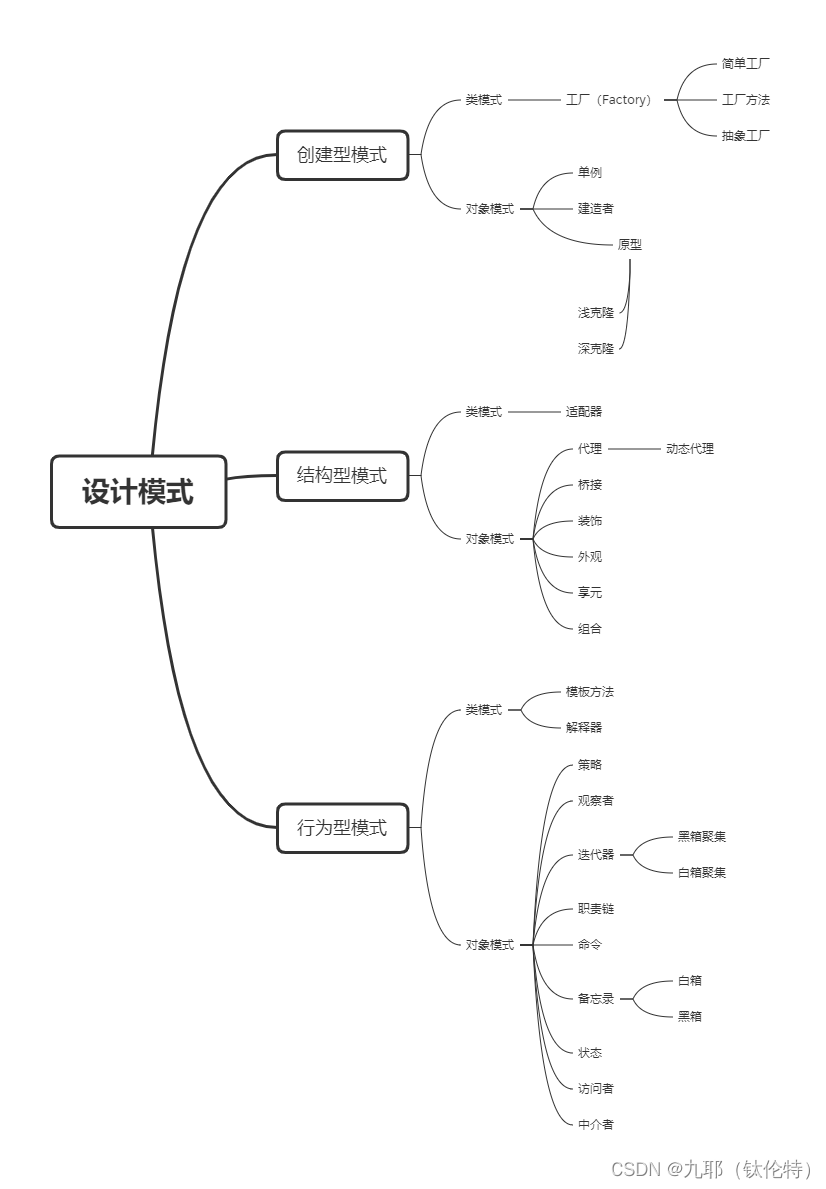
因为之前有学习过c11的并发库,最近在搞项目准备复习,本节开始就重温一下这块内容打算连着写上几篇博客去记录一下..
题外话get几个概念
1.进程是资源分配的基本单位,线程是调度的基本单位,注意基本二字,这并不意味着进程不能调度,进程当然可以调度;线程是基本的调度单位,只要达到线程水平就可以被调度了
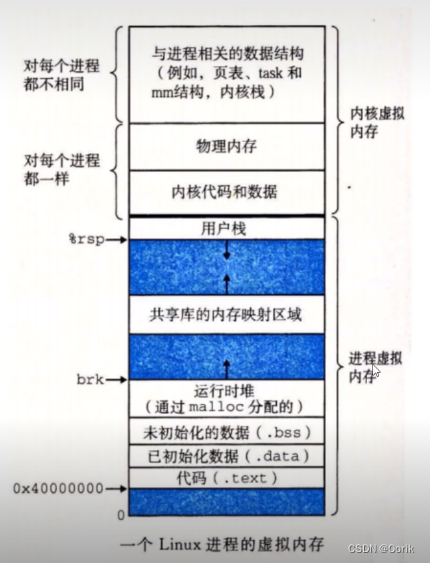
2.目前据我所知哈还没有能直接写出由线程开始的程序,为啥呢?因为此时没有系统资源让你去动,跑程序就要代码,进程是资源分配的基本单位,说明你线程要依附于进程,单单创建个线程,他是没有用户资源区的,就没有代码段数据区这些,不过创建的时候线程他是一直有自己的内核栈的且独立;
3.独有堆栈才能保证自己独立运行,这里的堆栈是共享了父进程的地址空间之后在里面分配了自己独立的堆栈,就是用户态的堆栈吧,还是得依靠父进程,这也能说明了第二个问题,只有依靠了进程,有了用户资源才能跑代码不是
目录
今天先从thread线程的使用开始:
构造函数:
一些公共的api
get_id()
join()
detach()
别的几个函数
joinable()
hardware_concurrency
线程的命名空间 std::this_thread
sleep_for()
sleep_until()
yield()
说几个小点
线程独有自己的堆栈
类的成员函数的线程化:
在学习linux的时候肯定都接触过c语言里线程pthread,不过他并不好用,各种回调函数,句柄很多参数等等,相关的api也是一大堆,不过在c++11之后就提供了线程类叫做 std::thread,用起来就很简单了。

说到线程,肯定就要考虑线程同步,线程安全的问题,同linux上一样,c++11也提供了pv原子操作,互斥(各种锁),条件变量,信号量,future(用来获取异步任务)等等这些去支持多线程的并发,后面陆续去说这些类
今天先从thread线程的使用开始:
构造函数:
//
thread() noexcept;
默认构造函,构造一个线程对象,在这个线程中不执行任何处理动作
//
thread( thread&& other ) noexcept;//只能移动构造了
移动构造函数,将 other 的线程所有权转移给新的 thread 对象。之后 other 不再表示执行线程。
//
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );//可变参数模板
创建线程对象,并在该线程中执行函数 f 中的业务逻辑,args 是要传递给函数 f 的参数
任务函数 f 的可选类型有很多,具体如下:普通函数,类成员函数,匿名函数,仿函数(这些都是可调用对象类型)
可以是可调用对象包装器类型,也可以是使用绑定器绑定之后得到的类型(仿函数)
//
thread( const thread& ) = delete; //不能拷贝构造
使用 =delete 显示删除拷贝构造,不允许线程对象之间的拷贝线程中的资源是不能被复制的,因此通过 = 操作符进行赋值操作最终并不会得到两个完全相同的对象。
// move (1) //不允许赋值 thread& operator= (thread&& other) noexcept; // copy [deleted] (2) thread& operator= (const other&) = delete;如果 other 是一个右值,会进行资源所有权的转移
如果 other 不是右值,禁止拷贝,该函数被显示删除(=delete),不可用
一些公共的api
get_id()
返回线程的id
每个被创建出的线程实例都对应一个线程 ID,这个 ID 是唯一的,可以通过这个 ID 来区分和识别各个已经存在的线程实例
函数原型
std::thread::id get_id() const noexcept;回收线程资源:有两种
join()和detach()
用的时候只能二选一
join()
join() 字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。在某个线程中通过子线程对象调用 join() 函数,调用这个函数的线程被阻塞,但是子线程对象中的任务函数会继续执行,当任务执行完毕之后 join() 会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。
注意:join在哪个线程里面调用,哪个线程走到join就会阻塞这个线程,比如在main这个主线程去创建了一个子线程funa,funa执行,main也走他的,当走到funa的join时候,main就阻塞在这里了,等着funa走完,返回回来之后main才继续走
很简单的道理
函数原型
void join();detach()
detach() 函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,子线程可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源
函数原型
void detach();用了这个函数就好像,孩子叛逆了离家出走跑到后台去了,父母管不着了,父线程管不着子线程了,他们各干各的
对于join和detach个人感觉,用join好一点,毕竟join了父线程必须要等到子线程的结果才行,而detach的话,你也不知道你父线程运行完了,子线程有没有走完,没有走完如果父线程结束程序结束,那结果肯定是由问题的不是~~当然了这是个人见解,学艺不精
给出示例,把上面我说的都演示了一下。
void* funa(void*)
{cout << "void *" << endl;return nullptr;
}
void funb()
{cout << "void" << endl;return;
}
void func(int a, int b)
{int c = a + b;cout << "func" << endl;cout << "c= " << c << endl;
}
void dosomething()
{cout << "我要干活了" << endl;cout << "hhhhhhhh" << endl;cout << "mainmainmain" << endl;
}
int main()
{//创建线程对象thread tha(funa, nullptr);thread thb(funb);thread thc(func, 10, 20);cout << "funa的线程id:" << tha.get_id() << endl;cout << "funb的线程id:" << thb.get_id() << endl;tha.join();//主线程要等待创建的这些线程结束thb.join();thc.join();//main解除阻塞了,才往下走dosomething();return 0;
}把join都换成detach,就会发现结果很多次有的子线程的结果都没有完全打印,就是因为父线程结束了,二者分离子线程还没完,除非在父线程结束前你加个sleep休眠一下,等等子线程。像linux下不管是进程fork了或者线程,刚开始学习的时候sleep也是挺常见的操作,毕竟都是些操作系统底层的问题
还有就是你会发现每次打印的结果,经常会乱序,这就是因为线程嘛,不加以控制,大家都在一起走,谁先走完就不确定了。我开篇也说了线程同步,安全这是多线程并发必须要控制的,用互斥,条件变量这些去控制,后面我会分别讲的。。
这两句话算我多啰嗦,能点进来看我这个博客的肯定对于进程和线程的问题,怎么控制这些应该是清楚的。
别的几个函数
joinable()
joinable() 函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型:
返回值为 true:主线程和子线程之间有关联(连接)关系
返回值为 false:主线程和子线程之间没有关联(连接)关系
bool joinable() const noexcept;void foo()
{this_thread::sleep_for(std::chrono::seconds(1));
}int main()
{thread t;cout << "before starting, joinable: " << t.joinable() << endl;t = thread(foo);cout << "after starting, joinable: " << t.joinable() << endl;t.join();cout << "after joining, joinable: " << t.joinable() << endl;thread t1(foo);cout << "after starting, joinable: " << t1.joinable() << endl;t1.detach();cout << "after detaching, joinable: " << t1.joinable() << endl;
}

- 在创建的子线程对象的时候,如果没有指定任务函数,那么子线程不会启动,主线程和这个子线程也不会进行连接
- 在创建的子线程对象的时候,如果指定了任务函数,子线程启动并执行任务
- 主线程和这个子线程自动连接成功在主线程调用了join()函数,子线程中的任务函数继续执行,直到任务处理完毕,这时join()会清理(回收)当前子线程的相关资源,所以这个子线程和主线程的连接也就断开了,因此,调用join()之后再调用joinable()会返回false。
- 子线程调用了detach()函数之后,父子线程分离,同时二者的连接断开,调用joinable()返回false
hardware_concurrency
thread 线程类还提供了一个静态方法,用于获取当前计算机的 CPU 核心数(是虚拟核),根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
static unsigned hardware_concurrency() noexcept;
实际上我的电脑本身是4核处理,这个函数返回的其实是虚拟的cpu核心数,也就是逻辑处理器。我这个电脑物理处理器是4,逻辑处理器是8
int main()
{int num = thread::hardware_concurrency();cout << "CPU number: " << num << endl;
}
![]()
线程的命名空间 std::this_thread

在这个命名空间中提供了四个公共的成员函数,通过这些成员函数就可以对当前线程进行相关的操作了
get_id()前面说了,说说剩下三个
进程一共有五种状态分别为:创建态,就绪态,运行态,阻塞态(挂起态),退出态(终止态) 其中创建态和退出态维持的时间是非常短的,稍纵即逝。我们主要是清楚就绪态 , 运行态 , 挂起态
线程创建后同样有这五个状态
sleep_for()
线程和进程的执行有很多相似之处,在计算机中启动的多个线程都需要占用 CPU 资源,但是 CPU 的个数是有限的并且每个 CPU 在同一时间点不能同时处理多个任务。
为了能够实现并发处理,多个线程都是分时复用CPU时间片,快速的交替处理各个线程中的任务。因此多个线程之间需要争抢CPU时间片,抢到了就执行,抢不到则无法执行(因为默认所有的线程优先级都相同,内核也会从中调度,不会出现某个线程永远抢不到 CPU 时间片的情况)。
this_thread 中提供了一个休眠函数 sleep_for(),调用这个函数的线程会马上从运行态变成阻塞态并在这种状态下休眠一定的时长,因为阻塞态的线程已经让出了 CPU 资源,代码也不会被执行,所以线程休眠过程中对 CPU 来说没有任何负担。
这个函数是函数原型如下,参数需要指定一个休眠时长,是一个时间段:
template <class Rep, class Period>void sleep_for (const chrono::duration<Rep,Period>& rel_time);
this_thread::sleep_for(chrono::seconds(1));//秒 this_thread::sleep_for(chrono::milliseconds(1000));//毫秒 this_thread::sleep_for(chrono::microseconds(1000*1000));//微妙注意:程序休眠完成之后,会从阻塞态重新变成就绪态,就绪态的线程需要再次争抢 CPU 时间片,抢到之后才会变成运行态,这时候程序才会继续向下运行。
sleep_until()
sleep_until():指定线程阻塞到某一个指定的时间点 time_point类型,之后解除阻塞
sleep_for():指定线程阻塞一定的时间长度 duration 类型,之后解除阻塞template <class Clock, class Duration>void sleep_until (const chrono::time_point<Clock,Duration>& abs_time);sleep_until() 和 sleep_for() 函数的功能是一样的,参数不同,实际开发具体选择
对于这两个函数学习之前要看看C++11 中提供了日期和时间相关的库 chrono,chrono 库主要包含三种类型的类:时间间隔duration、时钟clocks、时间点time point。也就是这俩函数要用到的参数

yield()
在线程中调用这个函数之后,处于运行态的线程会主动让出自己已经抢到的 CPU 时间片,最终变为就绪态,这样其它的线程就有更大的概率能够抢到 CPU 时间片了。使用这个函数的时候需要注意一点,线程调用了 yield () 之后会主动放弃 CPU 资源,但是这个变为就绪态的线程会马上参与到下一轮 CPU 的抢夺战中,不排除它能继续抢到 CPU 时间片的情况
std::this_thread::yield() 的目的是避免一个线程长时间占用CPU资源,从而导致多线程处理性能下降
std::this_thread::yield() 是让当前线程主动放弃了当前自己抢到的CPU资源,但是在下一轮还会继续抢void yield() noexcept;
说几个小点
线程独有自己的堆栈
多线程调用同一个方法,局部变量会共享吗_
//线程函数的返回值是没有意义的,不要取得线程的返回值
void funa(char c)
{cout << c << endl;int x = 10;cout << &x << endl;return;
}
int main()
{thread tha(funa,'a');thread thb(funa,'b');//每个线程独有自己的栈//线程a和b 不共享x这个局部变量,x打印不一样,因为x在不同的系统调用栈中tha.join();thb.join();return 0;
}局部变量是线程安全的【高并发】终于弄懂为什么局部变量是线程安全的了!!
类的成员函数的线程化:
class Test {int value;
public:Test() {}~Test(){}static void funa(int a)//没this{cout << "static funa==" << a << endl;}//this ,avoid setValue(const int x){//void setValue(Test*const this,const int x)value = x;cout << "setVaule:" << value << endl;}
};
int main()
{thread tha(Test::funa, 10);//不是全局,静态要指明tha.join();int b = 20;Test t;thread thb(&Test::setValue,&t,b);//有this 要指明对象地址thb.join();return 0;
}class AA {
public:void operator()(int a, int b)//仿函数{int c = a + b;cout << "c;" << c << endl;}void mul(int a, int b)//普通的成员函数{int d = a * b;cout << "d; " << d << endl;}
};
int main()
{thread tha(AA(), 10, 20);//仿函数当做可调用对象tha.join();AA aa;thread thb(&AA::mul, &aa, 5, 3);thb.join();int c = 20;//lambda表达式,也可以当线程化的可调动对象thread thc([&](int x)->void {c += x; }, 50);cout << "c:" << c << endl;thc.join();return 0;
}class Test {
public:int value;void func(){//thiscout<<"func"<<endl;}
};int main()
{Test test;int* p = nullptr;//0//p = &Test::value;//err//s是个指针,被限定了只能指向Test类型公有数据int Test::* s = nullptr;//s=0xffff ffff,s指的是偏移量s = &Test::value;//okp = &test.value;//ok//s = &test.value;//err,s指的是偏移量,test是具体对象了,就不能这么指向//所以要是类类型的指针,需要指定他的作用域Test t;void(Test:: * pf)() = &Test::func;thread tha(&Test::func,&t);//类型指针,非静态成员的话,需要后面传对象的地址//因为有this指针,静态成员函数就不用tha.join();return 0;
}好了到这简单回顾了一下线程有关的知识,聊了下C11并发库的这个thread类。看到这线程的使用应该就没问题了,后面我再回顾一下atomic,mutex等等这些去操作线程的类---
ok完事收工。
![[附源码]Nodejs计算机毕业设计基于大数据的超市进销存预警系统Express(程序+LW)](https://img-blog.csdnimg.cn/414a8c0d44344cb1944e405c770a1fd6.png)