降维?
降低数据集中特征的维数,同时保持尽可能多的信息的技术被称为降维。它是机器学习和数据挖掘中常用的技术,可以最大限度地降低数据复杂性并提高模型性能。
降维可以通过多种方式实现,包括:
主成分分析 (PCA):PCA 是一种统计方法,可识别一组不相关的变量,将原始变量进行线性组合,称为主成分。
第一个主成分解释了数据中最大的方差,然后每个后续成分解释主键变少。PCA 经常用作机器学习算法的数据预处理步骤,因为它有助于降低数据复杂性并提高模型性能。
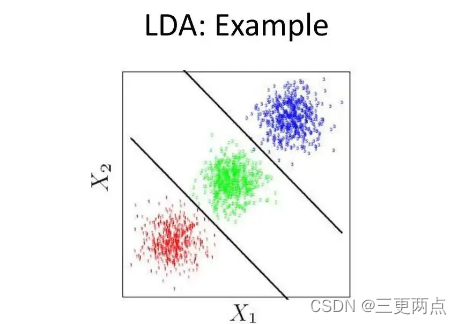
LDA(线性判别分析):LDA是一种用于分类工作的统计工具。它的工作原理是确定数据属性的线性组合,最大限度地分离不同类别。为了提高模型性能,LDA经常与其他分类技术(如逻辑回归或支持向量机)结合使用。
t-SNE: t-分布随机邻居嵌入(t-SNE)是一种非线性降维方法,特别适用于显示高维数据集。它保留数据的局部结构来,也就是说在原始空间中靠近的点在低维空间中也会靠近。t-SNE经常用于数据可视化,因为它可以帮助识别数据中的模式和关系。

独立分量分析(Independent Component Analysis) ICA实际上也是对数据在原有特征空间中做的一个线性变换。相对于PCA这种降秩操作,ICA并不是通过在不同方向上