来源:机器之心
本文约2900字,建议阅读10+分钟VGSE模型能够发掘与人工标注属性互补的视觉特征。来自北京邮电大学、马普所等机构的研究者提出了类别嵌入发掘网络,提高了类别嵌入在视觉空间的完备性,对零样本学习中类别之间的知识转移有重要促进作用。
零样本学习旨在模仿人类的推理过程,利用可见类别的知识,对没有训练样本的不可见类别进行识别。类别嵌入(class embeddings)是描述类别语义和视觉特征的向量,能够实现知识在类别间的转移,因而在零样本学习中发挥着不可替代的作用。
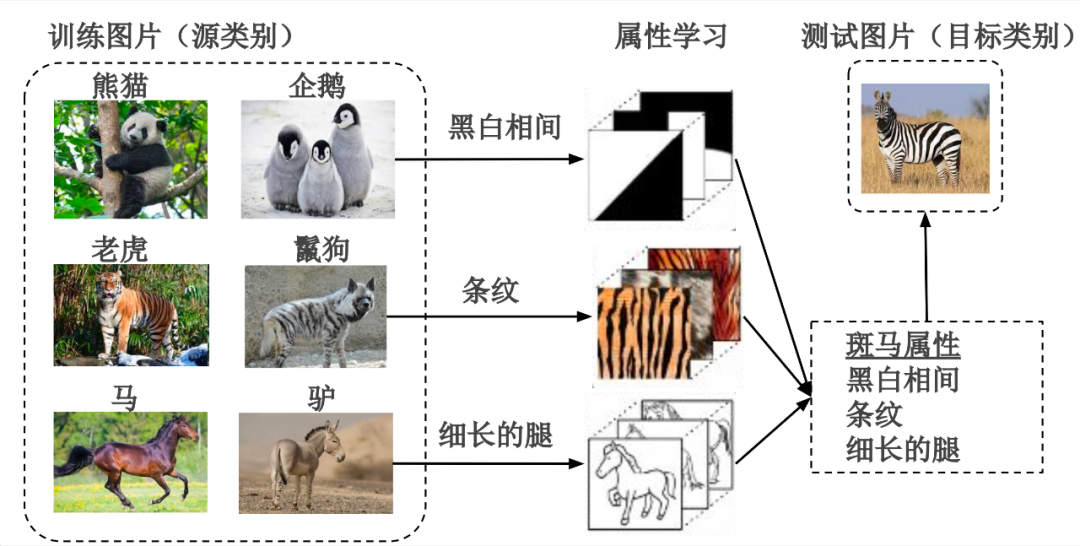
零样本分类图解
如上图所示,由于属性(attributes)能够被不同类别共享,促进了知识在类别间的转移,因此是使用最广泛的类别嵌入。并在其他计算机视觉任务(如面部识别、细粒度分类、时尚趋势预测)中被广泛用作辅助信息。
然而属性标注过程需要大量人力投入和专家知识,限制了零样本学习在新数据集上的拓展。此外,受限于人类的认知局限,其标注的属性无法遍历视觉空间,因而图像中一些具有辨别性的特征无法被属性捕捉,导致零样本学习效果不佳。
针对以上问题,来自北京邮电大学、马普所等机构的研究者提出了类别嵌入发掘网络(Visually-Grounded Semantic Embedding Network, VGSE),本文主要回答了两个问题:(1)如何从可见类图像中自动发掘具有语义和视觉特征的类别嵌入;(2)如何在没有训练样本的情况下,为不可见类别预测类别嵌入。

论文链接: https://arxiv.org/abs/2203.10444
代码链接: https://github.com/wenjiaXu/VGSE
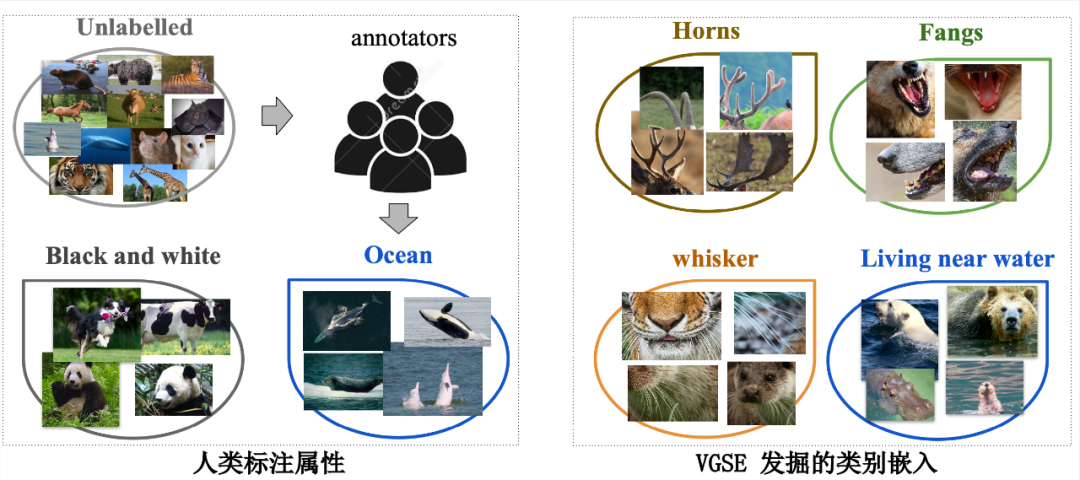
为了充分挖掘不同类别之间共享的视觉特征,VGSE 模型将大量局部图像切片按其视觉相似度聚类形成属性簇,从图像底层特征中归纳不同类别实例所共享的视觉特征。此外 VGSE 模型提出类别关系模块,在少量外部知识源的辅助下学习类别关系,能够将知识从源类别转移到目标类别,为没有训练图像的目标类别预测其类别嵌入。相较于其他基于语料自动挖掘而获得的属性,VGSE 模型在 CUB、SUN、AWA2 等零样本分类数据集上取得非常有竞争力的结果。如下图所示,本文能够发掘与人工标注属性互补的视觉特征,提高类别嵌入在视觉空间的完备性,对零样本学习中类别之间的知识转移有重要促进作用。本论文已被 CVPR 2022 录用。
类别嵌入发掘模型
类别嵌入发掘模型 VGSE 的算法流程如下所示,该模型主要由两个模块组成:(1)切片聚类模块(Patch Clustering, PC)以训练数据集为输入,将图像切片聚类成不同的簇。(2)类别关系模块(Class Relation, CR)用于预测不可见类的语义嵌入。
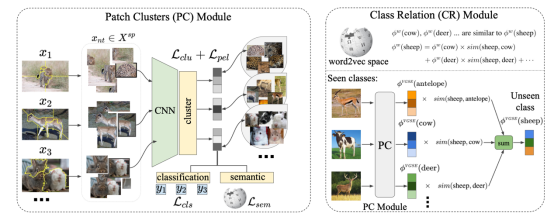
VGSE 模型结构图
切片聚类模块
由于属性通常出现在图像的局部区域,例如动物的身体部位、场景中物体的形状和纹理等,因此本文提出利用图像局部切片的聚类来发掘视觉属性簇。为了获得覆盖整个语义图像区域(例如动物头部)的图像块,切片聚类模块通过无监督紧凑分水岭分割算法 [4] 将图像分割成规则形状的区域,然后利用图像切片的视觉相似性进行聚类。
切片聚类模块是可微分的深度神经网络,给定图像切片,网络首先提取图像的特征,之后通过聚类层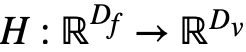 预测该特征被预测到每一个属性簇中的概率:
预测该特征被预测到每一个属性簇中的概率:
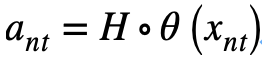
本文基于视觉相似性的聚类损失函数训练该聚类网络。强制图像切片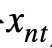 及其相似切片集被聚类到同样的属性簇:
及其相似切片集被聚类到同样的属性簇:
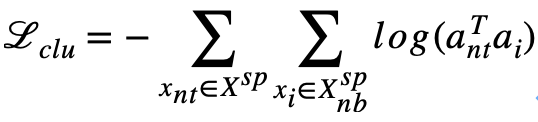
为了增强类别嵌入的可辨别性,使其能够分辨类别之间的显著性差异,本文提出加入可辨别性信息,通过学习全连接层,将每张图片的预测映射为其类别预测概率,然后使用交叉熵损失训练模型:
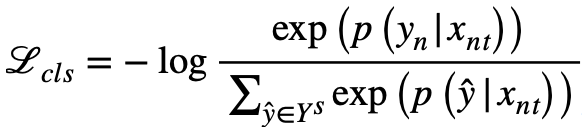
本文旨在学习类别之间共享的属性簇,促进知识在类别之间的转移,因此鼓励属性簇蕴含类别之间的语义联系。为实现这个目标,通过学习全连接层S,将每张图片的嵌入映射为类别的语义标签(此处使用类别名称的 w2v 向量)。然后通过回归损失训练模型,以加强类别嵌入的语义联系:
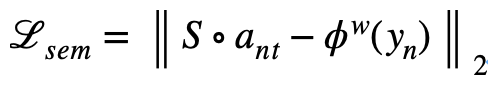
最终,完整图像的图像嵌入是通过平均该图像中的所有切片的嵌入来计算得到:
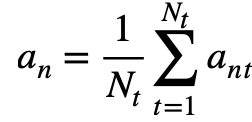
而类别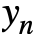 的嵌入由该类的所有图像嵌入平均而得:
的嵌入由该类的所有图像嵌入平均而得:
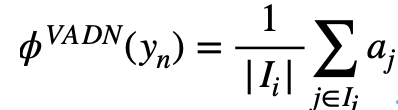
类别关系模块
可见类的类别嵌入可以由切片聚类模块预测得到。但现实情况中存在着大量不可见类,其类别嵌入无法通过图像进行预测。由于语义相关的类别通常共享部分属性,例如熊猫和斑马共享 “黑白相间“属性,麋鹿和公牛都包含“角” 这一属性。本节提出学习可见类与不可见类之间的语义相似性,并通过语义相关的可见类来预测不可见类的嵌入。任何外部语义知识,例如 w2v、glove 等类别语义嵌入或人工标注的属性,都可以用来学习两个类之间的关系。下文以 w2v 为例说明所提出的类别关系发掘模块。
给定可见类的 w2v 语义标签,和不可见类别的语义标签,本节学习了相似性映射,其中表示目标类和第个源类别之间的相似性。相似性映射通过以下优化问题学习:
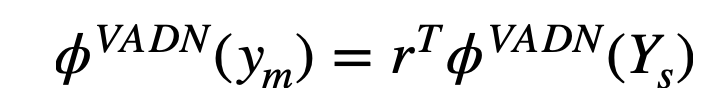
其中,目标类别的属性值是所有源类别属性值的加权和。
实验结果
本文在三个通用零样本分类数据集(CUB、AWA2、SUN)上验证所提出方法的效果。
下图展示了在 AWA2 数据集中学习得到的属性簇。我们将 10,000 个图像切片的嵌入利用 t-SNE 映射到二维空间。本文采样了几个属性簇 (用相同颜色的点) 并在图中标记了来自该属性簇的图像切片。
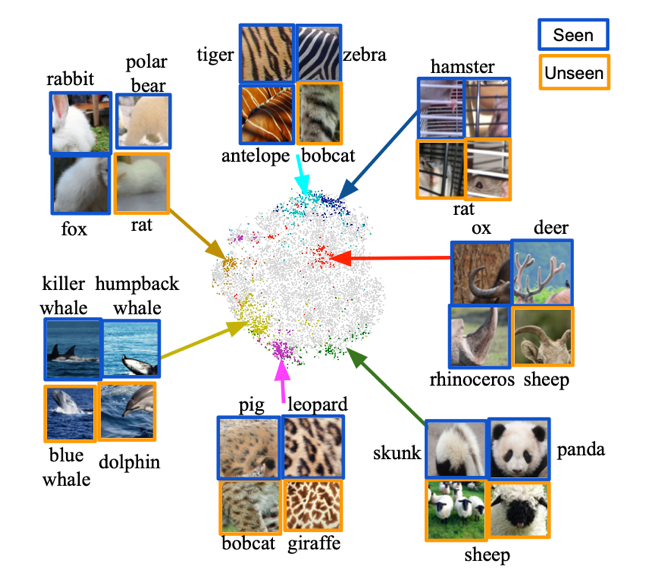
挖掘属性簇可视化结果
图中数据说明了以下几点:首先,可以观察到同一簇中的图像切片倾向于聚集在一起,且传达了一致的视觉信息,这表明图像嵌入提供了可辨别性信息。此外,几乎所有属性簇都包含来自多个类别的图像切片。例如,来自不同动物的条纹,虽颜色略有不同但纹理相似。这一现象表明本文学习的类别嵌入包含类间共享的信息。另一个有趣的观察是,本文提出的模型能够发现被人类标注忽略的视觉属性,可以增强人类标注属性的视觉完备性。
Table 1 展示了本文提出的类别嵌入 VGSE-SMO 与类别的 w2v 向量在三个数据集上的表现。为测试两种类别嵌入的能力,我们 f-VAEGAN-D2[5]等五种零样本分类模型上进行实验,结果表明本文提出的类别嵌入能够大幅度超越 w2v 向量的性能。
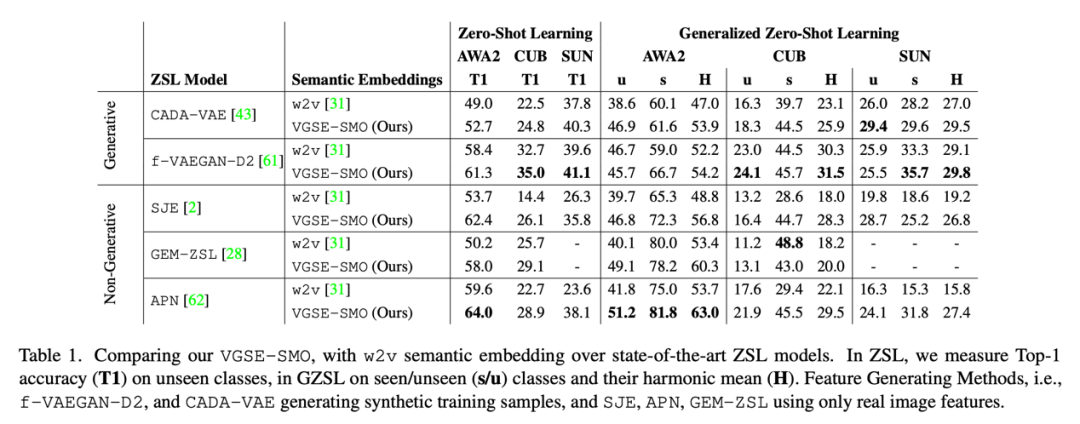
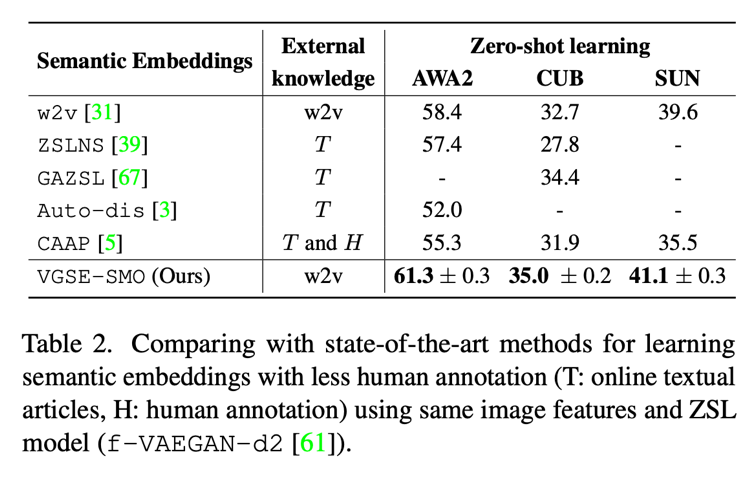
Table 2 在零样本分类任务上对比了本文提出的类别嵌入和其他几种语料挖掘属性方法的效果,结果表明本文的方法在仅使用 w2v 向量的情况下,效果要优于其他使用在线语料库的方法。
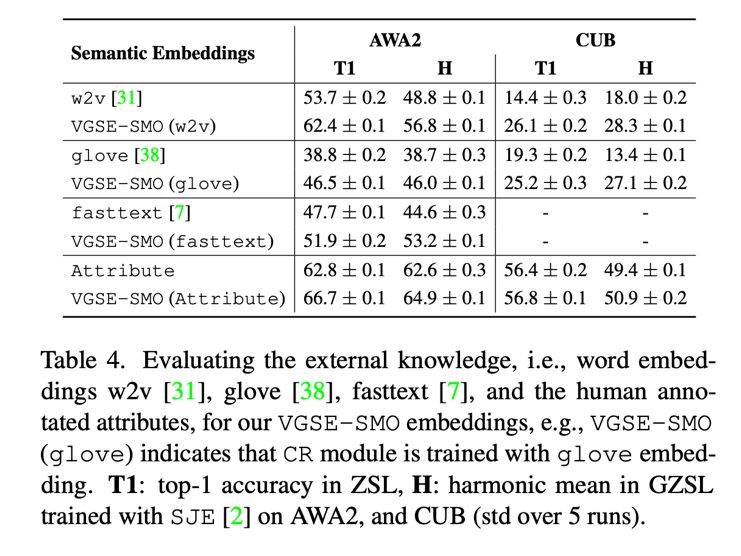
如前所述,本文提出的类别关系模块可以使用多种外部语义知识学习类别相似度,Table 4 展示了使用不同语义知识的效果。
本文进行用户调查探究所挖掘的类别嵌入的语义一致性和视觉一致性。随机挑选 50 个属性簇,并展示聚类中心的 30 张图片。用户首先被要求观察属性簇的示例图片。然后回答如下问题衡量属性簇的效果。

用户调查界面
结果表明,在 88.5% 和 87.0% 的情况下,用户认为本方法所挖掘的属性簇传达出一致的视觉和语义信息。
总结
为减少零样本学习所需的人工标注,提高类别嵌入的语义和视觉完备性,本文提出一个自动的类别嵌入发掘网络 VSGE 模型,能够利用图像切片的视觉相似性发掘类别嵌入。在三个数据集上的结果表明,本文提出的类别嵌入方案能够有效地提高语义嵌入的质量,并且可以挖掘出人类难以标注的细粒度属性。除了在零样本学习中发挥重要作用,本文所提出的类别嵌入也能够为其它属性相关研究提供新思路。
参考文献:
[1] Al-Halah, Ziad, and Rainer Stiefelhagen. "Automatic discovery, association estimation and learning of semantic attributes for a thousand categories." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[2] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Proceedings of the Advances in neural information processing systems. 2013.
[3] Wang, Xiaolong, Yufei Ye, and Abhinav Gupta. "Zero-shot recognition via semantic embeddings and knowledge graphs." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Neubert, Peer, and Peter Protzel. "Compact watershed and preemptive slic: On improving trade-offs of superpixel segmentation algorithms." Proceedings of the IEEE International Conference on Pattern Recognition. 2014.
[5] Xian, Yongqin, et al. "f-vaegan-d2: A feature generating framework for any-shot learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
编辑:黄继彦
校对:杨学俊