SSD系统架构
SSD作为数据存储设备,其实是一种典型的(System on Chip)单机系统:有主控CPU、RAM、操作加速器、总线、数据编码译码等模块,操作对象为协议、数据命令、介质,操作目的是写入和读取用户数据。
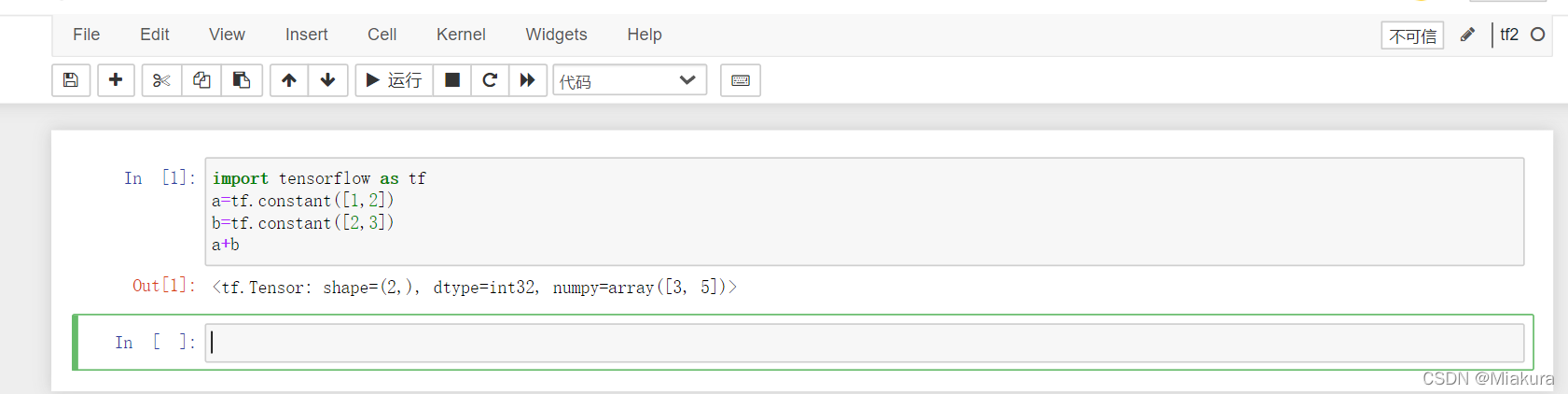
图2-1 SSD主控模块硬件图
图2-1是一个SSD系统架构的概略图,这款主控采用ARM CPU,主要分为前端和后端两大部。前端(Host Interface Controller,主机接口控制器)跟主机打交道,接口可以是SATA、PCIe、SAS等接口。后端(Flash Controller,闪存控制器)跟闪存打交道并完成数据编解码和ECC。除此之外还有缓冲(Buffer),DRAM。模块之间通过AXI高速和APB低速总线互联互通,完成信息和数据的通讯。在此基础之上,由SSD 固件开发者构筑固件(Firmware)统一完成SSD产品所需要的功能,调度各个硬件模块,完成数据从主机端到闪存端的写入和读取。
前端
主机接口:与主机进行通讯(数据交互)的标准协议接口,当前主要代表为SATA、SAS和PCIe等。表2-1是三者的接口速率:
表2-1 SATA/SAS/PCIe接口速率
| 接口 | 速率(@2017,Gb/s) |
| SATA | 6/3/1.5 |
| SAS | 12/6 |
| PCIe | 通道数 * 8(PCIe 3.0) |
SATA的全称是Serial Advanced Technology Attachment(串行高级技术附件),一种基于行业标准的串行硬件驱动器接口,是由Intel、IBM、Dell、APT、Maxtor和Seagate公司共同提出的硬盘接口规范。2001年,由Intel、APT、Dell、IBM、希捷、迈拓这几大厂商组成的SATA委员会正式确立了SATA 1.0规范,在当年的IDF Fall 大会上,Seagate宣布了SATA 1.0标准,正式宣告了SATA规范的确立。

图2-2 SATA接口
SAS(Serial Attached SCSI)即串行连接SCSI,是新一代的SCSI技术,和现在流行的Serial ATA(SATA)硬盘相同,都是采用串行技术以获得更高的传输速度,并通过缩短连接线改善内部空间等。SAS是并行SCSI接口之后开发出的全新接口,此接口的设计是为了改善存储系统的效能、可用性和扩充性,并且提供与SATA硬盘的兼容性。SAS的接口技术可以向下兼容SATA。具体来说,二者的兼容性主要体现在物理层和协议层的兼容。在物理层,SAS接口和SATA接口完全兼容,SATA硬盘可以直接使用在SAS的环境中;从接口标准上而言,SATA是SAS的一个子标准,因此SAS控制器可以直接操控SATA硬盘,但是SAS却不能直接使用在SATA的环境中,因为SATA控制器并不能对SAS硬盘进行控制。在协议层,SAS由3种类型协议组成,根据连接的不同设备使用相应的协议进行数据传输。其中串行SCSI协议(SSP)用于传输SCSI命令;SCSI管理协议(SMP)用于对连接设备的维护和管理;SATA通道协议(STP)用于SAS和SATA之间数据的传输。因此在这3种协议的配合下,SAS可以和SATA以及部分SCSI设备无缝结合。

图2-3 SAS接口
PCIe(Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,它原来的名称为“3GIO”,是由英特尔在2001年提出的,旨在替代旧的PCI、PCI-X和AGP总线标准。PCIe属于高速串行点对点多通道高带宽传输,所连接的设备分配独享通道带宽,不共享总线带宽,主要支持主动电源管理、错误报告、端对端的可靠性传输、热插拔以及服务质量(QoS,Quality of Service)等功能。它的主要优势就是数据传输速率高,目前最高的4.0版本可达到2GB/s(单向单通道速率),而且还有相当大的发展潜力。PCI Express也有多种规格,从PCI Express 1X到PCI Express 32X,意思就是1个通道到32个通道,能满足将来一定时间内出现的低速设备和高速设备的需求。PCI-Express最新的接口是PCIe 4.0接口。
图2-4展示的是PCIe接口,包括卡式和U.2:

图2-4 PCIe接口式插卡(AIC)

图2-5 U.2接口
前端是负责主机和SSD设备通讯的接口,命令和数据传输通过前端总线流向或流出SSD设备。
从硬件模块上来看,前端有SATA/SAS/PCIe PHY层,俗称物理层,接收串行比特数据流,转化成数字信号给前端后续模块处理。这些模块处理NVMe/SATA/SAS命令,它接收并处理一条条命令和数据信息,涉及到数据搬移会使用到DMA。一般命令信息会排队放到队列中,数据会放到SRAM快速介质中。如果涉及到加密和压缩功能,前端会有相应的硬件模块做处理,软件无法应对压缩和加密的快速的需求,会成为性能的瓶颈。
从协议角度,以一条SATA Write FPDMA命令为例,从主机端文件系统出发发出一条写命令请求,到主板南桥AHCI寄存器级别的写命令操作,忽略文件系统到AHCI路径的操作细节,从SSD前端总线上看会发出如下的写交互操作:
Step 1: 主机在总线上发出Write FPDMA命令FIS(Frame Information Structure,帧信息结构,是SATA为了实现异步传输数据块而使用的封包);
Step 2: SSD收到命令后,判断自己内部写缓存(Write Buffer)是否有空间去接收新的数据:如果有,则发出DMA Setup FIS到主机端,否则什么也不发,主机端处于等待状态。(这叫流控:数据流量控制);
Step 3: 主机端收到DMA Setup FIS后,发送不大于8KB数据的Data FIS给设备;
Step 4: 重复Step 2和Step 3直到数据全部发送完毕;
Step 5: 最后步骤设备(SSD)发送一个状态Status FIS给主机,表示从协议层面这条写命令完成全部操作。当然Status可以是一个good status或者一个bad/error status,表示这条Write FPDMA命令操作正常或者异常完成。
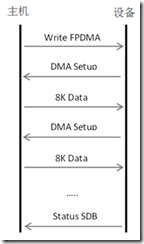
图1-6 SATA Write FPDMA命令协议处理步骤
SSD把命令和数据接收到SSD内部缓冲区之后还需要做些什么呢?任务还没完成,前端固件模块还需要对命令进行解析,并分派任务给中端FTL。命令解析(Command Decoder)将命令FIS解析成固件和FTL(Flash Translation Layer)能理解的元素:
· 这是一条什么命令,命令属性是读还是写类型;
· 如果是读写类型命令,命令的起始 LBA和数据长度;
· 命令的其他属性,如是否是FUA命令,和前一条命令LBA是否连续(即是连续还是随机命令)。
当命令解析完成后,放入命令队列里等待中端FTL排队去处理,由于已经有了起始LBA和数据长度两大主要信息元素,FTL可以准确地映射LBA空间到闪存的物理空间。至此,前端硬件和固件模块完成了它应该完成的任务。
主控CPU
SSD控制器SoC模块和其他嵌入式系统SoC模块并没有什么本质的不同,一般是一颗或多颗CPU核组成,同时片上有I-RAM、D-RAM、PLL、IO、UART、高低速总线等外围电路模块。CPU负责运算,系统调度,IO完成必要的输入输出,总线连接前后端模块。
通常我们所说的固件就运行在CPU核上,分别有代码存储区I-RAM和数据存储区D-RAM。如果多核CPU,需要注意的是软件可以是对称多处理(SMP)和非对称多处理(AMP)。对称多处理多核共享OS和同一份执行代码,非对称多处理是多核分别执行不同代码。前者多核共享一份I-RAM和D-RAM,后者每核对应一份I-RAM和D-RAM;前者资源共享,后者多核每核独立运行,没有内存抢占导致代码速度执行变慢的问题。当SSD的CPU要求计算能力更高时,除增加核数和增加单核CPU频率,AMP的方式设计更加适应计算和任务独立的要求,消除了代码和数据资源抢占的导致执行速度过慢的问题。
固件的设计根据CPU核数的设计,充分发挥多核CPU的计算能力是固件设计考虑的一方面,另外固件考虑任务划分,分别加载到不同CPU上执行,达到并行处理的同时也能让所有CPU有着合理均衡的负载,不至于有的CPU忙死有的CPU闲死,这是固件架构设计要考虑到的重要内容,目标是让SSD输出最大的读写性能。
SSD CPU的外围模块包括像UART/GPIO/JTAG是程序必不可少的调试端口,定时器模块Timer,还有其他的内部模块像DMA、温度传感器、Power regulator模块等等。
后端
在前文中关于后端和闪存有过一些描述,这里从SSD主控角度来分析一下后端硬件模块。
后端两大模块:ECC模块和闪存控制器。
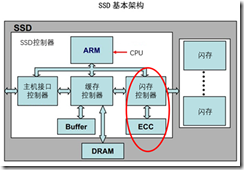
图2-7 SSD中的闪存控制器和ECC模块
ECC模块是数据编解码单元,由于闪存存储天生存在误码率,为了数据的正确性,在数据写入操作时给原数据加入ECC 校验保护,这是编码过程。读取数据时,同样需要解码来检错和纠错,如果错误的比特数超过ECC纠错能力,数据会以不可纠错误上传给主机。这里的ECC 编码和解码的过程就是ECC模块单元来完成的。SSD内的ECC算法主要有BCH和LDPC,并且LDPC正成为主流。
闪存控制器,使用包括符合闪存ONFI、Toggle标准的闪存命令,负责管理数据从缓存到闪存的读取和写入。
闪存控制器如何和闪存连接和通讯的,从单个闪存角度,连接的引脚如下,一个Die/LUN是一个闪存命令执行的基本单元,所以闪存控制器和闪存连接按照如下引脚连接:
l 外部接口:8个I/O口,5个使能信号(ALE、CLE、WE#、RE#、CE#),1个状态引脚(R/B#),1个写保护引脚(WE#);
l 命令、地址、数据都通过8个I/O口输入输出;
l 写入命令、地址、数据时,都需要将WE#、CE#信号同时拉低;数据在WE#上升沿被锁存;
l CLE、ALE用来区分I/O引脚上传输的是数据还是地址;
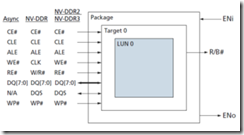
图1-8 闪存芯片接口
从闪存控制器角度,为了性能需求需要并发多个闪存Die/LUN,通常配置有多个通道 (channel)。一个通道挂多少个闪存Die/LUN,其一取决于SSD容量,其二取决于性能需求,Die/LUN个数越多,并发的个数越多,性能越好。
Die/LUN是闪存通讯的最小基本管理单元,配有上述的一套总线包括:8个I/O口,5个使能信号(ALE、CLE、WE#、RE#、CE#),1个状态引脚(R/B#),1个写保护引脚(WE#)…
如果一个通道上挂了多个闪存Die/LUN,每个Die共用每个通道上一套总线,那闪存控制器如何识别和哪个Die通讯呢?答案是选通信号CE#,在闪存控制给特定地址的闪存Die发读写命令和数据前,先选通对应Die的CE#信号,然后进行读写命令和数据的发送。一个通道上可以有多个CE,SSD主控一般设计为4-8个,对于容量而言选择有一定的灵活度。