StarRocks的改表语句
文章目录
- StarRocks的改表语句
- 1 数据类型
- 2 修改表结构
- 3 示例
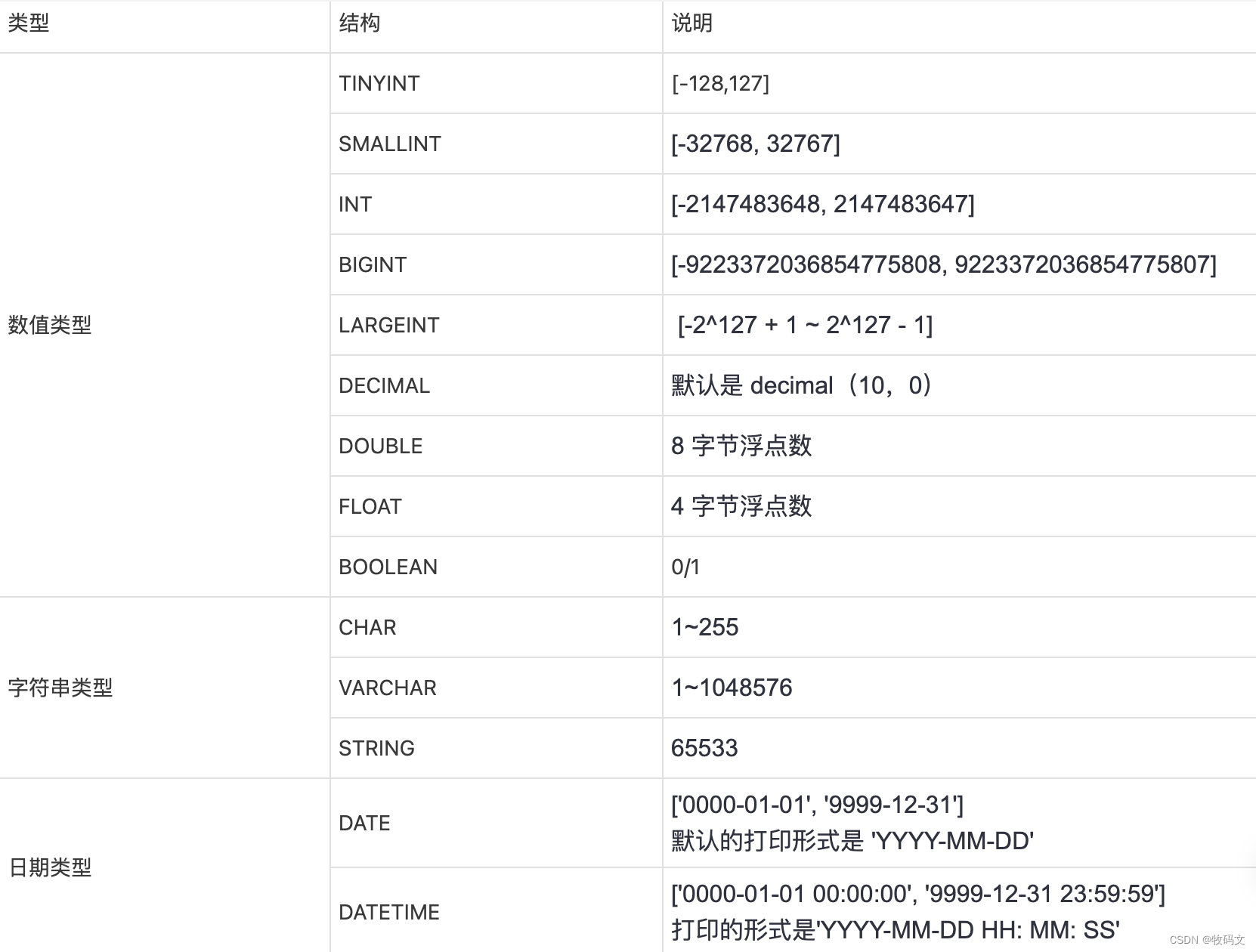
1 数据类型


2 修改表结构
StarRocks 支持多种 DDL 操作。
可以通过 ALTER TABLE 命令可以修改表的 Schema,包括增加列,删除列,修改列类型(暂不支持修改列名称),改变列顺序。
1 增加列
例如,在以上创建的表中,在 ispass 列后新增一列 uv,类型为 BIGINT,默认值为 0。
ALTER TABLE detailDemo ADD COLUMN uv BIGINT DEFAULT '0' after ispass;
2 删除列
删除以上步骤新增的列。注意如果您通过上述步骤添加了 uv,请务必删除此列以保证后续 Quick Start 内容可以执行。
ALTER TABLE detailDemo DROP COLUMN uv;
3 查看修改表结构作业状态
修改表结构为异步操作。提交成功后,您可以通过以下命令查看作业状态。
SHOW ALTER TABLE COLUMN\G;
当作业状态为 FINISHED,则表示作业完成,新的表结构修改已生效。
修改 Schema 完成之后,您可以通过以下命令查看最新的表结构。
DESC table_name;
3 示例
1 table
修改表的默认副本数量,新建分区副本数量默认使用此值。
ALTER TABLE example_db.my_table
SET ("default.replication_num" = "2");
修改单分区表的实际副本数量(只限单分区表)。
ALTER TABLE example_db.my_table
SET ("replication_num" = "3");
修改数据在多副本间的写入和同步方式。
ALTER TABLE example_db.my_table
SET ("replicated_storage" = "false");
以上示例表示将多副本的写入和同步方式设置为 leaderless replication,即数据同时写入到多个副本,不区分主从副本。
2 partition
增加分区,现有分区 [MIN, 2013-01-01),增加分区 [2013-01-01, 2014-01-01),使用默认分桶方式。
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2014-01-01");
增加分区,使用新的分桶数。
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
DISTRIBUTED BY HASH(k1) BUCKETS 20;
增加分区,使用新的副本数。
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
("replication_num"="1");
修改分区副本数。
ALTER TABLE example_db.my_table
MODIFY PARTITION p1 SET("replication_num"="1");
批量修改指定分区。
ALTER TABLE example_db.my_table
MODIFY PARTITION (p1, p2, p4) SET("in_memory"="true");
批量修改所有分区。
ALTER TABLE example_db.my_table
MODIFY PARTITION (*) SET("storage_medium"="HDD");
删除分区。
ALTER TABLE example_db.my_table
DROP PARTITION p1;
增加一个指定上下界的分区。
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES [("2014-01-01"), ("2014-02-01"));
3 rollup
创建 index: example_rollup_index,基于 base index(k1, k2, k3, v1, v2)。列式存储。
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index(k1, k3, v1, v2)
PROPERTIES("storage_type"="column");
创建 index: example_rollup_index2,基于 example_rollup_index(k1, k3, v1, v2)。
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index2 (k1, v1)
FROM example_rollup_index;
创建 index: example_rollup_index3,基于 base index (k1, k2, k3, v1), 自定义 rollup 超时时间一小时。
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index(k1, k3, v1)
PROPERTIES("storage_type"="column", "timeout" = "3600");
删除 index: example_rollup_index2。
ALTER TABLE example_db.my_table
DROP ROLLUP example_rollup_index2;
4 Schema Change
向 example_rollup_index 的 col1 后添加一个 key 列 new_col(非聚合模型)。
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT KEY DEFAULT "0" AFTER col1
TO example_rollup_index;
向 example_rollup_index 的 col1 后添加一个 value 列 new_col(非聚合模型)。
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;
向 example_rollup_index 的 col1 后添加一个 key 列 new_col(聚合模型)。
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;
向 example_rollup_index 的 col1 后添加一个 value 列 new_col SUM 聚合类型(聚合模型)。
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT SUM DEFAULT "0" AFTER col1
TO example_rollup_index;
向 example_rollup_index 添加多列(聚合模型)。
ALTER TABLE example_db.my_table
ADD COLUMN (col1 INT DEFAULT "1", col2 FLOAT SUM DEFAULT "2.3")
TO example_rollup_index;
从 example_rollup_index 删除一列。
ALTER TABLE example_db.my_table
DROP COLUMN col2
FROM example_rollup_index;
修改 base index 的 col1 列的类型为 BIGINT,并移动到 col2 列后面。
ALTER TABLE example_db.my_table
MODIFY COLUMN col1 BIGINT DEFAULT "1" AFTER col2;
修改 base index 的 val1 列最大长度。原 val1 为 (val1 VARCHAR(32) REPLACE DEFAULT “abc”)。
ALTER TABLE example_db.my_table
MODIFY COLUMN val1 VARCHAR(64) REPLACE DEFAULT "abc";
重新排序 example_rollup_index 中的列(设原列顺序为:k1, k2, k3, v1, v2)。
ALTER TABLE example_db.my_table
ORDER BY (k3,k1,k2,v2,v1)
FROM example_rollup_index;
同时执行两种操作。
ALTER TABLE example_db.my_table
ADD COLUMN v2 INT MAX DEFAULT "0" AFTER k2 TO example_rollup_index,
ORDER BY (k3,k1,k2,v2,v1) FROM example_rollup_index;
修改表的 bloom filter 列。
ALTER TABLE example_db.my_table
SET ("bloom_filter_columns"="k1,k2,k3");
也可以合并到上面的 schema change 操作中(注意多子句的语法有少许区别)
ALTER TABLE example_db.my_table
DROP COLUMN col2
PROPERTIES ("bloom_filter_columns"="k1,k2,k3");
修改表的 Colocate 属性。
ALTER TABLE example_db.my_table
SET ("colocate_with" = "t1");
将表的分桶方式由 Random Distribution 改为 Hash Distribution。
ALTER TABLE example_db.my_table
SET ("distribution_type" = "hash");
修改表的动态分区属性(支持未添加动态分区属性的表添加动态分区属性)。
ALTER TABLE example_db.my_table
SET ("dynamic_partition.enable" = "false");
如果需要在未添加动态分区属性的表中添加动态分区属性,则需要指定所有的动态分区属性。
ALTER TABLE example_db.my_table
SET ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "32");
修改表的 in_memory 属性。
ALTER TABLE example_db.my_table
SET ("in_memory" = "true");
5 rename
将名为 table1 的表修改为 table2。
ALTER TABLE table1 RENAME table2;
将表 example_table 中名为 rollup1 的 rollup index 修改为 rollup2。
ALTER TABLE example_table RENAME ROLLUP rollup1 rollup2;
将表 example_table 中名为 p1 的 partition 修改为 p2。
ALTER TABLE example_table RENAME PARTITION p1 p2;
6 index
在 table1 上为 siteid 创建 bitmap 索引。
ALTER TABLE table1
ADD INDEX index_name (siteid) [USING BITMAP] COMMENT 'balabala';
删除 table1 上的 siteid 列的 bitmap 索引。
7 swap
将 table1 与 table2 原子替换。
ALTER TABLE table1 SWAP WITH table2;
改key语句
修改指定 index 的列类型以及列位置 (MODIFY COLUMN)
语法:
ALTER TABLE [database.]table
MODIFY COLUMN column_name column_type [KEY | agg_type] [NULL | NOT NULL] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]