目录
❤ 前言
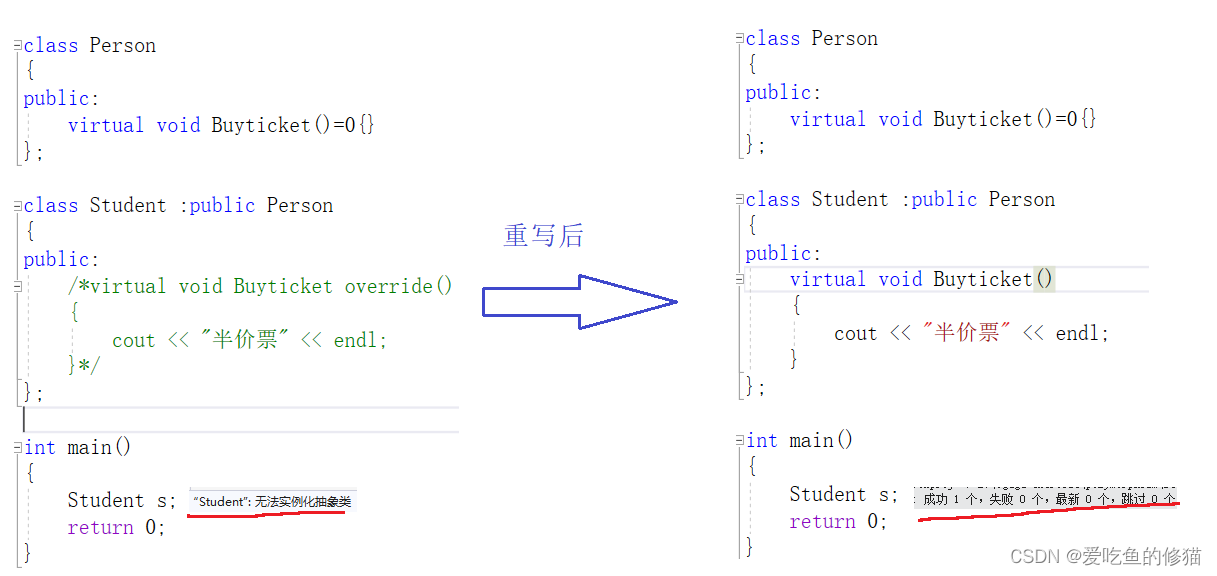
文本编辑器存取文件的原理(nodepad++,pycharm,word)
python解释器执行py文件的原理 ,例如python test.py
总结
❤ 什么是字符编码?
ASCII
MBCS
Unicode
❤ 字符编码的发展史
阶段一: 现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
阶段二: 为了满足中文,中国人定制了GBK
阶段三: 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
❤ 字符编码的分类
❤ 内存为什么不用UTF-8呢?
❤ 字符编码之文本编辑器操作
总结
❤ 乱码分析
乱码一:存文件时就已经乱码
乱码二:存文件时不乱码而读文件时乱码
❤ 总结
python从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129328397?spm=1001.2014.3001.5502
❤ 前言
文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
总结:
- python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
- 与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容
❤ 什么是字符编码?
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
编程的目的是让计算机干活,而编程的结果说白了只是一堆字符,也就是说我们编程最终要实现的是:一堆字符驱动计算机干活
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
ASCII
ASCII(American Standard Code for Information Interchange),是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制 符号。不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础。
MBCS
然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求。后来每个语言就制定了一套自己的编码,由于单字节能表示的字符太少,而且同时也需要与ASCII编码保持兼容,所以这些编码纷纷使用了多字节来表示字符,如GBxxx、BIGxxx等等,他们的规则是,如果第一个字节是\x80以下,则仍然表示ASCII字符;而如果是\x80以上,则跟下一个字节一起(共两个字节)表示一个字符,然后跳过下一个字节,继续往下判断。
这里,IBM发明了一个叫Code Page的概念,将这些编码都收入囊中并分配页码,GBK是第936页,也就是CP936。所以,也可以使用CP936表示GBK。
MBCS(Multi-Byte Character Set)是这些编码的统称。目前为止大家都是用了双字节,所以有时候也叫做DBCS(Double-Byte Character Set)。必须明确的是,MBCS并不是某一种特定的编码,Windows里根据你设定的区域不同,MBCS指代不同的编码,而Linux里无法使用 MBCS作为编码。在Windows中你看不到MBCS这几个字符,因为微软为了更加洋气,使用了ANSI来吓唬人,记事本的另存为对话框里编码ANSI就是MBCS。同时,在简体中文Windows默认的区域设定里,指代GBK。
Unicode
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
最初的Unicode标准UCS-2使用两个字节表示一个字符,所以你常常可以听到Unicode使用两个字节表示一个字符的说法。但过了不久有人觉得256*256太少了,还是不够用,于是出现了UCS-4标准,它使用4个字节表示一个字符,不过我们用的最多的仍然是UCS-2。
UCS(Unicode Character Set)还仅仅是字符对应码位的一张表而已,比如"汉"这个字的码位是6C49。字符具体如何传输和储存则是由UTF(UCS Transformation Format)来负责。
一开始这事很简单,直接使用UCS的码位来保存,这就是UTF-16,比如,"汉"直接使用\x6C\x49保存(UTF-16-BE),或是倒过来使用\x49\x6C保存(UTF-16-LE)。但用着用着美国人觉得自己吃了大亏,以前英文字母只需要一个字节就能保存了,现在大锅饭一吃变成了两个字节,空间消耗大了一倍……于是UTF-8横空出世。
UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII,ASCII字符使用1字节表示。然而这里省了的必定是从别的地方抠出来 的,你肯定也听说过UTF-8里中文字符使用3个字节来保存吧?
另外值得一提的是BOM(Byte Order Mark)。我们在储存文件时,文件使用的编码并没有保存,打开时则需要我们记住原先保存时使用的编码并使用这个编码打开,这样一来就产生了许多麻烦。 (你可能想说记事本打开文件时并没有让选编码?不妨先打开记事本再使用文件 -> 打开看看)而UTF则引入了BOM来表示自身编码,如果一开始读入的几个字节是其中之一,则代表接下来要读取的文字使用的编码是相应的编码:
BOM_UTF8 '\xef\xbb\xbf'
BOM_UTF16_LE '\xff\xfe'
BOM_UTF16_BE '\xfe\xff'
并不是所有的编辑器都会写入BOM,但即使没有BOM,Unicode还是可以读取的,只是像MBCS的编码一样,需要另行指定具体的编码,否则解码将会失败。
你可能听说过UTF-8不需要BOM,这种说法是不对的,只是绝大多数编辑器在没有BOM时都是以UTF-8作为默认编码读取。即使是保存时默认使 用ANSI(MBCS)的记事本,在读取文件时也是先使用UTF-8测试编码,如果可以成功解码,则使用UTF-8解码。记事本这个别扭的做法造成了一个 BUG:如果你新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成"汉a",你不妨试试.
❤ 字符编码的发展史
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到
Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode,统一用2Bytes代表一个字符,2**16-1=65535,可代表6万多个字符,因而兼容万国语言,但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
❤ 字符编码的分类
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
❤ 内存为什么不用UTF-8呢?
这样不就可以直接把代码从内存直接丢入硬盘了吗?出现这个问题的原因是硬盘中还躺了其他国家的代码,各个国家的代码的二进制还需要运行在计算机上使用,因此内存中必须使用Unicode的编码,因为Unicode能和硬盘中其他国家的二进制中的代码进行转换,但是UTF-8只是简化了代码的存储,它并不能与其他国家硬盘中的代码进行关系转换。总而言之只有Unicode编码才能运行其他国家硬盘中的代码,而UTF-8的代码无法进行该操作。
内存中还使用Unicode编码,是因为历史遗留问题造成的,但是因为现在写代码使用的都是UTF-8代码,所以以后内存中的代码都将变成UTF-8代码,并且以前遗留的各个国家的代码都将被淘汰,所以未来内存中使用的编码也将使用UTF-8编码替代Unicode编码。
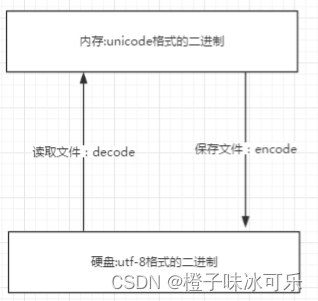
❤ 字符编码之文本编辑器操作
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
而文件编码保存时候使用的编码方式是右下角的编码方式,而解码的时候是使用文档开头申明的编码方式,两种编码不同的时候很容易出现乱码的情况。
❤ 乱码分析
首先明确概念
- 文件从内存刷到硬盘的操作简称存文件
- 文件从硬盘读到内存的操作简称读文件
乱码的两种情况:
-
乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败。但当我们硬要存的时候,编辑并不会报错(难道你的编码错误,编辑器这个软件就跟着崩溃了吗???),但毫无疑问,不能存而硬存,肯定是乱存了,即存文件阶段就已经发生乱码,而当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了。
-
乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了。
❤ 总结
- 保证不乱码的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码。
- 在内存中写的所有字符,一视同仁,都是Unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是Unicode转换成其他编码格式的过程了。简而言之,就是内存中固定使用的就是Uncidoe编码,我们唯一能改变的就是存储到硬盘时使用的编码。
- Unicode----->encode(编码)-------->gbk
- Unicode<--------decode(解码)<----------gbk