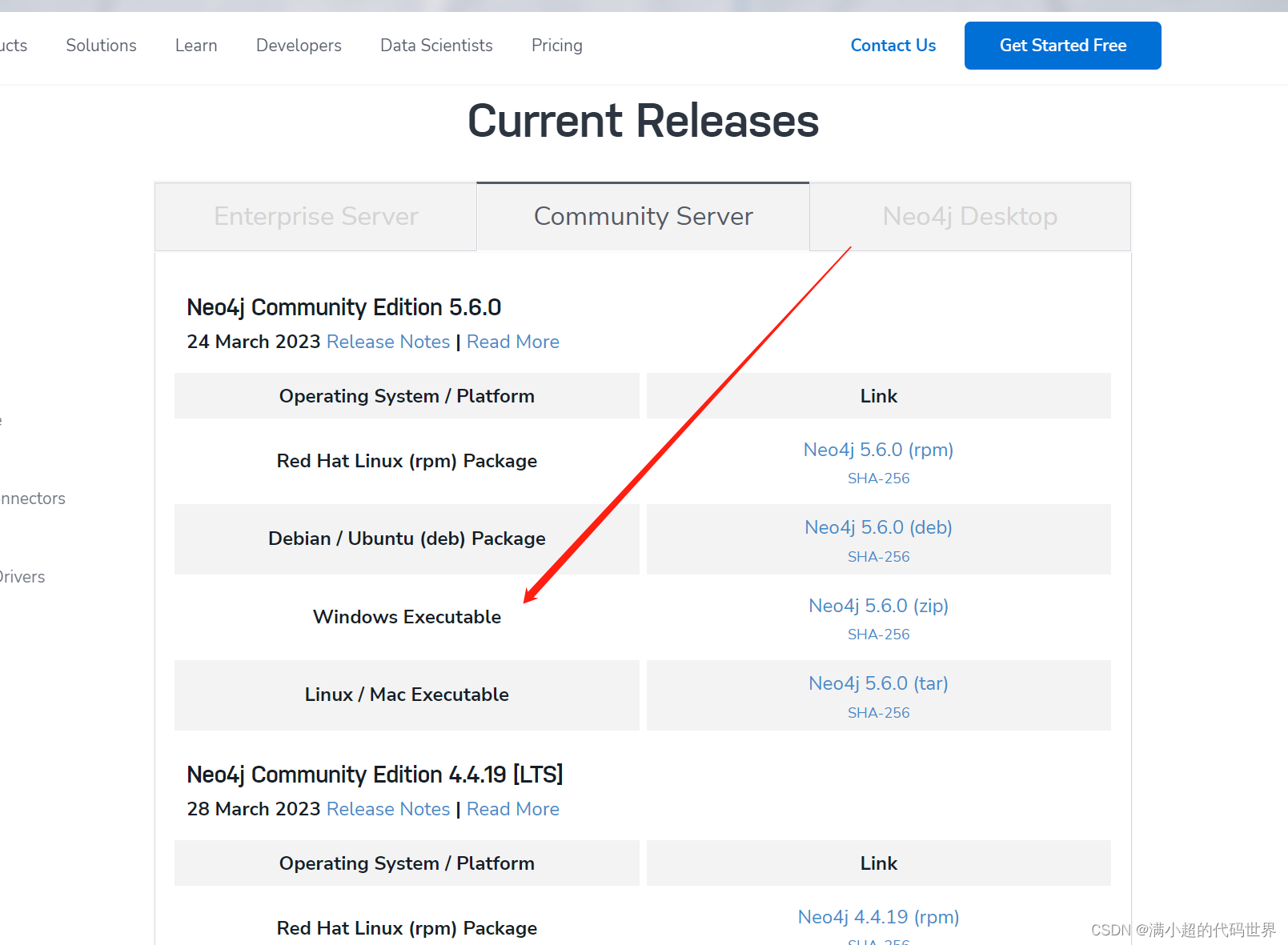
我下载的是3.5.28,超过4.x,jdk版本需要11
1.启动
在bin目录下使用cmd命令 在命令框中执行 neo4j.bat console启动数据库
2.使用
1.登录管理页面 http://localhost:7474
2.第一次登录账号密码都是neo4j
2.简单命令
1.创建节点 create (:node1{nodeId:1,name:'王大'})
2.修改节点 merge (a:node1{nodeId:1}) set a.name='王小二' return a //如果节点不存在就创建
3.删除节点 match (a:node1{nodeId:1}) delete a
4.查询节点 match (a:node1{nodeId:1}) return a
5.创建关系 create (a:node1{nodeId:1})-[:relationShip{shipId:1,shipName:'好友'}]->(b:node1{nodeId:2})
6.查询关系 match (a:node1)-[r:relationShip]->(b:node1) return a.name,r.shipName,b.name
7.在查询关系时可以在a和关系以及b中设置查询条件,或者在b后跟where条件来筛选二、使用springboot集成neo4j
1.引入依赖
本项目是springboot框架进行开发的,所以在项目中添加pom依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-neo4j</artifactId></dependency>
2.功能实现
这个功能是对人员进行关系筛选,人员身份是两类,一种是评委,一种是选手,所以,我们使用PersonNode对象,并且使用type来区分
可以使用neo4j框架自带的注解进行标注,NodeEntity是存在neo4j数据库种node的节点名称,Property是存放在数据库的名称,Relationship是节点关系的属性,包括节点类型和指向。指向默认是向外,也可以向内和双向。personRelationship是另一个关系类的名称
@Data
@NodeEntity(label = "PersonNode")
public class PersonNode {@Id@GeneratedValueprivate Long id;@Property(name = "type")private Integer type; @Property(name = "personId")private String personId;@Property(name = "name")private String name;@Property(name = "idCard")private String idCard;@Relationship(type = "personRelationship",direction = Relationship.OUTGOING) //这是关系private List<PersonRelationship> relationship;}
@Data
@RelationshipEntity(type = "personRelationship")
public class PersonRelationship {@Id@GeneratedValueprivate Long id;@StartNodeprivate PersonNode startNode;@EndNodeprivate PersonNode endNode;/**@Property 注解用于定义单个属性,通常用于标注在实体类的字段上,指定该字段映射到节点或关系的一个属性@Properties 注解用于定义多个属性,通常用于标注在实体类的方法上,指定该方法返回一个 Map<String, Object>使用@Property注解时,如果属性名与注解的值相同,则可以省略注解的值*/@Propertyprivate String relationName; //关系类型private String typeName; //分类名称private String level; //等级}
3.查询关系节点
1.创建一个PersonNodeRepository继承Neo4jRepository
2.在PersonNodeRepository可以使用注解@query来写cql语句
3.比如创建人员信息:我使用MERGE来实现,存在就更新
MERGE (n:PersonNode{personId: $personNode.personId}) SET n.name= $personNode.name,n.idCard=$personNode.idCard,n.type=$personNode.type return n
PersonNode saveOrUpdate(@Param("personNode")PersonNode personNode);
4.创建关系:先根据条件进行查询,在使用merge创建关系
@Query("Match (s:PersonNode{personId: $relationExcel.startPersonId}),(e:PersonNode{personId:$relationExcel.endPersonId})" +"MERGE (s)-[:personRelationship {relationName:${relationExcel.relationName},typeName:${relationExcel.typeName},relationId:${relationExcel.relationId}]->(e) ")void createPersonRelation(PersonRelationExcel relationExcel);
5.在neo4j种,查询后的数据是一个特殊的格式类型。所以往往需要对这个格式进行处理,我们可以使用apoc插件来使返回的结果呈现多层关系一样 的树状结构,在这个查询条件中,使用p来接收查询的结果,with将单个元素组组成列表,最后使用apoc生成树状数据。personRelationship中带有*表示查询所有层级的数据。如果不带 * ,那么只会返回两层数据
MATCH p=(n:PersonNode)-[:personRelationship*]->(m:PersonNode)
with collect(p) as ps call apoc.convert.toTree(ps) yield value return value
4. 查询指定评委和指定选手中,存在指定关系,并返回关系集合
为什么要这样,因为前端的框架需要所有的节点list和所有的关系list
1.首先返回node节点,根据relationName,relationIdList,expertIdList,auditPersonIdList来筛选,ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ,r是一个列表,需要遍历r来判断是否存在。使用关系后,使用WITH和relationships ,relationship将获取到p中所有 的关系,并且形成集合。UNWIND 将集合展开。可能有人问,集合展开和集合有什么关系:
有的集合长这样['a','b','c','d','e'] ,有的集合长这样:[['a','b','c'],['d','e']]
对于with形成的集合就长[['a','b','c'],['d','e']] , UNWIND 展开的集合长:['a','b','c','d','e']
最后我们得到了rs这样的集合,rs存在startNode和endNode的id,我们可以通过这两个属性来查询节点
我们使用collect来生成集合,并且使用distinct去重来获取到startNode的节点和endNode的节点
最后我们将这两个集合展开成一个集合返回
@Query("MATCH p=(n:PersonNode)-[r:personRelationship*]->(m:PersonNode) " +"WHERE 1=1 " +"AND CASE WHEN size($dto.relationName) <> 0 THEN ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ELSE true END " +"AND CASE WHEN size($dto.relationIdList) <> 0 THEN ALL(rel IN r WHERE rel.relationId IN $dto.relationIdList ) ELSE true END " +"AND CASE WHEN size($dto.expertIdList) <> 0 THEN n.personId IN $dto.expertIdList ELSE true END " +"AND CASE WHEN size($dto.auditPersonIdList) <> 0 THEN m.personId IN $dto.auditPersonIdList ELSE true END " +"AND CASE WHEN $dto.other ='Y' THEN length(p) > 1 ELSE true END " +"WITH n, m, relationships(p) AS rels " +"UNWIND rels AS rs " +"match (a:PersonNode{personId:startNode(rs).personId}),(b:PersonNode{personId:endNode(rs).personId}) "+"WITH collect(distinct {personId:a.personId,type:a.type,name:a.name}) + collect(distinct {personId:b.personId,type:b.type,name:b.name}) as nodes1 "+"UNWIND nodes1 as nodes " +"RETURN DISTINCT nodes")List getNode(@Param("dto") RelationConditionDto dto);2.获取关系的集合
和获取对象一样,注意,我们将r展开,还需要去重。match的结果关系可能有很多重复项
@Query("MATCH p=(n:PersonNode)-[r:personRelationship*]->(m:PersonNode) " +"WHERE 1=1 " +"AND CASE WHEN size($dto.relationName) <> 0 THEN ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ELSE true END " +"AND CASE WHEN size($dto.relationIdList) <> 0 THEN ALL(rel IN r WHERE rel.relationId IN $dto.relationIdList ) ELSE true END " +"AND CASE WHEN size($dto.expertIdList) <> 0 THEN n.personId IN $dto.expertIdList ELSE true END " +"AND CASE WHEN SIZE($dto.auditPersonIdList) <> 0 THEN m.personId IN $dto.auditPersonIdList ELSE true END " +"AND CASE WHEN $dto.other ='Y' THEN length(p) > 1 ELSE true END " +"UNWIND r AS rels " +"with distinct(rels) as rs "+"match (a:PersonNode{personId:startNode(rs).personId}),(b:PersonNode{personId:endNode(rs).personId}) "+"return a.personId as startId,a.name as startName,b.personId as endId,b.name as endName,rs.typeName as typeName,rs.relationName as relationName,rs.relationId as relationId")List<Map> getRelationList(@Param("dto") RelationConditionDto dto);