网络爬虫—多进程详讲
- 一·进程的概念
- 二·创建多进程
- 三·进程池
- 四·线程池
- 五·多进程和多线程的区别
- 六·实战演示
- 北京新发地线程池实战
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
🎁🎁《Python网络爬虫》专栏累计发表十二篇文章,上榜四篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
一·进程的概念
🧾 🧾进程是指计算机中正在执行的程序实例,它是操作系统进行资源分配和调度的基本单位。
- 进程可以包含多个线程,每个线程负责执行不同的任务。
- 进程之间相互独立,拥有独立的内存空间和资源,通过进程间通信来实现数据共享和协作。
- 进程可以在计算机系统中运行多个,操作系统根据优先级和资源需求来调度进程的执行,以保证系统的稳定性和性能。
🧾 简单来说:
比如你打开了一个文本编辑器,这个文本编辑器就是一个进程。进程可以包含多个线程,每个线程负责执行不同的任务。比如,在一个音乐播放器中,可能有一个线程负责播放音乐,另一个线程负责显示歌曲信息。
操作系统会根据进程的优先级和资源需求来调度进程的执行。这样可以保证系统的稳定性和性能,避免出现一些进程占用过多资源而导致系统崩溃或变慢的情况。
总之,进程是一个非常重要的计算机概念,它是操作系统进行资源分配和调度的基本单位,也是我们使用计算机时经常接触到的概念之一。
二·创建多进程
🧾 🧾==Python创建多进程可以使用multiprocessing模块。该模块提供了一个Process类,可以用来创建新的进程。==
🧾 下面是一个简单的例子,展示如何使用multiprocessing模块创建多进程:
import multiprocessingdef worker(num):"""子进程要执行的代码"""print('Worker %d is running' % num)if __name__ == '__main__':# 创建5个子进程for i in range(5):p = multiprocessing.Process(target=worker, args=(i,))p.start()
上面的代码中,我们定义了一个worker函数,它接受一个参数num,用于标识该进程的编号。在主程序中,我们使用for循环创建了5个子进程,并且将worker函数作为参数传递给Process类的构造函数。然后,我们调用start方法启动子进程。
🧾 当我们运行这个程序时,会输出下面的结果:
Worker 0 is running
Worker 1 is running
Worker 2 is running
Worker 3 is running
Worker 4 is running
可以看到,5个子进程都在运行,并且输出了自己的编号。
除了使用Process类外,multiprocessing模块还提供了其他一些类和函数,用于创建和管理多进程。比如,我们可以使用Pool类来创建进程池,从而实现并发执行多个任务。
🧾 下面是一个使用Pool类的例子:
import multiprocessingdef worker(num):"""子进程要执行的代码"""print('Worker %d is running' % num)if __name__ == '__main__':# 创建进程池,最大进程数为3pool = multiprocessing.Pool(processes=3)# 将5个任务分配给进程池for i in range(5):pool.apply_async(worker, args=(i,))# 关闭进程池,等待所有任务执行完毕pool.close()pool.join()
上面的代码中,我们使用Pool类创建了一个进程池,最大进程数为3。然后,我们使用apply_async方法将5个任务分配给进程池。最后,我们调用close方法关闭进程池,并使用join方法等待所有任务执行完毕。
🧾 当我们运行这个程序时,会输出下面的结果:
Worker 0 is running
Worker 1 is running
Worker 2 is running
Worker 3 is running
Worker 4 is running
可以看到,5个任务被分配给了3个进程,并发执行。
三·进程池
🧾 🧾Python进程池是一种用于管理和调度多个进程的技术,它能够提高程序的并发性和效率。通过创建一个进程池,我们可以将多个任务分配给池中的进程,使得它们可以并行执行,从而加快程序的运行速度。
🧾 创建多个进程,我们不用傻傻地一个个去创建。我们可以使用Pool模块来搞定。Pool 常用的方法如下:
| 方法 | 含义 |
|---|---|
| apply() | 同步执行(串行) |
| apply_async() | 异步执行(并行) |
| terminate() | 立刻关闭进程池 |
| join() | 主进程等待所有子进程执行完毕。必须在close或terminate()之后使用 |
| close() | 等待所有进程结束后,才关闭进程池 |
🧾 Pool类提供了一个简单的接口来创建进程池并管理多个进程。下面是一个简单的示例代码:
import multiprocessingdef func(x):return x*xif __name__ == '__main__':with multiprocessing.Pool(processes=4) as pool:results = pool.map(func, [1, 2, 3, 4, 5])print(results)
在上面的代码中,我们定义了一个名为func的函数,它接受一个参数并返回其平方值。接下来,我们使用with语句创建了一个进程池,并指定了进程数为4。然后,我们使用map方法将任务分配给进程池中的进程,并将结果存储在results变量中。
在这个例子中,我们使用了map方法来将任务分配给进程池中的进程。map方法接受一个函数和一个可迭代对象作为参数,并返回一个列表,其中包含了函数对每个元素的处理结果。在这个例子中,我们将func函数和一个包含5个数字的列表作为参数传递给map方法,最终得到了一个包含5个数字平方值的列表。
四·线程池
🧾 🧾Python线程池和进程池类似,也是一种用于管理和调度多个线程的技术,它能够提高程序的并发性和效率。
通过创建一个线程池,我们可以将多个任务分配给池中的线程,使得它们可以并行执行,从而加快程序的运行速度。
🧾 🧾Python中的线程池可以使用concurrent.futures模块中的ThreadPoolExecutor类来实现。
ThreadPoolExecutor类提供了一个简单的接口来创建线程池并管理多个线程。下面是一个简单的示例代码:
import concurrent.futuresdef func(x):return x*xif __name__ == '__main__':with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:results = executor.map(func, [1, 2, 3, 4, 5])print(list(results))
在上面的代码中,我们定义了一个名为func的函数,它接受一个参数并返回其平方值。接下来,我们使用with语句创建了一个线程池,并指定了线程数为4。然后,我们使用map方法将任务分配给线程池中的线程,并将结果存储在results变量中。
在这个例子中,我们使用了map方法来将任务分配给线程池中的线程。map方法接受一个函数和一个可迭代对象作为参数,并返回一个迭代器,其中包含了函数对每个元素的处理结果。在这个例子中,我们将func函数和一个包含5个数字的列表作为参数传递给map方法,最终得到了一个包含5个数字平方值的列表。
五·多进程和多线程的区别

🧾 🧾多线程和多进程都是用于提高程序并行处理能力的技术,但它们有以下几个方面的不同:
-
资源占用:多进程需要更多的资源,每个进程都需要独立的内存空间、CPU时间片等,而多线程则共享进程的资源,每个线程只需独立的栈空间和程序计数器。 -
数据共享:多进程之间的数据通信比较麻烦,需要使用IPC(进程间通信)技术,而多线程之间的数据共享比较容易,可以使用共享内存等方式。 -
稳定性:多进程的稳定性比较高,一个进程崩溃不会影响其他进程的正常运行,而多线程的稳定性较差,一个线程崩溃可能会导致整个进程崩溃。 -
编程难度:多线程的编程难度比较低,因为线程间的数据共享比较容易处理,而多进程的编程难度较高,因为进程间的数据共享需要使用IPC技术。
🧾 🧾程序一般属于两种类型:CPU密集型和I/O密集型。
- CPU 密集型:程序比较偏重于计算,需要经常使用CPU来运算。例如科学计算的程序,机器学习的程序等。
- I/O 密集型:顾名思义就是程序需要频繁进行输入输出操作。爬虫程序就是典型的I/O密集型程序。
如果程序是属于CPU密集型,建议使用多进程。而多线程就更适合应用于I/O密集型程序。
六·实战演示
北京新发地线程池实战
1·任务目标 🔥 🔥:使用线程池获取北京新发地蔬菜前一百页数据到csv文件中。
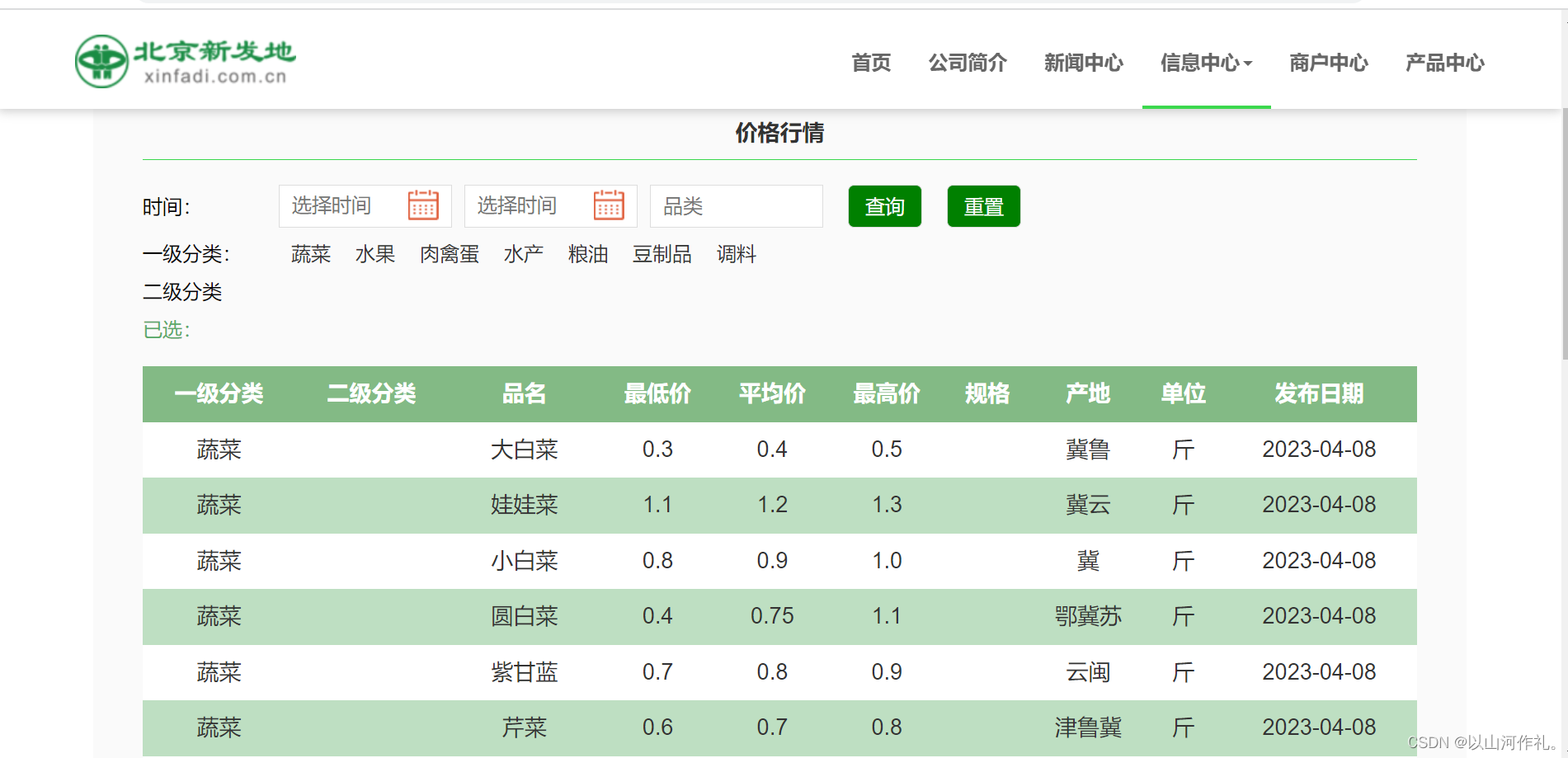
🎯2·按照之前学过的知识,我们一步一步来,按照普通的方法,先找数据,接着将数据获取到本地,然后在写入csv文件。
🎯3·通过查找数据和抓包,我们知道了数据在什么地方,接下来我们使用代码来将数据获取到本地:
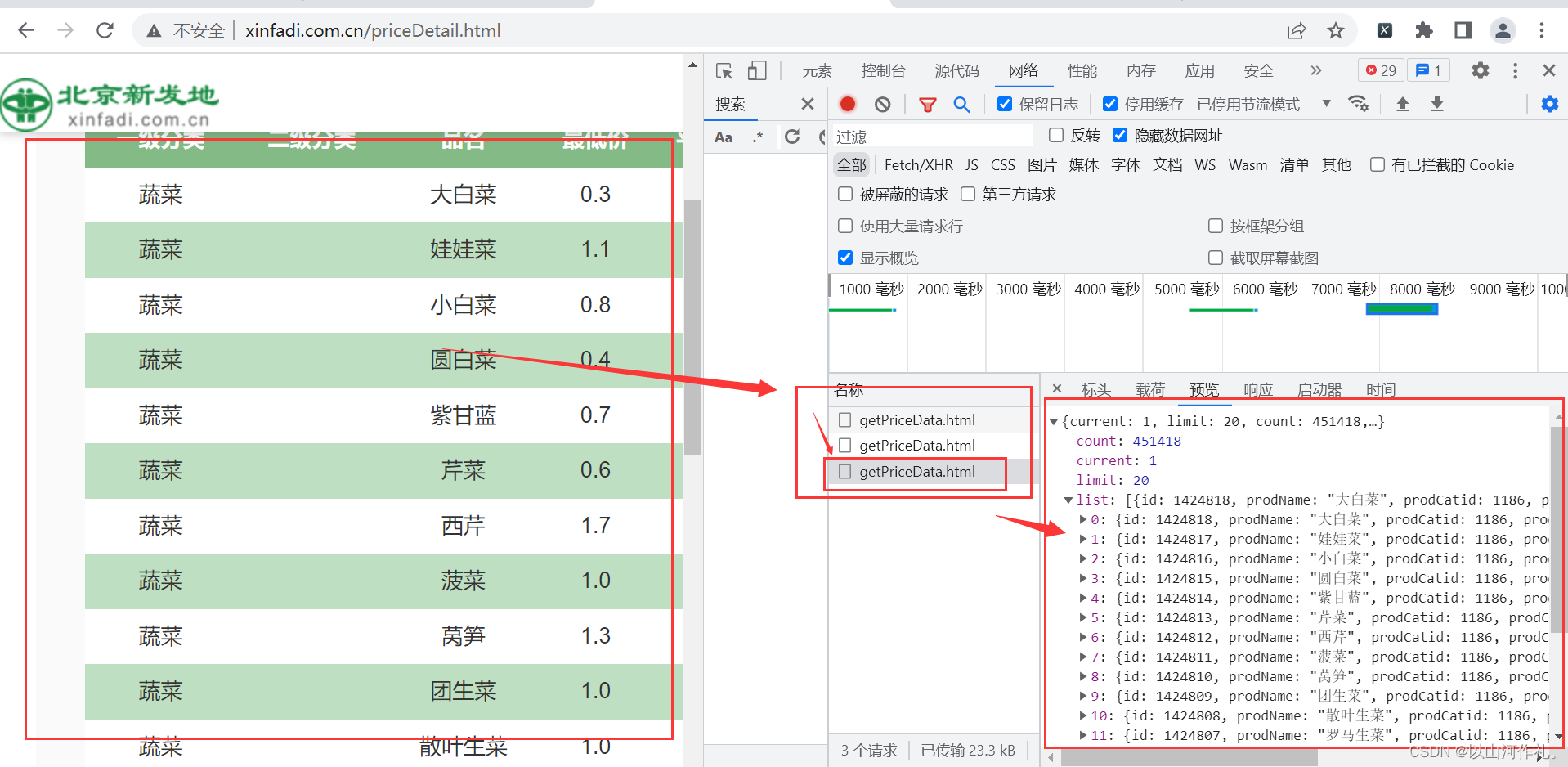
🎯4·代码如下:(获取第一页数据的代码)
import requestsurl = 'http://www.xinfadi.com.cn/getPriceData.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}json_data = requests.post(url, headers=headers).json()
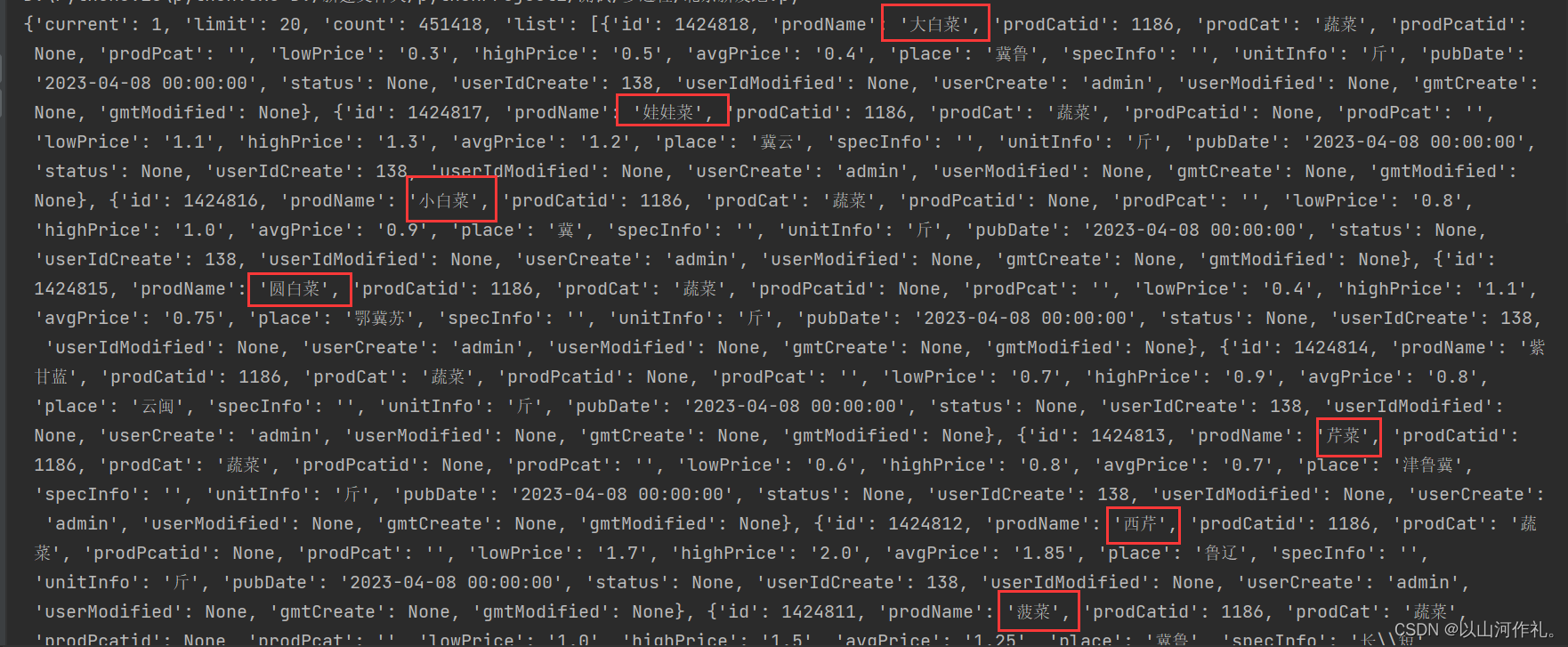
print(json_data)🎯5·数据如下:
🎯6·我们将数据解析放入csv文件中:
import csvimport requestsurl = 'http://www.xinfadi.com.cn/getPriceData.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}head = ['id', 'prodName', 'prodCatid', 'prodCat', 'prodPcatid', 'prodPcat', 'lowPrice', 'highPrice', 'avgPrice','place', 'specInfo', 'unitInfo', 'pubDate', 'status', 'userIdCreate', 'userIdModified', 'userCreate','userModified', 'gmtCreate', 'gmtModified']f = open('data.csv', 'w+', encoding='gbk', newline='')
csv_file = csv.writer(f)
csv_file.writerow(head)json_data = requests.post(url, headers=headers).json()
# print(json_data)
for dict_obj in (json_data['list']):data_list = []for j in head:data_list.append(dict_obj[j])csv_file.writerow(data_list)
f.close()
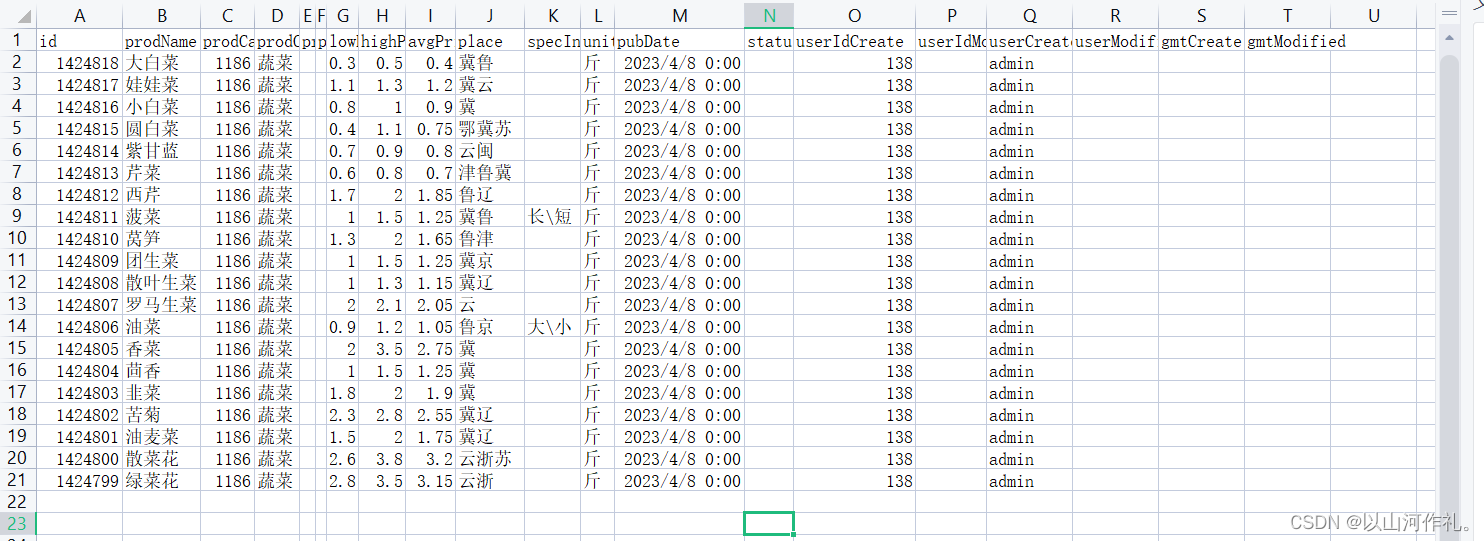
🎯7·这是第一页数据,完成了一大步。接着我们开始写循环,并且使用线程池来帮助我们更快的获取数据到本地。
🎯8·重要的代码我都写上了注释方便理解,就不在代码片以外做过多的解释;
import csv
from concurrent.futures import ThreadPoolExecutorimport requestsurl = 'http://www.xinfadi.com.cn/getPriceData.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}# 字段
head = ['id', 'prodName', 'prodCatid', 'prodCat', 'prodPcatid', 'prodPcat', 'lowPrice', 'highPrice', 'avgPrice','place', 'specInfo', 'unitInfo', 'pubDate', 'status', 'userIdCreate', 'userIdModified', 'userCreate','userModified', 'gmtCreate', 'gmtModified']# 创建csv文件
f = open('data.csv', 'w+', encoding='gbk', newline='')
csv_file = csv.writer(f)
csv_file.writerow(head)# 创建了一个名为pool的ThreadPoolExecutor对象,其中线程池大小为20。20为最大线程数量
pool = ThreadPoolExecutor(20)def data_get(page): # 定义了一个名为data_get的函数,用于获取每一页的数据,并将数据存储到CSV文件中。函数中的参数page表示当前页数。data = {'limit': 20,'current': page}#定义了一个名为data的字典,用于存储POST请求的参数。然后使用requests库发送POST请求,并将返回的JSON数据转换为字典格式。json_data = requests.post(url, headers=headers, data=data).json()for dict_obj in (json_data['list']): #使用for循环遍历每一个字典对象,并将需要的数据存储到一个列表中。最后,使用csv库将数据写入到CSV文件中。data_list = []for j in head:data_list.append(dict_obj[j]) # i是一个字典 j是keyprint(page, data_list)# 存储数据 安行写入数据csv_file.writerow(data_list)for index in range(1, 1 + 100): # 循环页数pool.submit(data_get, index) # 将数据存入线程池
#在主函数中使用for循环遍历每一页数据,并将每一页数据提交给线程池中的线程进行处理。具体地,使用pool.submit()方法将数据提交给线程池中的线程。
# 是否等线程全部结束继续往下面运行,相当于多线程的join()
pool.shutdown(True) #使用pool.shutdown(True)方法等待所有线程结束。其中,参数True表示等待所有线程结束后再继续往下执行。
# 关闭文件,将数据存入到文件
f.close()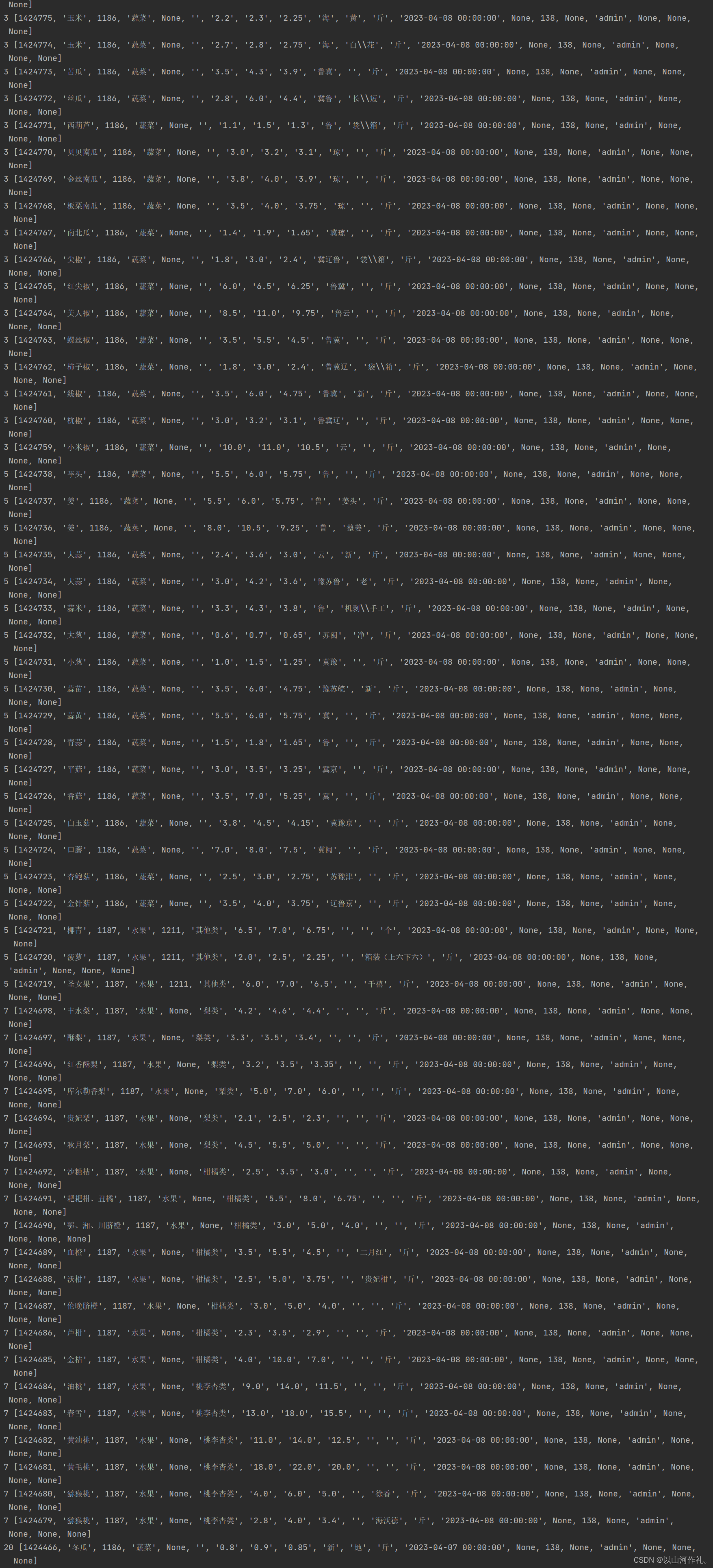
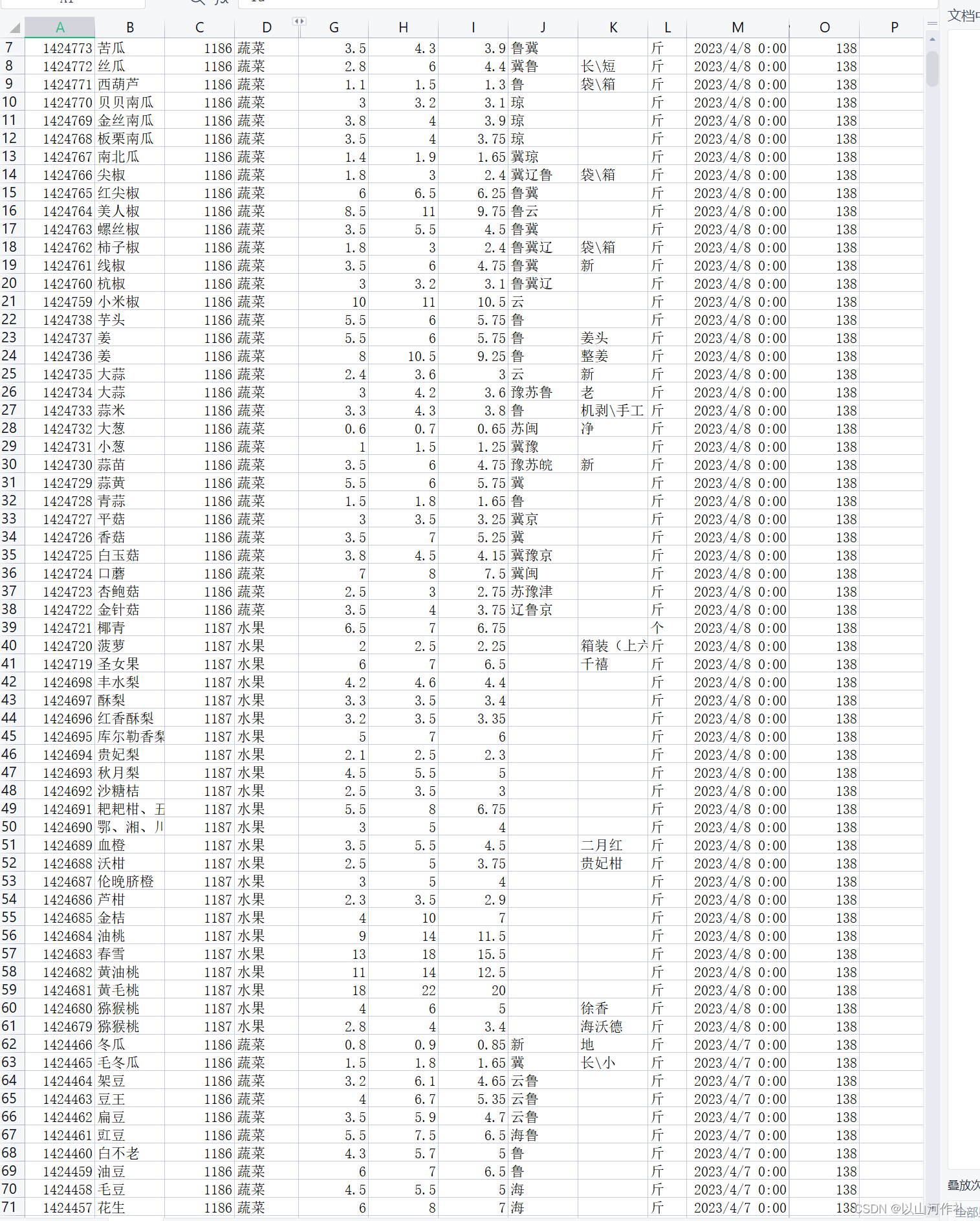
🎯9·任务目标到此就算完成,使用线程池获取数据能提高效率和节省资源,提高稳定性等。想要熟练的使用线程池就必须了解线程池的基本概念和原理,学习线程池的实现方法,然后练习使用线程池解决实际问题。
写在最后:
👉👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹

![动力节点王鹤SpringBoot3笔记——远程访问@HttpExchange[SpringBoot 3]](/images/no-images.jpg)