目录
- Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
- 摘要
- 本文方法
- Pixel-to-Prototype Contrast
- Prototype Estimation
- Cross-view Contrast
- Intra-view Contrast
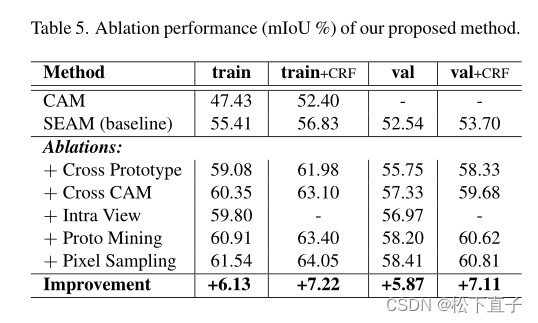
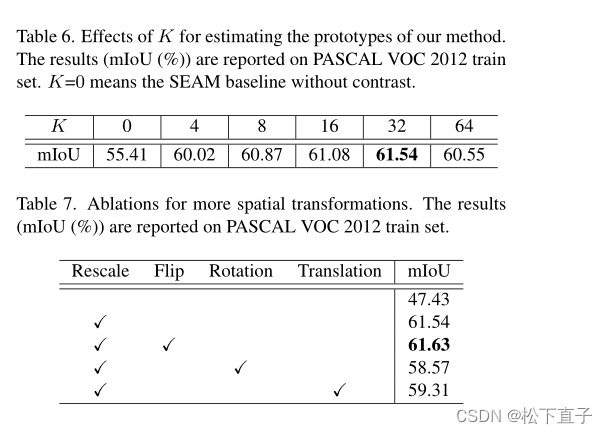
- 消融实验
Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
摘要
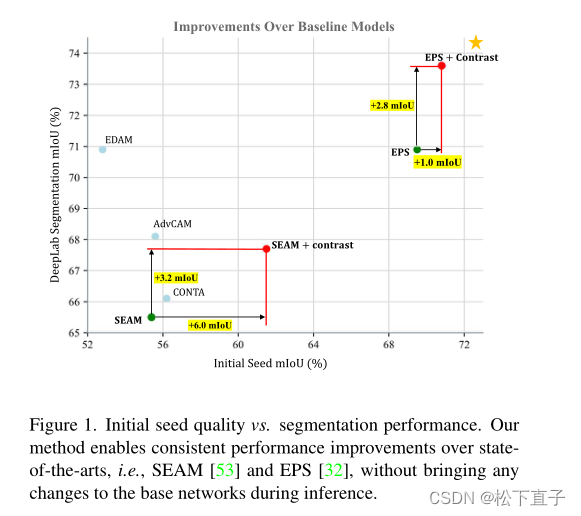
- 提出了弱监督Pixel-to-Prototype Contrast,可以提供像素级的监督信号来缩小差距
- 在不同视图和图像的单个视图中执行,旨在施加跨视图特征语义一致性正则化,并促进特征空间的内(间)类紧凑性(离散性)
- 本文方法可以无缝地整合到现有的WSSS模型中,而无需对基础网络进行任何更改,也不会产生任何额外的推断负担
本文方法
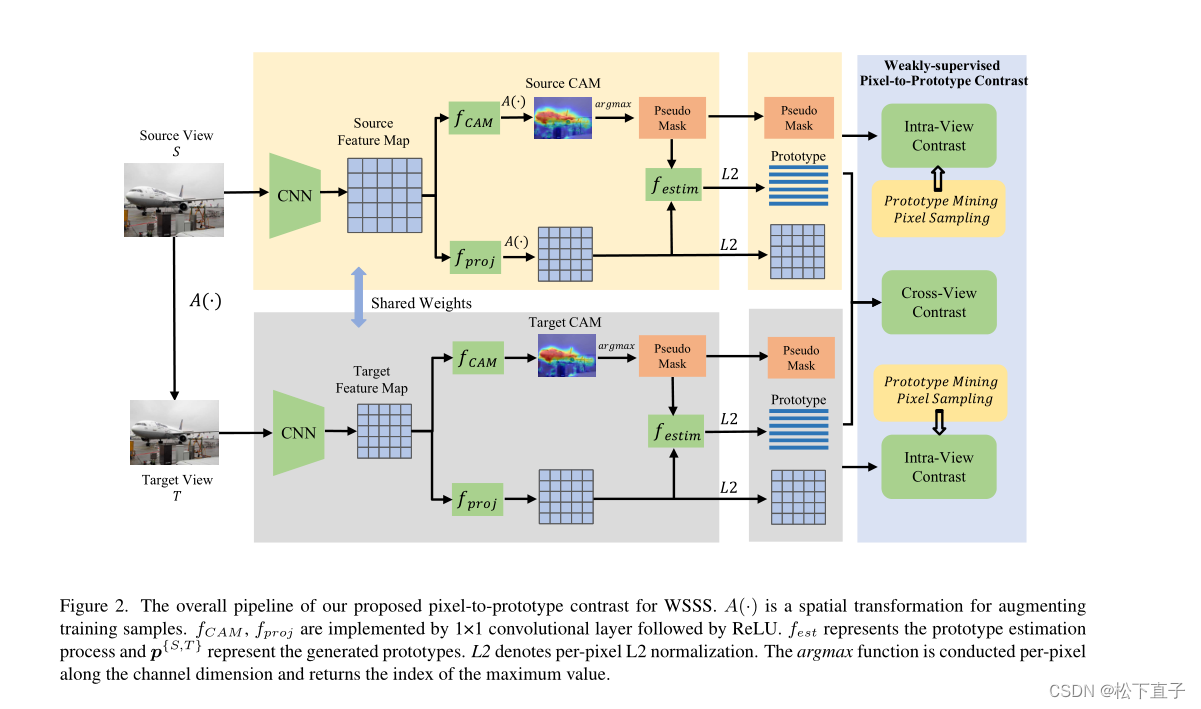
A(·)是增强训练样本的空间变换
fCAM, fproj由1×1卷积层实现,然后是ReLU。fest表示原型估计过程,p{S,T}表示生成的原型。
L2表示逐像素L2归一化。argmax函数沿着通道维度逐像素执行,并返回最大值的索引。
Pixel-to-Prototype Contrast
给定图像的CAM,我们使用逐像素的argmax函数来生成伪MASK y,即y = argmax(m),它决定了每个像素的类别。每个类别都有一个代表性的嵌入,原型用P = {pc}表示。
本文目标是在投影特征空间中通过对比学习来学习每个像素的判别特征嵌入。其思想如图所示
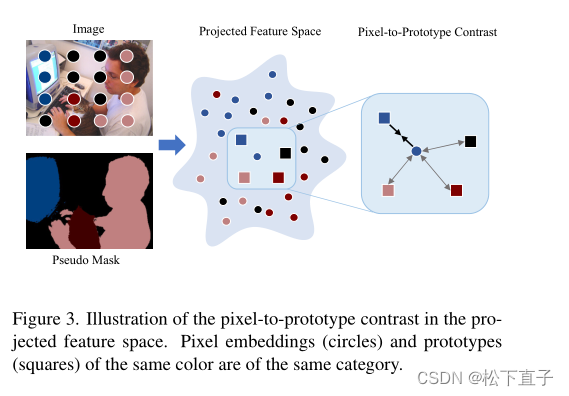
首先通过映射层获得像素级的特征vi∈R128,它由1 × 1卷积层实现,然后是ReLU。那么,给定vi和P,像素到原型的对比度F(·)有如下公式:
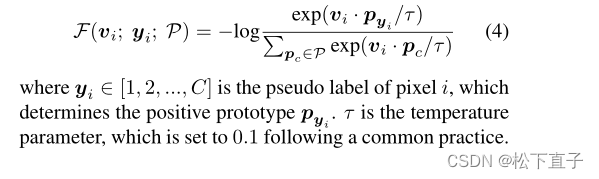
Prototype Estimation
进一步描述如何生成原型,一种可能的解决方案是通过聚类来挖掘像素级语义结构,就像在无监督语义分割中所做的那样。然而,在弱监督设置的情况下,该方法不能充分利用图像标签信息,通常需要过度聚类才能获得更好的性能。生成的聚类通常不能很好地匹配真正的类别。
在这项工作中,将像素级CAM值作为置信度,并建议从像素级特征嵌入中估计具有最高置信度的原型。具体来说,对于所有分配给c类的像素,我们经验地选择置信度最高的K个像素来估计原型。原型Pc计算是通过投影像素级嵌入的加权平均计算出来的:
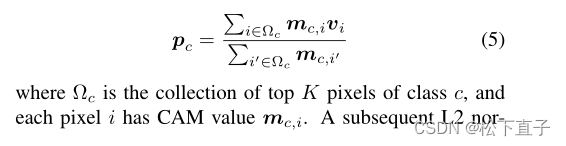
随后采用l2标准化对Pc
此外,为了捕获整个数据集的全局上下文,我们在整个训练批中计算原型,即选择整个训练中CAM值最高的像素。
Cross-view Contrast
交叉原型对比
考虑到两个视图之间的语义一致性,一个视图的原型可以作为另一个视图的监督信号,反之亦然。精确地说,给定一个像素i,其伪标签yi∈[1,2,…, C]和投影特征嵌入vi,借用另一个视图的原型P ’ = {P ’ C}对当前视图进行正则化。交叉原型对比损失计算为
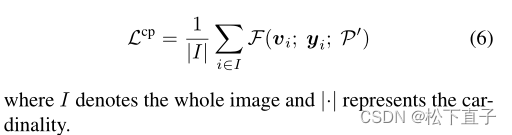
交叉CAM对比
此外,一个视图中的CAM也可以用于对另一个视图施加一致性正则化。CAM决定视图的伪掩码。因此,对于一个像素i在其自身视图中具有原型P,我们利用来自另一个视图的伪标签y 'i来确定正原型和负原型。类似地,交叉凸轮的对比损失可以写成
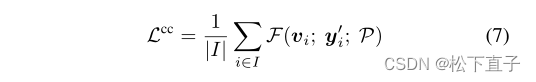
值得注意的是,跨视图对比是对称的,源视图和目标视图都可以作为当前视图计算Lcp和Lcc。最后将两个视图各自的Lcp和Lcc相加,得到总跨视图对比损失Lcross。
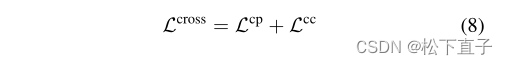
Intra-view Contrast
Intra-view Contrast
根据类内紧凑性和类间离散性的第二个假设,我们进一步提出了在每个图像的单个视图内进行的视图内对比。相对于交叉视图对比,对于一个带有伪标签yi的像素i,内视图对比从当前视图中获取原型P进行像素到原型的对比学习:
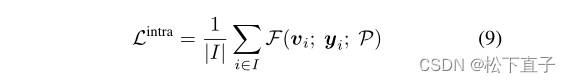
对两个视图进行视图内对比,为简单起见,在式(9)中不列出对称形式。
然而,我们通过实验发现,简单地引入Lintra会导致性能退化。原因是在弱监督设置的情况下,没有精确的像素级注释,分配给像素i的伪标签yi可能是不准确的,导致不准确的对比。在对比学习中的硬挖掘策略的激励下,通过引入半硬原型挖掘来缓解这个问题。此外,我们还采用了硬像素采样策略,更多地关注难以分割的像素样本
Semi-hard Prototype Mining
对于像素i,分配的标签yi决定了正原型pyi和负原型PN = P\pyi。本文没有直接使用PN,而是采用半硬原型挖掘:对于每个像素,我们首先收集前60%最难的负原型,从中选择50%作为负样本,计算视图内对比损失。
这里剩下的问题是如何定义“更难的”原型。对于像素i,我们将除了pyi之外的原型用点积来嵌入更接近于1的像素特征vi,即与像素相似的原型。
Hard Pixel Sampling
本文还引入了硬像素采样,以更好地利用硬像素。特别的是,没有使用属于一个原型pc的所有像素来计算视图内的对比损失,而是采用了逐类像素采样策略:对于每个类,一半像素是随机采样,一半像素是硬像素。
在训练期间定义了“更难的”像素,没有标签。对于原型pc,我们将点积与pc更接近- 1的归属像素视为更难的像素,即与原型不同的像素。“更硬”像素的定义与“更硬”原型正好相反,因为远离对应原型的像素需要更多的注意力才能拉近原型,以提高类内的紧凑性
我们实验证明,配备了这两种策略,我们减轻了不正确的对比和影响更好地使用困难的例子,这将进一步提高性能。
消融实验