SpringBoot整合Flink(施耐德PLC物联网信息采集)
Linux环境安装kafka
前情:
施耐德PLC设备(TM200C16R)设置好信息采集程序,连接局域网,SpringBoot订阅MQTT主题,消息转至kafka,由flink接收并持久化到mysql数据库;

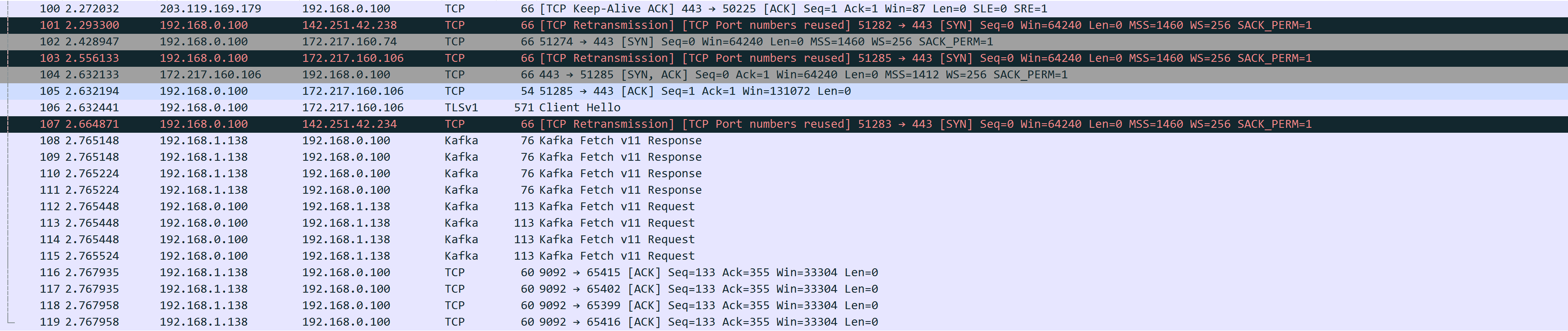
Wireshark抓包如下:
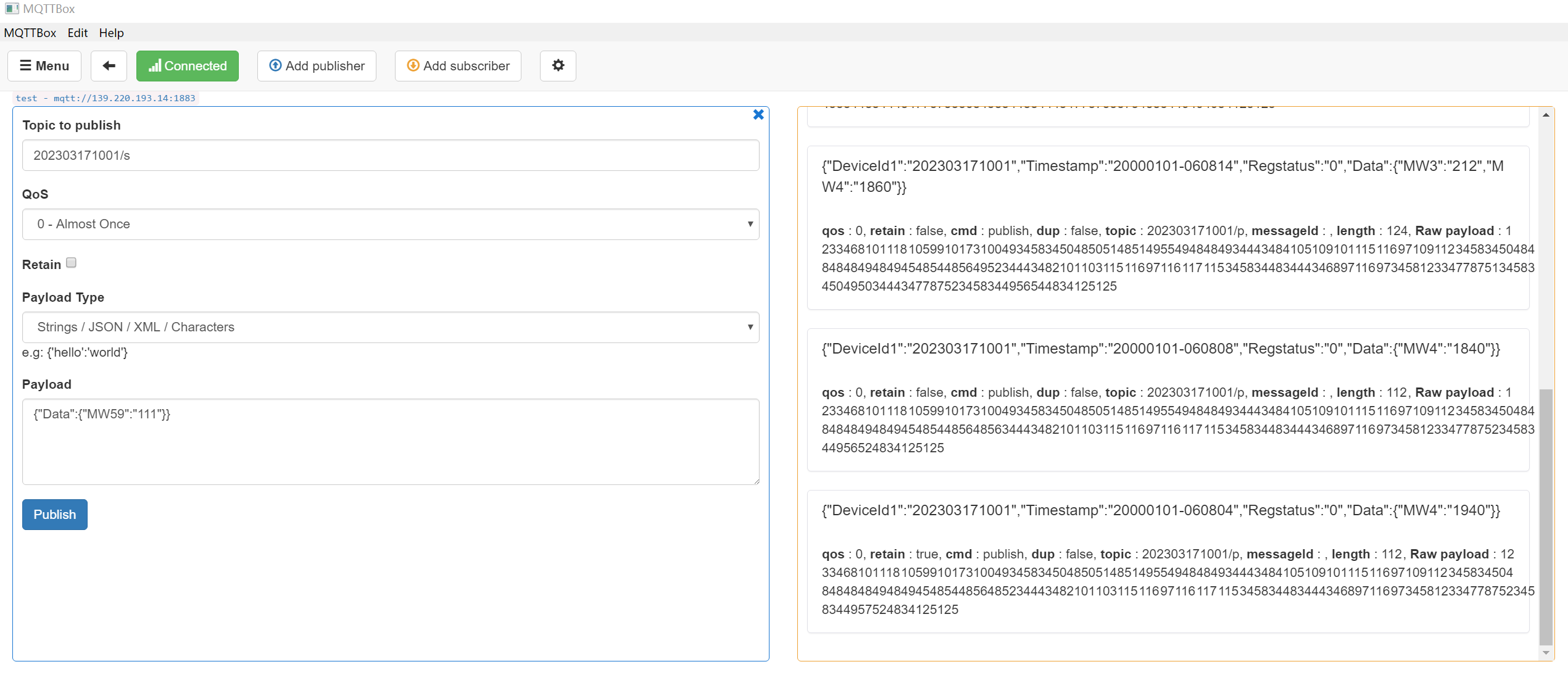
MQTTBox测试订阅如下:
已知参数:
服务器IP:139.220.193.14
端口号:1883
应用端账号:admin@tenlink
应用端密码:Tenlink@123
物联网账号:202303171001
物联网账号密码:03171001
订阅话题(topic):
202303171001/p(发布话题,由设备发送,应用端接收)
202303171001/s(订阅话题,由应用端发送,设备接收)
订阅mqtt (前提是kafka是已经就绪状态且plc_thoroughfare主题是存在的)
maven pom
<dependency><groupId>org.eclipse.paho</groupId><artifactId>org.eclipse.paho.client.mqttv3</artifactId><version>1.2.5</version></dependency>yaml配置
spring:kafka:bootstrap-servers: ip:9092producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer## 自定义
kafka:topics:# kafka 主题plc1: plc_thoroughfareplc:broker: tcp://139.220.193.14:1883subscribe-topic: 202303171001/pusername: admin@tenlinkpassword: Tenlink@123client-id: subscribe_client订阅mqtt并将报文发送到kafka主题
import org.eclipse.paho.client.mqttv3.*;
import org.eclipse.paho.client.mqttv3.persist.MemoryPersistence;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/*** PLC 订阅消息*/
@Component
public class SubscribeSample {private static final Logger log = LoggerFactory.getLogger(SubscribeSample.class);@Autowiredprivate KafkaTemplate<String,Object> kafkaTemplate;@Value("${kafka.topics.plc1}")private String plc1;@Value("${plc.broker}")private String broker;@Value("${plc.subscribe-topic}")private String subscribeTopic;@Value("${plc.username}")private String username;@Value("${plc.password}")private String password;@Value("${plc.client-id}")private String clientId;@PostConstructpublic void plcGather() {int qos = 0;Thread thread = new Thread(new Runnable() {@Overridepublic void run() {MqttClient client = null;try {client = new MqttClient(broker, clientId, new MemoryPersistence());// 连接参数MqttConnectOptions options = new MqttConnectOptions();options.setUserName(username);options.setPassword(password.toCharArray());options.setConnectionTimeout(60);options.setKeepAliveInterval(60);// 设置回调client.setCallback(new MqttCallback() {public void connectionLost(Throwable cause) {System.out.println("connectionLost: " + cause.getMessage());}public void messageArrived(String topic, MqttMessage message) {String data = new String(message.getPayload());kafkaTemplate.send(plc1,data).addCallback(success ->{// 消息发送到的topicString kafkaTopic = success.getRecordMetadata().topic();// 消息发送到的分区
// int partition = success.getRecordMetadata().partition();// 消息在分区内的offset
// long offset = success.getRecordMetadata().offset();log.info("mqtt成功将消息:{},转入到kafka主题->{}", data,kafkaTopic);},failure ->{throw new RuntimeException("发送消息失败:" + failure.getMessage());});}public void deliveryComplete(IMqttDeliveryToken token) {log.info("deliveryComplete---------{}", token.isComplete());}});client.connect(options);client.subscribe(subscribeTopic, qos);} catch (MqttException e) {e.printStackTrace();}}});thread.start();}
}
采集报文测试(如下图表示成功,并且已经发送到了kafka主题上)

Flink接收kafka数据
maven pom
<!--工具类 开始--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-collections4</artifactId><version>4.4</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.26</version></dependency><!--工具类 结束--><!-- flink依赖引入 开始--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.13.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.13.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>1.13.1</version></dependency><!-- flink连接kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.13.1</version></dependency><!-- flink连接es--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>1.13.1</version></dependency><!-- flink连接mysql--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-jdbc_2.11</artifactId><version>1.10.0</version></dependency><!-- flink依赖引入 结束--><!--spring data jpa--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>yaml配置
# 服务接口
server:port: 8222spring:kafka:bootstrap-servers: ip:9092consumer:group-id: kafkakey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerdatasource:url: jdbc:mysql://127.0.0.01:3306/ceshi?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: rootdruid:initial-size: 5 #初始化时建立物理连接的个数min-idle: 5 #最小连接池数量maxActive: 20 #最大连接池数量maxWait: 60000 #获取连接时最大等待时间,单位毫秒timeBetweenEvictionRunsMillis: 60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒minEvictableIdleTimeMillis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒validationQuery: SELECT 1 #用来检测连接是否有效的sqltestWhileIdle: true #申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效testOnBorrow: false #申请连接时执行validationQuery检测连接是否有效,如果为true会降低性能testOnReturn: false #归还连接时执行validationQuery检测连接是否有效,如果为true会降低性能poolPreparedStatements: true # 打开PSCache,并且指定每个连接上PSCache的大小maxPoolPreparedStatementPerConnectionSize: 20 #要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100filters: stat,wall,slf4j #配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙#通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000jpa:hibernate:ddl-auto: noneshow-sql: truerepositories:packages: com.hzh.demo.domain.*#自定义配置
customer:#flink相关配置flink:# 功能开关plc-status: trueplc-topic: plc_thoroughfare# 定时任务定时清理失效数据
task:plc-time: 0 0/1 * * * ?表结构
-- plc_test definition
CREATE TABLE `plc_test` (`pkid` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '主键id',`json_str` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT 'json格式数据',`create_time` bigint NOT NULL COMMENT '创建时间',PRIMARY KEY (`pkid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='plc存储数据测试表';启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.annotation.EnableScheduling;@SpringBootApplication
@EnableJpaRepositories(basePackages = "repository basePackages")
@EntityScan("entity basePackages")
@EnableScheduling
public class PLCStorageApplication {public static void main(String[] args) {SpringApplication.run(PLCStorageApplication.class, args);}
}实体类
import lombok.Builder;
import lombok.Data;import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;/*** PLC接收实体*/
@Table(name = "plc_test")
@Data
@Builder
@Entity
public class PLCDomain implements Serializable {private static final long serialVersionUID = 4122384962907036649L;@Id@Column(name = "pkid")public String id;@Column(name = "json_str")public String jsonStr;@Column(name = "create_time")private Long createTime;public PLCDomain(String id, String jsonStr,Long createTime) {this.id = id;this.jsonStr = jsonStr;this.createTime = createTime;}public PLCDomain() {}
}
jpa 接口
import com.hzh.demo.domain.PLCDomain;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;@Repository
public interface PLCRepository extends JpaRepository<PLCDomain,String> {}封装获取上下文工具类(ApplicationContextAware)由于加载先后顺序,flink无法使用spring bean注入的方式,特此封装工具类
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.i18n.LocaleContextHolder;
import org.springframework.stereotype.Component;@Component
public class ApplicationContextProviderimplements ApplicationContextAware {/*** 上下文对象实例*/private static ApplicationContext applicationContext;/*** 获取applicationContext** @return*/public static ApplicationContext getApplicationContext() {return applicationContext;}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {ApplicationContextProvider.applicationContext = applicationContext;}/*** 通过name获取 Bean.** @param name* @return*/public static Object getBean(String name) {return getApplicationContext().getBean(name);}/*** 通过class获取Bean.** @param clazz* @param <T>* @return*/public static <T> T getBean(Class<T> clazz) {return getApplicationContext().getBean(clazz);}/*** 通过name,以及Clazz返回指定的Bean** @param name* @param clazz* @param <T>* @return*/public static <T> T getBean(String name, Class<T> clazz) {return getApplicationContext().getBean(name, clazz);}/*** 描述 : <获得多语言的资源内容>. <br>* <p>* <使用方法说明>* </p>** @param code* @param args* @return*/public static String getMessage(String code, Object[] args) {return getApplicationContext().getMessage(code, args, LocaleContextHolder.getLocale());}/*** 描述 : <获得多语言的资源内容>. <br>* <p>* <使用方法说明>* </p>** @param code* @param args* @param defaultMessage* @return*/public static String getMessage(String code, Object[] args,String defaultMessage) {return getApplicationContext().getMessage(code, args, defaultMessage,LocaleContextHolder.getLocale());}
}
FIink 第三方输出(mysql写入)
import com.hzh.demo.config.ApplicationContextProvider;
import com.hzh.demo.domain.PLCDomain;
import com.hzh.demo.repository.PLCRepository;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;import java.util.UUID;/*** 向mysql写入数据*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class MysqlSink implements SinkFunction<String> {private static final Logger log = LoggerFactory.getLogger(MysqlSink.class);@Overridepublic void invoke(String value, Context context) throws Exception {long currentTime = context.currentProcessingTime();PLCDomain build = PLCDomain.builder().id(UUID.randomUUID().toString().replaceAll("-", "")).jsonStr(value).createTime(currentTime).build();PLCRepository repository = ApplicationContextProvider.getBean(PLCRepository.class);repository.save(build);log.info("持久化写入:{}",build);SinkFunction.super.invoke(value, context);}
}
Flink订阅kafka topic读取持续数据
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.util.Properties;/*** 接收 kafka topic 读取数据*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class FlinkReceivingPLC {private static final Logger log = LoggerFactory.getLogger(MyKeyedProcessFunction.class);@Value("${spring.kafka.bootstrap-servers:localhost:9092}")private String kafkaServer;@Value("${customer.flink.plc-topic}")private String topic;@Value("${spring.kafka.consumer.group-id:kafka}")private String groupId;@Value("${spring.kafka.consumer.key-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")private String valueDeserializer;/*** 执行方法** @throws Exception 异常*/@PostConstructpublic void execute(){final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(5000);//设定全局并发度env.setParallelism(1);Properties properties = new Properties();//kafka的节点的IP或者hostName,多个使用逗号分隔properties.setProperty("bootstrap.servers", kafkaServer);//kafka的消费者的group.idproperties.setProperty("group.id", groupId);properties.setProperty("key-deserializer",keyDeserializer);properties.setProperty("value-deserializer",valueDeserializer);FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties);DataStream<String> stream = env.addSource(myConsumer);stream.print().setParallelism(1);stream//分组.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}})//指定处理类
// .process(new MyKeyedProcessFunction())//数据第三方输出,mysql持久化.addSink(new MysqlSink());//启动任务new Thread(() -> {try {env.execute("PLCPersistenceJob");} catch (Exception e) {log.error(e.toString(), e);}}).start();}
}失效数据清理机制(为了方便测试,所以清理机制执行频率高且数据失效低)
import com.hzh.demo.repository.PLCRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.util.Optional;/*** 定时任务配置*/
@Component
@Configuration
public class QutrzConfig {private static final Logger log = LoggerFactory.getLogger(QutrzConfig.class);@Autowiredprivate PLCRepository plcRepository;/*** 数据清理机制*/@Scheduled(cron = "${task.plc-time}")private void PLCCleaningMechanism (){log.info("执行数据清理机制:{}","PLCCleaningMechanism");long currentTimeMillis = System.currentTimeMillis();Optional.of(this.plcRepository.findAll()).ifPresent(list ->{list.forEach(plc ->{Long createTime = plc.getCreateTime();//大于1分钟为失效数据if ((currentTimeMillis - createTime) > (1000 * 60 * 1) ){this.plcRepository.delete(plc);log.info("过期数据已经被清理:{}",plc);}});});}
}
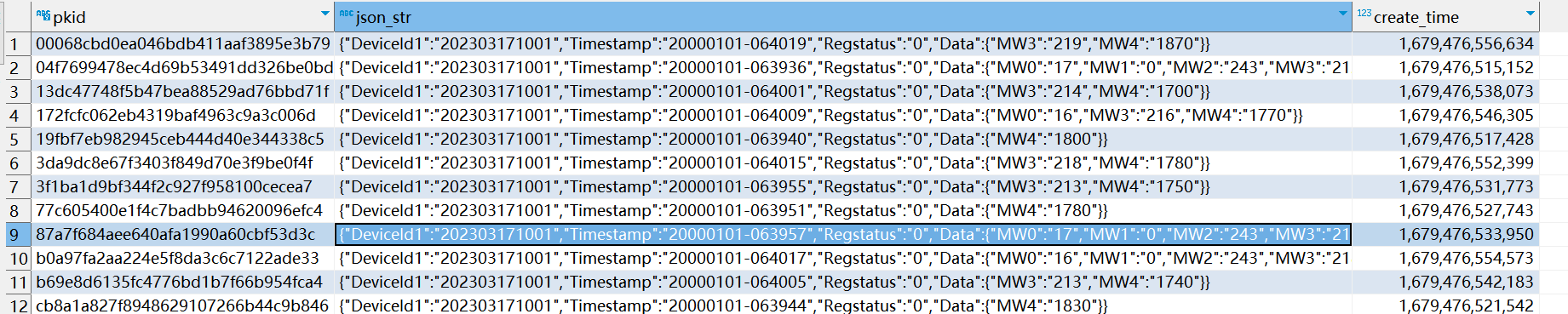
测试结果
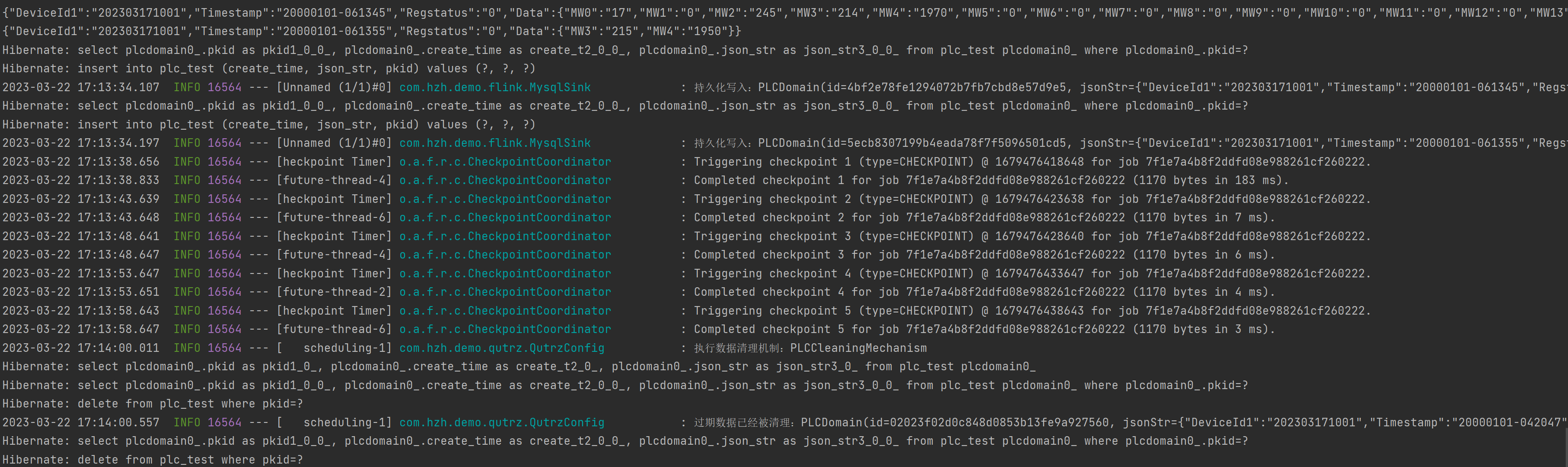
mysql入库数据