咱们吃个回头草吧

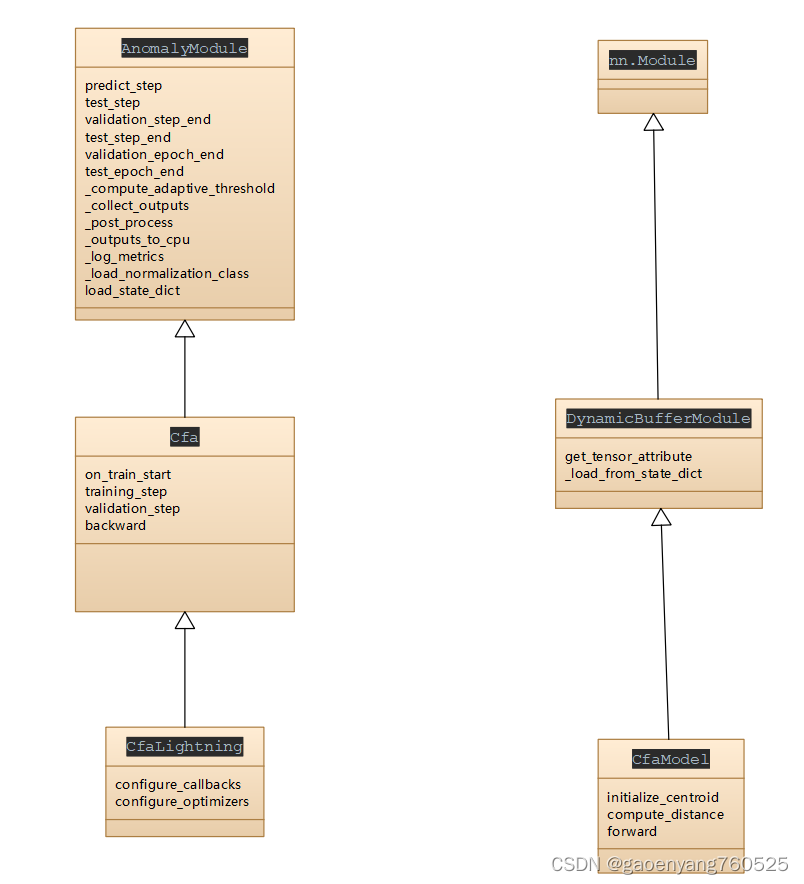
上面的图中,第55行,藏有玄机。前面我们没详细讲。就是这行,指定了,cfa算法,怎么训练的,算法实现细节都在这里。
那我们就得看get_model函数了:
def get_model(config: DictConfig | ListConfig) -> AnomalyModule:"""Load model from the configuration file.Works only when the convention for model naming is followed.The convention for writing model classes is`anomalib.models.<model_name>.lightning_model.<ModelName>Lightning``anomalib.models.stfpm.lightning_model.StfpmLightning`Args:config (DictConfig | ListConfig): Config.yaml loaded using OmegaConfRaises:ValueError: If unsupported model is passedReturns:AnomalyModule: Anomaly Model"""logger.info("Loading the model.")model_list: list[str] = ["cfa","cflow","csflow","dfkde","dfm","draem","fastflow","ganomaly","padim","patchcore","reverse_distillation","rkde","stfpm",]model: AnomalyModuleif config.model.name in model_list:module = import_module(f"anomalib.models.{config.model.name}")model = getattr(module, f"{_snake_to_pascal_case(config.model.name)}Lightning")(config)print("---------------getattr")print(getattr(module, f"{_snake_to_pascal_case(config.model.name)}Lightning"))print("---------------getattr-end")else:raise ValueError(f"Unknown model {config.model.name}!")if "init_weights" in config.keys() and config.init_weights:model.load_state_dict(load(os.path.join(config.project.path, config.init_weights))["state_dict"], strict=False)return model这里面,最关键的是,
一,关于module
module = import_module(f"anomalib.models.{config.model.name}")因为在config.yaml中,已经指定,
anomalib.models.{config.model.name}就是anomalib.models.cfa
那么,本质就是执行的下面的代码
module = import_module(anomalib.models.cfa)记住上面这行代码,重要!
于是,module就是下面这个东西:
<module 'anomalib.models.cfa' from 'D:\\BaiduNetdiskDownload\\anomalib\\anomalib
-main\\src\\anomalib\\models\\cfa\\__init__.py'>
二,关于model
model = getattr(module, f"{_snake_to_pascal_case(config.model.name)}Lightning")(config)其实就是执行,
model=getattr(module,CfaLightning)(config)
换句话说,就是
model=CfaLightning(config)
三、关于训练数据datamodule
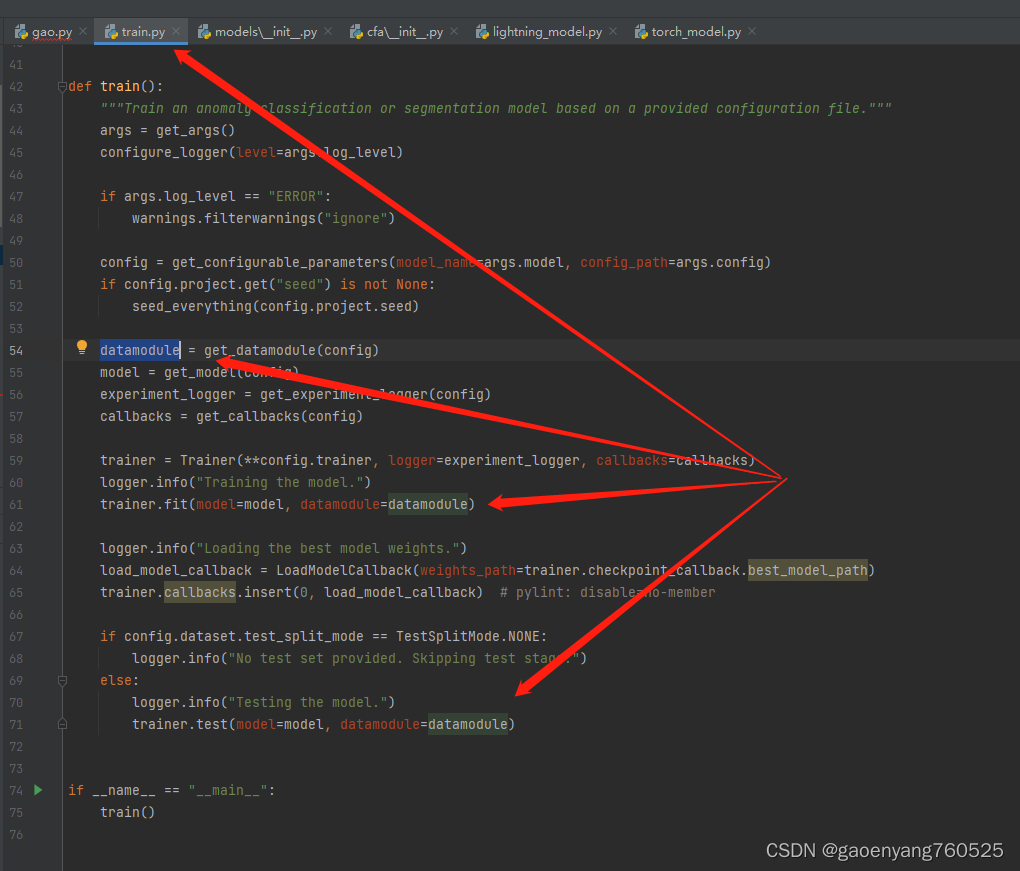
关键是看看那个54行的
datamodule = get_datamodule(config)
def get_datamodule(config: DictConfig | ListConfig) -> AnomalibDataModule:"""Get Anomaly Datamodule.Args:config (DictConfig | ListConfig): Configuration of the anomaly model.Returns:PyTorch Lightning DataModule"""logger.info("Loading the datamodule")datamodule: AnomalibDataModule# convert center crop to tuplecenter_crop = config.dataset.get("center_crop")if center_crop is not None:center_crop = (center_crop[0], center_crop[1])if config.dataset.format.lower() == "mvtec":datamodule = MVTec(root=config.dataset.path,category=config.dataset.category,image_size=(config.dataset.image_size[0], config.dataset.image_size[1]),center_crop=center_crop,normalization=config.dataset.normalization,train_batch_size=config.dataset.train_batch_size,eval_batch_size=config.dataset.eval_batch_size,num_workers=config.dataset.num_workers,task=config.dataset.task,transform_config_train=config.dataset.transform_config.train,transform_config_eval=config.dataset.transform_config.eval,test_split_mode=config.dataset.test_split_mode,test_split_ratio=config.dataset.test_split_ratio,val_split_mode=config.dataset.val_split_mode,val_split_ratio=config.dataset.val_split_ratio,)elif config.dataset.format.lower() == "mvtec_3d":datamodule = MVTec3D(root=config.dataset.path,category=config.dataset.category,image_size=(config.dataset.image_size[0], config.dataset.image_size[1]),。。。。。。。。。。return datamodule
这个datamodule,是什么类型的呢?
AnomalibDataModule类型的!而AnomalibDataModule的父类,是LightningDataModule类型
class AnomalibDataModule(LightningDataModule, ABC):"""Base Anomalib data module.Args:train_batch_size (int): Batch size used by the train dataloader.test_batch_size (int): Batch size used by the val and test dataloaders.num_workers (int): Number of workers used by the train, val and test dataloaders.test_split_mode (Optional[TestSplitMode], optional): Determines how the test split is obtained.Options: [none, from_dir, synthetic]test_split_ratio (float): Fraction of the train images held out for testing.val_split_mode (ValSplitMode): Determines how the validation split is obtained. Options: [none, same_as_test,from_test, synthetic]val_split_ratio (float): Fraction of the train or test images held our for validation.seed (int | None, optional): Seed used during random subset splitting."""def __init__(self,train_batch_size: int,eval_batch_size: int,num_workers: int,val_split_mode: ValSplitMode,val_split_ratio: float,test_split_mode: TestSplitMode | None = None,test_split_ratio: float | None = None,seed: int | None = None,) -> None:super().__init__()self.train_batch_size = train_batch_sizeself.eval_batch_size = eval_batch_sizeself.num_workers = num_workersself.test_split_mode = test_split_modeself.test_split_ratio = test_split_ratioself.val_split_mode = val_split_modeself.val_split_ratio = val_split_ratioself.seed = seedself.train_data: AnomalibDatasetself.val_data: AnomalibDatasetself.test_data: AnomalibDatasetself._samples: DataFrame | None = Nonedef setup(self, stage: str | None = None) -> None:"""Setup train, validation and test data.Args:stage: str | None: Train/Val/Test stages. (Default value = None)"""if not self.is_setup:self._setup(stage)assert self.is_setupdef _setup(self, _stage: str | None = None) -> None:"""Set up the datasets and perform dynamic subset splitting.This method may be overridden in subclass for custom splitting behaviour.Note: The stage argument is not used here. This is because, for a given instance of an AnomalibDataModulesubclass, all three subsets are created at the first call of setup(). This is to accommodate the subsetsplitting behaviour of anomaly tasks, where the validation set is usually extracted from the test set, andthe test set must therefore be created as early as the `fit` stage."""assert self.train_data is not Noneassert self.test_data is not Noneself.train_data.setup()self.test_data.setup()self._create_test_split()self._create_val_split()def _create_test_split(self) -> None:"""Obtain the test set based on the settings in the config."""if self.test_data.has_normal:# split the test data into normal and anomalous so these can be processed separatelynormal_test_data, self.test_data = split_by_label(self.test_data)elif self.test_split_mode != TestSplitMode.NONE:# when the user did not provide any normal images for testing, we sample some from the training set,# except when the user explicitly requested no test splitting.logger.info("No normal test images found. Sampling from training set using a split ratio of %d",self.test_split_ratio,)if self.test_split_ratio is not None:self.train_data, normal_test_data = random_split(self.train_data, self.test_split_ratio, seed=self.seed)if self.test_split_mode == TestSplitMode.FROM_DIR:self.test_data += normal_test_dataelif self.test_split_mode == TestSplitMode.SYNTHETIC:self.test_data = SyntheticAnomalyDataset.from_dataset(normal_test_data)elif self.test_split_mode != TestSplitMode.NONE:raise ValueError(f"Unsupported Test Split Mode: {self.test_split_mode}")def _create_val_split(self) -> None:"""Obtain the validation set based on the settings in the config."""if self.val_split_mode == ValSplitMode.FROM_TEST:# randomly sampled from test setself.test_data, self.val_data = random_split(self.test_data, self.val_split_ratio, label_aware=True, seed=self.seed)elif self.val_split_mode == ValSplitMode.SAME_AS_TEST:# equal to test setself.val_data = self.test_dataelif self.val_split_mode == ValSplitMode.SYNTHETIC:# converted from random training sampleself.train_data, normal_val_data = random_split(self.train_data, self.val_split_ratio, seed=self.seed)self.val_data = SyntheticAnomalyDataset.from_dataset(normal_val_data)elif self.val_split_mode != ValSplitMode.NONE:raise ValueError(f"Unknown validation split mode: {self.val_split_mode}")@propertydef is_setup(self) -> bool:"""Checks if setup() has been called.At least one of [train_data, val_data, test_data] should be setup."""_is_setup: bool = Falsefor data in ("train_data", "val_data", "test_data"):if hasattr(self, data):if getattr(self, data).is_setup:_is_setup = Truereturn _is_setupdef train_dataloader(self) -> TRAIN_DATALOADERS:"""Get train dataloader."""return DataLoader(dataset=self.train_data, shuffle=True, batch_size=self.train_batch_size, num_workers=self.num_workers)def val_dataloader(self) -> EVAL_DATALOADERS:"""Get validation dataloader."""return DataLoader(dataset=self.val_data,shuffle=False,batch_size=self.eval_batch_size,num_workers=self.num_workers,collate_fn=collate_fn,)def test_dataloader(self) -> EVAL_DATALOADERS:"""Get test dataloader."""return DataLoader(dataset=self.test_data,shuffle=False,batch_size=self.eval_batch_size,num_workers=self.num_workers,collate_fn=collate_fn,)