线程与进程
为了实现多个任务并发执行的效果,人们引进了进程。
何谓进程?
我们电脑上跑起来的每个程序都是进程。
每一个进程启动,系统会为其分配内存空间以及在文件描述符表上有所记录等。进程是操作系统进行资源分配的最小单位,这意味着各个进程互相之间是无法感受到对方存 在的,这就是操作系统抽象出进程这一概念的初衷,这样便使得进程之间互相具备”隔离性 (Isolation)“。
然而,进程存在很大的问题,那就是频繁的创建或销毁进程,时间成本与空间成本都会比较高。于是,人们又引进了更加轻量级的线程。
进程包含线程:一个进程里可以有一个线程,或是多个线程,这些线程共用同一份资源。每个线程都是一个独立的执行流,多个线程之间也是并发的。当然了,多个线程可以是在多个CPU核心上并发运行,也可以在同一个CPU核心上,通过快速的交替调度,"看起来"是同时运行的。
基于此,创建线程比创建进程快,销毁线程比销毁进程快以及调用线程比调用进程快。
虽然线程比进程更加轻量级,但不是说多线程就能完全替代多线程,相反,多线程与多进程在电脑中是同时存在的。
系统中自带的任务管理器看不到线程,只能看到进程级别的,需要使用其他第三方工具才能看到 线程,比如winDbg。
线程的创建
class MyThread extends Thread {@Overridepublic void run() {while (true) {System.out.println("hello t");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}public class ThreadDemo1 {public static void main(String[] args) {Thread t = new MyThread();// start 会创建新的线程t.start();// run 不会创建新的线程. run 是在 main 线程中执行的~~// t.run();while (true) {System.out.println("hello main");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}输出:
hello main
hello t
hello t
hello main
hello main
hello t
hello main
.......
启动一个线程
之前我们已经看到了如何通过覆写 run 方法创建一个线程对象,但线程对象被创建出来并不意味着线程 就开始运行了。还需要调用start方法,而这才真的在操作系统的底层创建出一个线程。
所以真正启动一个线程之前有三步:
1. main方法是主线程,在主线程中创建线程对象。
2. 覆写run方法,覆写 run 方法是提供给线程要做的事情的指令清单。
3. 调用start方法,线程开始独立执行。系统会在这里调用run方法,而不是靠程序员去调用!
为了加深同学们的理解,我对上述情况做了个类比:张三是项目的负责人(主线程),但要干的活太多了,他一个人忙不过来,所以他又叫了王五过来帮忙(创建线程对象),并给他讲解具体要做什么事情(覆写run方法),最后随着张三一声令下“大家开干吧!”,所有人都开始干活了(调用start方法)。
4. 中断一个线程
王五一旦进到工作状态,他就会按照老板的指示去进行工作,不完成是不会结束的。但有时我们 需要增加一些机制,例如老板突然来电话了,说转账的对方是个骗子,需要赶紧停止转账,那张三该如 何通知王五停止呢?这就涉及到线程中断的方式了。
中断一个线程,就是让一个线程停下来,或是说,让线程终止。对程序来说,那就是让run方法执行完毕。
目前常见的有以下两种方式:
1. 给线程设定一个结束标志位
2. 调用 interrupt() 方法来通知
4.1 使用自定义的变量来作为标志位
public class ThreadDemo1 {public static boolean isQuit = false;public static void main(String[] args) {Thread t = new Thread(() -> {while(!isQuit){//currentThread 是获取到当前线程实例.//此处的线程实例是 tSystem.out.println(Thread.currentThread().getName() + "给某客户转账中");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println(Thread.currentThread().getName() + "立马停止转账,并长吁一口气,\"好险好险\"");},"王五");t.start();try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}//此处的线程实例是 main System.out.println(Thread.currentThread().getName()+" 说 \"坏了,遇到骗子了,叫王五停止转转!\"");isQuit = true;}
}
这里问一个问题,我们可不可以把isQuit变量写到main函数里面?答案是不可以的。因为lambda表达式访问外面的局部变量时,使用的是变量捕获,其语法规定,捕获的变量必须是final修饰的,或者是一个"实际final",即该变量并没有用final修饰,但在实际过程中,变量没有修改。而我们看到,为了让run方法终止,isQuit的确修改了,那么这就会报错!
4.2 使用 Thread.interrupted() 或者 Thread.currentThread().isInterrupted() 代替自定义标志位
Thread类中,内置了一个标志位,通过调用interrupt方法实现:
方法 | 功能 |
public void interrupt() | 设置标志位为true;如果该线程正在阻塞中,如执行sleep,则会通过抛异常的方式让sleep立即结束 |
Thread 内部还包含了一个 boolean 类型的变量作为线程是否被中断的标记。
方法 | 功能 |
public static boolean interrupted() | 判断当前线程的中断标志位是否设置,调用后清除标志位 |
public static boolean isInterrupted() | 判断当前线程的中断标志位是否设置,调用后不清除标志位 |
在这里,同学们不免有个疑问,interrupted调用后清除标志位,与isInterrupted调用后不清除标志位有什么区别呢?下面给出两个对比例子:
public class ThreadDemo2 {public static void main(String[] args) {Thread t = new Thread(()->{for(int i = 0; i < 3; i++){System.out.println(Thread.interrupted());}});t.start();//把 t 内部的标志位给设置成 truet.interrupt();}
}输出:
true
false
false
除了第一个是true之外,其余的都是false,因为标志位被清除了。
public class ThreadDemo3 {public static void main(String[] args) {Thread t = new Thread(()->{for(int i = 0; i < 3; i++){System.out.println(Thread.currentThread().isInterrupted());}});t.start();t.interrupt();}
}输出:
true
true
true
全是true,因为标志位没有被清除!
但是!!如果interrupt与isInterrupted遇到了像sleep这样的会让线程阻塞的方法,会发生什么??
public class ThreadDemo3 {public static void main(String[] args) {Thread t = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println(Thread.currentThread().getName()+"给某位客人转账中...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println(Thread.currentThread().getName()+"停止交易!");},"王五");t.start();try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName()+"说:\"通知王五,对方是骗子\"");t.interrupt();}
}按照前面的讲解,同学们一定会很自然的觉得,肯定能打印"停止交易"这句话,但实际运行结果,大部分情况是下面这样子的:
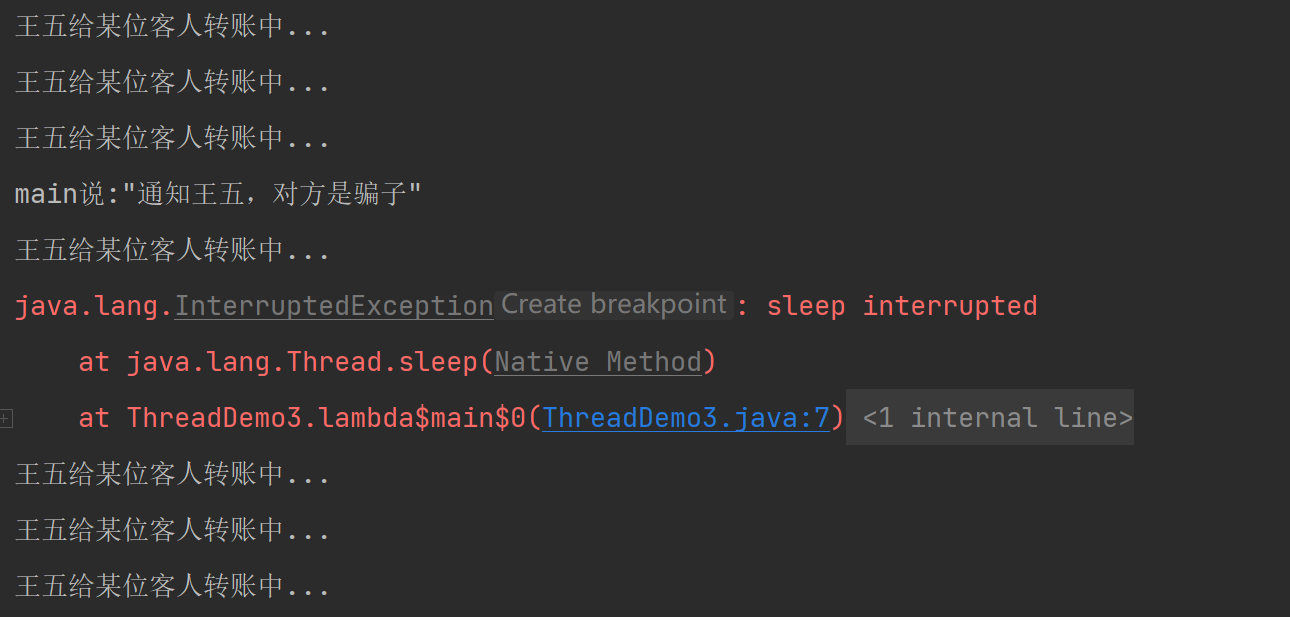
要知道多线程的代码执行顺序,并不是以往熟知的从上到下,而是并发的。上述代码中,自t.start()之后,便兵分两路,线程与主线程交替执行。当执行到t.interrupt()时,设置标志位为true。这里又会遇到两种情况,一是此时的线程t刚好来到while的判断语句,因为是取反,此时为false,跳出循环,打印"王五停止交易",线程t结束,并且由于主线程后面没有代码,主线程也结束。

但发生这种情况的概率十分低,因为执行sleep占据了大部分时间,所以大部分的情况是线程t已经进入到while当中了。那么sleep执行过程中,遇到标志位为true,它又会干两件事:一是立刻抛出异常。二是自动把isInterrupted的标志位给清空(true->flase)——这就导致while死循环了。当然了,如果执行sleep时,标志位为flase,它就继续执行,什么也不会做。
上述的情况是执行t.interrupt()之后,t线程大部分情况下,依旧在跑。下面再看其他的情况:
执行t.interrupt()之后,t线程立马结束:
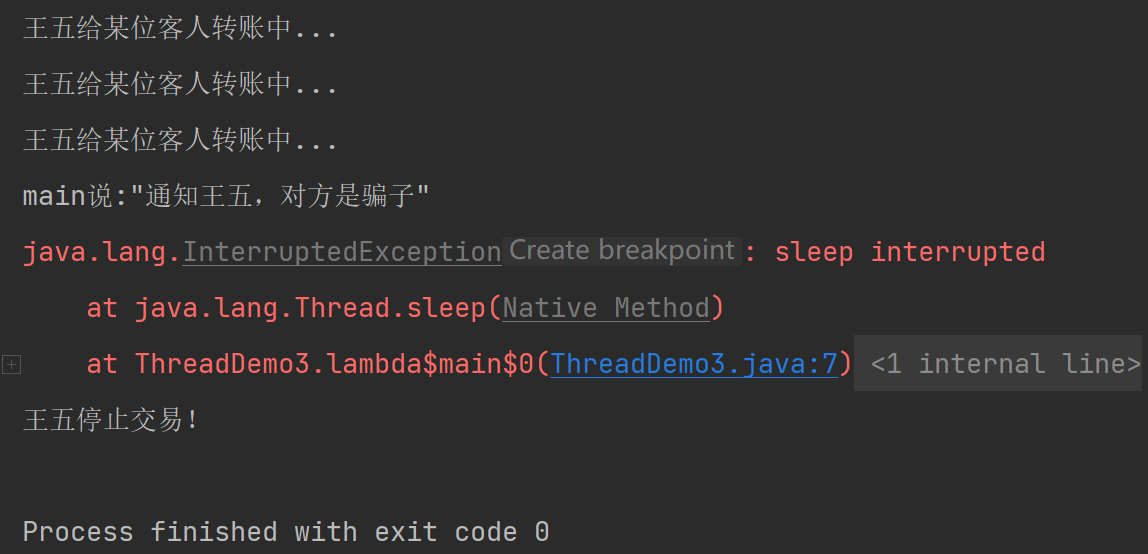
public class ThreadDemo3 {public static void main(String[] args) {Thread t = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println(Thread.currentThread().getName()+"给某位客人转账中...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();break;}}System.out.println(Thread.currentThread().getName()+"停止交易!");},"王五");t.start();try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName()+"说:\"通知王五,对方是骗子\"");t.interrupt();}
}
执行t.interrupt()之后,t线程等一会再结束:
public class ThreadDemo3 {public static void main(String[] args) {Thread t = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println(Thread.currentThread().getName()+"给某位客人转账中...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();try {Thread.sleep(10000);} catch (InterruptedException ex) {ex.printStackTrace();}break;}}System.out.println(Thread.currentThread().getName()+"停止交易!");},"王五");t.start();try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName()+"说:\"通知王五,对方是骗子\"");t.interrupt();}
}
到这里,同学们应该可以发现,t.interrupt()更像是个通知,而不是个命令。interrupt的效果,不是让t线程马上结束,而是给它结束的通知,至于是否结束、立即结束还是等会结束,都有赖于代码是如何写的。
5. 等待一个线程
线程之间是并发的,操作系统对于线程的调度,是随机的,因此无法判断两个线程谁先结束,谁后结束。
有时,我们需要等待一个线程结束之后,再启动另一个线程,那么这时,我们就需要一个方法明确等待线程的结束——join()。
public class ThreadDemo4 {public static void main(String[] args) throws InterruptedException{Thread t = new Thread(() ->{for(int i = 0; i < 6; i++){System.out.println("hello t");}});t.start();t.join();System.out.println("hello main!!");}
}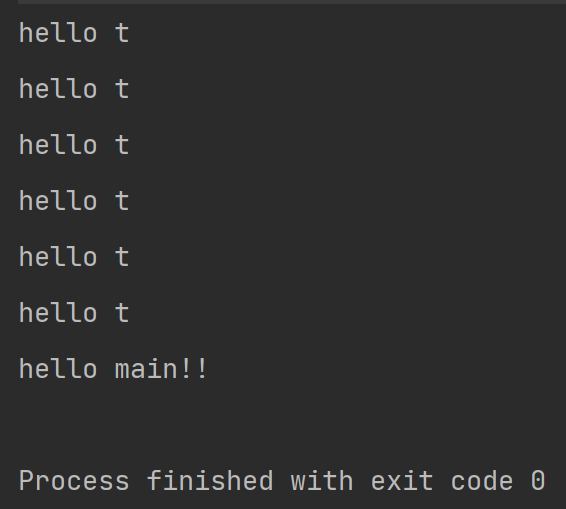
上述过程可以描述为:执行t.join()的时候,线程t还没有完成,main只能等t结束了才能往下执行,此时main发生阻塞,不再参与cpu的调度,此时只有线程t在运行。
而如果是下面这种情况呢?
public class ThreadDemo4 {public static void main(String[] args) throws InterruptedException{Thread t = new Thread(() ->{for(int i = 0; i < 6; i++){System.out.println("hello t");}});t.start();Thread.sleep(3000);t.join();System.out.println("hello main!!");}
}上述代码中,在t.start() 和 t.join() 之间加了个sleep,这就意味着执行 t.join() 时,线程t已经结束了,那么此时main线程无需再多花时间等待,直接就可以往下执行!!
那如果线程t完成的时间很长,难道只能一直“死等”下去吗?
其实不是,join还有另外的重载方法,是有参数的,可以指定最大等待时间,如果超过了,main线程就不等了,直接往下执行。
public class ThreadDemo4 {public static void main(String[] args) throws InterruptedException{Thread t = new Thread(() ->{for(int i = 0; i < 1000; i++){System.out.println("hello t");}});t.start();t.join(1);//等待t线程执行1毫秒System.out.println("hello main!!");System.out.println("hello main!!");System.out.println("hello main!!");}
}输出:
......
......
......
hello t
hello t
hello t
hello t
hello main!!
hello main!!
hello main!!
hello t
hello t
hello t
hello t
......
......
......
6. 线程的状态
public class ThreadDemo5 {public static void main(String[] args) throws InterruptedException{Thread t = new Thread(() -> {while(true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});System.out.println(t.getState());t.start();System.out.println(t.getState());}
}输出:
NEW
RUNNABLE
public class ThreadDemo5 {public static void main(String[] args) throws InterruptedException{Thread t = new Thread(() -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});t.start();Thread.sleep(2000);System.out.println(t.getState());}
}输出:
TERMINATED
系统中,线程已经执行完毕,但t还在。
了解线程的状态,有利于后序对多线程代码进行调试。
7. 线程的安全
导致线程不安全的原因有以下几点:
1. 线程的调度是抢占式执行的
2. 多个线程修改同一个变量,对比另外三种线程安全的情况:一个线程修改同一个变量;多个线程分别修改不同的变量;多个线程读取同一个变量。
3. 修改操作不是原子性的,即某个操作对应单个cpu指令的,就是原子性。
4. 内存的可见性引起的线程不安全
5. 指令重排序引起的线程不安全
7.1 修改操作不是原子性的导致线程的不安全
由于线程之间的调度顺序是不确定的,某些代码在多线程环境下运行,可能会出现bug。比如下面这段代码,两个线程针对同一个变量自增5w次。
class Counter{private int count = 0;public void add(){count++;}public int get(){return count;}
}public class ThreadDemo1 {public static void main(String[] args) throws InterruptedException{Counter counter = new Counter();Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});Thread t2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {counter.add();}});t1.start();t2.start();t1.join();t2.join();System.out.println(counter.get());}
}同学们猜一猜,输出结果是什么?大家肯定都是一拍脑门,脱口而出一个答案,那就是100000!
但实际情况是,每次输出都是一个不一样的数字:86186、75384、100000、99839......
这里其实就是发生了线程不安全问题。
count++操作,由三个cpu指令构成:
load:把内存中的数据读取到cpu中的寄存器中;
add:把寄存器中的值进行+1计算;
save:把寄存器中的值写会内存中。
由于多线程的调度顺序是不确定的,实际执行过程中,两个线程的+1操作的实际指令顺序就有多种可能!!下面画图示意:

实际情况是各种可能都会出现,比如会出现一个线程多次执行、一个线程count++的操作只执行了部分,又执行另一个线程,就是因为顺序执行与交错执行随机出现,导致最后自增次数不一定是100000。


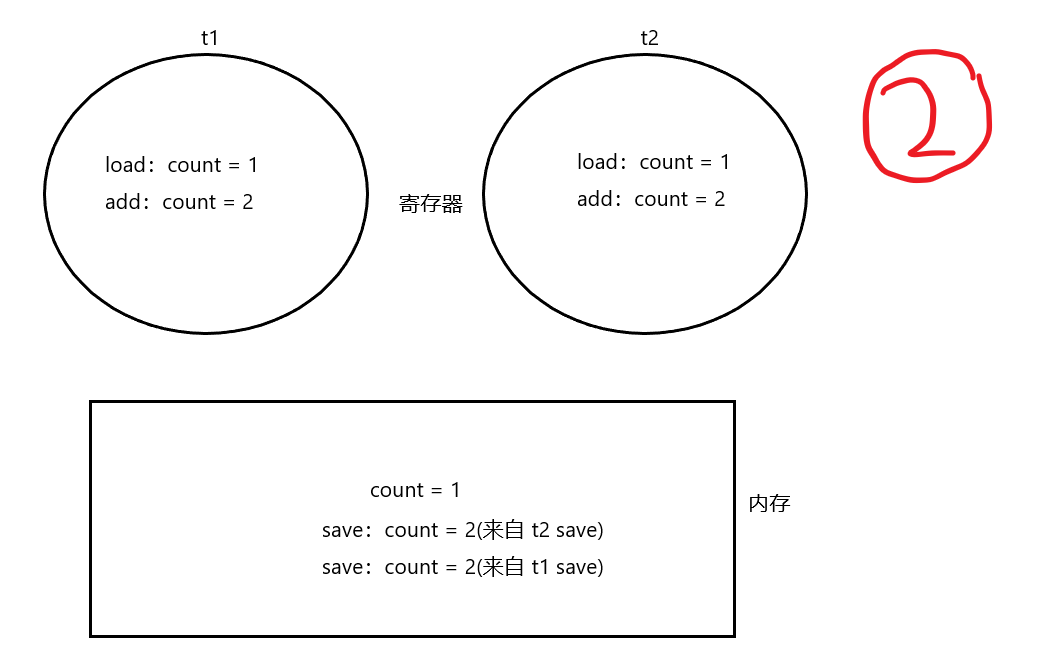
在这里可以发现,t1和t2对count分别自增一次,但由于调度的无序性,使得自增的操作交叉了,最后内存上的count为2,也就是本应自增两次的,变成了一次。
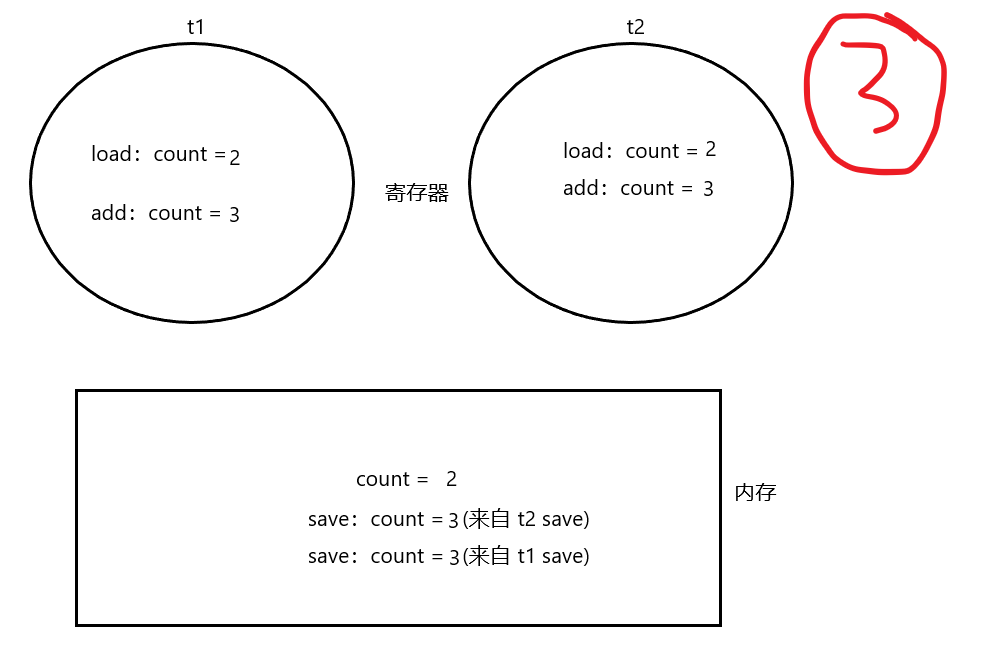
甚至还可能出现t1 load了之后,t2执行多次,最后t1再add跟save,那么t2自增那么多次的结果就会让t1自增一次的结果给覆盖!
这就是修改操作非原子性导致的线程不安全问题。那我们应该如何解决这样的问题呢?
答案就是加锁,通过加锁的方式,让count++这一操作变成原子性的。
如果两个线程针对同一个对象进行加锁,就会出现"锁竞争",一个线程抢占式执行抢到了锁之后,另一个线程如果也执行到同一个地方,它不能立马加锁,得阻塞等待那个抢到锁的线程放锁之后,才能成功加锁。如果两个线程针对不同对象进行加锁,就不会出现"锁竞争",各自获取各自的锁即可。
下面介绍加锁的方式:
一. 直接在定义方法时使用 synchronized 关键字,相当于以this为锁对象
class Counter{private static int count = 0;synchronized public void add(){count++;}public int get(){return count;}
}class Counter{private static int count = 0;public void add(){synchronized (this){count++;}}public int get(){return count;}
}锁有两个核心操作,加锁和解锁。上面的代码块表示,进入synchronized修饰的代码块时,会加锁,而出了synchronized代码块时,会解锁。this是针对具体哪个对象加锁。
二. synchronized修饰静态方法,相当于给类对象加锁
class Counter{private static int count = 0;synchronized public static void add(){count++;}public static int get(){return count;}
}
public class ThreadDemo1 {public static void main(String[] args) throws InterruptedException{Thread t1 = new Thread(() ->{for (int i = 0; i < 50000; i++) {Counter.add();}});Thread t2 = new Thread(() ->{for (int i = 0; i < 50000; i++) {Counter.add();}});t1.start();t2.start();t1.join();t2.join();System.out.println(Counter.get());}
}等同于以下方式:
class Counter{private static int count = 0;public static void add(){synchronized (Counter.class){count++;}}public static int get(){return count;}
}三. 更常见的是手动指定一个锁对象
class Counter{private static int count = 0;private Object locker = new Object();public void add(){synchronized (locker){count++;}}public int get(){return count;}
}
此时就能保证,t2的load是在t1的save之后的。这样一来,计算结果就能保证是线程安全的了。加锁,本质上就是让并发的变成串行的。
这里又有同学要问了,那加锁跟join有什么区别吗?
还是有很大区别的。join是让两个线程完整的串行,而加锁,只是让两个线程的某个一小部分串行,而其他依旧是并发的。这样就能在保证线程安全的情况下,让代码跑的更快一些,更好的利用多核cpu。
总而言之,加锁可能导致阻塞,这对程序的效率势必会造成影响。加了锁的,肯定比不加锁的慢,但又比join的完整串行要快,更重要的是,加了锁的一定比不加锁的算出来的结果更准确!
7.2 内存的可见性引起的线程不安全
可见性: 一个线程对共享变量值的修改,能够及时地被其他线程看到.
为了引出这一情况,我们先来看以下的代码:
import java.util.*;
public class ThreadDemo2 {public static int flag = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while(flag == 0){}System.out.println("t1 循环结束");});Thread t2 = new Thread(() -> {Scanner sc = new Scanner(System.in);System.out.println("请输入一个整数:");flag = sc.nextInt();});t1.start();t2.start();}
}对于上述代码,预期情况如下:t1通过flag==0作为条件进入循环,t2通过控制台输入一个整数,只要这个整数非0,t1的循环就会结束,此时t1的线程也就结束。
但是当我们去运行这段代码时,发现输入非0整数之后,t1线程并没有结束!!打开jconsole发现t1线程还在运行!
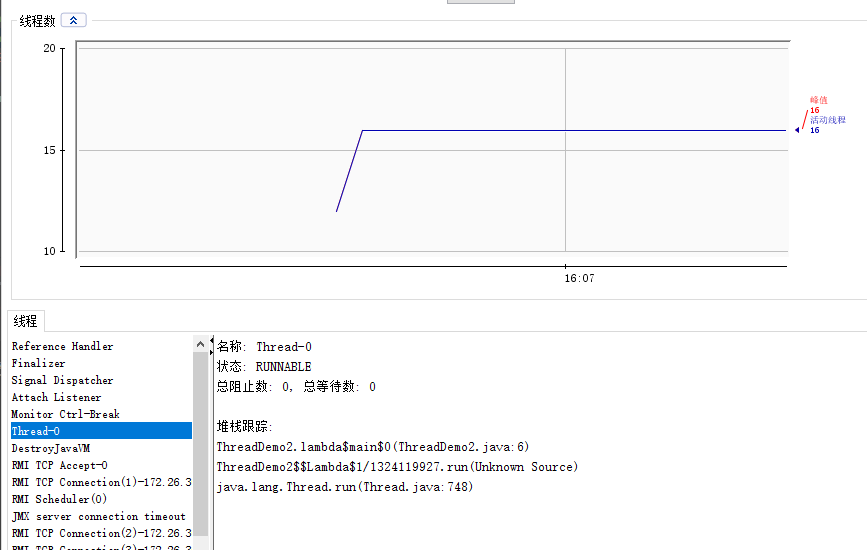
为什么会有这样的问题呢!!且看以下分析:
while的条件语句,flag==0,此处可拆分成两道cpu指令:
load:从内存中读取数据到cpu寄存器
cmp:比较寄存器的值是否为0
已知,读取内存数据的速度比读取硬盘数据要快,然而读取寄存器上的数据又比读取内存上的数据要快,即: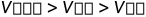 。因此load的时间开销就远远的高于cmp。
。因此load的时间开销就远远的高于cmp。
如果编译器需要快速的load,并且每次load的结果都一样,这对编译器来说是个负担。于是编译器就做了一个非常大胆的操作,把load给优化掉了,也就是说只有第一次执行load才真正的从内存读取了flag = 0,后续循环都只cmp,而不再执行load,相当于复用首次放于寄存器中的flag值。
编译器优化:就是能够智能的调整程序员的代码执行逻辑,保证程序结果不变的前提下,通过加减语句或是语句变换等一系列操作,让整个程序执行的效率大大提升!
在单线程环境下,编译器对于优化之后,程序结果不变的判断是非常准确的!但是多线程环境就不一定了!会出现调整之后,效率提高了,但是结果变了。
当预期结果跟实际结果不符时,就是出现bug了。
所以到这里,就可以解释清楚什么是内存可见性出现问题,也就是在多线程环境下,编译器对于代码优化产生了误判,从而引起bug。
那么该如何解决这个问题呢?只要让编译器停止对这个场景优化即可——使用volat关键字!
被volatile修饰的变量,编译器会禁止上述优化,能保证每次都是从内存中重新读取数据。
使用volatile修饰flag:
volatile public static int flag = 0;
当我们把上述代码修改成以下代码时,t1线程也能结束
public class ThreadDemo2 {public static int flag = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while(flag == 0){try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t1 循环结束啦啦啦");});Thread t2 = new Thread(() -> {Scanner sc = new Scanner(System.in);System.out.println("请输入一个整数:");flag = sc.nextInt();});t1.start();t2.start();}
}加了sleep,循环执行速度就慢下来了,此时load操作就不再是负担了,编译器就没必要优化了。
7.3 指令重排序引起的线程不安全
volatile还有另外的一个作用——禁止指令重排序。
指令重排序:也是编译器优化的策略,在保证整体逻辑不变的情况下,其调整了代码的执行顺序,让程序更高效。
写一个伪代码:
class Student{
......
}
public class Test{
Student s = null;
t1:
s = new Student();
t2:
if(s != null){
s.learn();
}
}
new 一个Student的对象,大体可以分为三步操作:1. 申请内存空间 2. 调用构造方法(初始化内存数据)3. 把对象的引用赋值给s(内存地址的赋值)
上述代码就可能会因为指令重排序出现问题:
假设t1按照 1 3 2 的顺序执行。如果t1执行完1 3 之后,t2就开始执行了,此时s这个引用就非空了,当t2调用s.learn()时,由于s指向的内存还未初始化,很有可能这里就会产生bug!!
因此解决方法要么是加锁,要么就使用volatile修饰!
8. wait 和 notify
实际开发中,有时我们会希望合理协调多个线程之间的执行先后顺序。
wait会做的事:
释放当前锁
让当前执行代码的线程阻塞等待
满足一定条件被唤醒时,重新尝试获取锁
由此可知,wait要搭配synchronized来使用,否则没有锁,后面又如何释放锁?单独使用wait,编译器会直接抛出异常!
notify会做的事:
只有一个单线程处于wait状态下,notify会将其唤醒,并使其重新获取该对象的对象锁
如果有多个线程等待,cpu调度会随机选一个处于wait状态下的线程唤醒
notify也是与synchronized搭配使用,调用notify方法后,当前线程并不会立马释放锁,要等到执行notify方法的线程全部执行完了之后,才会释放对象锁!
另外,wait和notify都是Object的方法,只要是个类对象,不是基本数据类型,都可以调用wait和notify。
public class ThreadDemo1 {public static void main(String[] args) throws InterruptedException{Object locker = new Object();Thread t1 = new Thread(() -> {try {System.out.println("wait 开始");synchronized (locker) {locker.wait();System.out.println("wait 再次加锁了~~~~~");}System.out.println("wait 结束");} catch (InterruptedException e) {e.printStackTrace();}});t1.start();Thread.sleep(1000);Thread t2 = new Thread(() -> {synchronized (locker){System.out.println("notify 开始");locker.notify();System.out.println("notify 结束");}});t2.start();}
}输出:
wait 开始
notify 开始
notify 结束
wait 再次加锁了~~~~~
wait 结束
与notify有一样唤醒功能的,还有一个notifyAll。使用notifyAll方法,可以一次唤醒所有等待线程。此时所有被唤醒的线程又要开始新一轮的竞争锁!
9. 多线程案例
9.1 单例模式
啥是设计模式?
设计模式好比象棋中的 "棋谱"。软件开发中也有很多常见的 "问题场景". 针对这些问题场景, 大佬们总结出了一些固定的套路。按照 这个套路来实现代码, 也不会吃亏。
单例模式是校招中最常考的设计模式之一。单例模式能保证某个类在程序中只存在唯一一份实例, 而不会创建出多个实例。单例模式具体的实现方式, 分成 "饿汉" 和 "懒汉" 两种。
对于这两种模式,举一个这样的例子,打开硬盘上的文件,读取文件内容并显示出来。
饿汉:把文件所有内容都读到内存中,并显示
懒汉:只读取把当前屏幕填充满的一小部分文件。如果用户要翻页,那就再读取剩下内容,如果用户不继续看,直接就省下了。
试想一下,如果这个文件非常的大,100g。饿汉模式的打开文件就要费半天,但懒汉却一下子就打开了。
下面给出单线程环境下,java实现单例模式的代码:
//饿汉模式——单线程
class Singleton{//唯一的一个实例private static Singleton instance = new Singleton();//获取实例的方法public static Singleton getInstance(){return instance;}//禁止外部 new 实例private Singleton(){}
}
public class ThreadDemo2 {public static void main(String[] args) {Singleton s1 = Singleton.getInstance();Singleton s2= Singleton.getInstance();System.out.println(s1 == s2);}
}在类内部把实例创建好,同时禁止外部创建实例,这样就可以保证单例的特性了。上述s1和s2指向同一个对象。
而懒汉模式实现单例,其核心思想是非必要不创建,那么就能先写出以下代码:
//懒汉模式————实现单例模式
//单线程环境:
class SingletonLazy{private static SingletonLazy instance = null;public static SingletonLazy getInstance(){if(instance == null){instance = new SingletonLazy();}return instance;}private SingletonLazy(){}
}
这里提出一个问题:上述两个代码是否线程安全??在多线程环境下调用getInstance是否会出问题??
对于饿汉模式,线程是安全的,因为程序是指单纯的 读 操作,没有修改。但是对于懒汉模式,多线程下,根本无法保证创建对象的唯一性!!如果对象管理的内存数据太大了,比如100g,n个线程,那就得加载100 * n G到内存中,那影响可就大了。
怎么解决这个问题呢?根据前面所学,答案就是加锁了!
//懒汉模式————实现单例模式
//多线程环境:
class SingletonLazy{private static SingletonLazy instance = null;public static SingletonLazy getInstance(){synchronized (SingletonLazy.class){if(instance == null){instance = new SingletonLazy();}}return instance;}private SingletonLazy(){}
}把锁加在能使 判定 与new一个对象是原子性的。
但如此一来,每一个调用getInstance的线程都得锁竞争,这样会让程序效率变得极为低下。
其实前面所说的线程不安全,只出现在首次创建对象时。一旦对象创建好了,后续调用getInstance就只是单纯的 读 操作!也就没有线程安全问题了,就没必要再加锁了!所以最好在进入锁之前,再来一次判断!
//懒汉模式————实现单例模式
//多线程环境:
class SingletonLazy{private static SingletonLazy instance = null;public static SingletonLazy getInstance(){// 这个条件, 判定是否要加锁. 如果对象已经有了, 就不必加锁了, 此时本身就是线程安全的.if(instance == null){synchronized (SingletonLazy.class){if(instance == null){instance = new SingletonLazy();}}}return instance;}private SingletonLazy(){}
}懒汉模式的代码修改到这,就完美无暇了吗?
NoNoNo!
上述代码还可能会发生一个极端的小概率情况——指令重排序!!
要知道new一个对象,其实是三步cpu指令:
申请内存空间
调用构造方法,初始化变量
引用指向内存地址
如果两个线程同时调用getInstance方法,t1线程发生指令重排序,执行了1和3之后,系统调度给了t2,来到判定条件,发现instance非空,此时条件不成立,直接返回实例的引用。如果t2继续调用,而instance所指向的内存空间并未初始化,那就会产生其他问题了!
所以,为了保险起见,杜绝指令重排序的情况发生,最好给instance加上volatile!
volatile private static SingletonLazy instance = null;9.2 阻塞队列
阻塞队列是一种特殊的队列,也遵循“先进先出”的原则。
阻塞队列也是一种线程安全的数据结构,具有以下特性:
当队列为满的时候,继续入队列的操作就会阻塞等待,直到其他线程从队列中取走元素;
当队列为空时,继续出队列的操作也会阻塞等到,直到其他线程往队列里插入元素。
阻塞队列非常有用,尤其是在写多线程代码(多个线程之间进行数据交互)的时候,就可以使用阻塞队列来简化代码的编写!
阻塞队列的一个典型应用场景就是“生产者消费者模型”。这是一种非常典型的开发模型。
9.2.1 介绍生产者消费者模型
在介绍生产者消费者模型之前,先了解以下两个概念:
耦合:描述两个模块之间的关联性,关联性越强,耦合越高;关联性越差,耦合越低。
写代码追求低耦合,避免代码牵一发而动全身!
内聚:高内聚指的是,将代码分门别类,相关联的放在一起,想找就会特别容易。
生产者消费者模型可以解决很多问题,但最主要的是以下两方面:
可以让上下游模块更好的“解耦合”——高内聚,低耦合。
考虑以下场景:
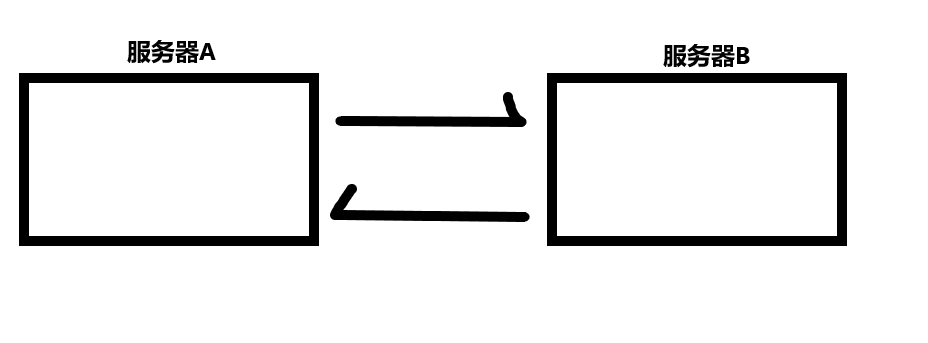
服务器A向服务器B发出请求,服务器B给A响应的过程中,如果B挂了,此时会直接影响A,A也就会跟着挂,这就是高耦合。
如果引入生产者消费者模型,耦合就降低了。
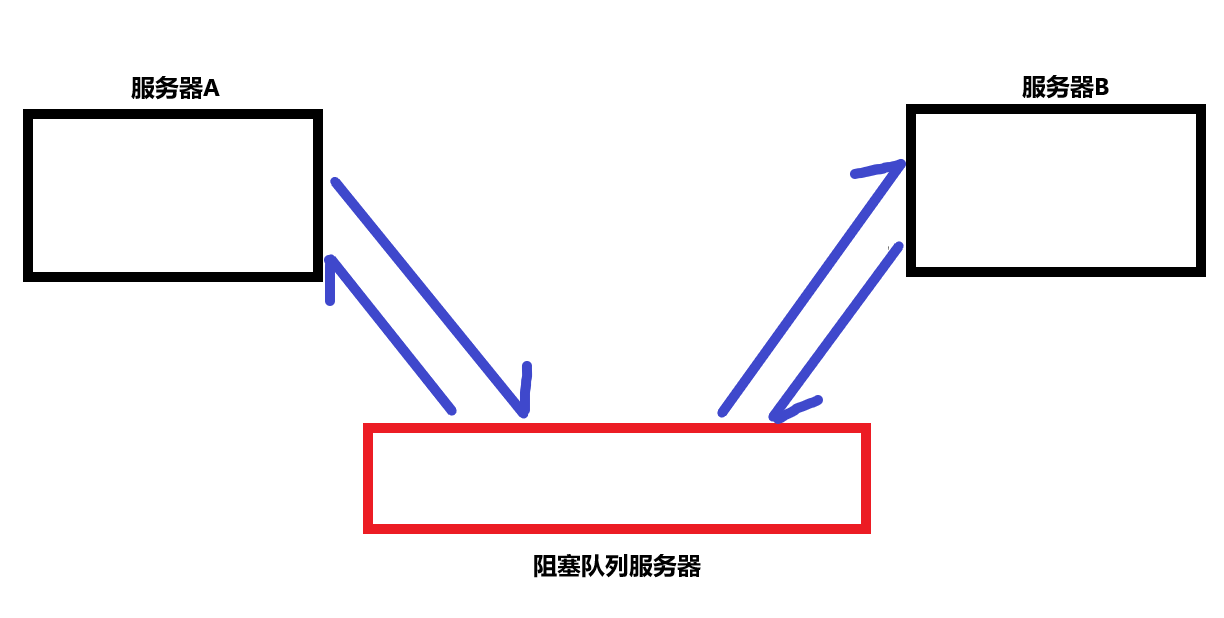
阻塞队列与业务无关,代码不大会变化,更加稳定;而AB是业务服务器,与业务相关,需要随时修改以便支持新的功能,也因此更容易出问题。如果A与B利用中间的阻塞队列来进行通信,那么当B出问题时,A完全不受影响。
削峰填谷
如果服务器A和服务器B是直接通信的,那么当A收到了用户的请求峰值,B也会同样收到来自A的请求峰值。要知道服务器处理每个请求都需要消耗硬盘资源,包括但不限于(CPU、内存、硬盘、带宽......)。如果某个硬盘资源使用达到了上限的同时,服务器B的设计并没有考虑到峰值的处理,此时服务器B可能就挂了!这就给业务的稳定性带来了极大的风险。
但如果A与B之间通过阻塞队列来进行通信,那么当A收到的请求多了时,阻塞队列里的元素也跟着多起来,此时B却可以按照平时的速率来接收请求,并返回响应。这里就可以看出阻塞队列帮服务器B承担了压力。
9.2.2 代码实现1:模拟实现一个阻塞队列
//循环队列!
public class MyBlockingQueue {private int[] nums = new int[100];volatile private int head = 0;volatile private int tail = 0;volatile private int size = 0;//入队列synchronized public void put(int elem) throws InterruptedException{//如果队列满了,阻塞等待if(size == nums.length){this.wait();}//如果队列未满,则可以继续添加nums[tail] = elem;tail++;//检查一下元素添加的位置是否未数组的最后一个if(tail == nums.length){tail = 0;}size++;//如果别的线程要取元素,发现数组为空,wait阻塞等待了,以下代码唤醒!//如果并没有别的线程阻塞等待,那么以下代码也没有任何副作用!this.notify();}//出队列synchronized public int take() throws InterruptedException{//如果队列为空,则阻塞等待if(size == 0){this.wait();}//如果队列不为空,那么就可以放心取元素了int value = nums[head];head++;//检查head是否已经来到数组的最后一个下标+1if(head == nums.length){head = 0;}size--;this.notify();return value;}
}上述代码的notify是交叉唤醒wait的!!
需要注意的是,除了notify()能唤醒wait()之外,如果其他线程中,调用了interrupt方法,就会提前唤醒wait!此时代码就会继续往下走,那对于空队列来说,再取元素,size就成了-1了!这就造成很大的问题了。所以最好wait被唤醒的时候,再判断一次是否满足条件,即将if改成while就好了!
//循环队列!
public class MyBlockingQueue {private int[] nums = new int[100];volatile private int head = 0;volatile private int tail = 0;volatile private int size = 0;//入队列synchronized public void put(int elem) throws InterruptedException{//如果队列满了,阻塞等待while(size == nums.length){this.wait();}//如果队列未满,则可以继续添加nums[tail] = elem;tail++;//检查一下元素添加的位置是否未数组的最后一个if(tail == nums.length){tail = 0;}size++;//如果别的线程要取元素,发现数组为空,wait阻塞等待了,以下代码唤醒!//如果并没有别的线程阻塞等待,那么以下代码也没有任何副作用!this.notify();}//出队列synchronized public int take() throws InterruptedException{//如果队列为空,则阻塞等待while(size == 0){this.wait();}//如果队列不为空,那么就可以放心取元素了int value = nums[head];head++;//检查head是否已经来到数组的最后一个下标+1if(head == nums.length){head = 0;}size--;this.notify();return value;}
}9.2.3 代码实现2:模拟实现生产者消费者模型
public class ThreadDemo2 {public static void main(String[] args) {MyBlockingQueue queue = new MyBlockingQueue();//消费者Thread t1 = new Thread(() -> {while(true){try {int value = queue.take();System.out.println("消费者: " + value);Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});//生产者:Thread t2 = new Thread(() -> {int value = 0;while(true){try {System.out.println("生产:"+ value);queue.put(value);Thread.sleep(2000);value++;} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
}上述代码中,生产者的生产速度远比消费者消费速度要慢,生产限制消费:
输出:
生产:0
消费者: 0
生产:1
消费者: 1
生产:2
消费者: 2
生产:3
消费者: 3
生产:4
消费者: 4
.......
如果生产速度远高于消费速度,又会怎么样呢?
输出:
生产:0
消费者: 0
生产:1
生产:2
......
生产:31
消费者: 1
生产:32
......
生产:63
消费者: 2
生产:64
......
生产:95
消费者: 3
生产:96
......
生产:104
消费者: 4
生产:105
消费者: 5
生产:106
消费者: 6
.......
到后面生产满了,就得等消费1个才能生产1个了。
9.3 定时器
定时器是实际开发中一个非常常用的组件,类似于一个 "闹钟",达到一个设定的时间之后, 就执行某个指定 好的代码。比如网络通信中, 如果对方 500ms 内没有返回数据, 则断开连接尝试重连。再比如一个 Map, 希望里面的某个 key 在 3s 之后过期(自动删除)。
9.3.1 标准库中的定时器
标准库中提供了一个 Timer 类,Timer 类的核心方法为 schedule。 schedule 包含两个参数,第一个参数指定即将要执行的任务代码, 第二个参数指定多长时间之后 执行 (单位为毫秒)。
import java.util.Timer;
import java.util.TimerTask;public class ThreadDemo1 {public static void main(String[] args) {Timer timer = new Timer();timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello hello hello hello♥");}},4000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello hello hello♥");}},3000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello hello♥");}},2000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello♥");}},1000);System.out.println("♥");}
}输出:
♥
hello♥
hello hello♥
hello hello hello♥
hello hello hello hello♥
此时的程序并没有执行完毕。那是因为Timer内置了线程,而且是个前台线程,会阻止进程结束!
9.3.2 模拟实现一个定时器
同学们,要想对定时器有更加深刻的了解,我们最好模拟实现一下定时器。
由上一节的代码可以看出,定时器内部不仅仅管理一个任务,还可以管理多个任务,虽然任务有很多,但它们的触发时间是不同的。只需要一个/一组工作线程,每次找到这些任务中,最先到达时间的任务,执行完之后再去执行下一个到达时间的任务,也可以是阻塞等待下一个到达时间的任务。这也就意味着,定时器的核心数据结构是堆!!
如果希望在多线程环境下,优先级队列还能线程安全,Java集合框架中提供了PriorityBlockingQueue,即带优先级的阻塞队列。
import java.util.concurrent.PriorityBlockingQueue;class MyTask implements Comparable<MyTask>{public Runnable runnable;public long time;//构造方法//delay 单位 毫秒public MyTask(Runnable runnable, long delay){this.runnable = runnable;time = System.currentTimeMillis() + delay;}@Override//优先级队列存放MyTask的对象,是需要比较方法的public int compareTo(MyTask o) {return (int)(this.time - o.time);}
}class MyTimer {private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();private Object locker = new Object();public void schedule(Runnable runnable, long delay){MyTask myTask = new MyTask(runnable,delay);queue.put(myTask);//如果新创建的任务等待时间比之前的任何一个任务都要短,那么这里唤醒wait,线程继续往下走的时候//取的就是这个新加入的任务了!、synchronized (locker){locker.notify();}}// 在这里构造线程, 负责执行具体任务了.public MyTimer(){Thread t1 = new Thread(() -> {while(true){try {synchronized (locker){MyTask myTask = queue.take();long currentTime = System.currentTimeMillis();if(myTask.time <= currentTime){myTask.runnable.run();}else{//时间还没到,把拿出来的任务再塞回去!queue.put(myTask);//由于这是个循环,再塞回去之后,下一个循环又再取出来,但时间依旧还有好久才到//这会让cpu在等待的时间里,反复取任务,又反复塞回去,忙等!!//所以我们最好让线程在这个时间里不再参与cpu调度locker.wait(myTask.time - currentTime);}}} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();}
}public class ThreadDemo2 {public static void main(String[] args) {MyTimer myTimer = new MyTimer();myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("♥♥♥♥♥");}},4000);myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("♥♥♥♥");}},3000);myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("♥♥♥");}},2000);myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("♥♥");}},1000);System.out.println("♥");}}输出:
♥
♥♥
♥♥♥
♥♥♥♥
♥♥♥♥♥
这小节的最后,提出这样一个问题:加锁的位置改成这样,会出现什么问题呢?
......public MyTimer(){Thread t1 = new Thread(() -> {while(true){try {MyTask myTask = queue.take();long currentTime = System.currentTimeMillis();if(myTask.time <= currentTime){myTask.runnable.run();}else{//时间还没到,把拿出来的任务再塞回去!queue.put(myTask);//由于这是个循环,再塞回去之后,下一个循环又再取出来,但时间依旧还有好久才到//这会让cpu在等待的时间里,反复取任务,又反复塞回去,忙等!!//所以我们最好让线程在这个时间里不再参与cpu调度synchronized (locker){locker.wait(myTask.time - currentTime);}}} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();}
}
......每一次take拿的的任务一定是所有任务中,到达时间最短的。如果把锁加到上述位置,就让take与wait不是原子性的。假设take之后,拿到了一个任务,执行时间14:30,而当前时间为14:00,在还没有走到wait之前,主线程main又创建了一个新的任务,14:10分的,此时notify就没有对应的wait可以唤醒。新任务创建成功之后,之前的线程继续往下走,就得干等30分,而不是等10分之后去执行14:10分的那个任务!这就使得最先到达时间的任务不能及时执行。
9.4 线程池
线程的创建虽然比进程的创建要轻量,但在频繁创建的情况下,开销也是不可忽视的! 为了进一步减少每次启动、销毁线程的损耗,人们引进了线程池。线程池就是提前把线程创建好,后续需要创建线程时,不再向系统申请,而是直接从线程池中拿,最后用完了,再把线程还给线程池。
为什么线程池就比直接创建线程效率更高呢?要知道从系统中创建线程,是在内核态里完成的。但对于内核来说,创建线程不是它唯一的任务,它可能先去完成别的任务,再继续创建线程。再者创建线程还涉及到用户态与内核态之间的切换;而从线程池里拿一个线程,只涉及到了用户态。给一个形象一点的例子:为了打印一份文件,你来到了打印店。内核就像是打印店里的工作人员,你让他帮你打印时,他有时空闲能直接帮你打印,有时你需要排队等候,甚至有时工作人员在忙自己的事情,你就得等他忙完了再帮你打印——时间不可控;而用户态操作更像是打印店里的自助打印机,你来到店里,直接打印完事——时间可控。
9.4.1 标准库里提供的线程池类
public class ThreadDemo2 {public static void main(String[] args) {//并没直接 new ExecutorService 来实例化一个对象//而是通过 Executors 里的静态方法完成对象构造!ExecutorService pool = Executors.newFixedThreadPool(2);//线程池里有个线程pool.submit(new Runnable() {@Overridepublic void run() {while(true){System.out.println("♥♥♥♥♥♥♥♥♥");}}});pool.submit(new Runnable() {@Overridepublic void run() {while(true){System.out.println("♥♥⭐♥♥");}}});}
}输出:
......
♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥
♥♥⭐♥♥
♥♥⭐♥♥
.......
♥♥⭐♥♥
♥♥⭐♥♥
♥♥⭐♥♥
♥♥⭐♥♥
♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥
......
9.4.2 模拟实现一个线程池
import java.util.*;
import java.util.concurrent.*;class MyThreadPool{//用阻塞队列来存放任务private BlockingDeque<Runnable> queue = new LinkedBlockingDeque<>();public void summit(Runnable runnable) throws InterruptedException{queue.put(runnable);}public MyThreadPool(int n){for (int i = 0; i < n; i++) {Thread t1 = new Thread(() -> {while(true){try {Runnable runnable = queue.take();runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();System.out.println("创建线程 "+ i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}public class ThreadDemo1 {public static void main(String[] args) throws InterruptedException{MyThreadPool pool = new MyThreadPool(10);Thread.sleep(12000);for (int i = 0; i < 1000; i++) {int number = i;pool.summit(new Runnable() {@Overridepublic void run() {System.out.println("hello " + number);}});}}
}输出:
创建线程 0
创建线程 1
创建线程 2
创建线程 3
创建线程 4
创建线程 5
创建线程 6
创建线程 7
创建线程 8
创建线程 9
hello 0
hello 1
hello 4
hello 5
........
需要注意的是,ThreadDemo1类中,匿名内部类遵循变量捕获规则,每次循环修改number的值,就相当于number没有被修改。
10 面试题
进程与线程的区别
wait和sleep的区别
不同点:
wait需要搭配synchronized使用,而sleep不需要
wait是Object的方法,而sleep是Thread的静态方法
相同点:
都可以让线程放弃执行一段时间
多线程环境下,懒汉模式如何保证线程安全?
加锁,把if和new变成原子操作
双重if,减少不必要的加锁操作
使用volatile禁止指令重排序,保证后续线程一定拿到完整的对象!


![[软件测试]软件测试的原则及软件质量](https://img-blog.csdnimg.cn/f90a725758494a84b28d7b35a787bcaf.png)