小孢子的神奇之旅-如何阅读MindSpore报错信息(2)

先回忆下自修孢问题解决的三步巅峰论,“1)理解问题原因 2)找到问题出在哪里 3)改了”,我们在上篇文章应用三步论解决了MindSpore Primitive算子执行的一个小问题,如果你读了MindSpore官网对算子分类的介绍,你会只知道还有一类nn算子。
我们看下MindSpore官网对这两种算子的解释:
• Primitive算子是开放给用户的最低阶算子接口,一个Primitive算子对应一个原语,它封装了底层的Ascend、GPU、AICPU、CPU等多种算子的具体实现,为用户提供基础算子能力。
• nn算子是对低阶API的封装,主要包括卷积层算子、池化层算子、损失函数、优化器等。还提供了部分与Primitive算子同名的接口,主要作用是对Primitive算子进行进一步封装,为用户提供更友好的API,当nn算子功能满足用户的要求时可以直接使用nn算子,而当nn算子功能无法满足用户特定要求时可以使用低阶的Primitive算子实现特定的功能
官网认真严肃的说明了两种算子的区别,孢子尝试用自带的歪风格来做一些自己的解读,见下图:

• Primitive算子可以认为是一些基础调料,你可以根据自己的口味按需组合出让自己满意的味道。
• nn算子则是满足大众口味调好的蘸料,也就是nn算子是由一个或者多个Primitive算子组合而成,你自己不用费脑筋调味,直接用就完了。
即nn算子是由Primitive组成的,提供特定功能的api,但如果你觉得这个api不能满足你的要求,你可以自己用Primitive算子来组合实现,例如:你吃火锅非得用芥辣+花椒做蘸料才爽快,估计你是找不到有这种成品蘸料了,就需要你自己来配置这种蘸料。所以选择哪种API,还是要从你的需求出发。
上次我们分析了Primitive算子的报错信息,本次来探索下nn算子的报错有没有啥不同。老规矩,没有困难制造困难,我们先来写段错误代码。
错误代码示例如下:
import numpy as np
import mindspore
import mindspore.nn as nn
from mindspore import context, Tensorx = Tensor(np.array([[[[1, 2, 3, 4], [3, 4, 5, 6]]]]), mindspore.float32)
net = nn.Moments(axis=5, keep_dims=False)
output = net(x)
print(output)接下来是见证问题的时刻:
[ERROR] ANALYZER(7282,7fc2f86b1740,python):2021-12-02-10:53:10.506.281 [mindspore/ccsrc/pipeline/jit/static_analysis/async_eval_result.cc:84] HandleException] Exception happened, check the information as below.
The function call stack (See file '/root/mindspore_test/rank_0/om/analyze_fail.dat' for more details):
# 0 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1003)
if tensor_dtype == mstype.float16:
# 1 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1007)
if not self.keep_dims:
# 2 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1005)
mean = self.reduce_mean(x, self.axis)
^Traceback (most recent call last):
File "test1.py", line 26, in <module>
output = net(x)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/cell.py", line 479, in __call__
out = self.compile_and_run(*args)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/cell.py", line 802, in compile_and_run
self.compile(*inputs)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/cell.py", line 789, in compile
_cell_graph_executor.compile(self, *inputs, phase=self.phase, auto_parallel_mode=self._auto_parallel_mode)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/common/api.py", line 661, in compile
result = self._graph_executor.compile(obj, args_list, phase, use_vm)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/ops/operations/math_ops.py", line 498, in __infer__
return self.do_infer(input_x, axis)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/ops/operations/math_ops.py", line 467, in do_infer
out_shape = _infer_shape_reduce(input_shp, axis_v, self.keep_dims, self.name)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/ops/operations/math_ops.py", line 44, in _infer_shape_reduce
reduce_one_axis(axis)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/ops/operations/math_ops.py", line 34, in reduce_one_axis
validator.check_int_range(one_axis, -dim, dim, Rel.INC_LEFT, 'axis', prim_name)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/_checkparam.py", line 413, in check_int_range
return check_number_range(arg_value, lower_limit, upper_limit, rel, int, arg_name, prim_name)
File "/root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/_checkparam.py", line 210, in check_number_range
arg_name, prim_name, rel_str, arg_value, type(arg_value).__name__))
ValueError: `axis` in `ReduceMean` should be in range of [-4, 4), but got 5.000e+00 with type `int`.报错信息似乎比上次的多了一些,我们依然用三步论来看这个问题。
第一步:阅读问题描述,理解问题原因。
回忆下上篇帖子,我们先找到python抛出的异常信息。在MindSpore打印的信息比较多的时候,如何查找python抛出的异常信息呢?这里的技巧是查找关键字“Traceback (most recent call last):”到“xxxError(不同错误类型会有不同的描述,例如:ValueError):……”之间的记录,如下:
Traceback (most recent call last): # 堆栈信息关键字
…… # 堆栈信息
ValueError: …… # 错误描述关键字基于上边的技巧,我们找到本次的问题描述如下:
ValueError: `axis` in `ReduceMean` should be in range of [-4, 4), but got 5.000e+00 with type `int`.从描述看是ReduceMean这个算子的参数axis是5,没在[-4, 4)范围内。从官网描述可见ReduceMean是个ops接口(即是一个Primitive算子)。
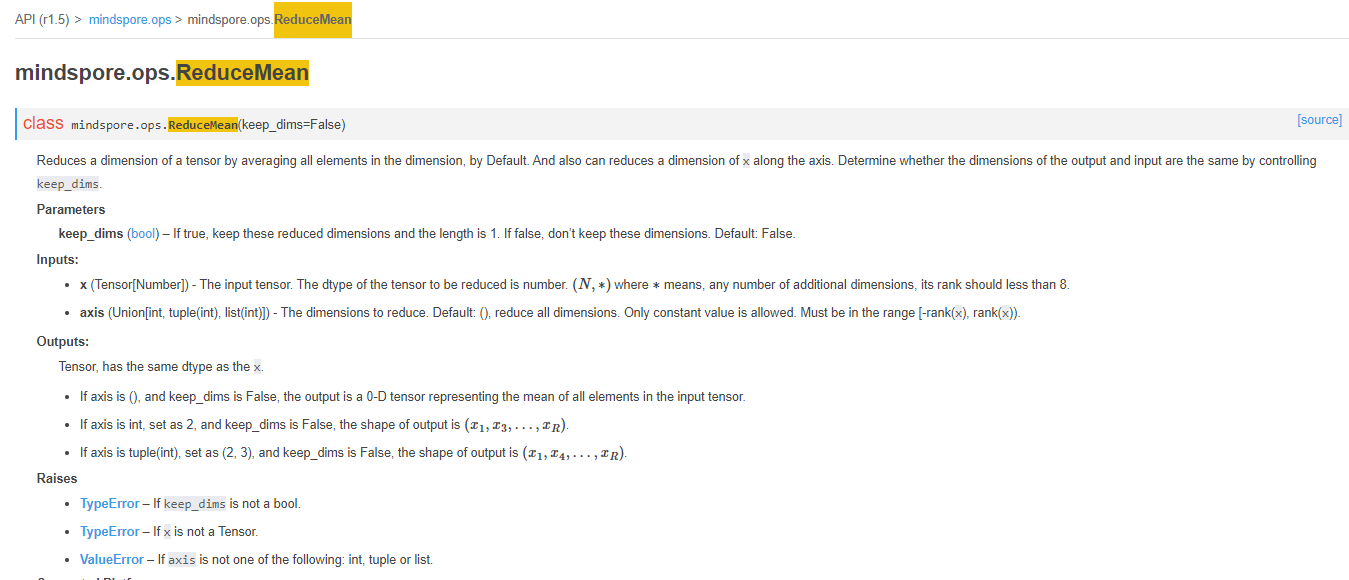
第二步:阅读堆栈信息,找到问题在哪里(具体的代码行)。
这一步我们要在代码中找到算子的位置,基于堆栈可以找到output = net(x)这行代码
Traceback (most recent call last):
File "test1.py", line 26, in <module>
output = net(x)
……继续查看代码,net是由Moments算子赋值而来。这里就有点意思了,貌似这个报错不讲武德,不按照套路打呀。代码里并没有找到ReduceMean这个算子,只有一个Moments算子,它们是什么关系呢?
……
net = nn.Moments(axis=5, keep_dims=False) # nn.Moment赋值给net
output = net(x)
……这就是前面提到的蘸料与基础调料的关系了,这里的ReduceMean是组成nn算子Moments的元素,Moments传入的参数axis没有在正确范围内,导致了ReduceMean执行出错。
第三步:解决问题,达到人生巅峰。
知道了原因,修复这个问题也就简单了,修改axis到正确范围,问题就解决了。
import numpy as np
import mindspore
import mindspore.nn as nn
from mindspore import context, Tensorx = Tensor(np.array([[[[1, 2, 3, 4], [3, 4, 5, 6]]]]), mindspore.float32)
net = nn.Moments(axis=1, keep_dims=False) #修改axis到正确范围
output = net(x)
print(output)回顾下本次冲击巅峰的过程,主要在Primitive(ReduceMean)->nn(Moments)映射的地方爬了个坡,其他过程根据已掌握的技能还算顺利。本次的经验告诉我们,一些问题的解决需要你翘起脚往里边看看,你就豁然开朗了。
这里我们可以稍稍看下Moments的代码,Moments是一个继承了Cell的子类,也确实如我们分析,用到了ReduceMean算子。
class Moments(Cell):
......
def __init__(self, axis=None, keep_dims=None):
......
self.reduce_mean = P.ReduceMean(keep_dims=True)
......
def construct(self, x):
......
mean = self.reduce_mean(x, self.axis)
......
return mean, variancehttps://gitee.com/mindspore/mindspore/blob/master/mindspore/nn/layer/math.py
不过这里Cell又是个啥?孢子先挖个坑下回填吧。
今天的故事是不是就结束了?等下,下边这段报错信息又是个啥?心细的同学应该发现了本次的报错信息有如下明显的不同。出现了一个叫做“The function call stack”的堆栈信息。
The function call stack (See file '/root/mindspore_test/rank_0/om/analyze_fail.dat' for more details):
# 0 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1003)
if tensor_dtype == mstype.float16:
# 1 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1007) #####更新
if not self.keep_dims:
# 2 In file /root/anaconda3/envs/test/lib/python3.7/site-packages/mindspore/nn/layer/math.py(1005)
mean = self.reduce_mean(x, self.axis)
^这个……静态图模式您听说过吗?…… 又是一个新的故事,继续刨坑吧。
自修孢金句“翘起脚往里瞧瞧,风景独好”