目的
笔者看了一些介绍“混合A星”的博客,写的比较业余和肤浅。本文从专业的角度探讨一下无人车运动规划中著名的混合A星方法底层原理和代码实现。混合A星的应用包括泊车、取车(例如特斯拉的Smart Summon,如下右图),也可以用于低速清扫车的运动规划。


1 开源代码
据我所知,网上的开源混合A星算法代码有下面几个(还有一些matlab、mathematica、python版本笔者未包含)。通过分析他们的代码我们可以取长补短,也欢迎大家补充。
1 百度Apollo无人驾驶项目中的开放场地轨迹规划模块open_space;
2 瑞典老外的硕士论文项目:karl kurzer,本文也以它为例进行代码解剖;
3 ROS Navigation2的插件SmacPlannerHybrid,这个知名度比较低,但是较新,代码进行了优化;
4 Habrador以特斯拉为例用C#写的:Self-driving-vehicle;
2 基本思想
混合A星方法(Hybrid A*)由斯坦福大学的Dmitri Dolgov, Sebastian Thrun等人在2008年的会议论文《Practical Search Techniques in Path Planning for Autonomous Driving》中首次提出,后来又在此基础上补充了一些细节发表在机器人领域的顶级期刊 International Journal of Robotics Reaserch 上。狭义的混合A星只包含搜索的过程,广义的混合A星把后处理也加上了。所以混合A星可以看成是由几个模块组合起来的。混合A星适用于有运动约束的机器人,最典型的例子就是各种轮式移动机器人,比如汽车。
单词“Hybrid”有“杂交、混血”之意。顾名思义,混合A星可以看成是探索树方法和A星算法的混血儿。这两种方法在机器人领域都是家喻户晓的大明星,所以他们结个婚生个孩子也很自然,毕竟组合创新是最容易的创新之一。拙劣的创新是生硬的模仿,但是混合A星方法组合的就比较巧妙,把爸妈的优点都继承了。什么优点呢,笔者后面会仔细分析。总之,它们的孩子也出名了,甚至最新版的Matlab居然都内置了混合A星函数:plannerHybridAStar,想体验的读者可以玩玩,但是Matlab使用了占据栅格地图进行碰撞检测。
混合A星算法的思想比较简单,为了让入门者更容易理解,先介绍它的明星父母:探索树方法和A星算法。探索树方法也是一个比较通用的方法,有好多变种,最有名的就是RRT(快速探索随机树)方法。
A星算法也是非常有名,它其实也是生长一颗树,从起点开始不断向外探索,直到找到目标点停止生长。这么描述听起来好像跟Dijkstra方法一样,只不过A星方法更“聪明”。Dijkstra方法比较笨,它只知道傻傻地一个个生长最外面的所有节点。A星就知道哪些节点离目标更近,它会优先生长更近的节点,所以A星比Dijkstra方法快。
3 启发信息
启发信息(heuristics)非常重要,所以笔者不免多说几句。我们知道,A星算法是Dijkstra算法的升级版,那么A星算法比Dijkstra算法厉害在哪里呢?它厉害就厉害在使用了启发信息上。启发信息对于新手来说可能又是一个难理解的抽象概念。想象一下,人生中迷茫不知所措的时候别人给你的建议或者指点,这就是一种启发,让你找到出路。笔者大胆改编一下培根的名言:信息就是力量。当然,它既然叫启发那就意味着它提供的信息是有帮助的,如果有人给你指了一条错误的路,那就不叫启发了。所以说启发信息这个东西也不是随随便便就能设计出来的,多少有点技巧,这也是为什么常用的启发信息就那么几个。
启发信息对于混合A星算法同样至关重要,所以也是作者着重讨论的。混合A星算法使用了两种启发信息的组合,这两种启发一种“考虑机器人运动约束不考虑环境障碍物”,一种刚好相反“不考虑运动约束考虑障碍物”,如下图所示。这个“考虑运动约束不考虑障碍物”的启发信息就是大名鼎鼎的Reeds-Shepp曲线的长度,“不考虑运动约束考虑障碍物”的启发信息就是传统A星算法搜索到目标的路径的长度。混合A星算法选择两者的最大值作为最终的启发信息。为什么要使用这两种启发信息?作者是这样解释的,使用第一种(“考虑约束不考虑障碍物”)是为了防止机器人从错误的方向到达目标,作者说实际试验中使用这种启发比不使用的效率提高了一个数量级,看来是必不可少了。使用第二种(“考虑障碍物不考虑约束”)是为了防止在断头路或者U型障碍物里浪费时间。有没有同时既考虑运动约束也考虑障碍物的启发信息呢?目前还没有。

启发信息唯一的作用是给搜索算法提供指引、让算法更“聪明”,从而优先搜索有可能产生解的区域,不要在没必要的区域浪费时间。因为搜索的范围越多计算量越大效率越低,所以启发信息提供的指导越准确,最终算法的效率就越高。启发信息既然只是提供指导,那么它的计算量就不能太大,不能喧宾夺主,要是计算量太大就没有意义了,还是用人生迷茫的例子解释,别人提供建议太复杂了。启发信息最好是很快就能算出来的,例如A星使用的“到目标的欧式距离”,混合A星使用的Reeds-Shepp曲线的长度和A星得到的最优解不是非常快(跟欧式距离比),但是还是可以接受的。作者也发现了,Reeds-Shepp曲线和A星得到的最优解这两个启发信息既然不依赖障碍物,那就可以提前把所有离散节点的启发信息一次性都算好存起来,然后在搜索过程中直接查询,这种用空间换时间的策略也是一种解决办法。启发信息必须满足一些要求,最重要的一个要求是,不能高估,可以低估。低估的意思是启发信息的大小比实际解的值要小,即便你不知道实际解的值(比如最短距离),但是你可以估计它的下限。这里采用的两个启发信息都是低估,所以是合理的,从两个低估里取最大值当然还是低估,所以仍然是合理的。
作者还表示,这么定义的启发信息跟混合A星其实没什么关系(不依赖混合A星的状态)。也就是说,你可以用在其它搜索算法上(随便用不要钱),当然你要是找到更牛逼的启发信息也可以换成你自己的。所以,启发信息是个可以替换的模块,跟混合A星算法不是绑定的,你觉得好就用,有更好的也可以换,当然你要是彻底不用那混合A星算法就发挥不出它的威力了。
4 栅格
栅格就是对空间的一种划分,当然不是唯一的划分方式。栅格在混合A星方法中起到什么作用呢,或者说为什么要使用栅格?仅仅是为了继承A星的特点吗。如果是这样的话,那么栅格并不是必须的。为什么呢?因为每次的扩展都会产生有限的子节点,同理子节点的子节点也是有限个的,所以直接对子节点应用A星搜索的代价计算方法和选择方法就可以了。所以混合A星使用栅格真正的目的是限制节点对空间的覆盖。
4.1 共占栅格问题
在扩展子节点的时候,如果移动的距离比栅格的范围小,那就有可能与自己的父节点位于同一个栅格,下图展示了这种情况。
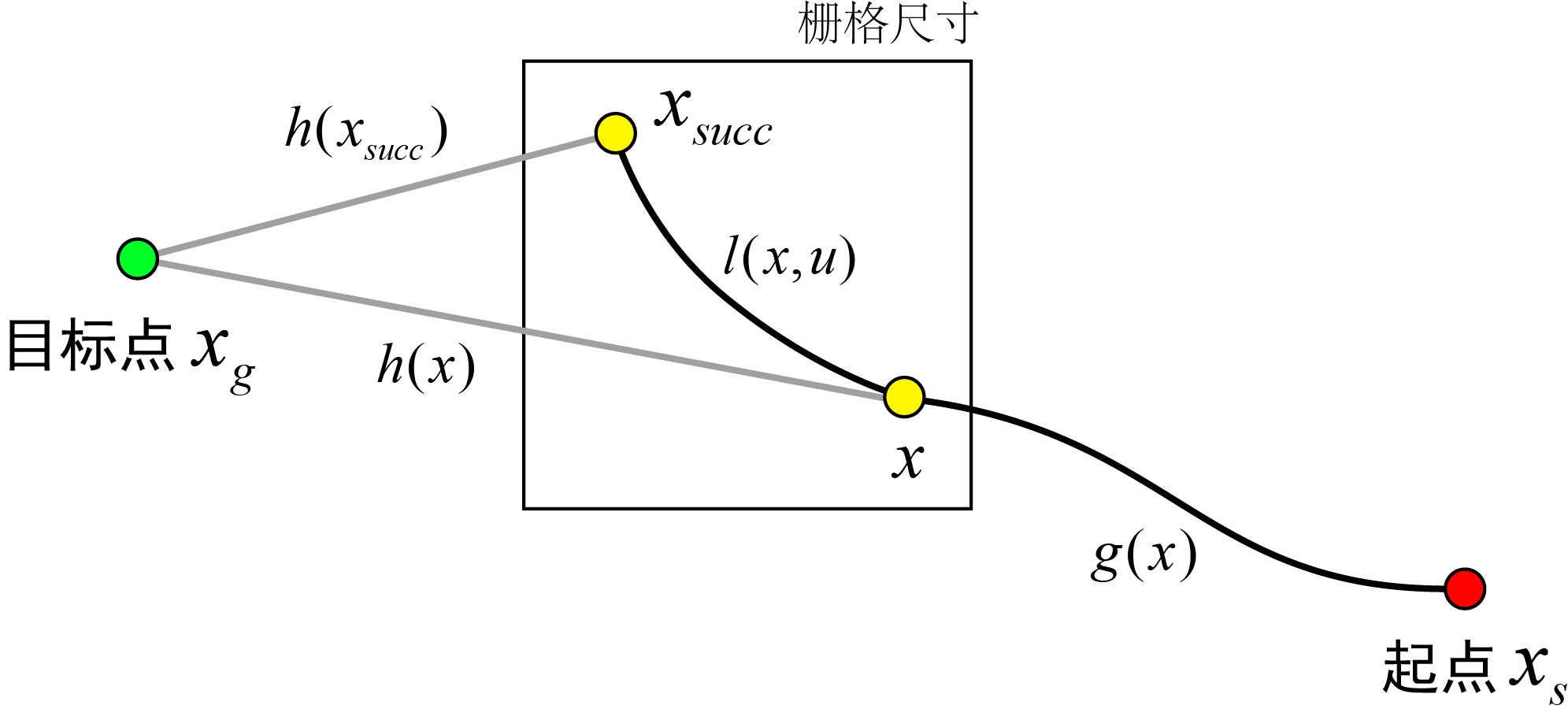
在这种情况下,子节点 x s u c c x_{succ} xsucc的代价值永远大于父节点 x x x的代价值,由于 A ∗ A^* A∗算法总是优先挑选代价值小的节点,所以后果就是子节点 x s u c c x_{succ} xsucc永远不会被选中。为什么会这样呢?还是看上图,假设父节点 x x x的已用代价是 g ( x ) g(x) g(x),它的启发代价是 h ( x ) h(x) h(x)。子节点扩展的代价是 l ( x , u ) l(x,u) l(x,u),子节点 x s u c c x_{succ} xsucc的启发代价是 h ( x s u c c ) h(x_{succ}) h(xsucc),启发函数总是具有consistent的性质(想知道为什么就得看 A ∗ A^* A∗算法的更深层原理了,这里面的水很深,二流作者写的普通博客是不会涉及的),因此满足三角形不等式:三角形任意两边长之和大于第三边长,所以有 l ( x , u ) + h ( x s u c c ) > h ( x ) l(x,u)+h(x_{succ})>h(x) l(x,u)+h(xsucc)>h(x),虽然扩展的边不是直线但是必然不会比直线短,所以不等式总是成立。又因为父节点 x x x的总代价 f ( x ) = g ( x ) + h ( x ) f(x)=g(x)+h(x) f(x)=g(x)+h(x),而子节点 x s u c c x_{succ} xsucc的总代价 f ( x s u c c ) = g ( x ) + l ( x , u ) + h ( x s u c c ) f(x_{succ})=g(x)+l(x,u)+h(x_{succ}) f(xsucc)=g(x)+l(x,u)+h(xsucc),所以很显然下式成立(当然前提是代价都是正数)。
g ( x ) + l ( x , u ) + h ( x s u c c ) > g ( x ) + h ( x ) g(x)+l(x,u)+h(x_{succ})>g(x)+h(x) g(x)+l(x,u)+h(xsucc)>g(x)+h(x)
为了解决这个问题,作者提出了放大父节点代价的思想,具体就是给父节点的总代价加一个常数。这个常数记为tieBreaker(“tie break”翻译为“打破僵局”),它是个正数。如果 f ( x s u c c ) < f ( x ) + t i e B r e a k e r f(x_{succ})<f(x)+tieBreaker f(xsucc)<f(x)+tieBreaker,就会选择子节点扩展,否则就不要子节点。
如果子节点与父节点占据同一个栅格,那就不能把再子节点的前向指针指向父节点,而应该换成爷爷节点(也就是父节点的父节点) 。因为子节点会覆盖掉nodes3D中的父节点:nodes3D[iSucc] = *nSucc; 路径到这里就无法回溯了,因为虽然父节点的指针还在但是父节点本身已经被覆盖掉不存在了。此时递归函数tracePath会进入死循环,电脑内存会被耗尽。
但是如果子节点的前向指针指向爷爷节点可能又会导致另一个问题,中间会空出一部分,如下图所示。因为运动约束,每个节点都是从唯一的父节点通过运动方程递推生成的,直接将前向指针指向爷爷节点会导致这段路径不符合机器人约束,因为你改变了出发点。

在百度的无人驾驶项目中的混合A*代码中,直接将扩展的距离设置成了栅格的对角线,如下。因为对角线是一个栅格能容纳的最大距离(仅对直线来说),这样便可以保证子节点与父节点不会占据一个栅格。也因为采用了这样的设计,百度没有考虑这种共占的情况,所以也没有进行判断。
double arc = std::sqrt(2) * xy_grid_resolution_;
5 算法特点
需要设置的参数有:
机器人控制量采样值
空间离散的分辨率。空间离散的分辨率如何选择呢?机器人每次运动的距离如何设置呢,显然与空间分辨率有关,如果分辨率太小,计算量就太大;如果分辨率太大,机器人运动距离太小,那么每次生成的节点都在一个栅格里,探索树就没办法扩展。
启发函数如何选取?
论文中讨论了几种启发函数,一种是考虑约束但不考虑障碍物的RS曲线的长度,一种是不考虑约束但是考虑障碍物的普通A星算法搜索出来的路径长度。
● 混合A星适用于什么场景?
存在障碍物的环境,低速、有运动约束的机器人或无人车。在无人驾驶上具体可以用于停车场的自动泊车的路径规划。
这里的关键词是“约束”,如果你看到有人把混合A星用在差速机器人或者全向机器人上,那你就可以得出判断:使用者不懂混合A星。因为,如果机器人没有运动约束,那么完全没有必要用混合A星。
● 混合A星的缺点是什么?
知己知彼才能用好,混合A星一个比较大的问题是,它输出的路径质量一般比较差,这里差的意思是指路径包含一些不必要的拐弯或者倒车动作,这就是为什么一般在混合A星之后再优化一下,或者把混合A星当成一个给优化算法提供初始路径的子模块,而不是单独使用。
还有,混合A星也是一种依赖分辨率的方法,受制于分辨率,它要么有可能找不到解,要么花的时间太多,实时性不好。
6 算法改进
1 双向探索,即不仅在起点向终点扩展,也从终点向起点扩展。这在终点障碍物密集时比较有效。
2 变分辨率,不使用均匀一致的分辨率,在障碍物附近使用较高的分辨率,远离障碍物时使用低分辨率,减少不必要的计算。
3 轨迹片段仿真使用连续变化的控制量。
7 算法实现
混合A星算法实现采用的是karl kurzer的版本,下载和编译过程如下。新建并运行脚本即可实现傻瓜式一键安装,非常简单。
#!/bin/bash
mkdir -p ~/HybridAStar/src
cd ~/HybridAStar/src
git clone https://github.com/karlkurzer/path_planner.git
cd ..
catkin_make
source devel/setup.bash
rospack profile
roslaunch hybrid_astar manual.launch
7.1 搜索逻辑
扩展的子节点每次都要判断是不是在Closed集合里,如果在说明其所在的栅格已经被探索过了,这个子节点就没有价值了,应该扔掉。那一个节点什么时候应该被添加到Closed集合里呢,与A*一样,在它所有的子节点都生成完以后就会被它添加到Closed集合中。
7.2 障碍物建模
几乎所有的路径规划算法都需要与环境中的障碍物打交道,所以对障碍物的表示或者说建模是必不可少的一步的。目前,常用的障碍物表示方法无外乎离散栅格方法和几何方法。
7.2.1 占据栅格地图
机器人感知外部世界的一种方式是通过激光雷达,激光雷达输出的点代表环境中障碍物的分布。但是,激光雷达输出的数据是一个个离散的点(的坐标),而且点的数量又特别多。规划算法一般无法使用这样的原始数据,因此需要把点做一个转换。一种方法是将环境分割成很多小栅格,栅格中的数值表示是否存在障碍物,判断是否存在的依据就是根据激光点的分布情况。作为一种常用的方法,ROS就提供了二维占据栅格地图的表示方法 —— OccupancyGrid。
由于在无人驾驶项目中,一般使用多线数的激光雷达。为了把三维激光雷达的原始点云转换成ROS中的占据栅格地图,笔者使用了这个开源包:velodyne_height_map_occupancy_map。这个包的原理很简单,就是统计落在每个小栅格里激光点的垂直方向(z轴)的坐标,如果垂直坐标差值超过一个阈值(比如15厘米)就认为存在障碍物。这样做的目的是滤掉那些落在地面上的激光点。下图是激光雷达点云和生成的占据栅格地图,地图分辨率是0.2米。也因为这是一种二维地图表示方法,没有考虑障碍物在垂直方向上的分布,所以相当于是向地面的投影。如果障碍物在高度方向上超出了机器人的最大高度可以无视,这个可以在程序中很容易通过添加判断的方式进行修改。

在修改过程中,笔者犯了一个小错误,如果不检查数组的上限就往里填充就会报以下错误,这是因为越界访问了分配的内存导致的,所以教训是一定要提前检查。
malloc.c:2401: sysmalloc: Assertion `(old_top == initial_top (av) && old_size == 0) || ((unsigned long) (old_size) >= MINSIZE && prev_inuse (old_top) && ((unsigned long) old_end & (pagesize - 1)) == 0)’ failed

这个地图的原点也要修改。nav_msgs/OccupancyGrid消息中的nav_msgs/MapMetaData字段中的origin存储了占据栅格地图原点在全局世界坐标系中的位置。这个地图是随着机器人移动的,所以原点要搞清楚。需要注意的是,占据栅格地图的默认原点不在它自己的几何中心,而是左下角(lower left corner),因为地图从左下角开始编号,左下角的栅格坐标就是(0,0)。通常将激光雷达作为地图的中心或者中心附近,因此需要更改原点坐标,做一个偏移。这只需要修改origin中的值即可。
当然,地图原点改变了,在后续碰撞检测环节也要修改。对应的文件是CollisionDetection.cpp中的configurationTest,因为这里是查询栅格点是否被占据的。如果地图只是被平移了,那么只要修改XY坐标即可,如下。
float map_lowerleft_x = grid->info.origin.position.x;
float map_lowerleft_y = grid->info.origin.position.y;
float map_resolution_ = grid->info.resolution;
int X = (int)((x-map_lowerleft_x) / map_resolution_);
int Y = (int)((y-map_lowerleft_y) / map_resolution_);
7.2.2 碰撞检测
碰撞检测方法完全取决于障碍物的表示方法。需要提醒读者的是,碰撞检测是路径规划中非常耗时的一个步骤,所以在选择障碍物的表示方法的时候要慎重。
如果选择占据栅格地图这种离散的方法,那么相应的机器人也要进行离散。可以将机器人的外形(例如长方形)分成一个个小栅格,每个栅格依次判断是否与占据栅格相交叉,如果有一个交叉在那就意味着发生了碰撞。
首先,如何从机器人的外形得到它的离散栅格呢?作者使用的是论文《A Fast Voxel Traversal Algorithm for Ray Tracing》中的方法,代码在fast_voxel_traversal。该方法比古老的Bresenham方法更快。一个展示动画在这里:点击我。
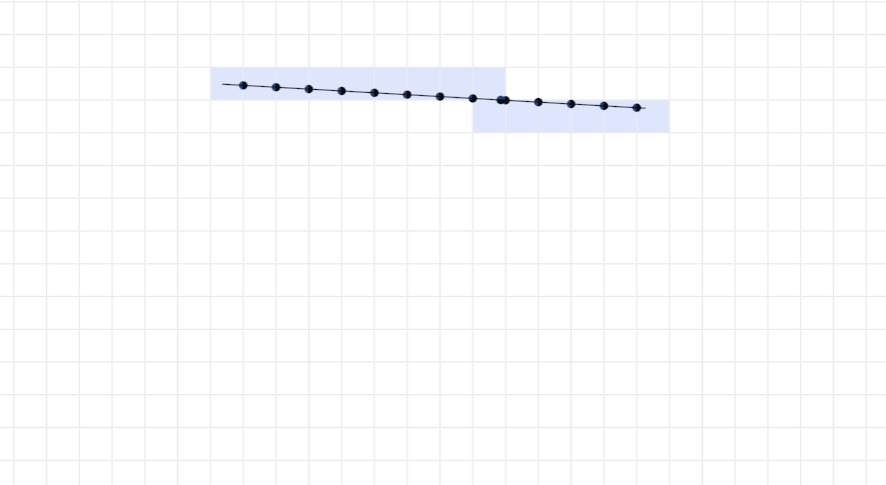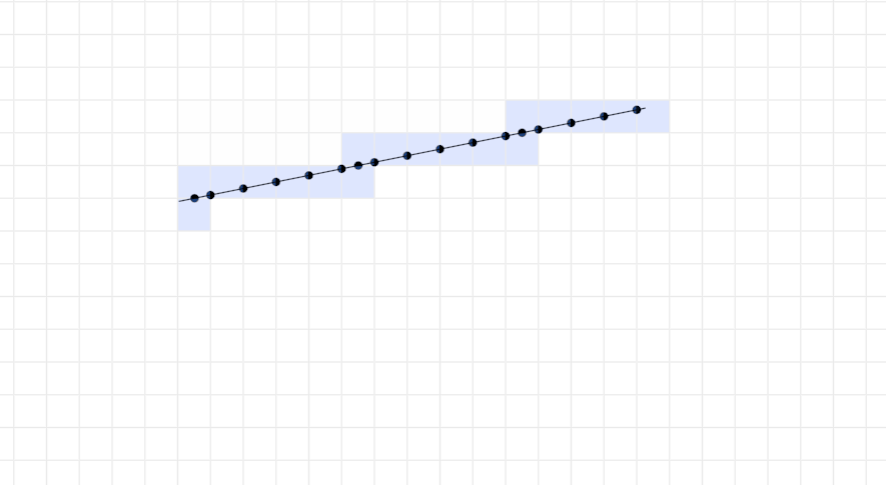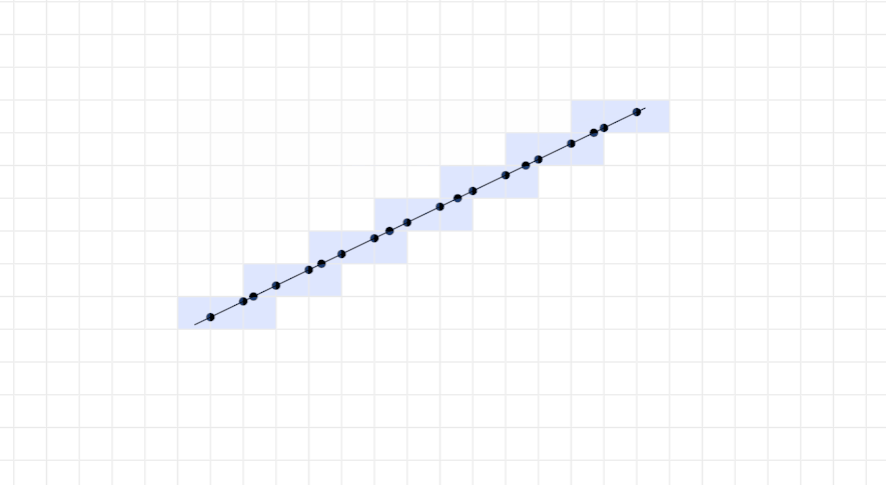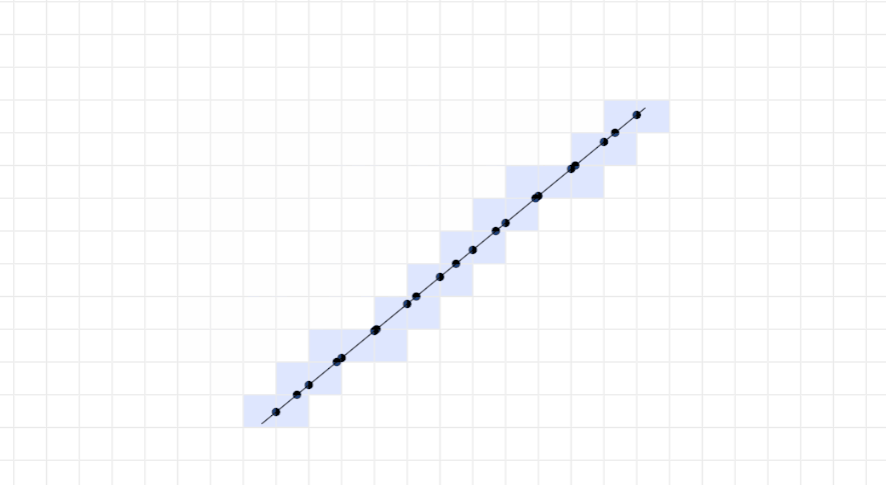

如果把机器人放在占据栅格地图中,它每移动一下,显然对应的栅格坐标就要更新一下。如果我们能提取计算出它在不同位置和姿态占据的栅格,那么在碰撞检测时就只需要判断栅格交叉就行了。因为机器人平移时,只需要对机器人所有的栅格加上或者减去一定偏移即可这样的计算很快,所以真正需要计算的是机器人在转动时。因此,作者对机器人的转动角度进行了离散化,提前计算出所有角度下对应的栅格,这个是在collisionLookup函数(lookup.h)中做的。
作为对比,百度Apollo无人驾驶项目中的混合A*则采用了几何多边形的障碍物表示方法。多边形方法的好处是能够更准确的表示物体的轮廓。
7.3 代码优化
源程序有几个严重的缺点,首先分辨率定义混乱。A* 搜索有自己的离散分辨率,而碰撞检测采用占据栅格法,栅格也有自己的分辨率,一般这两个是不一样的。而源程序定义为一样的,这显然不合理。其次,连接目标使用的是Dubins曲线,这对无人车来说显然是不合理的。修改后的运行效果如下图所示,其中黑色物体表示障碍物,红色箭头表示起始的无人车位姿,绿色的则表示目标位姿。可见,大多数情况能得到比较好的路径,但是有时得到的路径质量也很差,有时甚至失败(侧方位停车的时候)。例子中使用的地图分辨率是10cm,A* 搜索分辨率是1m,角度离散为144个(2.5°)。

原文件使用的全局坐标系名称是path,我们改成更常用的map。在path.h文件里修改,如下:
path.header.frame_id = "map";
发布的路径话题名称是/path,路径在rviz中显示没有问题,但是如果打印出来就会发现消息头多了一个,如下图所示。原因是 path.cpp 文件中的Path::clear()函数里的path.poses.clear()语句导致,把它放到下面的Path::updatePath函数中即可。

karl kurzer的程序中使用的是原生指针,百度则使用了智能指针std::shared_ptr。当然,尽量使用智能指针,虽然它占用内存更多。
7.4 前进后退
混合A星算法输出的是一条路径,该路径由一连串离散的坐标点组成。如果你想在路径基础上添加速度构成一条轨迹,可以这么做:前进时设置速度为正值,后退时设置速度为负值,在前进和后退相接的点设置速度为0。这样做需要判断什么时候是前进,什么时候是后退。判断方法是计算机器人航向角 θ r \theta_r θr与相邻路径点构成的向量 θ p \theta_p θp的夹角 Δ θ \Delta\theta Δθ。涉及到角度要小心,需要保证角度的范围。为此定义正则函数modpipi,其功能是将角度转换为 ( − π , π ) (-\pi,\pi) (−π,π)的范围内。计算相邻路径点向量与 x x x轴的角度需要利用atan2函数,使用这个函数也要小心。注意,atan2(0,0)=0。原程序有一个小BUG,即可能存在两个坐标完全一样的点,原因是在做Dubins曲线拼接时没有考虑重叠。为此,先对路径预处理,剔除相邻路径点 x y xy xy坐标完全相同的其中一个点。这也是
7.5 话题发布path.cpp
规划出来的路径通过path.cpp这个文件发布出来。这个文件中的命名雷同,看起来非常累,比如文件名叫path,类的名称叫Path,话题名也叫path,坐标系也叫path,这是一种混乱的命名方式。
这里我们最感兴趣的是发布路径的消息:
nav_msgs::Path path;
负责向里填充数据的是addSegment函数
void Path::addSegment(const Node3D& node)
planner.h里定义了碰撞检测
CollisionDetection configurationSpace
然后把加载的地图赋值给它,
configurationSpace.updateGrid(map);