Natural TTS Synthesis by Conditioning Wavenet On Mel Spectrogram predictions
-
本篇论文是Tacotron2官方发布的论文,主要讲述了该组在TTS方向的新的进展。Tacotron2在目前TTS领域有着十分重要的地位。
该系统由两个部分组成,一个部分是循环序列到序列的特征预测网络,将特征叠加到梅尔光谱图上,在该部分之后通过一个修正过的Wavenet作为vocoder,它的输入为梅尔光谱图,通过vocoder之后,会将其合成为时域波形。Tacotron2所得到的合成语音比参照语音的MOS仅仅低了0.05。
在TTS方向,有着很多方法,在开始时,通常分为级联TTS和参数TTS两种方法,级联TTS合成语音的效果比较好,但是它对数据质量的要求条件比较高,通常需要的成本很高。参数TTS所需要的成本相对要低,但是其合成的语音相对比较模糊,不自然。之后在DL时代,出现了Wavenet和Tacotron在TTS领域的应用,都取得了非常优秀的成果,但是都存在着自身的缺陷。目前最优秀的两种方法联合起来应用于Tacotron2当中。
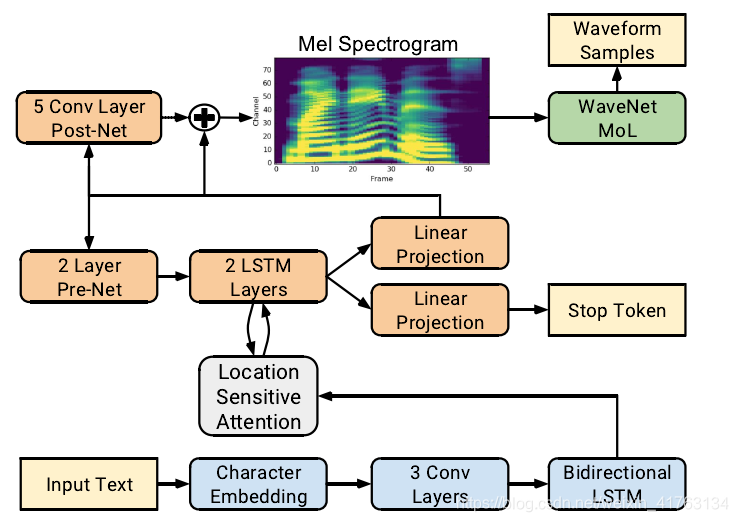
上图即Tacotron2的整体结构。
将输入文本转化为嵌入向量作为第一层的输入,通过特征预测得到的梅尔声谱图序列作为下一层Wavenet的输入,然后得到时域波形。
Wavenet的输入通常为语言特征,预测对数基频或者音素持续时间,但在Tacotron2中Wavenet的输入换成了梅尔声谱图。梅尔声谱图与STFT声谱图相关。相对于语言和声音特征,梅尔声谱图是一个比较简单,低水平的表现,wavenet模型通过这种表现能够直接生成音频。
接下来是两部分的详细描述,首先是第一部分声谱的预测网络,在Tacotron中,梅尔光谱图是由短时傅立叶变换转换得到。在本文中,使用一个80bins的梅尔滤波器组,并通过对数动态范围压缩,将STFT转化为梅尔光谱图。在对数压缩之前,滤波器组的输出量级会被剪辑到最小值0.01。第一部分的网络由encoder+attention+decoder组成。encoder的作用是将特征序列转化为隐藏的特征表现,decoder通过这种特征表现来预测光谱图。输入的特征表现为512维特征的嵌入向量,然后将该特征输入到三层卷积层当中,卷积核的个数为512个,大小为5*1。卷积层之后加上Norm层和Relu激励函数。最后一层卷积层的输出输入到一个双向LSTM层当中来生成编码后的特征。在encoder之后紧接着是attention。attention 的作用是要将充分编码的序列变为固定长度的语境向量。本文中使用了Location-sensitive attention来完成了这一步,通过这种算法,可以减轻某些潜在的失败模式。attention probability是由投影输入和位置特征所计算得到的。decoder是一个自动回归的RNN,它将每步每帧编码的输入序列预测为梅尔光谱图。当前步的预测要首先通过一个包含着2个全连接层的pre-net,每个全连接层有着256个Relu单元。prenet作为一个信息瓶颈,在attention学习上起着非常重要的作用。Prenet的输出和attention的语境向量被串联起来通过一个2层的单向LSTM层,有着1024个单元。**级联LSTM的的输出和attention语境向量要通过线性转换来预测目标光谱图。最终预测的光谱图要通过一个5层卷积的post-net,post-net预测了残差,并加入到预测结果当中,来提升总体的效果。每一个post-net是由512个滤波器组成,滤波器大小为51。*之后是正则化和tanh激励函数(除了最后一层)。
本文通过减小MSE(mean square error)进行训练,在post-net之后加速收敛。我们通过MDN对输出分布进行建模得到的对数似然误差来进行试验,这样可以避免长期使用同一变量。实验发现很难进行训练,并且不能生成好的声音题材。与光谱图的预测相似的是,将LSTM的输出和语境向量串联并投影形成标量之后,通过一个sigmoid激励函数来预测probability,然后完成了输出的序列。stop token的预测可以在模型动态决定何时终止生成语音时,作为参照。当第一帧生成完成时,probability最多会增加0.5。
网络中的卷积层均使用0.5的丢失率,LSTM层统一使用0.1的zoneout。仅decoder部分的prenet使用0.5的丢失率。与Tacotron相比,我们的模型使用相对简单的结构,使用了vanilla LSTM和卷积层来取代CBHG和GRU的RNN层。我们不使用reduction factor,decoder每一步都会生成一个简单的光谱图。
wavenet vocoder 我们使用了一个修正过的wavenet结构来讲光谱图特征表现转换为时域的波形图。和原始的结构相同的是,有30个扩大的卷积层,分组为三个扩大的周期。我们用RixelCNN++和Parallel Wavenet来代替softmax层,使用Mol来生成16为的采样,频率为24khz。为了计算逻辑混合分布,wavenet堆叠的输出通过Relu激励函数后,通过线性投影来预测每个混合部分的参数。损失通过基本事例的negative log-likehood所得。
训练过程:首先训练特征预测网络,然后通过第一层的输入来训练第二层修正的wavenet网络。为了训练特征预测网络。为了训练特征预测网络,使用标准的maxinum-likehood训练的发放,通过一个GPU,batch_size为64。优化方法是用Adam优化器,学习率为0.001,在每50000次迭代之后,学习率会有着0.00001的衰减。使用L2正则化的方法,权重为0.000001。
之后通过特征预测网络得出的预测信息来训练修正的wavenet,预测网络以Teacher forcing的模式运行。通过32个GPU进行同步训练,batch_size=128,并且也是用Adam作为优化器,固定学习率为0.0001。在每次参数更新的过程中来平均模型的权重。在更新步骤中维持网络参数的指数加权移动平均值,衰减为0.9999。在US English 数据集上进行训练,训练的文本都是归一化后的文本。
本文描述了Tactron2,一个完整的TTS系统,将序列到序列的循环网络和attention网络结合起来来预测梅尔声谱图,然后通过修正果的wavenet vocoder。最终该系统生成的合成语音有着达到Tacotron水平的韵律和wavenet水平的音频质量。该系统可以直接通过不需要使用复杂特征工程的数据进行训练,并且达到接近于自然人类语音的声音质量。