一、有赞数据链路
1、数据链路介绍
首先介绍有赞的数据总体架构图:

自顶向下可以大致划分为应用服务层、数据网关层、应用存储层、数据仓库,并且作业开发、元数据管理等平台为数据计算、任务调度以及数据查询提供了基础能力。
以上对整体架构做了初步的介绍,对于质量把控来说,最核心的两个部分是:数据仓库以及数据应用部分。因为这两部分属于数据链路中的核心环节,相对于其他层级而言,日常改动也更为频繁,出现问题的风险也比较大。
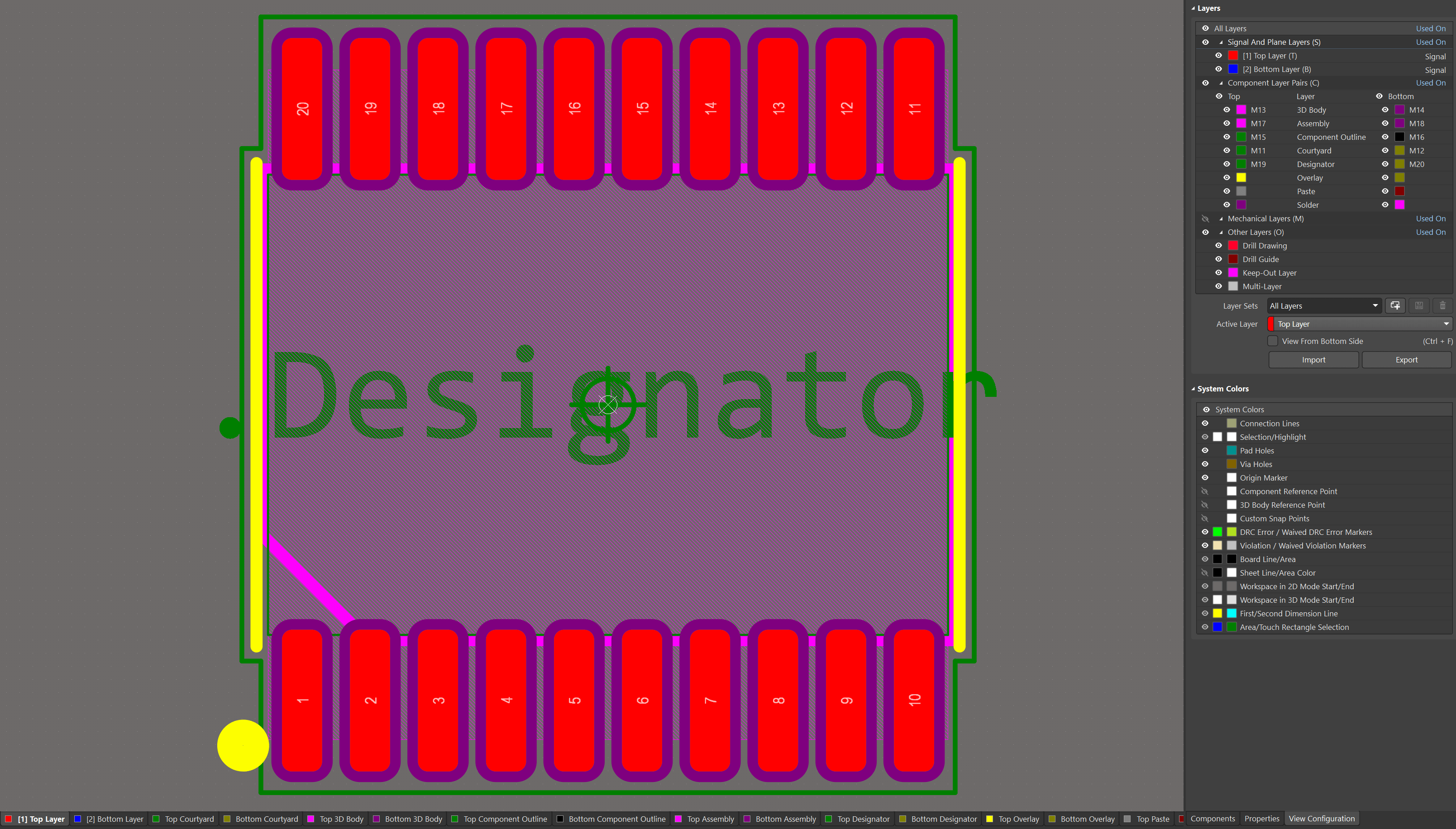
二、数据层测试
1、整体概览
首先,针对数据层的质量保障,可以分成三个方面:数据及时性、完整性、准确性。
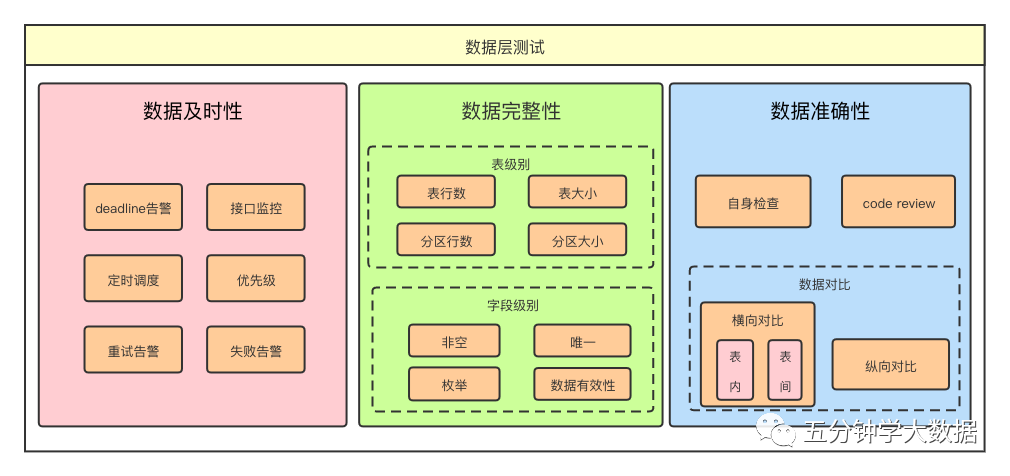
2、 数据及时性
数据及时性,顾名思义就是测试数据需要按时产出。及时性重点关注的三个要素是:定时调度时间、优先级以及数据deadline。其中任务的优先级决定了它获取数据计算资源的多少,影响了任务执行时长。数据deadline则是数据最晚产出时间的统一标准,需要严格遵守。
这三要素中,属于“普世规则”且在质量保障阶段需要重点关注的是:数据deadline。那么我们基于数据deadline,针对及时性的保障策略就可分为两种:
-
监控离线数据任务是否执行结束。这种方式依赖于有赞作业开发平台的监控告警,若数据任务在deadline时间点未执行完成,则会有邮件、企微、电话等告警形式,通知到相应人员。
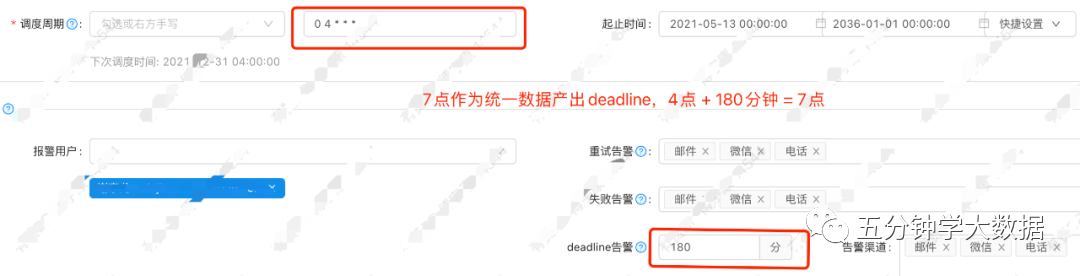
-
检查全表条数或者检查分区条数。这种方式依赖接口自动化平台,通过调用dubbo接口,判断接口返回的数据指标是否为0,监控数据是否产出。
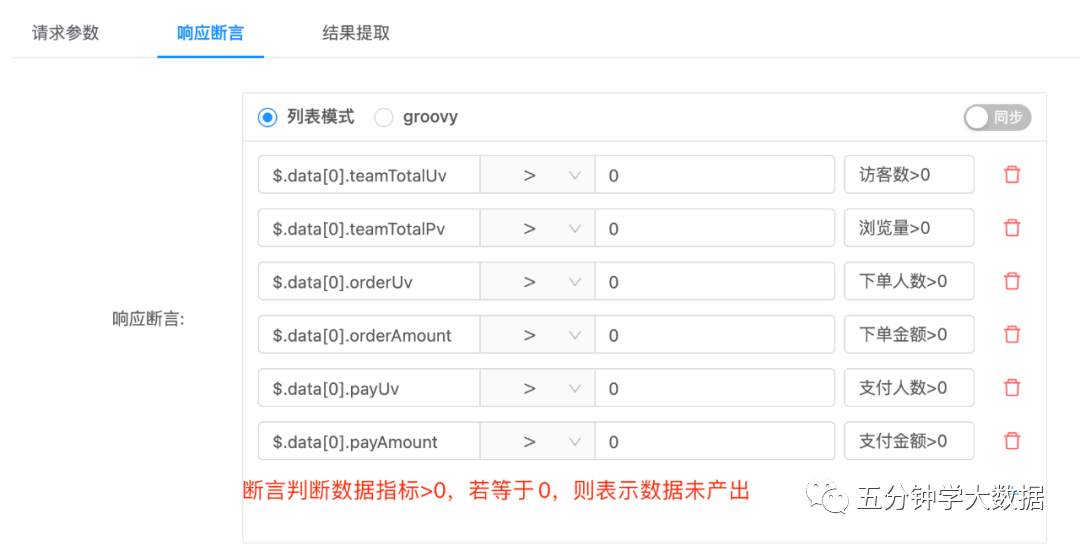
其次我们可以关注失败、重试次数,当任务执行过程中出现多次失败、重试的异常情况,可以抛出告警让相关人员感知。这部分的告警是对deadline告警的补充,目前在有赞作业开发平台上也有功能集成。
3、数据完整性
数据完整性,顾名思义看数据是不是全,重点评估两点:数据不多、数据不少。
-
数据不多:一般是检查全表数据、重要枚举值,看数据有没有多余、重复或者数据主键是否唯一。
-
数据不少:一般是检查全表数据、重要字段(比如主键字段、枚举值、日期等),看字段的数值是否为空、为null等。
可见数据完整性和业务本身关联度没有那么密切,更多的是数仓表的通用内容校验。所以从一些基础维度,我们可以将测试重点拆成表级别、字段级别两个方向。

表级别完整性:
-
全表维度,通过查看全表的总行数/表大小,若出现表总行数/总大小不变或下降,说明表数据可能出现了问题。
-
分区维度,通过查看当日分区表的数据行数/大小,若和之前分区相比差异太大(偏大或偏小),说明表数据可能出现了问题。
目前有赞元数据管理平台已集成相关数据视图:

字段级别完整性:
-
唯一性判断:保证主键或某些字段的唯一性,防止数据重复导致和其他表join之后数据翻倍,导致最终统计数据偏大。
比如判断ods层订单表中的订单号是否唯一,编写sql:
select
count(order_no)
,count(distinct order_no)
from ods.xx_order
若两者相等,则说明order_no值是表内唯一的;否则说明order_no表内不唯一,表数据存在问题。
-
非空判断:保证重要字段非空,防止空数据造成和表join之后数据丢失,导致最终统计数据偏少。
比如判断ods层订单表中的订单号是否出现null,编写sql:
select
count(*)
from ods.xx_order
where order_no is null
若结果等于0,则说明order_no不存在null;若结果大于0,则说明order_no存在null值,表数据存在问题。
-
枚举类型判断:保证枚举字段值都在预期范围之内,防止业务脏数据,导致最终统计结果出现遗漏/多余的数据类型。
比如判断ods层订单表中的shop_type字段中所有枚举值是否符合预期,编写sql:
select shop_type from ods.xx_order group by shop_type
分析查询结果是否满足预期,确保不会出现遗漏/多余的枚举类型。
-
数据有效性判断:判断数据格式是否满足预期,防止字段的数据格式不正确导致数据统计的错误以及缺失。常见的有日期格式
yyyymmdd。
一旦出现数据完整性问题,对数据质量的影响很大。所以完整性策略更适用于ods层,因为我们更期望从源头发现并解决数据不合理问题,及时止损,避免脏数据进入下游之后,数据污染扩大。
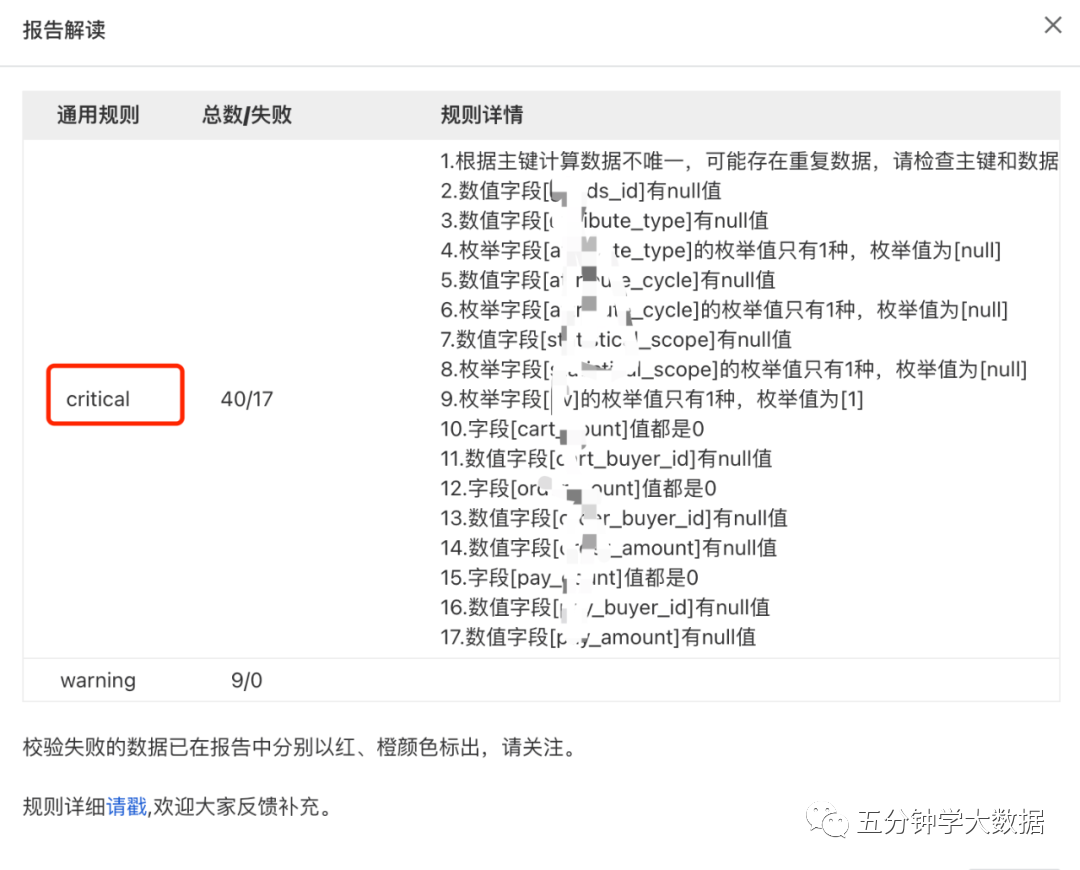
另外,我们看到完整性校验内容逻辑简单,且比较固定,稍微进行简单的抽象就能将其模板化。那么作为测试,我们更倾向于将数据完整性校验做成工具。目前有赞“数据形态工具”已经落地,下面给出我的一些思路:
-
针对所有表来说,普世性的规则,比如表主键的唯一性。
-
针对不同类型比如数值、String、枚举、日期格式类型,列举出常见的数据判断规则。
-
给每项规则进行等级划分,比如表的主键不唯一,记为critical。String类型字段的空值比例大于70%,记为warning。
-
根据表数据是否满足上述这些规则,最终落地一份可视化报告,测试人员可根据报告内容评估数据质量。
4、数据准确性
数据准确性,顾名思义数据要“准确”。“准确”这个概念比较抽象,因为我们很难通过一个强逻辑性的判断,来说明数据有多准,大部分都存在于感性的认知中。所以准确性测试也是在数据质量保障过程中思维相对发散的一个方向。
经过总结,我们可以从字段自身检查、数据横向对比、纵向对比、code review等方面,去把控数据的准确性,这些测试点和业务的关联也比较密切。

4.1 自身检查
数据自身检查,是指在不和其他数据比较的前提下,用自身数据来检查准确的情况,属于最基本的一种检查。常见的自身检查包括:检查数值类指标大于0、比值类指标介于0-1范围。这类基础规则,同数据完整性,也可以结合“数据形态工具”辅助测试。
举个例子,比如针对订单表,支付金额必然是大于等于0,不会出现负数的情况,编写sql:
select
count(pay_price)
from
dw.dws_xx_order
where par = 20211025 and pay_price<0
若结果为0,说明支付金额都是大于0,满足预期;否则若count结果大于0,说明数据存在问题。
4.2 表内横向数据对比
表内横向对比可以理解为同一张表内,业务上相关联的两个或多个字段,他们存在一定的逻辑性关系,那么就可以用来做数据对比。
比如针对订单表,根据实际业务分析易得:针对任何一家店铺的任意一款商品,都满足订单数 >=下单人数,编写sql:
select
kdt_id
,goods_id
,count(order_no)
,count(distinct buyer_id)
from dw.dws_xx_order
where par = '20211025'
group by kdt_id,goods_id
having count(order_no)<count(distinct buyer_id)
若查询结果不存在记录,则说明不存在 订单数<下单人数,反向说明订单数>=下单人数,则符合预期;否则若查询结果的记录大于0,则不符合预期。
4.3 表间横向数据对比
表间横向对比可以理解为两张表或多张表之间,其中具有业务关联或者业务含义一致的字段,可以用来做数据对比:
-
同类型表之间对比:针对hive里的支付表A和支付表B,里面都有支付金额字段,那么同样维度下的 表A.支付金额 = 表B.支付金额。
-
多套存储之间对比:比如有赞数据报表中心针对支付表,应用层存储分别用到了mysql和kylin,用作主备切换,那么相同维度下的kylin-表A.支付金额 = mysql-表B.支付金额。
-
多个系统之间对比:跨系统之间,比如有赞的数据报表中心和crm系统,两个系统都有客户指标数据,那么相同维度下的数据报表中心-表A.客户指标 = crm-表B.客户指标。
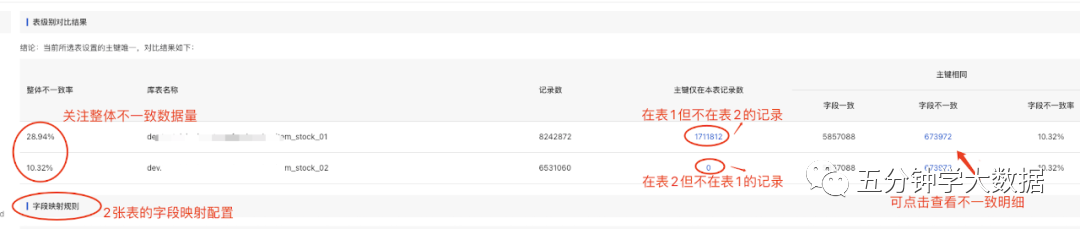
我们深度剖析数据横向对比的底层逻辑,本质就是两张表的不同字段,进行逻辑运算符的比较,也比较容易抽象成工具。目前有赞“数据比对工具”已经落地,下面给出我的一些思路:
-
输入两张表,分别设置两表的主键。
-
输入两张表中需要对比的字段,且设置对比的运算符,比如>、=、<。
-
根据设置的规则,最终数据对比通过、不通过的记录,落地一份可视化报告,测试人员可根据报告内容评估数据质量。
4.4 纵向数据对比
纵向对比就是上下游的数据比较,目的是确保重要字段在上下游的加工过程中没有出现问题。
比如数仓dw层存在订单的明细表,数据产品dm层存在订单数的聚合表,那么二者在相同维度下的数据统计结果,应该保持一致。
4.5 code review
首先,在进行code review之前的需求评审阶段,我们先要明确数据统计的详细口径是什么,下面举两个实际的需求例子。
-
需求1:(错误示例)统计时间内店铺内所有用户的支付金额。问题所在:需求描述太过于简洁,没有阐述清楚数据统计的时间维度以及过滤条件,导致统计口径不清晰,要求产品明确口径。
-
需求2:(正确示例)有赞全网商家域店铺维度的离线支付金额。支持自然日、自然周、自然月。统计时间内,所有付款订单金额之和(剔除抽奖拼团、剔除礼品卡、剔除分销供货订单)。
明确需求之后,下面详细介绍code review的一些常见关注点:
1)关联关系 & 过滤条件
-
关联表使用 outer join 还是 join,要看数据是否需要做过滤。
-
关联关系 on 字句中,左右值类型是否一致。
-
关联关系如果是1:1,那么两张表的关联键是否唯一。如果不唯一,那么关联会产生笛卡尔导致数据膨胀。
-
where 条件是否正确过滤,以上述需求为例子,关注sql中是否正确剔除抽奖拼团、礼品卡和分销供货订单。

2)指标的统计口径处理
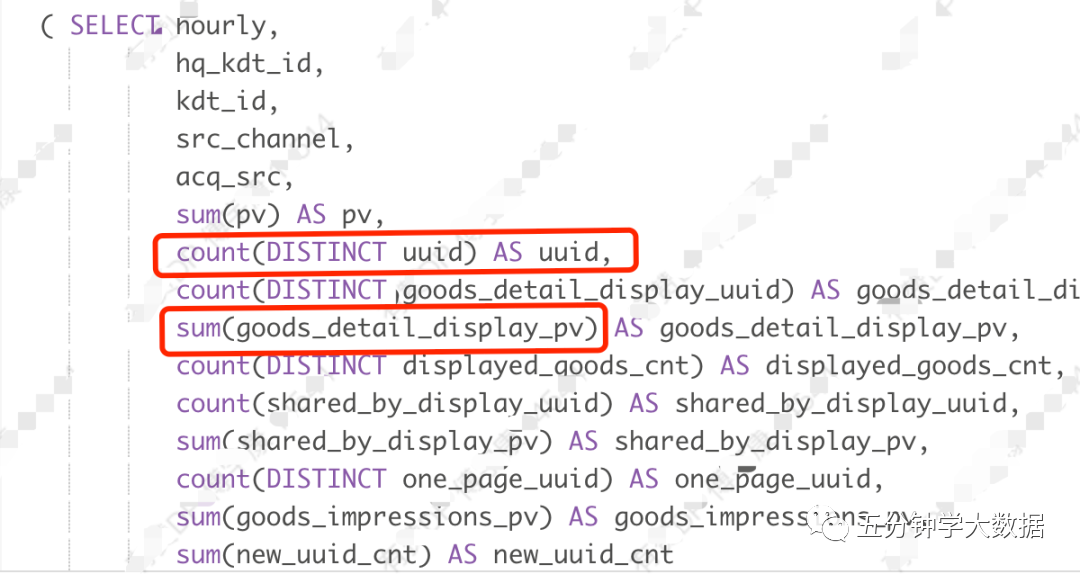
数据指标的统计涉及到两个基本概念:
-
可累加指标:比如支付金额,浏览量等,可以通过简单数值相加来进行统计的指标,针对这类指标,sql中使用的函数一般是sum。
-
不可累加指标:比如访客数,不能通过简单相加,而是需要先去重再求和的方式进行统计,针对这类指标,sql中一般使用count(distinct )。
3)insert插入数据
-
是否支持重跑。等价于看插入时是否有overwrite关键字,如果没有该关键字,重跑数据(多次执行该工作流)时不会覆盖脏数据,而是增量往表插入数据,进而可能会导致最终数据统计翻倍。
-
插入的数据顺序和被插入表结构顺序是否完全一致。我们要保证数据字段写入顺序没有出错,否则会导致插入值错乱。

三、应用层测试
1、整体概览

基本的前端页面 + 服务端接口测试,和一般业务测试关注点是一致的,不再赘述。本篇重点展开“数据应用“测试需要额外关注的地方。
2、 降级策略
-
在页面新增数据表的时候,需求、技术评审阶段确认是否需要支持“蓝条”的功能,属于“测试左移”。
蓝条介绍:有赞告知商家离线数据尚未产出的页面顶部蓝条,其中的“产出时间” = 当前访问时间 +2小时,动态计算得到。

-
测试比率类指标时,关注被除数 = 0 的特殊场景。在后端code review、测试页面功能阶段,关注该点。目前有赞针对这种情况,前端统一展示的是“-”。

3、 主备策略
遇到有主备切换策略时,测试过程中注意数据正常双写,且通过配置,取数时能在主备数据源之间切换。

4、 数据安全
关注数据查询的权限管控,重点测试横向越权、纵向越权的场景。
四、后续规划
目前在实际项目的数据准确性对比中,数据对比工具因为暂不支持sql函数,所以只能代替50%的手工测试,一些复杂的横向和纵向数据对比还是需要编写sql。后续计划支持sum、count、max、min等sql函数,把工具覆盖范围提升到75%以上,大大降低数据对比的成本。
目前“数据形态报告”、“数据对比工具”更多的运用项目测试当中,后续计划将形态检查和数据对比做成线上巡检,将自动化和数据工具相结合,持续保障数仓表的质量。
目前针对sql code review的方式主要靠人工,我们计划把一些基础的sql检查,比如insert into检查,join on条件的唯一性检查、字段插入顺序检查等作成sql静态扫描,整合到大数据测试服务中,并且赋能给其他业务线。