一、概述
代码来自:https://github.com/jindongwang/transferlearning,可以前往github下载代码,本文涉及的代码的位置为:Code->DeepDA。理论基础可以参见:[迁移学习]域自适应
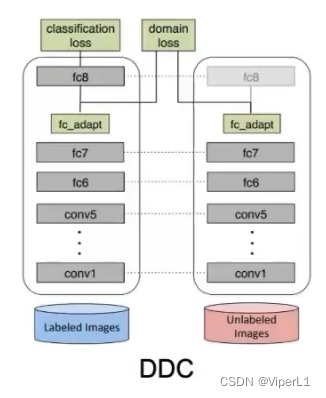
整体网络结构如下:可以视为一个分类网络(如Resnet50)+一个fc_adapt模块组成 。其损失函数为,即原来的交叉熵损失函数后面添加一个衡量源域和目标域之间距离的损失函数,一般为MMD,超参数
用来控制此损失函数的权重。
二、代码分析
1.dataloader
转到main函数,可以看到与dataloader相关的代码为:
source_loader, target_train_loader, target_test_loader, n_class = load_data(args)跳转后可以看到,在load_data(.)函数中数据集被分成下面三个部分,分别对应源域、目标域训练集、目标域测试集。
source_loader,target_train_loader,target_test_loader而实际起作用的是data_loader中的load_data,该函数重写了DataSet类并调用了dataloader
data = datasets.ImageFolder(root=data_folder, transform=transform['train' if train else 'test'])data_loader = get_data_loader(data, batch_size=batch_size, shuffle=True if train else False, num_workers=num_workers, **kwargs, drop_last=True if train else False)n_class = len(data.classes)2.model
main函数中,与model有关的代码为:
model = get_model(args)def get_model(args):model = models.TransferNet(args.n_class, transfer_loss=args.transfer_loss, base_net=args.backbone, max_iter=args.max_iter, use_bottleneck=args.use_bottleneck).to(args.device)return model该函数实际是从models文件中的TransferNet类中提取网络模型,继续转到TransferNet,该类有以下几个参数:类别个数,骨干网络类型,transfer_loss类型,以及一些调整骨干网络的参数。
class TransferNet(nn.Module):def __init__(self, num_class, base_net='resnet50', transfer_loss='mmd', use_bottleneck=True, bottleneck_width=256, max_iter=1000, **kwargs):随后看该网络的前向传递函数,基本可以归类为以下几部:
①骨干网络提取
source = self.base_network(source)
target = self.base_network(target)②源域分类
source_clf = self.classifier_layer(source)代码中的分类器是一个全连接层,对应的参数是隐藏层通道数和输出类别数
self.classifier_layer = nn.Linear(feature_dim, num_class)③源域分类损失函数计算
clf_loss = self.criterion(source_clf, source_label)代码中采用了一个交叉熵损失函数
self.criterion = torch.nn.CrossEntropyLoss()④迁移学习
这一小节是域自适应迁移学习和传统分类网络的最大区别,除了传统的cls_loss之外,该网络还计算了transfer_loss。
代码中提供了lmmd,daan,bnm三种方式,其代码基本大同小异,这里选取lmmd进行解析,lmmd代码如下:
if self.transfer_loss == "lmmd":kwargs['source_label'] = source_labeltarget_clf = self.classifier_layer(target)kwargs['target_logits'] = torch.nn.functional.softmax(target_clf, dim=1)该段代码的主要功能是从参数列表中获取source_label,同时使用上面同样的分类器对由骨干网络提取到的目标域特征进行分类(使用softmax进行分类,结果记录为target_logits),随后源域特征和目标域特征以及参数会被送入adapt_loss(.)模块用以计算transfer_loss。
同时从后续代码得知,如果使用最简单的mmd是不需要经过这一步处理的。
transfer_loss = self.adapt_loss(source, target, **kwargs)self.adapt_loss = TransferLoss(**transfer_loss_args)TransferLoss类为一个transfer_loss的提取模块,提供了6种不同的损失函数,这里以mmd为例。
if loss_type == "mmd":self.loss_func = MMDLoss(**kwargs)MMDLoss的完整代码如下:
import torch
import torch.nn as nnclass MMDLoss(nn.Module):def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5, fix_sigma=None, **kwargs):super(MMDLoss, self).__init__()self.kernel_num = kernel_numself.kernel_mul = kernel_mulself.fix_sigma = Noneself.kernel_type = kernel_typedef guassian_kernel(self, source, target, kernel_mul, kernel_num, fix_sigma):n_samples = int(source.size()[0]) + int(target.size()[0])total = torch.cat([source, target], dim=0)total0 = total.unsqueeze(0).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))total1 = total.unsqueeze(1).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))L2_distance = ((total0-total1)**2).sum(2)if fix_sigma:bandwidth = fix_sigmaelse:bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)bandwidth /= kernel_mul ** (kernel_num // 2)bandwidth_list = [bandwidth * (kernel_mul**i)for i in range(kernel_num)]kernel_val = [torch.exp(-L2_distance / bandwidth_temp)for bandwidth_temp in bandwidth_list]return sum(kernel_val)def linear_mmd2(self, f_of_X, f_of_Y):loss = 0.0delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)loss = delta.dot(delta.T)return lossdef forward(self, source, target):if self.kernel_type == 'linear':return self.linear_mmd2(source, target)elif self.kernel_type == 'rbf':batch_size = int(source.size()[0])kernels = self.guassian_kernel(source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)XX = torch.mean(kernels[:batch_size, :batch_size])YY = torch.mean(kernels[batch_size:, batch_size:])XY = torch.mean(kernels[:batch_size, batch_size:])YX = torch.mean(kernels[batch_size:, :batch_size])loss = torch.mean(XX + YY - XY - YX)return loss里面有大量的数学变换在这里就不进行深究了。其前向函数的作用是将源域和目标域之间的差距计算出来并返回loss。
⑤返回函数
该模型的前向传递函数最后会返回两个参数:clf_loss, transfer_loss,这两个参数将会被用于后面的反向传递。
3.训练
训练过程中,会从source_loader中提取源域图像和标签,从target_train_loader中提取目标域图像(不需要目标域的标签)。
然后将数据这三个数据送入模型,得到clf_loss和transfer_loss。最后将transfer_loss×权重系数lambda后与clf_loss相加后可以得到最终的损失函数loss。
clf_loss, transfer_loss = model(data_source, data_target, label_source)
loss = clf_loss + args.transfer_loss_weight * transfer_loss再然后就是自动的反向传递:
optimizer.zero_grad()
loss.backward()
optimizer.step()4.测试
测试过程与上面的训练大同小异,主要是不再需要前向传递。使用的是model中的predict函数而不是默认的前向传递函数
s_output = model.predict(data)该函数与之前的前向传递函数相比没有adapt_loss模块:
def predict(self, x):features = self.base_network(x)x = self.bottleneck_layer(features)clf = self.classifier_layer(x)return clf