Self Correspondence Distillation for End-to-End Weakly-Supervised Semantic Segmentation
摘要
论文链接
代码链接
目前的方法对综合语义信息的提取不足,导致伪标签质量较低
- 提出了一种简单而新颖的自相关蒸馏(SCD)方法,在不引入外部监督的情况下对伪标签进行细化。
- SCD使网络能够利用从自身派生的特征相关性作为蒸馏目标,通过补充语义信息来增强网络的特征学习过程。
- 为了进一步提高伪标签的分割精度,设计了一个Variationaware Refine Module,通过计算像素级的变化来增强伪标签的局部一致性。
- 提出了一个高效的基于变压器的端到端框架(TSCD),通过SCD和可变感知细化模块来实现精确的弱监督分割任务。

本文方法
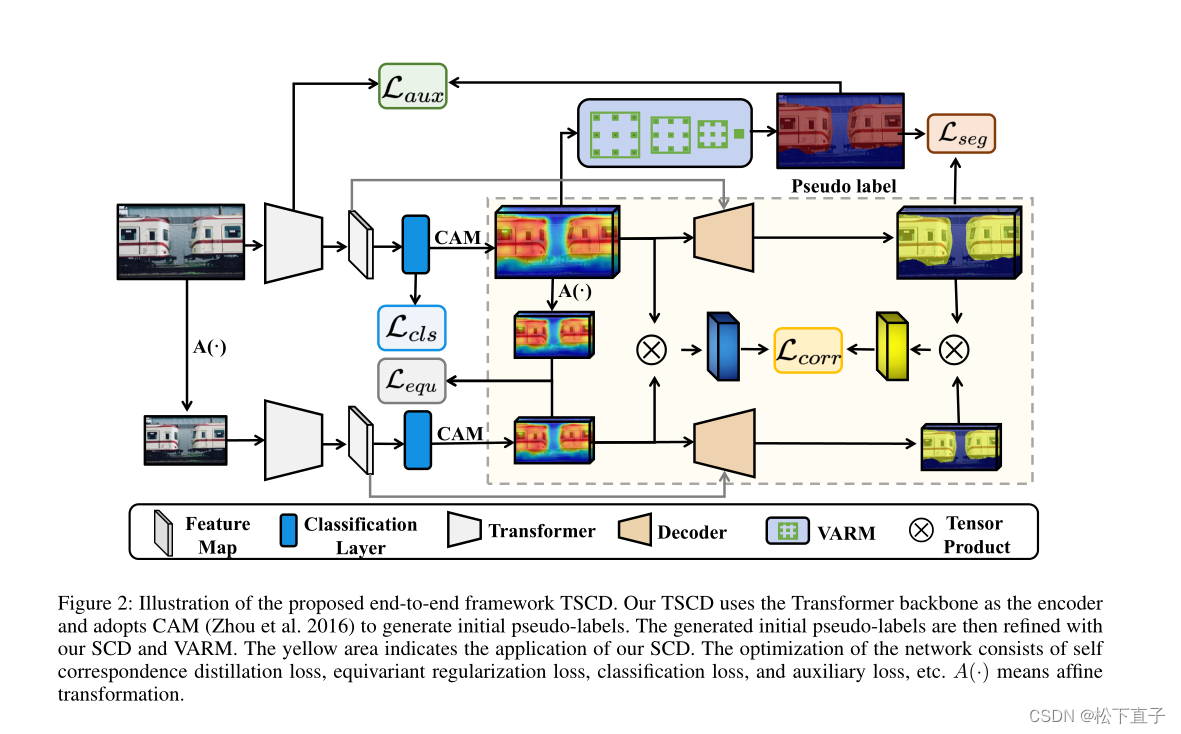
Self Correspondence Distillation
通过自相关蒸馏对原始图像的CAM进行细化,不需要任何额外的标签和外部监督,同时可以帮助网络获得全面的图像语义信息。自监督特征学习的最新进展表明,密集特征在语义上是相关的,这些密集的特征映射可以是类激活映射
CAM Feature Correspondence
形式上,我们关注cam之间的相关体积。给定两个CAM, m1∈RH1×W1×C, m2∈RH2×W2×C, H1, H2为高度,W1, W2为宽度,C为类别,我们定义CAM特征相关关系为:
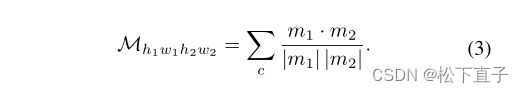
具体来说,给定一个图像I∈R(H×W ×D)和一个仿射变换A(·),我们使用编码器提取的特征映射来生成cam。以CAM m1为例,我们用E: R(H×W ×D)→R(H1×W1×C)表示从提取的特征图生成CAM m1的过程。因此,m1和m2可以表示为:
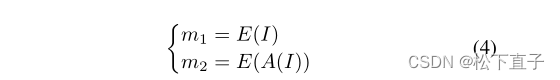
那么CAM特征对应关系可以进一步表示为:
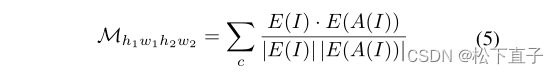
编码器和解码器共享权值,图像I和A(I)的分割预测映射分别记为s1∈R(H1×W1×C)和s2∈R(H2×W2×C)。然后将分割特征对应定义为:
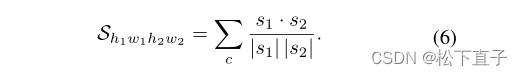
SCD for Training
我们的自相关蒸馏(SCD)背后的直觉是,分割特征对应可以从CAM特征对应中提取有用的语义信息,以自学习的方式细化CAM。受自监督特征学习的启发,我们考虑将分割特征对应与网络自身的CAM特征对应对齐。损失函数的设计目的是将相应的cam推到一起,以增强语义相关性,当两个分割预测之间存在显著相关性时。我们通过将对应的分割特征S(h1w1h2w2)与对应的CAM特征M(h1w1h2w2)进行简单的元素乘法来实现SCD损失函数:
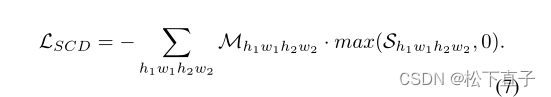
在实践中,为了保证推理效率,我们采用随机抽样策略来训练我们的SCD损失函数,样本数量为n。如果分割预测图的大小与对应CAM的大小不同,则对分割预测图应用双线性上采样
Variation-Aware Refine Module
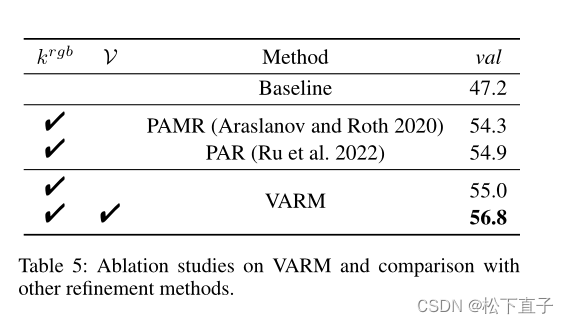
CAM得到的初始伪标签通常局部不一致,边界粗糙。许多多阶段方法使用CRF来进一步细化初始伪标签,这降低了训练效率。对于端到端方法,Araslano等人(Araslanov和Roth 2020)利用像素自适应卷积提取局部图像信息以获得局部一致性,而Ru等人进一步结合空间信息构建细化模块。不同于前面两人,我们设计了可变感知的细化模块,它引入了图像降噪的思想来克服局部不一致性。
具体来说,对于图像i中的位置(i, j)和(k, l),我们首先计算图像像素级的变化:

其中σij为标准差,α为平滑权值。为了增强伪标签的局部一致性,对于图像中变化较大的像素,我们计算校正核kij,kl,以避免出现一些突然变形的值
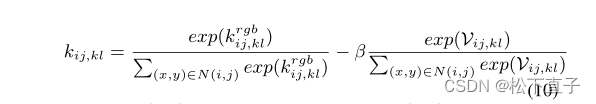
其中N(i, j)是(i, j)的邻居集,使用扩张卷积获得。我们采用迭代更新策略更新像素标签(CAM) Pi,j,c:
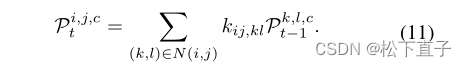
我们的变量感知细化模块通过感知像素级变化来增强初始伪标签的局部一致性,同时保证了较高的训练效率。
Transformer-Based Framework with Self Correspondence Distillation
自对应蒸馏(TSCD)框架由transformer主干、SCD、VARM、等变正则化loss、分类loss、辅助loss和分割loss组成。然后分别介绍了各损失函数和总损失
等变正则化损失:等变约束已被证明可以缩小弱监督和充分监督之间的监督差距
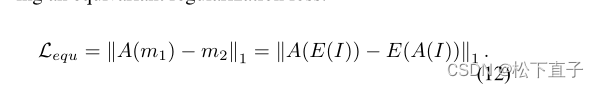
分类损失:softmax
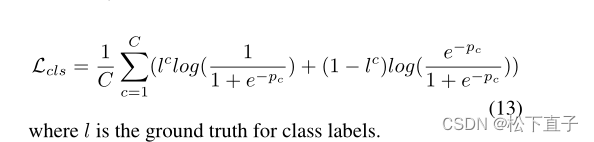
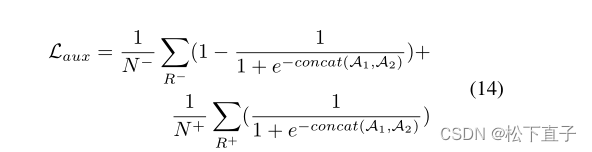
辅助损失:affinity loss
直接使用编码器最后两层输出的注意图(A1, A2)来计算辅助损耗。形式上,辅助损失表示为:
总损失:
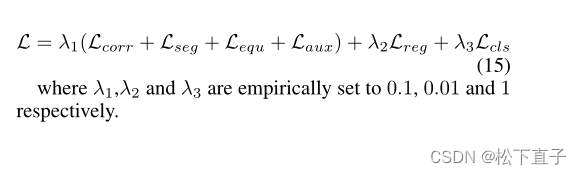
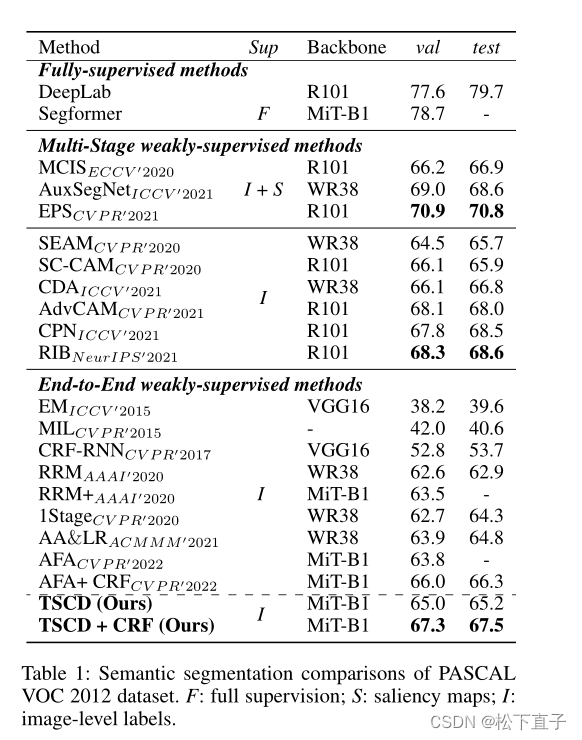
实验结果
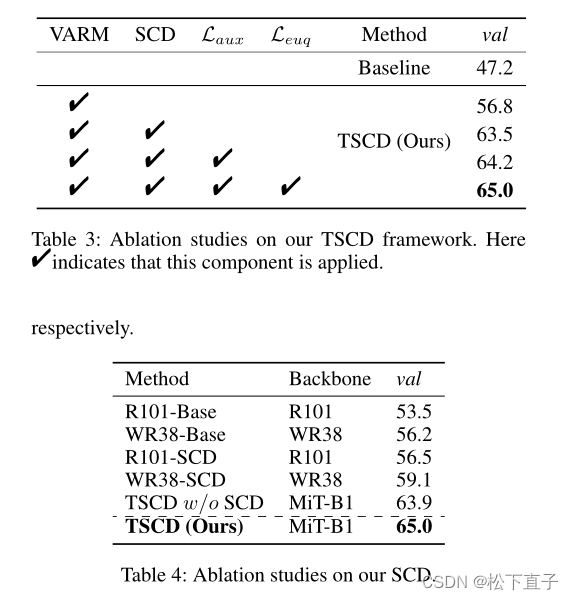
消融实验