目录
- 引子
- 十大SQL
- 1. 统计班级总分前十名
- 2. 删除重复记录, 且保留一条
- 3. 最大连续登陆天数的问题
- 4. 计算除去部门最高工资,和最低工资的平均工资
- 5. 计算占比和同比增长
- 6. 算成绩
- 7.算昨天每个城市top 10消费金额的用户,输出city_id,city_name,uid, 消费总金额
- 8. 求连续点击三次的用户数,中间不能有别人的点击 ,最大连续天数的变形问题
- 9. AB球队得分流水表,得到连续三次得分的队员名字 和每次赶超对手的球员名字
- 10. 举例说明内连接、外连接、左连接、右连接的区别
- SQL语法图解
- 窗口函数
- 参考
引子
哪些是程序员的通用能力?算法、正则表达式和SQL。这三样,是程序员的基本功,就跟数学公式一样,它不涉及智商,但关乎你的学习态度,牵扯到程序员的面子。面试官考这些时,如果连这个都不会,就会遭到鄙视。有次有个应聘者质疑我,说术业有专攻,你不该考这些问题,说我这是在问茴字的四种写法。
十大SQL
1. 统计班级总分前十名
表结构stu_score:(student_id, course_id, score)
select student_id, sum(score) as s from stu_score group by student_id order by s desc limit 10
这道题比较基本,考察聚合函数用法。下面两个进阶一点:
要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
select 课程号,count(学号) as 选修人数
from score
group by 课程号
having 选修人数 >=2
order by 选修人数 desc, 课程号 asc;
查询没有学全所有课的学生的学号、姓名
select 学号,姓名
from student
where 学号 in
(select 学号
from score
group by 学号
having count(课程号) < (select count(课程号) from course));
2. 删除重复记录, 且保留一条
表结构: (book_id, book_name)
从书籍列表里,删除书名重复的记录,保留book_id最小的记录:
delete from ebook
where book_name in (select book_name from ebook group by book_name having count(*) > 1)and book_id not in (select min(book_id) from ebook group by book_name having count(*)>1);
这个考察了子查询和min()函数以及having子句的使用。很多数据库都支持这种子查询。注意,上述SQL在MySQL中执行会报错:
[HY000][1093] You can't specify target table 'ebook' for update in FROM clause
这是因为MySQL不允许你在做子查询时去修改表。trick的办法是创建临时表:
delete from ebook
where book_name in (select t1.book_name from (select book_name from ebook group by book_name having count(*) > 1) as t1)and book_id not in (select t2.id from (select min(book_id) as id from ebook group by book_name having count(*)>1) as t2);
上面创建了两张临时表t1和t2。这样MySQL就可以执行了。
3. 最大连续登陆天数的问题
题目: 找出连续7天登陆,连续30天登陆的用户。
考察点:窗口函数
select *
from
(select user_id ,count(1) as numfrom(select user_id,date_sub(log_in_date, rank) dtsfrom (select user_id,log_in_date, row_number() over(partitioned by user_id order by log_in_date ) as rankfrom user_log)t)agroup by dts
)b
where num = 7
4. 计算除去部门最高工资,和最低工资的平均工资
emp 表:(id 员工 id ,deptno 部门编号,salary 工资)
核心是使用窗口函数降序和升序分别排一遍就取出了最高和最低。
select a.deptno,avg(a.salary)
from (select *, rank() over( partition by deptno order by salary ) as rank_1, rank() over( partition by deptno order by salary desc) as rank_2 from emp) a
group by a.deptno
where a.rank_1 >1 and a.rank_2 >1
5. 计算占比和同比增长
t_user记录了用户注册时间和平台,统计2018年1月份
每天各平台(“ios”,“android”,“h5”)注册用户总量占所有平台总用户的比例,以及各平台注册用户按周同比增长(与一周前相比)的比例
建表语句
create table t_user
(
uid BIGINT COMMENT "用户id"
, reg_time STRING COMMENT "注册时间,如2018-07-01 08:11:39"
, platform STRING COMMENT "注册平台,包括app ios h5"
);
解答:
知识点:窗口函数。
注意:如果存在某天的缺失数据,偏移函数会有错误
SELECT a.reg_date
,a.platform
,ROUND(a.reg_num/sum(a.reg_num)over(PARTITION BY a.reg_date),4) as rate
,ROUND((a.reg_num-a.reg_num_7)/a.reg_num_7,4) as rate_week
FROM(
SELECT
DATE(reg_time) as reg_date
,platform
,COUNT(uid) as reg_num
,lag(COUNT(uid),7)over(PARTITION BY platform ORDER BY DATE(reg_time)) as reg_num_7
FROM t_user
WHERE SUBSTR(reg_time,1,7)='2018-01'
GROUP BY DATE(reg_time),platform
) a ;
6. 算成绩
表名:subject_scores
输入
Name subject score
王建国 数学 95
王建国 语文 89
李雪琴 数学 100
李雪琴 语文 100
李雪琴 英语 100
输出
Name math chinese English
王建国 95 89 0
李雪琴 100 100 100
解答:
所涉知识点:GROUP BY 和 CASE WHEN 实现行变列
注意:(1)空的数据这里判断为0;(2)CASE WHEN 前要使用聚合函数,不然报错)
SELECT
name,
MAX(CASE subject WHEN '数学' THEN score ELSE 0 END) as math,
MAX(CASE subject WHEN '语文' THEN score ELSE 0 END) as chinese,
MAX(CASE subject WHEN '英语' THEN score ELSE 0 END) as English
FROM subject_scores
GROUP BY name;
7.算昨天每个城市top 10消费金额的用户,输出city_id,city_name,uid, 消费总金额
表名:orders
每次消费记录一条
city_id,city_name,uid,order_id,amount,pay_order_time, pay_date
解答:(窗口函数)
SELECT a.city_id,
a.city_name,
a.uid,
a.pay_amount as '消费总金额'
FROM
(
SELECT city_id,city_name,uid,SUM(amount) as pay_amount,RANK()over(PARTITION BY city_id ORDER BY SUM(amount) DESC) as rank_no
FROM orders
WHERE pay_date='2020-01-01'
GROUP BY city_id,city_name,uid
) a
WHERE a.rank_no<=10;
8. 求连续点击三次的用户数,中间不能有别人的点击 ,最大连续天数的变形问题
总结:相邻问题的本质就是基于研究对象(比如用户、会员、员工等),利用窗口函数对时间字段进行有差别的排序,然后基于研究对象和新增的{排序差值列},进行分组计数的求连续点击、签到、复购等业务问题的计算;
'''
a表记录了点击的流水信息,包括用户id ,和点击时间
usr_id a a b a a a a
click_time t1 t2 t3 t4 t5 t6 t7'''
-- 方式一:
use demo;
WITH t1 AS (SELECT MemberID AS user_id, STime AS click_timeFROM OrderListWHERE MemberID IS NOT NULL/*选取demo.OrderList 作为底表测试数据*/AND DATE_FORMAT(STime, '%Y-%m') = '2017-02'), t2 AS (SELECT *, row_number() OVER (ORDER BY click_time) AS rank1, row_number() OVER (PARTITION BY user_id ORDER BY click_time) AS rank2FROM t1), t3 AS (SELECT *, rank1 - rank2 AS diffFROM t2), t4 AS (SELECT DISTINCT user_idFROM t3GROUP BY user_id, diffHAVING COUNT(1) > 3)
-- SELECT * from t4 ;
SELECT *
FROM t3
WHERE user_id IN (SELECT user_idFROM t4
)
ORDER BY user_id, diff, click_time; -- 方式二: SELECT DISTINCT user_id
FROM (SELECT *, rank_1 - rank_2 AS diffFROM (SELECT *,row_number() OVER (ORDER BY click_time) AS rank_1,row_number() OVER (PARTITION BY user_id ORDER BY click_time) AS rank_2FROM (SELECT MemberID AS user_id, STime AS click_timeFROM OrderListWHERE MemberID IS NOT NULL /*选取demo.OrderList 作为底表测试数据*/AND DATE_FORMAT(STime, '%Y-%m') = '2017-02') a) b
) c
GROUP BY diff, user_id
HAVING COUNT(1) > 3; 9. AB球队得分流水表,得到连续三次得分的队员名字 和每次赶超对手的球员名字
表结构:
create table bktab (team string comment '球队名称',number int comment '球员号码',score_time string comment '得分时间',score int comment '得分分数',name string comment '球员姓名')
comment 'AB球队得分流水表'
row format delimited fields terminated by '\t'
lines terminated by '\n' stored as orc;
分析思路:
1.按score_time 对全局排序
2.获取当前行 A队累计得分 B队累计得分
3.获取 当前 A队累计得分 与 B队累计得分的差值
4.当前行差值 与上一行差值,发生符合变化时,表示 分数发生了反超
-- 查询sql
selectteam,number,score_time,score,name,ateam_score,bteam_score
from (selectteam,number,score_time,score,name,ateam_score,bteam_score,diff_score,lag(diff_score) over (order by score_time asc) as pre_diff_score,case when diff_score > 0 and lag(diff_score) over (order by score_time asc) < 0 then 1when diff_score < 0 and lag(diff_score) over (order by score_time asc) > 0 then 1when diff_score is not null and lag(diff_score) over (order by score_time asc) is null then 1else 0end as if_surpassfrom (selectteam,number,score_time,score,name,sum(if(team = 'A',score,0)) over (order by score_time asc) as ateam_score,sum(if(team = 'B',score,0)) over (order by score_time asc) as bteam_score,sum(if(team = 'A',score,0)) over (order by score_time asc) - sum(if(team = 'B',score,0)) over (order by score_time asc) as diff_scorefrom bktab) t1
) t2
where if_surpass = 1
;
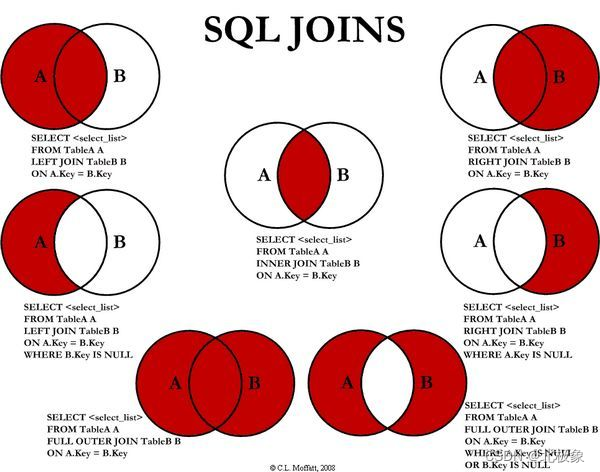
10. 举例说明内连接、外连接、左连接、右连接的区别
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法:
查询所有课程成绩小于60分学生的学号、姓名
SELECT A.学号,B.姓名 FROM score A LEFT JOIN student B ON A.学号 = B.学号 GROUP BY A.学号 HAVING MAX(成绩) < 60;
SELECT customer.last_name, city.name
FROM customer
INNER JOIN cityON customer.id = city.customer_id;
SELECT c.last_name AS lname, t.name AS city
FROM customer AS c
INNER JOIN city AS tON c.id = t.customer_id;
SELECT last_name FROM customer
INTERSECT
SELECT last_name FROM employee;
You can join tables using JOIN, including INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN, and CROSS JOIN (please see the courses listed at the end of this article for more information). In this example, we want to join data from the tables customer and city. INNER JOIN needs to come after FROM and the name of the first table, customer. After INNER JOIN, place the name of the second table, city. The records with data from both tables are matched by ON with the condition to join. The records in the table city are matched to the records from the table customer if they have the same value in the column id in the table customer and in the column customer_id in the table city.
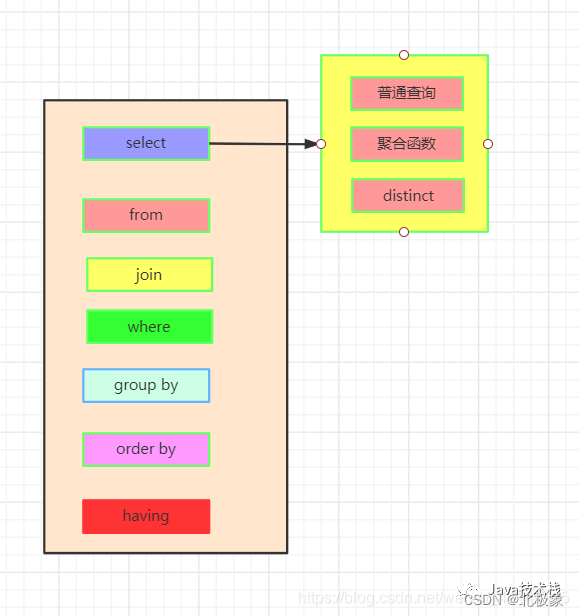
SQL语法图解
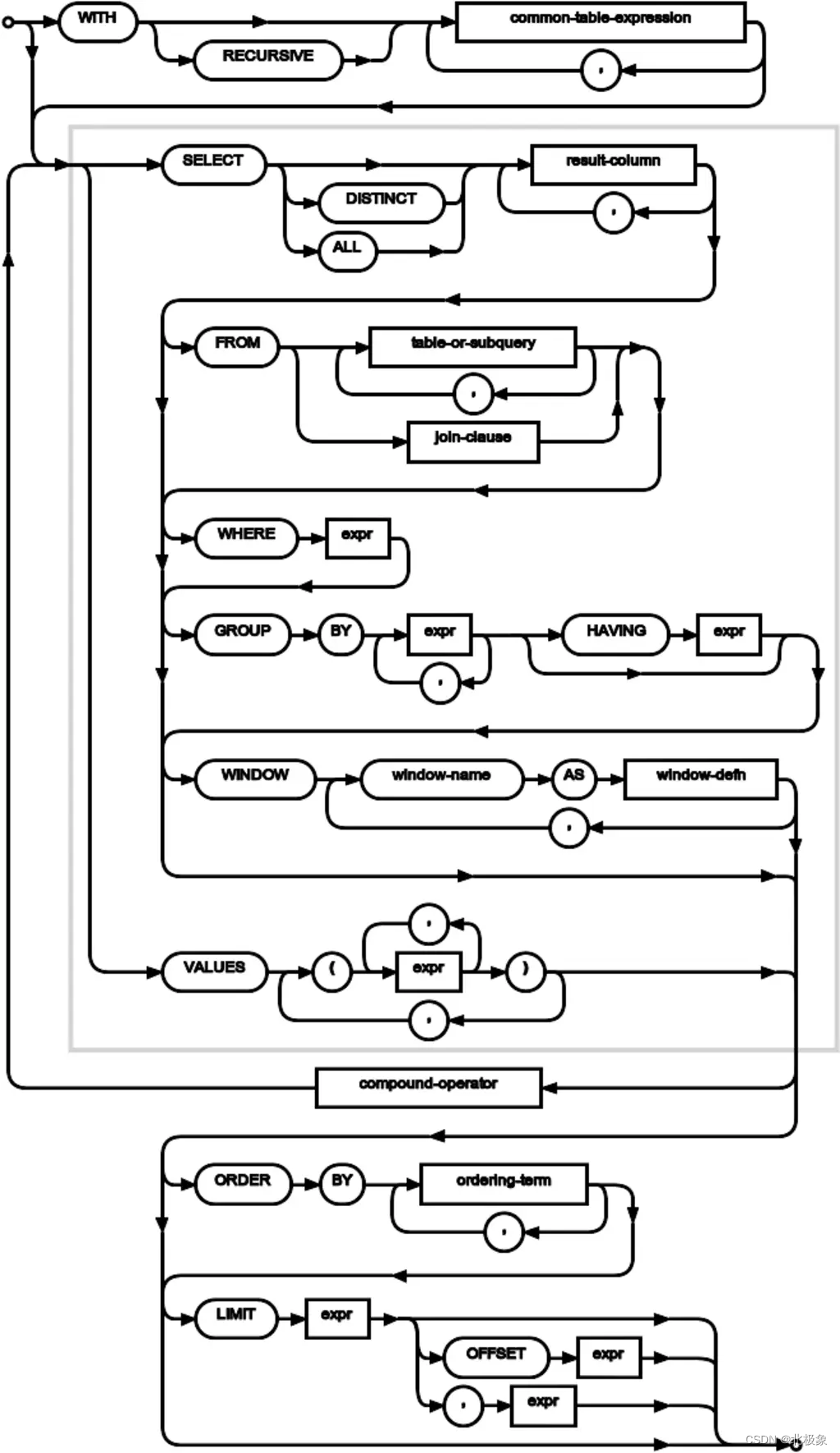
窗口函数
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)
窗口函数包括:
1) 专用窗口函数,如rank, dense_rank, row_number等专用窗口函数
2) 聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
参考
- https://zhuanlan.zhihu.com/p/92654574