SRP Batcher是URP中非常重要的draw call优化方式。本篇介绍SRP Batcher的原理,使用条件,以及如何在自定义的URP Shader中支持SRP Batcher。
SRP Batcher原理
我们通常的draw call优化都是从减少draw call入手,其中有基于几何体合并的合批,包括静态batch和动态batch,都是讲不同的mesh合并成一个mesh,减少draw call的调用次数,以及当mesh相同时使用GPU Instancing一次性批量绘制也可大大减少draw call。而SRP Batcher另辟蹊径,Unity再研究之后认为,大部分的draw call比较费的其实不是draw call本身,因为对于CPU来说,一个draw call仅仅是提交几个简单的指令。真正费的是伴随着draw call的渲染状态切换,比如材质使用的uniform。早期的平台不支持uniform buffer object,设置每个uniform都要使用一条指令,如果两个材质的uniform大不相同,切换材质时就要重复设置,造成大量的渲染状态切换。另外标准的unity渲染工作流可以在一帧中任意时候修改材质的属性,这虽然很灵活,但是也造成了渲染状态的切换。下图是unity标准的渲染工作流:
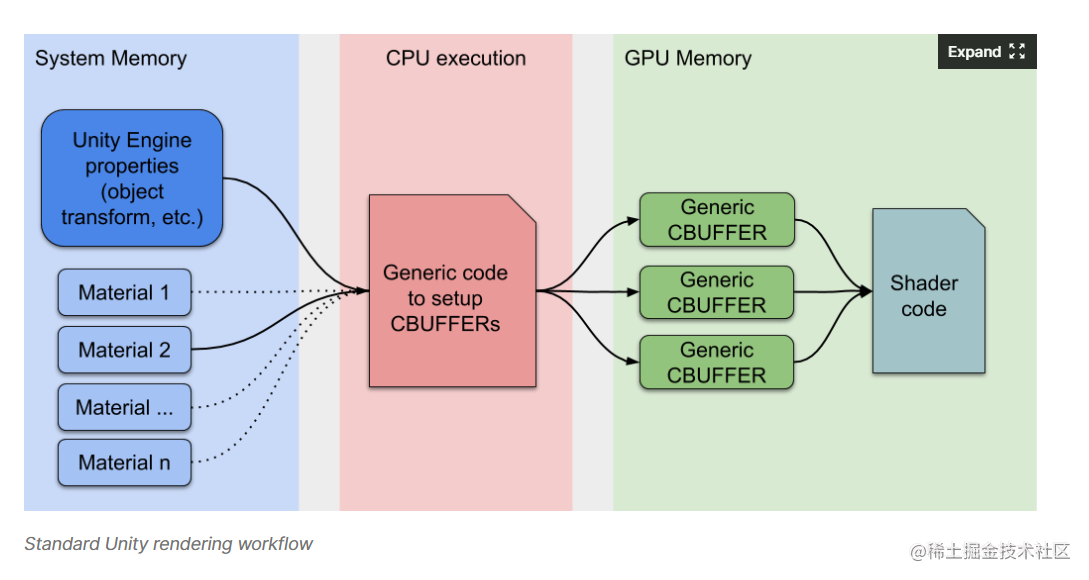
在渲染循环中,当发生材质切换时,CPU会搜集材质需要的各种属性,并且会设置到GPU显存的各个CBuffer中,CBuffer的数量取决于shader定义了多少CBuffer。
而Unity在实现SRP时,修改了底层代码,通过尽可能在显存中缓存材质属性,来提升材质多而shader变体少这种通常情况下的渲染状态切换的效率。
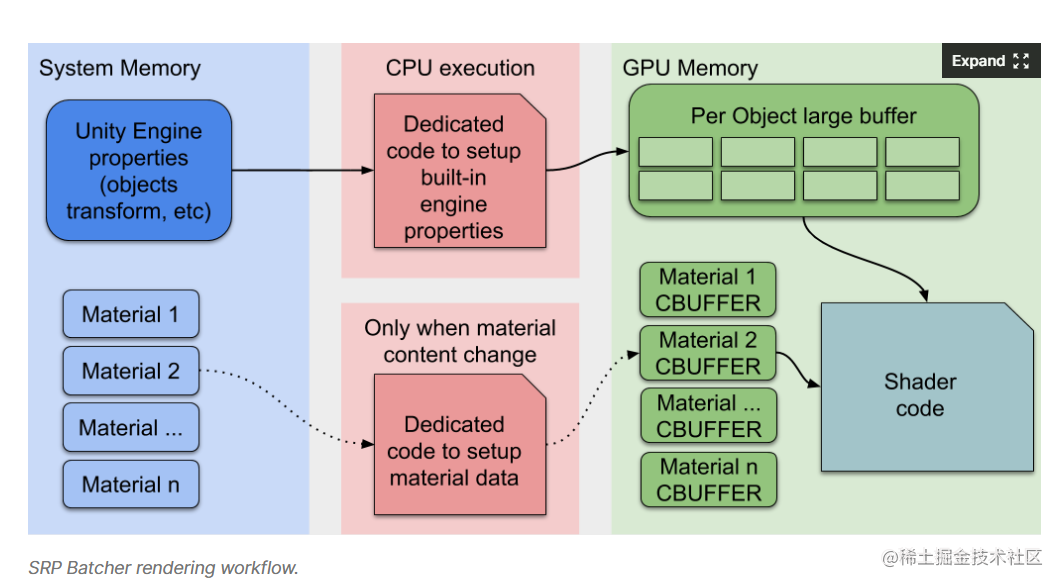
SRP Batcher的渲染工作流如上图,显存中有一个存放逐个Object属性的大buffer,并且CPU上有专用的代码将引擎内置属性填充到这个buffer中(比如每个物体的矩阵)。同时显存中还缓存了每个材质的CBuffer,当切换材质时CPU并不需要重复的设置材质的属性,而只是简单的告诉GPU现在用哪个材质缓存的属性。如果材质的属性不变,就不需要从CPU往GPU传递新的属性值。从这两个方面入手,切换材质时从CPU向GPU传递的数据量以及次数被大大降低了。想象一下如果你有几百个物体使用各自不同的材质,但是这些材质使用了同一个shader变体,如果材质不变化,那么只有刚开始加载时传递了材质属性,之后如果这些物体的矩阵改变才会更新一下改变的per-Object属性,否则啥都不用作。对比之前的标准操作,省了不是一点半点。
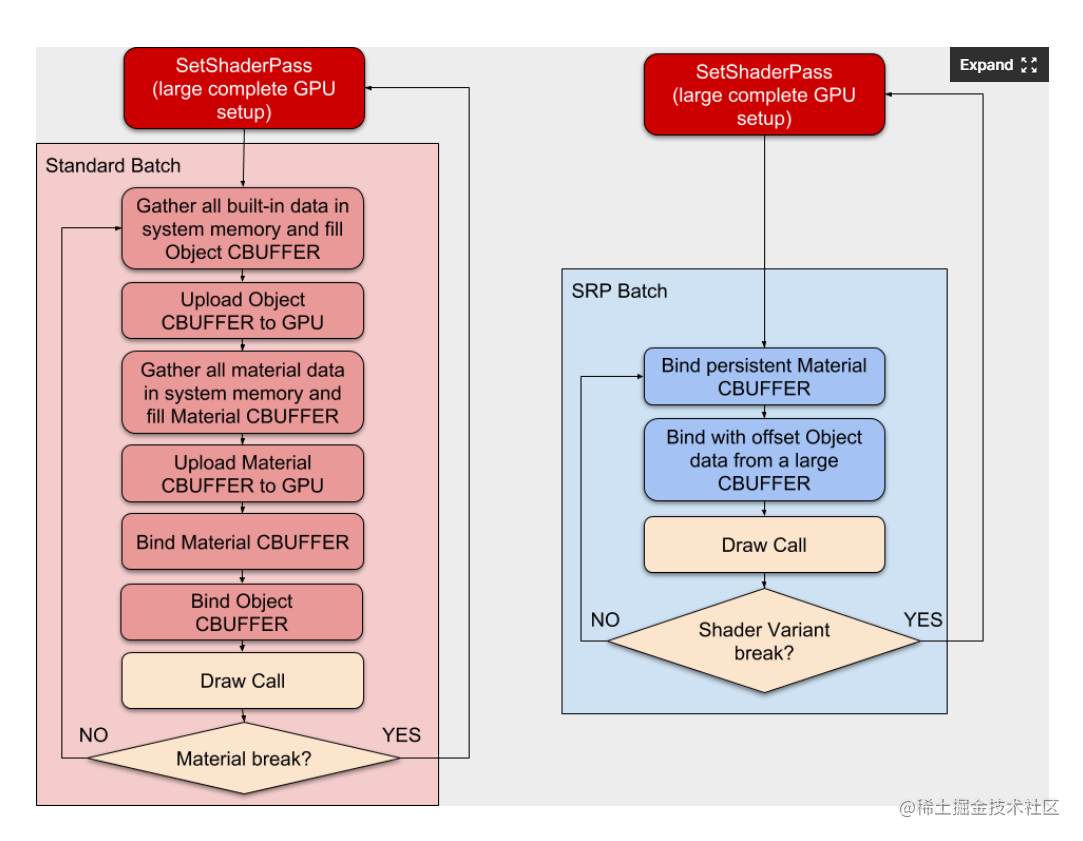
从上图可以对比看一下,老的流程需要搜集并上传object的CBuffer,搜集并上传Material的各个CBuffer,绑定材质的CBuffer,绑定Object CBuffer最后才能执行draw call。而SRP Batcher优化后,只需要做bind和draw就行。当shader变体没改变时就是bind材质属性,从object大buffer中使用offset bind object CBUffer,然后draw call。如果shader变体改变,则执行set pass call。
SRP Batcher和静态Batcher, GPU Instancing,动态batch的优先级
- 如果物体是静态的(Batching Static),则会使用Static Batching。如果物体的材质兼容SRP Batcher,则会同时使用SRP Batcher。
- 动态物体,优先使用 SRP Batcher
- 在非静态Batch,且不支持SRP Batcher的情况下,如果物体的材质和Renderer兼容GPU Instancing,则会启用GPU Instancing
- 以上都不支持的情况下,如果开启了Dynamic Batching,则会使用动态Batch。
SRP Batcher的使用条件
- 首先要在URP Asset的高级设置中开启:

也可以在代码中开关:
GraphicsSettings.useScriptableRenderPipelineBatching = true;
- GameObject要兼容SRP Batcher
- GameObject必须是包含Mesh或SkinnedMesh,而粒子是不支持SRP Batcher的
- 不可以使用MaterialPropertyBlocks.
- GameObject材质的shader要兼容与SRP Batcher,在Shader的Inspector中能看到是否兼容:
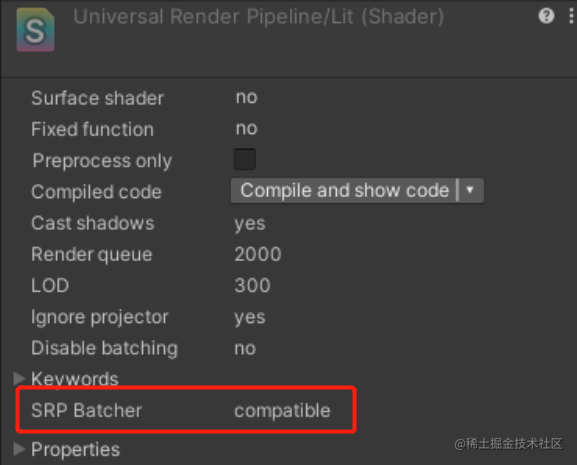
自定义Shader兼容SRP Batcher
- 首先对于Unity内置属性,比如
unity_ObjectToWorld要放在一个名字为UnityPerDraw的CBuffer中。其实我们写自定义shader都是直接include URP的Libraray的,其中已经做好了这个。在Packages\com.unity.render-pipelines.universal\ShaderLibrary\UnityInput.hlsl中我们看到:
// Block Layout should be respected due to SRP Batcher
CBUFFER_START(UnityPerDraw)
// Space block Feature
float4x4 unity_ObjectToWorld;
float4x4 unity_WorldToObject;
float4 unity_LODFade; // x is the fade value ranging within [0,1]. y is x quantized into 16 levels
real4 unity_WorldTransformParams; // w is usually 1.0, or -1.0 for odd-negative scale transforms// Light Indices block feature
// These are set internally by the engine upon request by RendererConfiguration.
real4 unity_LightData;
real4 unity_LightIndices[2];float4 unity_ProbesOcclusion;// Reflection Probe 0 block feature
// HDR environment map decode instructions
real4 unity_SpecCube0_HDR;// Lightmap block feature
float4 unity_LightmapST;
float4 unity_DynamicLightmapST;// SH block feature
real4 unity_SHAr;
real4 unity_SHAg;
real4 unity_SHAb;
real4 unity_SHBr;
real4 unity_SHBg;
real4 unity_SHBb;
real4 unity_SHC;
CBUFFER_END
这些属性被分为不同的block,虽然我们可能只使用一部分block,但是还是得按照这个布局来。
- 材质自定义的属性要放在
UnityPerMaterial的CBuffer中。
以之前看过的SimpleLitInput.hlsl为例:
CBUFFER_START(UnityPerMaterial)float4 _BaseMap_ST;half4 _BaseColor;half4 _SpecColor;half4 _EmissionColor;half _Cutoff;half _Surface;
CBUFFER_END
这些属性都是在逐材质的属性,因此需要定义在这个cbuffer中,才能在材质切换时直接绑定显存中的cbuffer。另外虽然贴图也是在Properties中指定的,但是贴图本身不能放到CBuffer中,但是其缩放(这儿的_BaseMap_ST)要放进去。这是因为贴图和Sampler都不是Uniform。
本篇总结
本篇从SRP Batcher的原理入手,理解了原理自然知道Shader应该怎么写才能支持。