环境:opencv-4.0,python,c++
方法:opencv_createsamples,opencv_traincascade,haar特征或者lbp特征+cascade分类器
流程:
收集样本,处理样本
训练分类器
目标检测
一.
收集样本,处理样本
收集正样本
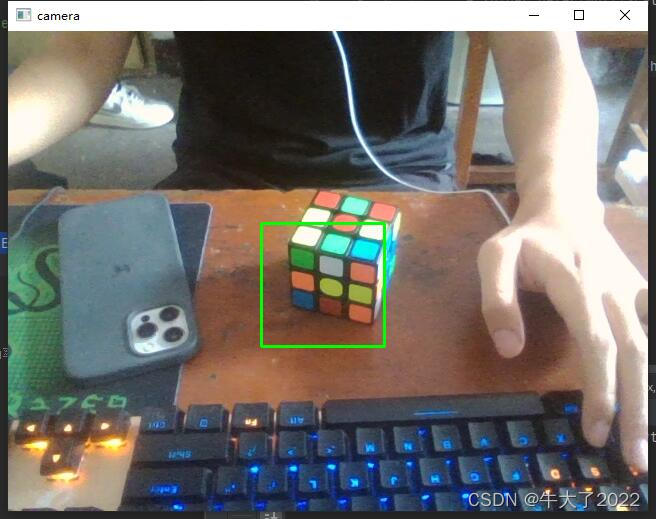
关于正样本的收集,一张或多张都可以,首先对样本进行处理,我收集了50个正样本。
在这里插入图片描述
处理正样本
处理样本,灰度化,归一化,大小为(50, 50)
path = "/home/yk/project/pyCharm/train/true/"
for i in range(1, 51):
print(path+str(i)+'.jpg')
img = cv2.imread(path+str(i)+'.jpg', cv2.IMREAD_GRAYSCALE)
img5050 = cv2.resize(img, (50, 50))
cv2.imshow("img", img5050)
cv2.waitKey(20)
cv2.imwrite('/home/yk/project/pyCharm/train/pos/'+str(i)+'.jpg', img5050)
处理后效果
在这里插入图片描述
二.
收集负样本
关于负样本,只要不含有正样本图片即可,最好是识别场景的图片。
我找到一个负样本下载链接。https://pythonprogramming.net/static/images/opencv/negative-background-images.zip
下载后如图
在这里插入图片描述
三.
生成描述文件
正负样本描述文件生成。
import os
def create_pos_n_neg():
for file_type in ['neg']:
for img in os.listdir(file_type):
if (file_type == 'neg'):
line = file_type + '/' + img + '\n'
with open('bg.txt', 'a') as f:
f.write(line)
elif (file_type == 'pos'):
line = file_type + '/' + img + ' 1 0 0 50 50\n'
with open('info.txt', 'a') as f:
f.write(line)
if __name__ == '__main__':
create_pos_n_neg()
生成bg.txt(负)文件和info.txt(正)
四.
opencv_createsamples -vec pos.vec -info info.txt -bg bg.txt -w 20 -h 20 -num 4100 (num为生成正样本数目)
生成pos.vec文件
指令说明:
-vec pos.vec:指定生成的文件,最终生成的就是pos.vec;
-info pos_img\pos.txt:目标图片描述文件,在pos\pos.txt;
-bg neg_img\neg.txt:背景图片描述文件,在neg\neg.txt;
-w 20:输出样本的宽度,20;
-h 20:输出样本的高度,20;
五.
opencv_traincascade -vec pos.vec -bg bg.txt -data xml -w 20 -h 20 -mem 1024 -npos 4000 -nneg 23000 -mode ALL
开始训练(xml为提前创建的文件夹)
opencv_traincascade -data xml -vec pos.vec -bg bg.txt -numStages 20 -minHitRate 0.999 -maxFalseAlarmRate 0.5 -numPos 4000 -numNeg 12000 -w 20 -h 20 -mode ALL
指令说明:
-vec pos.vec:正样本文件名;
-bg neg_img\neg.txt:背景描述文件;
-data xml:指定存放训练好的分类器的路径名,也就是前面建立的xml文件夹;
-w 20:样本图片宽度,20;
-h 20:样本图片高度,20;
-mem 1024:提供的以MB为单位的内存,很明显,这个值越大,提供的内存越多,运算也越快;
-npos 45:取45个正样本,小于总正样本数;
-neg 180:取180个负样本,小于总负样本数;
-nstages 5:指定训练层数,层数越高耗时越长;(可以不写)
-maxFalseAlarmRate 0.5:分类器的每一级希望得到的最大误检率,总的误检率大约为max_false_rate*number_of_stages(0.4~0.5)
-mode:选择用来训练的haar特征集的种类。basic仅仅使用垂直特征。all使用垂直和45度角旋转特征。
minHitRate 0.9999:分类器的每一级希望得到的最小检测率,总的最大检测率大约为min_hit_ratenumber_of_stages
minHitRate:影响每个强分类器阈值,当设置为0.95时如果正训练样本个数为10000个,那么其中的500个就很可能背叛别为负样本,第二次选择的时候必须多选择后面的500个,按照这种规律为后面的每级多增加numPosminHitRate个正样本,根据训练的级数可以得到如下公式