目录
1.namedtuple(‘name’, [list])
2.Counter()
3.deque()
4.OrderedDict()
前言:
python中内置容器包括list、dict、set、tuple,而python中的collections模块则另引入了五种数据结构,更好地满足编码需求。
collections 是python内部的集合模块,内置以下几种数据类型:
1.namedtuple(‘name’, [list])
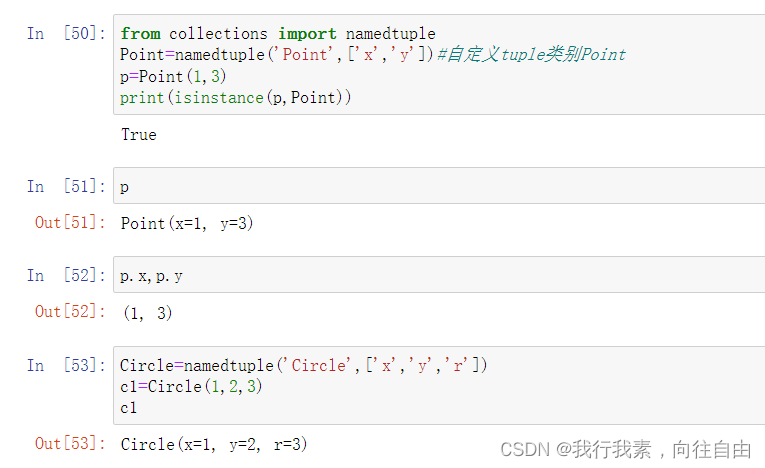
tuple是不可变的元组,如定义坐标点(1,2)、(3,4),但很难直接从代码看出这是表示坐标的,为了增加代码的可读性,我们可以用 ** namedtuple() ** 创建自定义的tuple对象,这个对象是tuple 的子类。
如用(x,y)表示一个点:
from collections import namedtuple #从collections导入数据类型
Point = namedtuple('Point',['x','y'])#自定义tuple类型Point
p = Point(1,3)
print(isinstance(p,Point))#p是Point类型的实例
print(p)#Point(x=1, y=3)
print (p.x)#1
print (p.y)#3
#也可以定义其他类型
Circle = namedtuple('Circle',['x','y','r']) #自定义tuple类型Circle
这样的一个tuple对象有了可被引用的名称 Point,并且可以通过引用对象属性来访问元组元素 。
2.Counter()
Counter是一个计数器,用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。
#统计字符串中各个字符出现的个数
from collections import Counter
#从可iterable数据类型(list,tuple,dict)创建Counter类型实例#从字符串创建
s = ' programming '
c = Counter(s);
print(c)#Counter({' ': 2, 'r': 2, 'g': 2, 'm': 2, 'p': 1, 'o': 1, 'a': 1, 'i': 1, 'n': 1})
#默认按键值对从大到小输出
#从字典类型创建
cdict = Counter({'a':4,'b':5})
print (cdict)#output:Counter({'b': 5, 'a': 4})#从键值对创建,a b指的是键值,不能加引号
ckeys = Counter(a=5,b=6)
print(ckeys)#output:Counter({'b': 6, 'a': 5})
print(type(c))#<class 'collections.Counter'>#返回计数器TopN部分
print(c.most_common())#[(' ', 2), ('r', 2), ('g', 2), ('m', 2), ('p', 1), ('o', 1), ('a', 1), ('i', 1), ('n', 1)]
print(c.most_common(5))#返回出现频率最高的五个元素[(' ', 2), ('r', 2), ('g', 2), ('m', 2), ('p', 1)]
#注意到c.most_common()返回类型为list
print(type(c.most_common()))#<class 'list'>
#那么就可以取出现次数最少的几个元素
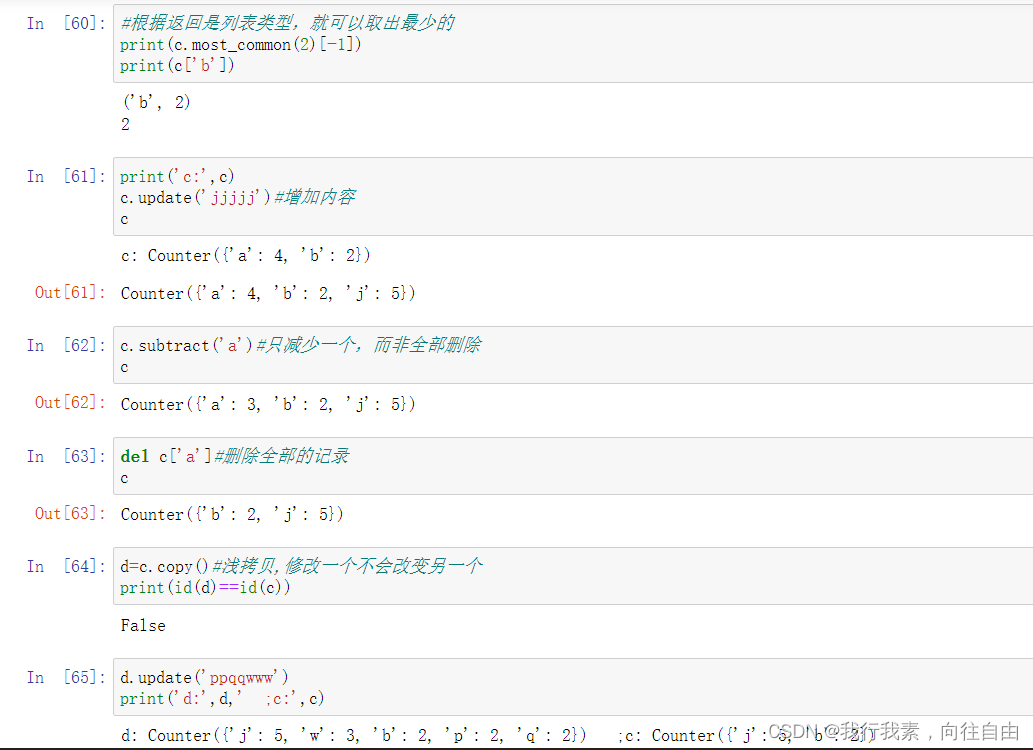
print(c.most_common()[:-4:-1])#出现次数最少的3个元素[('n', 1), ('i', 1), ('a', 1)]
print(c['m'])#2返回元素出现次数#计数器内容增加 update
c.update('mmm')#参数为字符串类型
print(c['m'])#5
print(c['a'])#1
c2=Counter('aaa')
c.update(c2)#参数为Counter类型
print(c['m'])#5
print(c['a'])#4,增加了了三个'a'
print('=======')#计数器内容减少 subtract
print(c['b'])#访问的键不存在时,输出0,而不会报错.output:0
c.subtract('aab')
print(c['a'])#,减少了两个'a' output:2
print(c['b'])#output:-1#del 删除键值
print(c)#output:Counter({'m': 5, ' ': 2, 'r': 2, 'g': 2, 'a': 2, 'p': 1, 'o': 1, 'i': 1, 'n': 1, 'b': -1})
del c['a']
print(c)#output:Counter({'m': 5, ' ': 2, 'r': 2, 'g': 2, 'p': 1, 'o': 1, 'i': 1, 'n': 1, 'b': -1}) 没有'a'
print(c['a'])#0#element() 返回迭代器
print(list(c.elements()))#[' ', ' ', 'p', 'r', 'r', 'o', 'g', 'g', 'm', 'm', 'm', 'm', 'm', 'i', 'n'],排列无序,不包括个数小于1的键值#c中的键值转换为list、set、dict类型
print(list(c))#[' ', 'p', 'r', 'o', 'g', 'm', 'i', 'n', 'b']
print(set(c))#{'g', 'b', 'o', 'r', ' ', 'm', 'p', 'i', 'n'}
print(dict(c))#{' ': 2, 'p': 1, 'r': 2, 'o': 1, 'g': 2, 'm': 5, 'i': 1, 'n': 1, 'b': -1}#浅拷贝
d = c.copy()
print(c==d)#True#加减算术操作,没有乘除
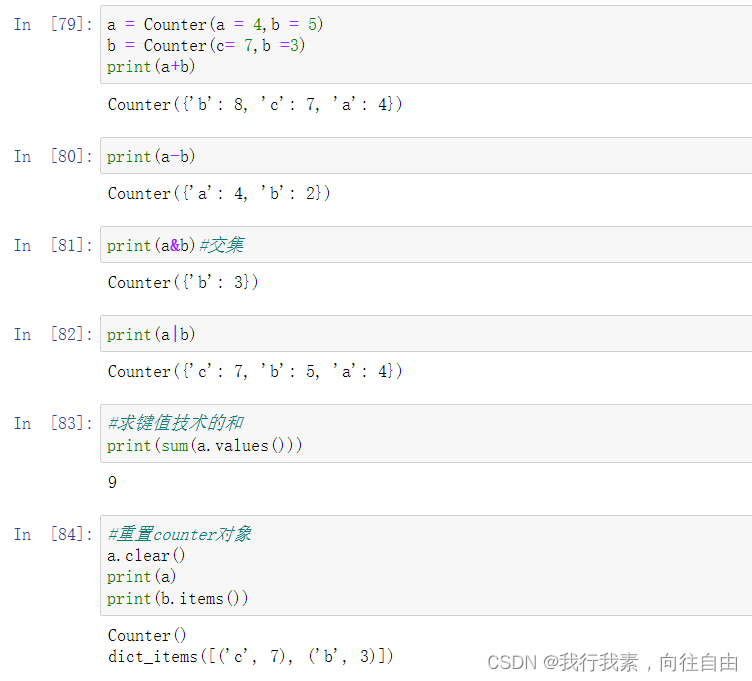
a = Counter(a = 4,b = 5)
b = Counter(c= 7,b =3)
print(a+b)#Counter({'b': 8, 'c': 7, 'a': 4})
print(a-b)#Counter({'a': 4, 'b': 2})subtract 只保留正数计数的元素print(a&b)#Counter({'b': 3}) 输出元素交集 min(a,b)
print(a|b)#Counter({'c': 7, 'b': 5, 'a': 4}) 输出元素并集 max(a,b)#求键值技术的和
print(sum(a.values()))#9#重置counter对象
a.clear()
print(a)#Counter(),没有删除
print(b.items())#dict_items([('c', 7), ('b', 3)])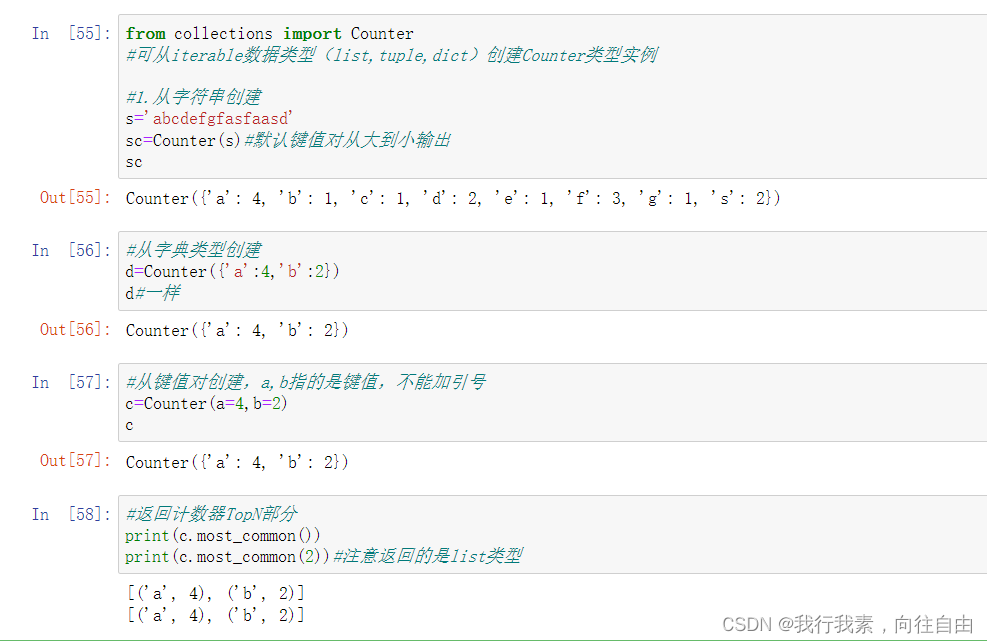

深浅拷贝:

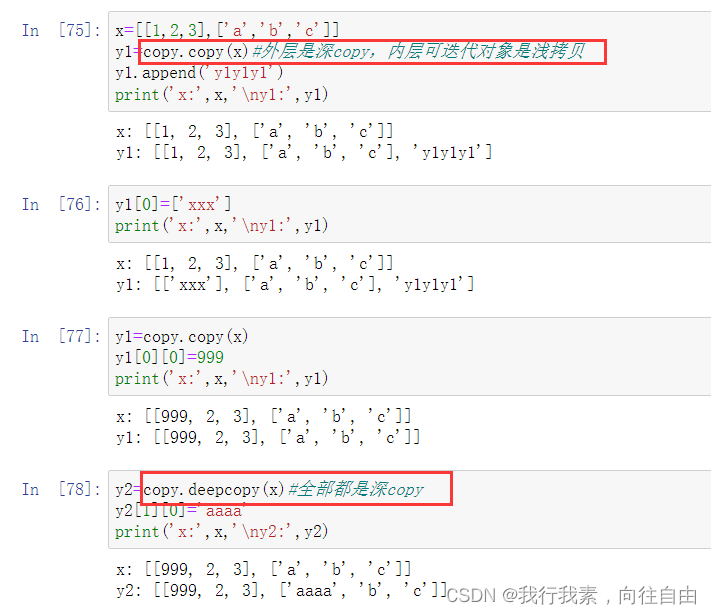
3.deque()
在python 中list查找时间复杂度为O(1),但是插入和删除元素时间复杂度为O(n),即耗时会随着数据规模线性增长。
deque增删元素的时间复杂度为O(1)
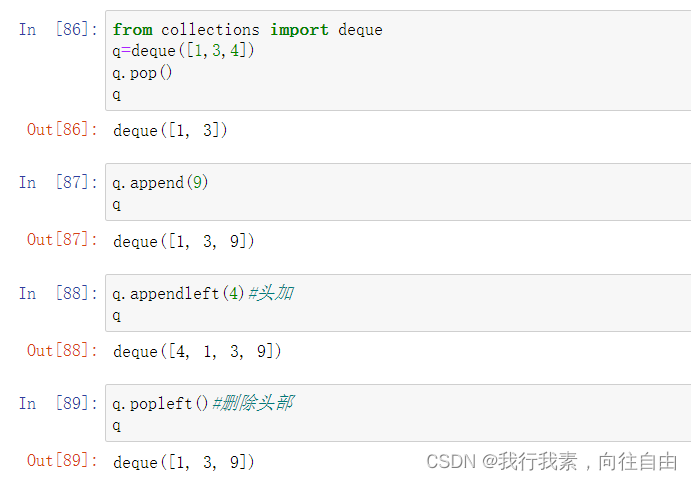
from collections import deque
q = deque([1,3,4])
q.pop()
print(q)#deque([1, 3])
q.append(9)
print(q)#deque([1, 3, 9])
q.appendleft(4)#从头部添加元素
print(q)#deque([4, 1, 3, 9])
q.popleft()#删除头部元素
print(q)#deque([1, 3, 9])
4.OrderedDict()
有序字典,认为字典是有序的,按照创建orderdict实例输入的键值对顺序排列,而不是按照key值本身的顺序。
# 普通Dict类型认为字典是无序的,OrderedDict认为字典是有序的,因此对于键值对排列不同的两个字典,OrderDict会认为是不同的
from collections import OrderedDict
print ('Regular dictionary:')
d2={}
d2['a']='A'
d2['b']='B'
d2['c']='C'd3={}
d3['c']='C'
d3['a']='A'
d3['b']='B'print (d2 == d3)#Trueprint ('\nOrderedDict:')
d4=OrderedDict()
d4['a']='A'
d4['b']='B'
d4['c']='C'd5=OrderedDict()
d5['c']='C'
d5['a']='A'
d5['b']='B'print (d4==d5)#Falseprint ("Regular dictionary")
d={}
d['b']='B'
d['c']='C'
d['a']='A'
for k,v in d.items():print (k,v)#python3中字典dict正常按序输出,从当前情况看,和orderdict没有区别print ("\nOrder dictionary")
d1 = OrderedDict()d1['b'] = 'B'
d1['c'] = 'C'
d1['a'] = 'A'
d1['1'] = '1'
d1['2'] = '2'
for k,v in d1.items():print (k,v)
#b B
# c C
# a A
# 1 1
# 2 2