H264参数SPS(序列参数集)和PPS(图像参数集)说明
https://blog.csdn.net/heanyu/article/details/6191576
https://blog.csdn.net/H514434485/article/details/51063069
H.264码流第一个 NALU是 SPS(序列参数集Sequence Parameter Set)
对应H264标准文档 7.3.2.1 序列参数集的语法进行解析
H.264码流第二个 NALU是 PPS(图像参数集Picture Parameter Set)
对应H264标准文档 7.3.2.2 序列参数集的语法进行解析
H.264码流第三个 NALU 是 IDR(即时解码器刷新)
对应H264标准文档 7.3.3 序列参数集的语法进行解析
H2.64中I帧和IDR帧的区别
I和IDR帧都是使用帧内预测的。它们都是同一个东西而已,在编码和解码中为了方便,要首个I帧和其他I帧区别开,所以才把第一个首个I帧叫IDR,这样就方便控制编码和解码流程。IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始,重新算一个新的序列开始编码。而I帧不具有随机访问的能力,这个功能是由IDR承担,IDR会导致DPB(参考帧列表——这是关键所在)清空,而I不会。IDR图像一定是I图像,但I图像不一定是IDR图像。一个序列中可以有很多的I图像,I图像之后的图像可以引用I图像之间的图像做运动参考。一个序列中可以有很多的I图像,I图像之后的图象可以引用I图像之间的图像做运动参考。
对于IDR帧来说,在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容,与此相反,对于普通的I-帧来说,位于其之后的B-和P-帧可以引用位于普通I-帧之前的I-帧。从随机存取的视频流中,播放器永远可以从一个IDR帧播放,因为在它之后没有任何帧引用之前的帧。但是,不能在一个没有IDR帧的视频中从任意点开始播放,因为后面的帧总是会引用前面的帧。
在分离H.264码流的时候,直接存储AVPacket后的文件可能是不能播放的。
如果视音频复用格式是TS(MPEG2 Transport Stream),直接存储后的文件是可以播放的。
复用格式是FLV,MP4则不行。
经过长时间资料搜索发现,FLV,MP4这些属于“特殊容器”,需要经过以下处理才能得到可播放的H.264码流:
1.分离某些封装格式(例如MP4/FLV/MKV等)中的H.264的时候,需要首先写入SPS和PPS,否则会导致分离出来的数据没有SPS、PPS而无法播放。H.264码流的SPS和PPS信息存储在AVCodecContext结构体的extradata中。需要使用ffmpeg中名称为“h264_mp4toannexb”的bitstream filter(比特流过滤器)处理。有两种处理方式:
(1)使用bitstream filter处理每个AVPacket(简单)
把每个AVPacket中的数据(data字段)经过bitstream filter“过滤”一遍。关键函数是av_bitstream_filter_filter()。示例代码如下
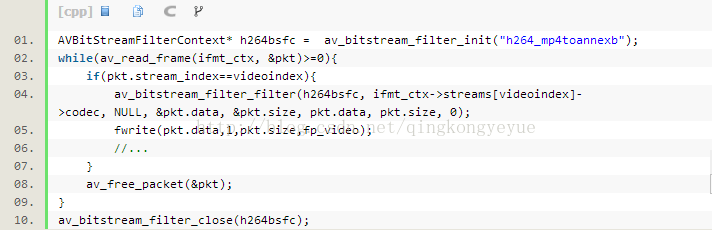
上述代码中,把av_bitstream_filter_filter()的输入数据和输出数据(分别对应第4,5,6,7个参数)都设置成AVPacket的data字段就可以了。
需要注意的是bitstream filter需要初始化和销毁,分别通过函数av_bitstream_filter_init()和av_bitstream_filter_close()。
经过上述代码处理之后,AVPacket中的数据有如下变化:
*每个AVPacket的data添加了H.264的NALU的起始码{0,0,0,1}
*每个IDR帧数据前面添加了SPS和PPS
(2)手工添加SPS,PPS(稍微复杂)
将AVCodecContext的extradata数据经过bitstream filter处理之后得到SPS、PPS,拷贝至每个IDR帧之前。下面代码示例了写入SPS、PPS的过程。通过查看FFMPEG源代码我们发现,AVPacket中的数据起始处没有分隔符(0x00000001), 也不是0x65、0x67、0x68、0x41等字节,所以可以AVPacket肯定这不是标准的nalu。其实,AVPacket前4个字表示的是nalu的长度,从第5个字节开始才是nalu的数据。所以直接将AVPacket前4个字节替换为0x00000001即可得到标准的nalu数据。
具体代码如下:
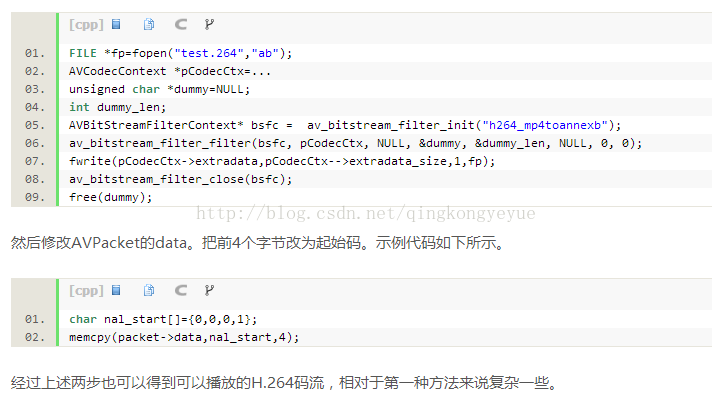
拷贝4个字节(0x00000001)
当封装格式为MPEG2TS的时候,不存在上述问题。
2、SPS和PPS
SDP中的H.264的SPS和PPS串,包含了初始化H.264解码器所需要的信息参数,包括编码所用的profile,level,图像的宽和高,deblock滤波器等。
3、相关函数介绍
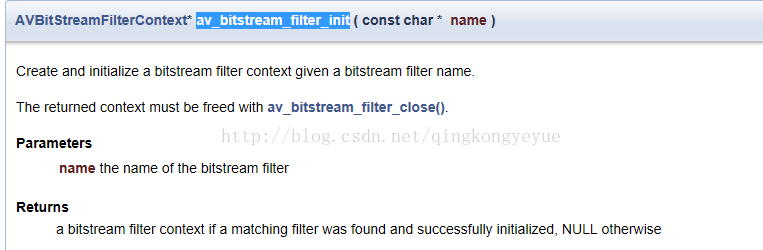
(1)av_bitstream_filter_init
输入参数:比特流过滤器的名字
输出参数:根据比特流过滤器的创建并初始化一个比特流过滤器的上下文。
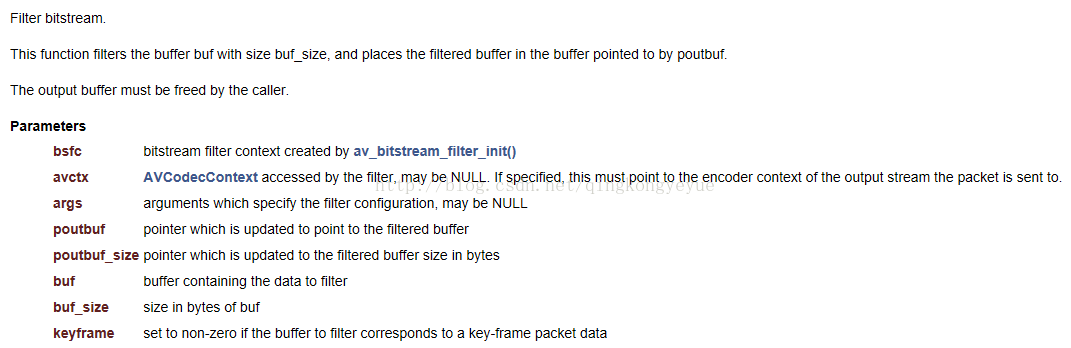
(2)av_bitstream_filter_filter
参数1:比特流过滤器的上下文
参数2:avcodeccontext输出流的编码器上下文.。
参数3:指定筛选器配置的参数,可能为空.
参数4:指针被更新以指向过滤缓冲区.
参数5:指针以字节形式更新到已过滤的缓冲区大小.
参数6:包含数据到过滤器的缓冲区
参数7:在字节缓冲区大小
参数8:设置为非零,如果缓冲区对应于一个关键帧数据包


1、学习路线
step1、初步了解h264,了解h264数据帧分类和识别
step2、h264语法相关算法解析,这里对理解h264的视频帧很重要。通俗的说h264数据定义是由一组Bit组成,但是某个字段不是固定专有几个bit,它是根据其值通过算法转义保存。
step3、sps、pps帧语法定义
2、h264简介
在H.264/AVC视频编码标准中,整个系统框架被分为了两个层面:视频编码层面(VCL)和网络抽象层面(NAL)。其中,前者负责有效表示视频数据的内容,而后者则负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。NAL占一个字节。
NAL单元(NALU):NAL的基本语法结构,它包含一个字节的头信息和一系列来自VCL的称为原始字节序列载荷(RBSP)的字节流。 数据流是储存在介质上时: 每个NALU 前添加起始码:0x00000001(或者0x000001),用来指示一个 NALU的起始和终止位置。我们平时的每帧数据就是一个NAL单元(SPS与PPS除外)。
编码器将每个NAL各自独立、完整地放入一个分组,因为分组都有头部,解码器可以方便地检测出NAL的分界,并依次取出NAL进行解码。每个NAL前有一个起始码 0x00 00 01(或者0x00 00 00 01),解码器检测每个起始码,作为一个NAL的起始标识,当检测到下一个起始码时,当前NAL结束。同时H.264规定,当检测到0x000000时,也可以表征当前NAL的结束。那么NAL中数据出现0x000001或0x000000时怎么办?H.264引入了防止竞争机制,如果编码器检测到NAL数据存在0x000001或0x000000时,编码器会在最后个字节前插入一个新的字节0x03,这样:
0x000000->0x00000300
0x000001->0x00000301
0x000002->0x00000302
0x000003->0x00000303
解码器检测到0x000003时,把03抛弃,恢复原始数据(脱壳操作)。解码器在解码时,首先逐个字节读取NAL的数据,统计NAL的长度,然后再开始解码。
NALU头由一个字节组成, 它的语法如下:
+---------------+
|0|1|2|3|4|5|6|7|
+-+-+-+-+-+-+-+-+
|F|NRI| Type |
+---------------+
F: 1 个比特.
forbidden_zero_bit. 在 H.264 规范中规定了这一位必须为 0.
NRI: 2 个比特.
nal_ref_idc. 取 00 ~ 11, 似乎指示这个 NALU 的重要性, 如 00 的 NALU 解码器可以丢弃它而不影响图像的回放. 不过一般情况下不太关心
这个属性.
Type: 5 个比特.
nal_unit_type. 这个 NALU 单元的类型. 简述如下:
0 没有定义
1 一个非IDR图像的编码条带 (bp帧)
slice_layer_without_partitioning_rbsp( )
2 编码条带数据分割块A
slice_data_partition_a_layer_rbsp( )
3 编码条带数据分割块B
slice_data_partition_b_layer_rbsp( )
4 编码条带数据分割块C
slice_data_partition_c_layer_rbsp( )
5 IDR图像的编码条带 (i帧)
slice_layer_without_partitioning_rbsp( )
6 辅助增强信息 (SEI)
sei_rbsp( )
7 序列参数集 (sps帧)
seq_parameter_set_rbsp( )
8 图像参数集
pic_parameter_set_rbsp( pps帧)
9 访问单元分隔符
access_unit_delimiter_rbsp( )
10 序列结尾
end_of_seq_rbsp( )
11 流结尾
end_of_stream_rbsp( )
12 填充数据
filler_data_rbsp( )
13 序列参数集扩展
seq_parameter_set_extension_rbsp( )
14...18 保留
19 未分割的辅助编码图像的编码条带
slice_layer_without_partitioning_rbsp( )
20...23 保留
24 STAP-A 单一时间的组合包
25 STAP-B 单一时间的组合包
26 MTAP16 多个时间的组合包
27 MTAP24 多个时间的组合包
28 FU-A 分片的单元
29 FU-B 分片的单元
30-31 没有定义
当遇到 00 00 00 01 67表示sps帧
当遇到 00 00 00 01 68 表示pps帧
3、h264语法相关算法解析
1、无符号指数哥伦布熵编码
1.1 编码过程
1、将待编码的数加1转换为最小的二进制序列(假设一共M位);
2、此二进制序列前面补充M-1个0;
3、enjoy!
1.1.1 示例
对 4 进行无符号指数哥伦布熵编码
1、将4加1(为5)转换为最小的二进制序列即 101 (此是M=3)
2、此二进制序列前面补充M-1即两个0
3、得出的4的无符号指数哥伦布熵编码的序列为 00101
1.2 解码过程
1、获取二进制序列开头连续的N个0
2、读取之后的N+1位的值,假设为X
3、X-1获取解码后的值
1.2.1 示例
如对 00101进行无符号指数哥伦布熵解码
1、获取开头连续的N个0, 此时N = 2
2、再向后读取N+1位的值,即 101,为5
3、 5 - 1 =4 获取其解码后码值,enjoy!
1.3 其他
注意0的无符号指数哥伦布熵编码的二进制序列为 1
2 有符号指数哥伦布熵编码
2.1 编码过程
1、将待编码的数的绝对值转换为最小的二进制序列(假设一共M位)
2、在此二进制序列后补充一位符号位0表示正,1表示负
3、在此二进制序列前补充M个0
4、enjoy
2.1.1 示例1
如对4进行有符号指数哥伦布熵编码
1、4的绝对值转为最小二进制序列,即 100 (此时M = 3)
2、后面补充符号位,0 即 1000
3、前面补充M个0, 即 0001000
4、enjoy
2.1.2 示例2
如对-15进行有符号指数哥伦布熵编码
1、-7的绝对值转为最小二进制序列,即 1111 (此时M = 4)
2、后面补充符号位,1,即 11111
3、前面补充M个0,即 000011111
4、enjoy
2.2 解码过程
1、获取二进制序列开头连续的N个0
2、读取之后的N位的值,假设为X
3、获取最后1位符号位
4、获取解码后码值
2.2.1 示例1
如对二进制序列 0001000 进行有符号指数哥伦布熵解码
1、获取开头连续的N个0, 此时N = 3
2、再获取N为数值,即 100 即为4
3、获取最后的符号位,0,即为正值
4、故此序列解码后的码值为4
2.2.2 示例2
如对二进制序列 000011111 进行有符号指数哥伦布熵解码
1、获取开头连续的N个0, 此时N = 4
2、再获取N为数值,即 1111 即为15
3、获取最后的符号位,1,即为负值
4、故此序列解码后的码值为-15
4、sps语法
5、pps语法
---------------------
作者:yuanbinquan
来源:CSDN
原文:https://blog.csdn.net/yuanbinquan/article/details/60148345?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!