系统可靠性:互联网时代的挑战
SLA保证
- 事故时长45 分钟内--4个9
- 事故时长5小时--打破 3个9的承诺
- 事故细节:亚马逊 6 页纸 技术细节
系统可靠性
- 影响半径---->从低往上扩大;从上往下是依赖;
- 单节点是root cause;大规模;测试、架构设计很难预防;
- 观点:高流量、低时延、数据一致性、快速上线 要求;
- 【自研系统】 【Cloud Native(搭积木 选择block)】 【云计算(脏累的活,打包架构方案)】 3套系统5种状态 (桌面上---架构师 CNCF 解决方案)
- 系统可靠性 = f(发生概率,持续时间,影响半径)
事故原因分析
- 人为失误:删除数据系统; -- 常态
- 系统故障:大集群超过1W个节点 -- 常态
- 没有pre_prod环境
- 日常OPS操作 -- 审批等
减少事故方案
- 减少爆炸半径:影响控制在50%内,通过限流、降级系统还可以运作;
- 金丝雀发布、报警(ftf):抢先发现问题
- 微软:日志、监控 报警如果很敏感,报警误报--->直接关闭(组织架构决定了系统架构和做事方法:不完善的还不如没有)
- 亚马逊:devops 开发、测试、运维 同一个团队中(24*7 相应报警)
系统可靠性RCA分享
- SOP 标准操作流程;故障操作手册;自查;自检;长时间演练、有预案(注意:有序的预案);
- dashbord 仪表盘;
- War-Room 会议室; root-cause :所有节点数据误删,但有备份;
- TTD 事故监测时间;2分钟
- TTR 事故恢复时间;
- 如果100个团队有问题,个人一般不会是Trouble Maker;
复盘整改
good
- 事件报警及时
- 相应升级迅速
- 数据备份恢复正常
- 团队应急有序
bad
- 生产环境误操作 -- 冲击粗壮神经
- 冷启动多年未试
- 冷启重试缺少规范 -- 雪崩效应的原因
商旅实践
方法论(务虚)
一

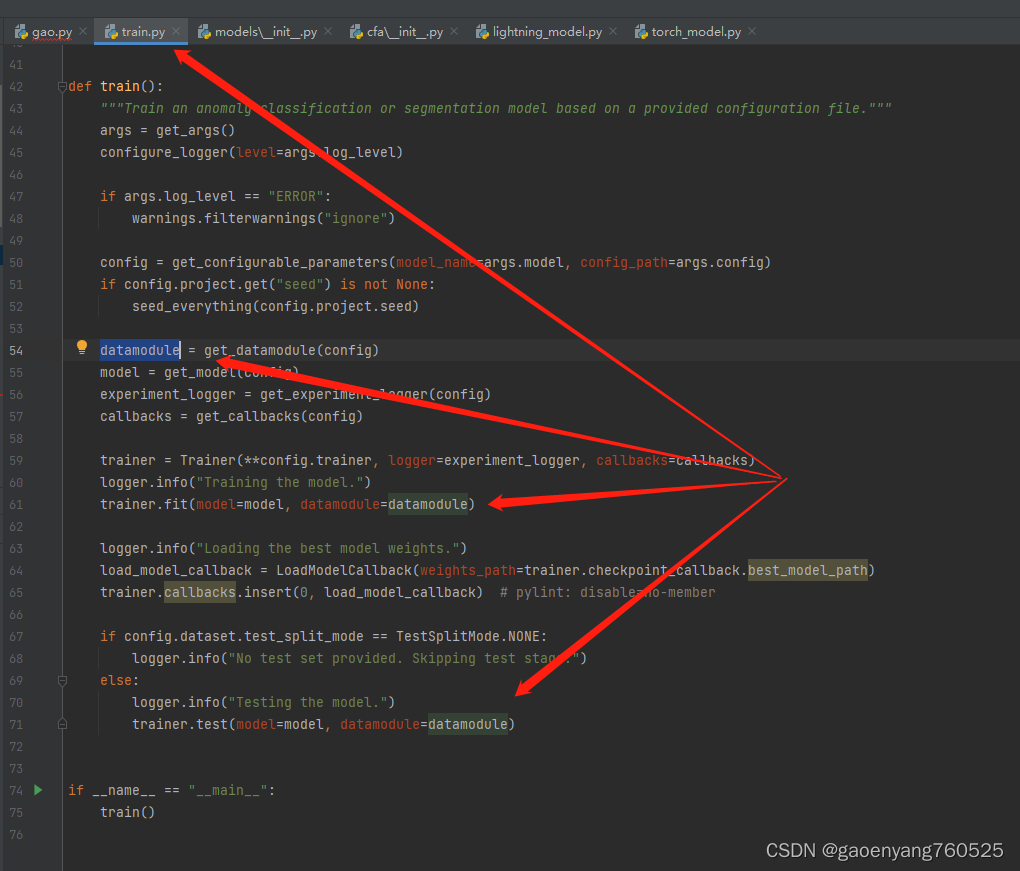
Quality is not an act, it is a habit 品质不是一时的表现,是长久的习惯
- 亚里士多德
- 好的品质是好的习惯造成的;
- 不好的品质...当你背着腾讯、阿里的光环发现问题时不好的习惯,一定要清醒的认识到到它是根深蒂固的
- 不然技术改造、推动变换 效果可能都不会太好 -- 经验教训
二

Good intentions don't work, mechanisms do. 良好的意愿是没有用的,建立机制才是关键!
- 贝索斯
- COE模版 杜绝出现口号,需要具体措施;
- 一定要培养良好的工程习惯;
- 一定要有自动的机制Mechanism;
- design for failure 模版 1 2 3 详尽的步骤;
务实
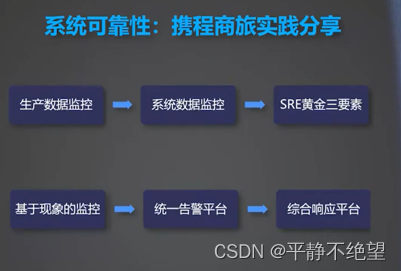
- 生产数据监控--系统数据监控--SRE黄金三要素
- 基于现象的监控--统一告警平台--综合相应平台
- TTD TTR 作为KPI
- 5分钟检测,10分钟恢复 做不到就要严格的复盘
- 控制影响半径--->DC 隔离、同城双活
- 技术展望

![C++ [内存管理]](https://img-blog.csdnimg.cn/img_convert/35edba3b72a0ab22f56bc7f5b0722a85.jpeg)