前言
“纸上谈兵”已经快一年,这项目有点意思了,其实、有难度的事情才好玩。从年初至今陆续买了20多套各类开发板,我还没一套去上手试玩;只是买回来“摸摸”感受一下,看看相关资料、用“想象力”探视和思考,之后就丢弃一旁“吃灰”了。音响成品倒是试用过不少,那又不用“开发”,只是用
心去“试听”和比较吧。“飞鸡2号和飞鸡1号”合一了,“飞鸡2号”采用现成的模块(全志H6或RK3568方案)直接插在“飞鸡1号12路1600W纯数字直推功放板”上(通过25Mbps的单端SPI接口通信),构成“多媒体娱乐中心”、也叫“飞鸡2号”;先使用linux操作系统、只是增加一个音频协议转换驱动C程序;这样,难度系数大幅降低,将来再通过100Mbps差分SPI口连接到“AOS的飞鸡1号小电脑”、从而取消“全志H6或RK3568方案”模块。
增加一个项目“中级发烧小电脑”、也叫“飞鸡1号”,这将使用AOS简易操作系统和定制开发的多核(64位RISC)芯片,芯片分为8组。主组:最大32个多核单元 + 外围设备 + 组间仲裁器IARB(Intergroup arbiter),7个副组、每个副组: 最大32个多核单元。组间仲裁器IARB嵌入在主组通信管理员Cadm的RALU核,以便配置和管理。
飞鸡1号小电脑供电电源:20V/15A、300W。
⚫算术逻辑单元核RALU(RISC Arithmetic Logical Unit):主频1GHZ。
AISC压缩16位指令集(A instruction set computer)简写汇编暂为28条指令束:非标准X的基本整数指令集I、原子性存储器指令集A、扩充的位操作指令集B、16位压缩指令集C、事务存储器通信操作指令集T,通过操作SVCU核的打包SIMD扩展指令集P、可伸缩向量扩展指令集V、可伸缩向量单精度浮点指令集F、可伸缩向量双精度浮点指令集D、可伸缩向量四精度浮点指令集Q、可伸缩向量十进制浮点指令集L、可伸缩向量整数指令集VI。
有2套(用户和内核)16个通用64位寄存器x0~x15,X0--X9通用寄存器、X10 = 0、X11 = SR状态标志寄存器、X12 = SP、X13 = PC远端程序计数器、X14 = LR连接寄存器、X15专用装配寄存器。不兼容RISC-V指令集。
⚫可伸缩向量运算单元核SVCU(Scalable Vector calculations Unit):主频1GHZ。
256个通道,每个通道16管道、每个管道分为:单精度浮点4条管线(GPU的4D、或2*2D、1D+3D、模式),双精度浮点2条管线,四精度浮点1条管线,16位半精度浮点8条管线,8位整数16条管线...。可同时做16K个单精度浮点运算,算力达到16TFLOPS(每秒万亿次浮点运算),输入输出缓存8MB的SRAM。芯片可以有128个SVCU核,芯片总算力:2PFLOPS。这是理论估算,按现有工艺、估计功耗可以“开飞机”了,呵呵。核心电源0.8V?5nm工艺可以具现?我不知道。
管线支持乘加、卷积等等多级流水运算,AI应用;单时钟周期256*16*16个8位乘法和加法矩阵计算,缓存可以一次支持:32级流水线*256*16*16 = 2M个8位乘法和加法矩阵计算。通常是APU = SVCU + RALU + 外部DDR5.0的结构,RALU支持分支编程、DDR5.0控制器等等;多核单元的内部总线速度为64GB(字节)/S,外部DDR5.0速度51.2GB(字节)/S。
单说算力是不对的,还要看连接DDR5.0内存的速度;如果APU都有单独连接DDR5.0的2通道外部总线(2*32位),每组连接1根DDR5.0内存条,总的DDR5.0速度:8*51.2GB(字节)/S = 409.6GB(字节)/S,共8根2*64GB的DDR5.0内存条1TB。如果多核单元都没有对外通信、只在内部总线运行,多核单元内部256位总线、那芯片最大总线速度:
8组*32多核单元*64GB(字节)/S = 16TB(字节)/S。
多核单元可以是RALU和APU的多个的灵活组合,APU是试图将GPU、FPU、VPU、AI核(TPU、BPU、DPU、NPU、TPU、等等)、统一架构的设想。
⚫高速内部总线HSIB(High-speed internal bus):主频2GHZ
纵横竖3D立体开关网络连接8组最大256个多核单元(RALU核或APU核或它们的组合),最大组内同时点到点多核单元间通信16对、最大组之间同时点到点多核单元间通信4对,每个组内总线等效为最大4096位、最大总线速度2G*512B/S = 1TB(字节)/S;点到点多核单元最大组间通信总线1024位、最大速度为 2G*128 B/S = 256 GB(字节)/S。如果只有组内多核单元间通信时等效为8组*16*256位 = 32K位总线、那芯片最大总线速度:8TB(字节)/S;组之间实际只有4*256位的总线,可以同时4对多核单元在组之间通信。
⚫256位内部设备总线DB(Device bus):主频2GHZ,速度64GB(字节)/S,DDR5.0双通道速度51.2GB(字节)/S。
专门一个多核管理:空间管理员Sadm(APU多核结构、内存空间MMU管理),含外部DDR5.0总线单通道A的IP核。各种设备都视为大小不一的收发兵乓FIFO(First In First Out)缓冲区(256位/32字节一个单元,缓冲区:1--n个单元),设备处理完一个FIFO缓冲区后、转到另一个FIFO缓冲区工作并发出中断,Sadm对相应设备发送片选和初始地址、再读或写处理完的FIFO缓冲区,之后将相应数据读或写到DDR主存。Sadm的一小部分工作量就是:设备与DDR主存的等效DMA传输,其它CPU节点与DDR主存的数据包传输。
这样一来,统一了各种设备的物理层驱动;不同的设备(不管是高速、低速、千奇百怪,还是各类多核单元),都统一视作对设备之FIFO缓冲区以及DDR主内存的设备相应区域之内存操作(多核单元是独立物理内存区,但都对应到相应的虚拟内存空间)!没有DMA传输了,已经被空间管理员Sadm代替;硬件中断也是极大地被弱化,转化到各个多核单元的是“中断消息包”。简单说:DMA和中断都是存在的,但已是系统硬件统一处理了,编写操作系统时、无需过多考虑;万千设备物理层驱动程序归化为一,不同的设备物理层驱动程序、其不同点只是在DDR主存的设备初始地址和长度以及设备配置寄存器的副本(正本自然是初始化时、已写在设备的配置寄存器组内)。将设备看作文件,设备物理层驱动程序需有“设备文件操作接口”;linux、windows、等等操作系统,对不同的设备需编写不同的设备驱动程序,这是它们千万行以上代码量的原因!你现在不会觉得AOS的小于5000行代码量是“吹牛”吧。AOS的物理层驱动程序会有多少代码量?估计就几十行!AOS的设备物理层驱动程序是一个“设备物理层驱动代码类A”、只有一份,不同设备的物理层驱动程序是A的具体对象、只是有不同的“内存”属性;这样,会形成各种设备的“内存”属性表,我们可以用“网页”来对各种设备动态配置,甚至可以显示芯片引脚的动态配置图像,这就是“生态环境”;STM32单片机在这方面就做得比较好,其对程序员的亲和度较高、编程“生态环境”很好。
设备物理层驱动程序之上是各种设备协议层驱动程序。OSI模型是分层方法中的一种通用功能划分方法,OSI模型分为七层:
1、物理层:
主要对物理连接方式,电气特性,机械特性等制定统一标准,传输“位(比特)流”;如网线的接口RJ类型、光纤的接口类型、各种传输介质的传输速率,FIFO缓冲区及配置控制寄存器的初始地址和大小、时钟、中断、模式、等配置与控制。
设备物理层为软硬件实现,设备物理层之上通常是协议层驱动程序的软件实现。连续的位流或连续的帧或连续的数据包就称为数据流Data stream(也可以m帧为一个数据包DPK(Data packet)),有2种相对方向的数据流,数据流输入DSI(Data stream input),数据流输出DSO(Data stream output);物理层往上层走称为数据流输入DSI,反之、称为数据流输出DSO。有单向输入或输出的设备,也有双向通信的设备。从设备输出数据流DSO、自然会有明确的相关上层协议驱动程序操控,问题是从设备进入的数据流输入DSI该走那一条道路?比如小电脑的类似PCIe 5.0X1口连接另一个装置(含有WIFI、BT、千兆以太网MAC口、USB2.0、USB3.0、
SATA3.0硬盘口、等等),如果从WIFI来了一个数据帧(它可能是键盘数据、也可能是鼠标信息、也可能是话筒信号数据)、那么该是给上层的谁负责?又比如SPI口、它可能接收到的数据帧、或许是音频数据包也或许是FLASH数据、也可能是以太网MAC格式数据包、等等,AOS应该如何应对?
小电脑的硬件端口通常都是相对固定的功能,其物理层驱动相对固定的连接到相应上层,由用户做功能配置和切换;需要考虑的是类似PCIe 5.0X1的高速串行通信端口过来的帧,我们需要一个24位的“流标识”符、来表述进入帧所代表的数据流输入DSI(键盘、鼠标、MAC、SATA3.0磁盘数据、USB2.0、USB3.0、音频、视频、视音频、等等)。我们需要尽量简化和清晰表述物理层,PCIe 5.0显然不符合要求;高速串行通信无非是一对差分接收和一对差分发送,和SPI是类似的,只是时钟嵌入了收发信号中;可用的招数、通信就那几招:强来、调幅、调频、调相位。调频时钟不好恢复去除,余下就3种组合。麻烦的是各类信号的帧(或包)长是不一样的、实时性要求不一样,不能用定长的FIFO去规划。是故,FIFO缓冲区设计为也可以用指定地址去读写缓冲区,实时帧会有一个中断位,如果收到这种实时帧、硬件会发出中断,让空间管理员Sadm读往DDR并运行相关驱动。
高速串行通信端口一个帧最少为一个单元256位,帧头必须有24位“流标识”符、24位实际有效字节数(实际只是21位、2MB,最高位乃中断位、其余2高位备用)和16位帧长度(单元数)。
24位“流标识”符:第一个字节、数据流类型,第二个字节、协议规则(压缩标准(低4位)、源接口等等)、第三个字节、数据流通道(最高位1输入,0位输出)。比如:音频数据流ADS_MP3_USB2.0_LIN3,MP3压缩来源USB2.0接口的音频数据流第三输入左通道,文件数据流FDS_N_SATA3.0_文件动态通道号(文件号等信息在协议内表示)。数据流类型通常有:音频流、视频流、视音频混合流、文件流、MAC网络数据流(里面又包含各种数据流)、分离后的二级流、中间数据流、中间混合流、AI流、原始流、等等,具体有待规划。
任一个层驱动程序,我们都可以抽象出一个最多三端口的层驱动模型:连接上层的数据流端口CULDSP(Connect the upper level data stream port),连接下层的数据流端口CLLDSP(Connect the lower level data stream port ),连接文件操作的控制流端口CFOCSP(Connect the file operations control stream port )。没有上层时,就只有CFOCSP和CLLDSP;物理层的下层就是位流数据,也只有2层、CULDSP和CFOCSP。
编写AOS应用程序,就是画图、画出数据流程图!其编程“生态环境”就是“网页画图”、可以用“C#、VB、C++、JAVA、等等”高级语言制作“编程生态环境”。应用程序(巨大的虚拟空间):进程(主线程)模块、线程模块,控制流模块,应用程序数据流协议驱动模块,设备数据流驱动模块(物理层驱动、各种协议层驱动);用线将各种模块连接就构成了应用程序,除公用模块外、应用程序的各种模块,“编程生态环境”都会生成模块程序框架,程序员在程序框架内用C语言编写相应模块程序。模块就是一种方法类库,应用程序专有的就是动态库;公用的是AOS自带的标准类库(设备驱动库、标准方法库),用户可以酌情用“网页”选择安装。应用程序数据流协议驱动模块或许会有多个数据流输入DSI和多个组合变换后的中间混合数据流输出DSO,设备数据流协议驱动模块的CFOCSP也可能连接多个应用程序、如键盘鼠标数据流(但更新信息还是发给焦点应用程序为主)。
2、数据链路层:
该层的作用包括了物理地址寻址(如媒体访问控制MAC地址的封装和解封装),数据的成帧,流量控制,数据的检错,重发等。为了保证传输,从网络层接收到的数据被分制成特定的可被物理层传输的帧。由n位比特bit构成帧,n是多少得看具体协议;帧是n位比特的数据结构,它不仅包括原始数据,还包括发送方和接收方的物理地址以及纠错和控制的信息。其中的地址确定了帧将发送的位置,纠错和控制信息则保证帧的准确到达。如果传送数据的过程中,接收点检测到数据有错误,就通知发送方重新发送这一帧。交换机就处在这一层,最小的传输单位——帧。
3、网络层:
控制子网的运行,如逻辑编址,分组传输,路由选择最小单位——分组(包)报文IP地址工作在OSI参考模型的第三层网络层。两者之间分工明确,默契合作,完成通信过程。IP地址专注于网络层,将数据包从一个网络转发到另外一个网络;而MAC地址专注于数据链路层,将一个数据帧从一个节点传送到相同链路的另一个节点。
4、传输层:
定义了一些传输数据的协议和端口号(WWW端口80等),如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的), 主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组,常常把这一层数据叫做段。传输协议同时进行流量控制,或是根据接收方接收数据的快慢程度,规定适当的发送速率,解决传输效率及能力的问题。
5、会话层:
通过传输层(端口号:传输端口与接收端口)建立数据传输的通路,主要在你的系统之间发起会话或者接受会话请求(设备之间需要互相认识可以是IP也可以是MAC或者是主机名)。维持和终止通信,在一层协议中,可以解决节点连接的协调和管理问题。
6、表示层:
确保一个系统的应用层发送的消息可以被另一个系统的应用层读取,编码转换,数据解析,管理数据的解密和加密。例如,PC程序与另一台计算机进行通信,其中一台计算机使用扩展二一十进制交换码(EBCDIC),而另一台则使用美国信息交换标准码(ASCII)来表示相同的字符。如有必要,表示层会通过使用一种通格式来实现多种数据格式之间的转换。
7、应用层:
是最靠近用户的OSI层,这一层为用户的应用程序(例如电子邮件、文件传输和终端仿真)提供网络服务。
七层协议是用来参考看看而已,你编写的应用协议层最好的就是只有一层!有那编写七层协议的时间,不如多出去玩耍。
不同设备的时钟不一样,从而速度也不一样,单端IO口最大翻转速度200MBPS。
FIFO(First In First Out) 是一种先进先出的数据缓存器;只能顺序写入数据,或顺序的读出数据,其数据地址由内部读写指针自动加1完成,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。FIFO一般用于不同时钟域之间的数据传输。
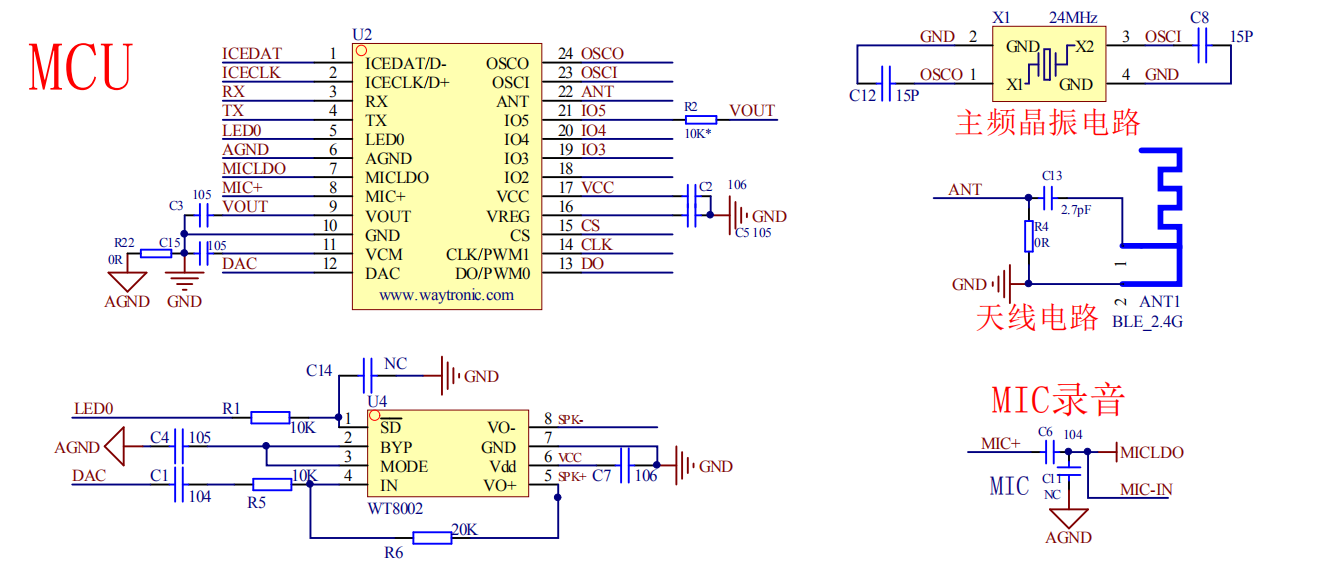
一、拟规划的外部设备
时钟速度都是可以在设备配置寄存器中选择的!设备也都可以关闭、以降低功耗。FIFO缓冲区的收发单元数、可程序设置。设备挂接在256位内部设备总线DB(Device bus)上:主频2GHZ,速度64GB(字节)/S,归属空间管理员Sadm负责,DDR5.0的A通道:速度25.6GB(字节)/S。
1、一路异步串口和RS485口的二线复用(去除时钟CLK的SPI口变形而成):串口最大速度25Mbps,RS485口最大速度25Mbps,FIFO缓冲区收发各有最大2单元。简明的物理层,可自定义通信协议层,技术员亲和度极高。
因为串口没有传输同步时钟信号,必须从信号中用高速定时器8倍采样检测起始位以得到异步时钟,起始位最小位宽:1/( 200MBPS/8 ) = 40ns。提高串口最大速度到100Mbps,应该也可以、只是高速定时器要到800MHZ以上。芯片内设1.6GHZ定时器时钟,可支持16倍过采样边沿检测。
2、三路SPI/I2S/AC97/SAI/SPDIF可接音频IC的2*4线接口,可配置为音频光纤SPDIF输入输出接口:24576kbps,最大200Mbps。
⚫同步串行口4线SPI:
MISO:主模式下接收数据输入/从模式下输出数据。
MOSI:主模式下发送数据输出/从模式下输入数据。
SCK: SPI 主器件的串行时钟输出引脚以及 SPI 从器件的串行时钟输入引脚。
SS :从器件选择引脚。可用于:选择单个从器件以进行通信,同步数据帧或检测多个主器件之间是否存在冲突。
SPI口支持与外部器件进行半双工、全双工和单工同步串行通信。该接口可配置为主模式或从模式,并且能够在多从或多主配置中运行。
保护配置和设置:
速度最大设置可为200Mbps,帧长度从 4 到 256 位的任意值,SPI Motorola 和 TI 格式支持;
数据之间的最小延时,以及 SS 与数据流之间的最小延时均可调, 对于主模式和从模式都可以通过硬件或者软件进行 SS 管理;
可配置的 SS 信号极性和时序,MISO 与 MOSI 交换功能;
可调节的主器件接收器采样时间,可编程的时钟极性和相位;
可编程的数据顺序,最先移位 MSB 或 LSB;
可以对传输的数据量进行编程,以控制 SS 和 CRC;
用于确保可靠通信的硬件 CRC 功能: 在发送模式下可以添加CRC 校验值,在接收模式下,自动进行 CRC 错误校验;
用户自定义模式:在发送模式下可以自动添加帧头(最大4位、如同SPDIF的报头模式 B、M 和 W)、帧尾(CRC或奇偶校验位P),在接收模式下,自动进行错误校验及去除帧头和帧尾;
可触发中断的主模式故障、上溢或下溢标志以及 CRC或P 错误检测;
停止模式(未向外设 IP 提供时钟)下从器件发送和/或接收功能,以及唤醒功能;
可配置的 FIFO 阈值(数据打包)、数据包之间发送延时量设置、以适应从设备FIFO深度,FIFO缓冲区收发各有最大64单元(兵乓2块),可触发中断的专用发送和接收标志。
⚫可配置为I2S音频模式:支持I2S Philips 标准,LSB 或 MSB 对齐标准,PCM 标准。
SDO:串行数据输出(映射到 MOSI),在主模式下发送音频采样以及在从模式下接收音频采样。
SDI:串行数据输入(映射到 MISO),在主模式下接收音频采样以及在从模式下发送音频采样。
WS:字选择(映射到 SS ),表示帧同步。主模式下被配置为输出,从模式下被配置为输入。
CK:串行时钟(映射到 SCK ),表示串行位时钟。主模式被配置为输出,从模式为输入。
当某些外部音频设备需要使用主时钟输出时,可以使用其它引脚:
MCK:主时钟(单独映射),适用于 I2S 配置为主模式的情况。主时钟频率固定为 256 x FWS (其中 FWS 为音频采样频率)。
⚫可配置为SAI音频模式:可配置为支持 I2S 标准、LSB 或 MSB 对齐、PCM/DSP、TDM 和 AC97 等协议。
SAI_SD:串行数据输出(映射到 MOSI),主模式发送音频采样以及在从模式接收音频采样。
SAI_SI:串行数据输入(映射到 MISO),主模式接收音频采样以及在从模式发送音频采样。
SAI_FS: 帧同步(映射到 SS ),它在主模式被配置为输出,在从模式被配置为输入。
SAI_SCK:串行时钟(映射到 SCK ),表示串行位时钟。主模式配置为输出,从模式为输入。
当某些外部音频设备需要使用主时钟输出时,可以使用其它引脚:
SAI_MCLK:主时钟(单独映射),适用于 SAI 配置为主模式的情况。主时钟频率固定为 256 x FWS (其中 FWS 为音频采样频率)。
SAI_CK:PDM(数字麦克风) 比特流时钟。PDM_SCL
SAI_D:PDM 比特流数据。PDM_SDA
注:数字麦克风接口、芯片不提供,有些音频编解码IC有这功能接口。在此,SAI音频模式、I2S、SPI是没多少区别(配置时协议设置),随意使用。
⚫可配置为音频光纤SPDIF或同轴电缆模式:符合 IEC-60958 和 IEC-61937 标准或用户自定义模式的 S/PDIF 流。
SPDIF_TXD:串行音频光纤数据输出(映射到 MOSI),主模式下发送音频光纤采样数据。
SPDIF_RXD:串行音频光纤数据输入(映射到 MISO),主模式下接收音频光纤采样数据。
IEC-60958 和 IEC-61937 标准的SPDIF 块包含 192 个帧。每个帧由两个 32 位的子帧构成,通常一个子帧用于左通道,一个用于右通道。每个子帧由一个 SOPD 模式(4 位)构成,用于指定该子帧是否为块的开始(报头B),或者是否标识块中某处通道 A(报头M),或者是否指代通道 B(报头W)。
最大符号率:12.288 Mbps = 192k(采样率)*64位。这些标准支持高采样率的简单立体声以及压缩的多通道环绕声,如 Dolby 或 DTS 定义的音频。
位 0 到位 3 包含同步报头之一(报头B、M、W)。
位 4 到位 27 包含以线性 2 的补码表示的音频采样字D0--D23,最高有效位 (MSB) 为位 27。
位 28(有效性位“V”)表示数据是否有效(例如转换为模拟数据)
位 29(用户数据位“U”)包含用户数据信息,如光盘的音轨编号。
位 30(通道状态位“C”)包含通道状态信息,如采样率和复制保护。
位 31(奇偶检验位“P”)包含奇偶校验位,这样位 4 到位 31(含)将含偶数个“1”和偶数个“0”。
一帧64位中只有48位+6位、的有效数据,位“V”、“C”、“U”、对技术员的亲和度较差。接收和发送使用2倍位流的比特流双相符号编码(曼彻斯特数据流),也就是说实际传输的符号率为:24576kbps = 2*12288kbps。为最大程度减小传输线路上的直流分量值,并加快时钟从数据流中恢复的速度,位 4 到位31 采用双相符号编码,同步报头B、M、W自然是从4位变为8位编码。可以在双相协议驱动层软件实现双相符号编解码,那么物理层自然还是SPI口。
或许低成本塑料光纤口也就25Mbps带宽,实际只传输12.288 Mbps、损失一半带宽,似乎有点说不过去。双相符号编码在同轴电缆上应用还行,但光纤口还有“直流分量值”?是故,提供了用户自定义模式,不再通过双相符号编码;一帧64位都是有效数据,硬件自动插入或去除同步报头4位和报尾1位奇偶校验,实际1帧是69位;报头就相当于串口的“起始位”,只是取消了串口的“停止位”吧;传输帧速度同步并非最重要,用25Mbps也行,充分理解:流、协议层、物理层、链路层、数据块、帧、等概念,才是真正重要的事情;采样率、时钟、等,在接收方是可以重建的!
3、一路I2C二线接口(这里是用于连接音频编解码IC、如ES8388):速度最大1Mbps,FIFO缓冲区收发各有最大2单元。
I2C(内部集成电路)总线接口、处理微控制器与串行I2C 总线间的通信。它提供多主模式功能,可以控制所有 I2C总线特定的序列、协议、仲裁和时序。它支持标准模式 ( Sm、100kbps )、快速模式 ( Fm、400kbps ) 和超快速模式 ( Fm+、1Mbps )。它还与 SMBus(系统管理总线)和 PMBus(电源管理总线)兼容。该接口通过数据收或发引脚 (SDA) 和时钟引脚 (SCL) 连接到 I2C总线。可以用SPI口单工模式来模拟I2C口,SDA(MOSI)、SCL(SCK),只是将SCK时钟频率调低、MOSI脚输出时配置为OC门输出。这样一来,连接音频编解码IC只需一路SPI口(I2S模式和芯片配置时的模拟I2C之SPI单工模式)了,这路I2C被用于HDMI2.1口、属于GPU显示接口的设备(不是挂在设备总线DB上)。
理论的东西、我都是从难到易,方案性能规划无限放大;而实际动手时、我都是从易到难,无限简化、反复推敲;“多一个香炉多一个鬼”、能去除一个部件、就得想法去除。“飞鸡1号小电脑”、我想象的只是一包烟大小、呵呵。这2个多月时间动手做了十多对音箱,换不同喇叭各种试听,得到一点小经验,慢慢来、不急。
飞鸡1小电脑音频接插口:
ES8388的1路差分输入ADC和2路DAC输出,没有隔直电容、带保护。ADC/DAC为24-bit, 8 kHz to 96 kHz sampling frequency。
微eDP扩展口插座方案:485口(串口)半双工 + 1路差分SPI口 + 1路可扩充光纤同轴双绞线输入输出口 + 24位的ADC/DAC口 。
1 3 5 7 9 11 13 15 17 19
MOSI+ MOSI- SCLK+ SCLK- SPDIFO+ SPDIFO- GND LOUT2 ROUT2 AND
2 4 6 8 10 12 14 16 18 20
MISO+ MISO- RS485+ RS485- SPDIFI+ SPDIFI- GND LIN2 RIN2 +5V
可扩充光纤同轴双绞线输入输出口、也可以作为另一路同步差分SPI口,这样就有双路同步差分SPI口。飞鸡2号12路1600W纯数字直推功放板的主芯片,我原以为一片就可以直推16路功放;现在看来算力差远了,一片只能直推8路(还需做过流、过压、检测和保护,还需对每路功放的输出做高速ADC采样以便小电脑(因功放芯片没有力气了)计算音箱阻抗、频响曲线、距离、AI推理);16路96khz采样率音频数据,每路每秒都需要AI插值到3072K点(3百多万点啊),想靠芯片内的DSP、就算是普通线性插值都够呛;另外还有2路需支持音频带宽768Khz、24位的超高清监听DAC,最终总释放速度:16路*3072K*24位 = 1.18Gbps。还得靠小电脑的算力才能AI插值(有点类似3D图形的Tessellation(细分曲面)技术),这得增加传输带宽,双路同步差分SPI可到2*200Mbps、但实际只用100Mbps(功放芯片的SPI口速率低,我没办法,将来得重选芯片)。
我的K歌(以后试验会使用的抖音号,193801013838ch)、预计会有3到10级的实时AI运算过程;
⚫设备预调:播放母带信号源,音响设备AI微调模块(计算音箱阻抗、频响曲线、距离、负反馈AI学习推理,真实表现母带信号),AI插值模块(曲线细分技术,需大数据AI分析、交互、调整)。
⚫素质提升:自动网上音乐知识、乐器演奏,学习、推理、联想记忆库、音乐专家AI模块。
⚫前端处理:信号源:无损立体声数据流、ADS_LLS(无损音质)_WIFI6_LIN1和ADS_LLS_WIFI6_RIN1,高端wifi话筒的数据流(192khz采样、24位ADC)ADS_HMIC_WIFI6_IN0。前端混合模块输出6路数据流:原始三路、混合右粗节奏同步RIN1 + HMIC、混合左粗节奏同步LIN1 + HMIC、LIN1+ RIN1。EQ(equalizer)33段均衡频响调节AI模块,时空混响效果处理AI模块。
⚫中端处理:各个专业、业余歌星、原唱对同一首歌的演唱,做大数据分析、学习,云端建立模型的比对分析微调AI模块;保留演唱者音色、特点,然后做音域扩宽、专业音准和节奏的特色专业细调AI模块。
⚫后端处理:高频相位补偿、时域频域微调的AI音频修饰模块,音响设备AI微调模块,曲线细分AI插值模块。
⚫后台处理:高度智能化的人机交流AI模块(声音模式识别,自然语言处理,学习、推理、联想记忆数据库)。
小电脑必将成为音乐全才、怪才,我们必须坚持“天赋不足设备补”的精神。
4段音频带话筒监听耳机3.5插座:(插入检测IO1线)
LOUT1、ROUT1、立体声监听输出和1路差分话筒MIC输入(使用了LIN1、RIN1)。
4段连接手机(k歌)3.5插座:(插入检测IO2线)
LIN2、RIN2、立体声输入(伴奏输入)和1路话筒混响mixR输出。
差分话筒MIC输入、或者手机伴奏输入立体声信号到ES8388、24位ADC成为数字信号,ES8388不能同时采样2路信号上传,话筒、伴奏信号必须有一个来自wifi话筒或wifi伴奏、或文件音频伴奏或MAC网络或USB过来的伴奏信号。话筒和伴奏信号再经过小电脑软件各种音效处理、回到ES8388经过24位DAC混合输出mixR回到手机,也或者最终的混合数字信号直接经网络回归“全民k歌”软件。
4、一路连接板上装有AOS的FLASH的6线SDIO接口:半双工、200MB/s(四线DDR模式)。
IO0/SO:(映射到 SPI0_MOSI),在双线/四线模式中为双向 IO,单线模式中为串行输出。
IO1/SI: (映射到 SPI0_MISO),在双线/四线模式中为双向 IO,单线模式中为串行输入。
CS1: 片选择(映射到 SPI0_SS ),低电平有效。
CLK: 串行时钟(映射到SPI0_SCK ),表示串行位时钟,FLASH (4GB)的时钟。
IO2: (映射到 SPI1_MOSI),在四线模式中为双向 IO。
IO3: (映射到 SPI1_MISO),在四线模式中为双向 IO。
实际上就是用2路SPI拼接而成,双线模式时是一路SPI。
FLASH (4GB)四线模式:uboot(6KB)、aos(10KB)、类库(设备驱动、设备协议层驱动、图形处理库)、基础应用软件。
5、高速差分通信接口:POE RJ45口,一对接收和一对发送差分信号线,速度总共为32Gbps、等效PCIe 5.0X1。
⚫每对差分线(收或者发)的FIFO缓冲区有最大64K单元(2MB),对于差分线串行通信的研发、必须投入大力量。
⚫必须坚守物理层的清晰表达与简洁。
⚫你得想象高速差分通信接口、和SPI口并没有太多的区别,它只是通信速度快一些、缓冲区大一些、同步时钟嵌入在收发信号中吧。
⚫4相调制(等效相位调制2位),64种电平、或说64种差分电流的6位幅度调制,这样一来、传送每个符号是8位二进制数,就类似QAM256。
⚫如果连接的是光模块,只好用16相调制(等效相位调制4位),传送每个符号是4位二进制数,还需I2C配置口。
⚫调整差分总线频率f(或说符号率速度)就会得到不同的8倍f传输速度,f = 2GHZ、传输速度16Gbps,收发全双工就是32Gbps、等效PCIe 5.0。
⚫高速串行差分通信口一帧最少为一个单元256位,帧头必须有24位“流标识”符、24位实际有效字节数(实际只是21位、最大2MB,最高位乃中断位、其余2高位备用)和16位帧长度(单元数)。
⚫24位“流标识”符:第一个字节、数据流类型,第二个字节、协议规则(压缩标准(低4位)、源接口等等)、第三个字节、数据流通道(最高位1输入,0位输出)。比如:音频数据流ADS_MP3_USB2.0_LIN3,MP3压缩来源USB2.0接口的音频数据流第三输入左通道。
⚫数据流类型通常有:音频流、视频流、视音频混合流、文件流、MAC网络数据流(里面又包含各种数据流)、分离后的二级流、中间数据流、中间混合流、AI流、原始流、等等,具体有待规划。
⚫8/10b编码没有太多意义,在协议驱动层略为软件补偿一下线路共模就OK;128/130b编码也就是看作一帧256位后补偿4位(也可做为帧同步),其实、差分放大器可以做到共模或者差分对线平均直流电平无关,这类8/10b编码、更多是考虑商业因素或砖家叫兽的空想。很多场合下,通常是直接连光纤模块,要其何用?
⚫高速(G级)的DAC、ADC技术并不复杂,为何做到几千元/片?那是因为老外妄想技术垄断,国产的又以为很难。基础原理就那样了、简单明白,工艺上改进差分对管的速度、做到8位DAC、10G点/秒、没难度。我一个“散装业余玩家”,没条件去做实验。
⚫跳变沿过补偿:比如差分驱动电源是1.8V,弄个开关管、上半桥在跳变沿瞬间接通3.3V电源(不用担心过电流、线路上等效串联电阻有2*100欧的)约30ps;因为哪一个瞬间、下半桥的下臂还没断开(有死区时间的)上臂也没导通,之后、即使存在下半桥上下臂导通的情形,而时间太短暂、功耗也可忽略不计;即使存在下半桥上下臂都断开的情形,电流也可以通过下半桥上臂二极管流到1.8V电源。这样做的因素,就是使得接收端的100欧电阻跳变哪一瞬间有相对较大的电流,线路电容影响减弱;终是使得跳变沿的斜率变陡峭,可以走更高的符号频率、如8GHZ,或许64Gbps可以实现。至于接收端的高频补偿,那是差分放大器之工艺实现。上下半桥是差分相对的!
⚫PCI总线已经发展到PCI-Express时代,这是一个串行高速总线,分为X1、X2、X4、X8、X12、X16和X32七种模式;
X1模式有2对差分线,1对收1对发,X2模式有4对差分线,2对收2对发,其它类推。
PCIe 1.0(8/10b编码)X1的1对(收发)差分线全双工速率为2.5Gbps(250MB/S),
PCIe 2.0(8/10b编码)X1的1对(收发)差分线全双工速率为5.0Gbps(500MB/S),
PCIe 3.0(128/130b编码)X1的1对(收发)差分线全双工速率可达8.0Gbps(1GB/S),
PCIe 4.0(128/130b编码)X1的1对(收发)差分线全双工速率可达16Gbps(2GB/S),
PCIe 5.0(128/130b编码)X1的1对(收发)差分线全双工速率可达32Gbps(4GB/S)。
⚫小电脑有1个POE RJ45通信口插座:POE供电2*30W或2*70W。收发差分线速度:32Gbps、等效PCIe 5.0X1。
引脚:
1、 TX_D1+ Tranceive Data+(发送数据+)
2、TX_D1- Tranceive Data-(发送数据-)
3、 RX_D2+ Receive Data+(接收数据+)
4、 +20V/1.5A或+48V/1.5A 短距离(小于5米)电源
5、 +20V/1.5A或+48V/1.5A 短距离(小于5米)电源(设备拔插自动检测IO3线)
6、 RX_D2- Receive Data-(接收数据-)
7、 GND
8、 GND
⚫POE RJ45口用于连接“多功能硬盘盒”(wifi6.0 + 4盘位*SATA3.0 + SSD固态硬盘 + 5口千兆路由器 + 2*usb2.0 + usb3.0 + SDXC卡座)。
小电脑的键盘、鼠标、遥控、等等,只能是通过无线wifi6.0来进入。
二、GPU显示接口
0组(主组)最大32个多核单元:主要有5大多核单元(木、火、土、金、水)(实际32核、16个多核单元GPU),GPU = ALU + SVCU
生发管理员Badm:2*GPU、肝木血藏魂,主生发,文件节点树。
时间管理员Tadm:2*GPU + APIC。心火藏神,为调度(运)、为“动力”,为定时器、时间线。
空间管理员Sadm:APU(2*GPU + MMU、A通道32GB、DDR5.0) + 通用外设(5*SPI + POE RJ45(PCIe5.0X1) + RS485)。脾土肉藏意。
界面管理员Iadm: APU(2*GPU + MMU、B通道32GB、DDR5.0) + 6*GPU + 显示外设(DP + HDMI2.1/eDP + I2C)。肺金气藏魄,主气息出入界面。
通信管理员Cadm:2*GPU 、肾水精藏志。核间的消息通信IPC(Internal Process Communication)、组间通信仲裁器。
1、多用途DP/eDP显示插座:全双工或半双工通信、PCIe5.0X2,速度64Gbps。
如果游戏发烧玩家、想追求更高的效果,那这插口就是外接高级显卡的全双工通信口、PCIe5.0X2,等效于PCIe4.0X4、等效于PCIe3.0X8、等效于PCIe2.0X16。小电脑(主要是界面管理员Iadm小组)只是负责:坐标、建模、纹理信息、光影、部分AI运算、等等,而传输到显卡的大多是:多边形、顶点、等数据信息,并没有占据多大带宽、PCIe5.0X2足足有余。
界面管理员Iadm多核单元只是在显存速度略为比高级显卡差些,多核单元内总线也可以做到2048位总线、带宽可达到512GB(字节)/S的;如果每组多核单元另外伸出1024位总线外接DDR5.0三十二通道,也是可以做到32*25.6GB(字节)/S = 819.2GB(字节)/S。但这些追求,我认为有点过份了,得不偿失,还不如将精力放在游戏AI和内容上。
DP/eDP插口:半双工输出连接显示屏最大速率:64Gbps(8GB(字节)/S)。
1、ML_Lane0(p) 对应PCIe5.0X2的 PCIe_TX0P
2、GND
3、ML_Lane0(n) 对应PCIe5.0X2的 PCIe_TX0N
4、ML_Lane1(p) 对应PCIe5.0X2的 PCIe_RX0P
5、GND
6、ML_Lane1(n) 对应PCIe5.0X2的 PCIe_RX0N
7、ML_Lane2(p) 对应PCIe5.0X2的 PCIe_TX1P
8、GND
9、ML_Lane2(n) 对应PCIe5.0X2的 PCIe_TX1N
10、ML_Lane3(p) 对应PCIe5.0X2的 PCIe_RX1P
11、GND
12、ML_Lane3(n) 对应PCIe5.0X2的 PCIe_RX1N
13、GND
14、GND
15、AUX_CH(p) 对应定制aux口
16、GND
17、AUX_CH(n)
18、Hot Plug GPIO线
19、DP_PWR Return
20、DP_PWR
当连接显卡时,显卡功耗几百瓦、只能是另外的显卡电源供电。
8K高清屏:8K*4K*3B(三基色)*60帧/S = 5.76 GB/S = 46.08Gbps。一帧缓存为96MB。
4K高清屏:4K*2K*3B(三基色)*60帧/S = 1.44 GB/S = 11.52Gbps。一帧的缓存为24MB。
是故,DP/eDP显示口可以带2个30帧的4K高清屏和一个60帧的8K高清屏。
2、多用途DP/eDP/HDMI2.1/MIPI_CSI/MIPI_DSI显示插座(HDMI插口):全双工或半双工通信、PCIe2.1X2,速度12Gbps(1GB(字节)/S)。
DP/eDP/MIPI_DSI模式:2个30帧的4K高清屏或一个60帧的4K高清屏。
HDMI2.1模式:1个30帧的6K高清屏(6K*2K*3B(三基色)*30帧/S = 8.64Gbps),aux口切换为I2C,PCIe_TX0差分线切换为差分时钟输出线。
MIPI_CSI摄像头模式:支持1千6百万像素、30帧/S,8千万像素、6帧/S。
通信口模式:PCIe2.1X2/PCIe1.1X2。
三、高速内部总线HSIB
1、理论
一路驱动扇出到多个输入,在低频时问题不大,高速时就不行了;是故,任一时刻、总线上只能有一对核在通信,一个输出、一个输入;核到总线的通道得使用双向MOS开关切换,一个MOS开关大约是2个mos管吧,相比几十亿晶体管的芯片、不算什么,估计是芯片内部的多层立体布线麻烦。三态门驱动串接一堆部件的总线方法、只有在差分驱动情形下可以了。这都是输入电容若的祸,大约COMS门输入电容有5PF,如果工艺好的、会更小一些。
以下为粗略估算:
电压V = 电路I * 阻抗R,设R = 100欧、V = 3.3V,那I = 33mA、功耗P = 109mW;如果V降低一半为1.65V,那功耗P = 109mW /4 = 27.23mW。
如果只是阻抗R变小一半,那功耗也会降低一半。是故,降低电源电压对降低驱动功耗效果明显。
当驱动频率f为10MHZ时,20个输入门的等效电容C为100PF,容抗
R = 1 / 2*PI*f*C = 1 / ( 2*3.14*10^7*10^-10 ) = 159 欧。
设 V = 3.3V,那 I = 20.73mA、功耗P = 68.4mW。
当驱动频率f为2GHZ时,20个输入门的等效电容C为100PF,容抗
R = 1 / 2*PI*f*C = 1 / ( 2*3.14*2*10^9*10^-10 ) = 0.796 欧。
设 V = 3.3V,那 I = 4147mA、功耗P = 13.685 W。呵呵,256路驱动时、几千瓦,芯片完了。
如果只是一个输入门。等效电容C为5PF,容抗
R = 1 / 2*PI*f*C = 1 / ( 2*3.14*2*10^9*5*10^-12 ) = 15.9 欧。
设 V = 3.3V,那 I = 207.3mA、功耗P = 684mW。
设 V = 1.0V,那 I = 62.83mA、功耗P = 62.83mW。如果是256路驱动,那 I = 16.085 A、
功耗P = 16.085 W。呵呵,这仅是总线驱动、还有一大推逻辑门在运作啊,岂非要上千瓦。
我这个“多科小白”对IC工艺更是一窍不通,只能猜测吧。或许新的IC工艺可以降低等效电容C为2PF以下?也或许新工艺对高速电路很少用速度略低的PMOS管,也或许结合了更快的NPN管、BiCMOS工艺?我不懂了,也或许将来会用差分驱动取代单端驱动。又为何DDR5.0单端驱动也可以到达6.4Gbps?诶、世上牛鬼多去了。
总之,多扇出一个门、就会多一倍的功耗,总线某时刻只能是点对点通信,其它断开;就如同SRAM、DDR、等存储器,可以集成有几百亿单元,但只有地址选择的对应单元才会“接通开关”连接到数据总线上。总之,高频时的IC功耗大是不可避免的、鱼和熊掌是不可兼得,想降低功耗、只能是降低电源电压。
当然,降低频率、容抗也会相应升高,自然地、低功耗也就可以实现,但高速度没了。
NPN管比PNP管快的原因是NPN的基子少子是电子,PNP的是空穴,电子的迁移率比空穴大。NMOS比PMOS快也是这个原因。而NPN比NMOS快的原因是NPN是体器件,其载流子的迁移率是半导体内的迁移率;NMOS是表面器件,其载流子的迁移率是表面迁移率(因为反形层是在栅氧下的表面形成的)。而半导体的体迁移率大于表面迁移率。
2、组内256位高速内部总线HSIB:64GB(字节)/S。参考示意图。
通信管理员Cadm:2*GPU 、肾水精藏志。核间的消息通信IPC(Internal Process Communication),组内及组间的通信仲裁器。
芯片分为8组。组间仲裁器IARB嵌入在主组通信管理员Cadm的RALU核,以便配置和管理。
主组:最大32个多核单元 + 外围设备 + 组间仲裁器IARB(Intergroup arbiter)(硬件实现),7副组、每个副组: 最大32个多核单元。
为简化通信协议,取消组仲裁器GARB、只有一个组间仲裁器IARB;每个多核单元属于某个小组,由小组内的管理员调配小组内的成员间通信。
通信管理员Cadm、生发管理员Badm、时间管理员Tadm的小组内外通信总线都是256位总线,速度64GB(字节)/S,为GPU小组。
通信管理员Cadm多核单元小组:2*GPU(RALU + SVCU)+ 组间仲裁器IARB、管理员仲裁器AARB(Administrator arbiter)合一(硬件实现)。
主组内部、及组间总线4*256位,速度256GB(字节)/S。
其它多核单元小组内部、副组以及组间总线位数酌情规划。
DDR5.0的每个通道:速度25.6GB(字节)/S。
SVCU核、并非是可以运行程序,虽然它有很多AU算术运算单元,但没有逻辑运算单元LU和位操作单元BOU;原因只是为了简化和集成更多的AU算术运算单元,SVCU是RALU的伴生核。
SVCU核:输入输出缓存8MB,256个通道,每个通道16管道。
0号通道0号管道:对int32、也支持并行逻辑运算:AND、OR、EOR、BIC、ORN。
4条管线int32/2条管线int64/2条管线双精度浮点FP64/2条管线双精度十进制浮点LFP64/1条管线四精度浮点FP128/1条管线四精度十进制浮点LFP128。
其它每个管道:管线4种模式可程序配置与切换。
FP32单精度浮点4条管线(GPU的4D、或2*2D、1D+3D、模式),FP16半精度浮点或int16整数为8条管线,int8整数为16条管线。
RALU核:cache最大8MB,统一管理(含SVCU核8MB的SRAM)、共16MB。24位本地SRAM地址,AISC指令集(内含内存读写CISC指令集)。
界面管理员Iadm多核单元APU小组256位内部总线,速度:64GB(字节)/S;类似PCIe5.0X2和PCIe2.1X2的显示接口设备、以及GPU们都是挂接在APU小组256位内部总线上;GPU们通过申请应答线使用总线,设备则通过中断请求来使用总线。APU带MMU虚拟内存管理单元,伸出到外部DDR5.0的一个通道40位总线(不含地址线、控制线等)、速度25.6GB(字节)/S。
显示口设备每对差分线(收或者发)的FIFO缓冲区有最大64K单元(2MB),AUX的FIFO缓冲区最大2K单元(64KB)。
空间管理员Sadm多核单元APU小组256位内部总线,速度:64GB(字节)/S;通用外设(5*SPI + POE RJ45(PCIe5.0X1)+ RS485),以及GPU们都是挂接在APU小组256位内部总线上;GPU们通过申请应答线使用总线,设备则通过中断请求来使用总线。APU带MMU虚拟内存管理单元,伸出到外部DDR5.0的一个通道40位总线(不含地址线、控制线等)、速度25.6GB/S。
每一个多核单元属于一个小组,或说属于某个管理员。
一个多核单元的某核想和小组内的另一个某核通信时:
1)、它得先向管理员AARB申请(专线)(1个时钟周期),因为也可能在同一时刻有另外的某某核也在做同样的事情,尽管ns级碰撞的几率极小;
2)、AARB会据优先级批复应答(专门应答线)(1个时钟周期),是否可占据小组内部总线;如果否(也许总线忙),只有先撤销申请、等待或...;
3)、如果是,则需报告AARB需通信的对方核地址(开关接通8位目标地址线到AARB)(1个时钟周期);
4)、跟着,AARB断开小组地址线连接、将通信双方核之开关接通到小组内部总线(1个时钟周期),它们可以开始主从半双工通信了;双方通信结束后,需撤销“申请线信号”、AARB将通信的2核之开关断开到小组内部总线连接(1个时钟周期)、以便它方使用小组内部总线。
管理员仲裁器AARB是硬件实现,建立小组内连接时间(如果小组内总线空闲)4时钟周期2ns。
如果小组内的某核想和另一个小组的某核通信时:
1)、它得先向管理员AARB申请(专线)(1个时钟周期),因为也可能在同一时刻有另外的某某核也在做同样的事情,尽管ns级碰撞的几率极小;
2)、AARB会据优先级批复应答(专门应答线)(1个时钟周期),是否可占据小组内部总线;如果否(也许总线忙),只有先撤销申请、等待或...;
3)、如果是,则需报告AARB需通信的对方核地址(开关接通8位目标地址线到AARB)(1个时钟周期),并占住小组内部总线。
4)、AARB向组间仲裁器IARB申请(专线)(1个时钟周期),
5)、当组内总线忙碌时,批复应答、否(1个时钟周期);
6)、空闲时、IARB会连接小组内地址总线到相应空闲的一条组内总线上,接收8位目标地址;如目标小组总线忙碌(专线),批复否(1个时钟周期);
7)、如果组内总线和目标小组总线空闲,IARB将通信的2核之开关接通到小组内和组内总线、同时也断开8位目标地址线,它们可以开始主从半双工通信了;双方通信结束后,需撤销“申请线信号”、IARB将通信的2核之开关断开到小组内和组内的总线连接(1个时钟周期)、以便它方使用总线。建立组内2核通信的连接时间(如果小组内和组内总线空闲)6时钟周期3ns。


四、芯片的AISC指令集
比较测试指令类:CMP比较、CMN(负数比较)、TST测试、TEQ相等测试。与SUB、ADD、AND、EOR、相比,只是刷新状态寄存器SR相应标志、而不传送结果吧,是故取消。因为带有SVCU,运算类指令减弱。CISC指令集(复杂指令集Complex instruction set computer)(含读-修改-写的相关指令、SVCU操控指令、通信指令、等等),还在规划。
AISC压缩16位指令集(A instruction set computer)简写汇编为28条指令束:
X0---X15,X15专用装配,X14 = LR,X13 = PC,X12 = SP,X11 = SR状态标志寄存器,X10 = 0。内核与用户各一套16个寄存器。有立即数的指令占去16位64K编码空间的56K,R类的指令编码空间不到8k,不兼容RISC-V指令集。
ALU算术逻辑运算类:10
ADD{I} Xd, Xm|imm8; // 加法(addition),Xd += Xm,或者 Xd += imm8,NZCV。
ADD8 Xd, Xm; // 无符号8字节并行加法,8*ZiCi(HI标志)。
SUB Xd, Xm|imm8; // 减法(subtraction),Xd - = Xm,或者 Xd - = imm8 ,NZCV。
SUB8 Xd, Xm; // 无符号8字节并行减法,8*ZiCi(HI标志)。
EOR{I} Xd, Xm|imm8; // 按位异或(Exclusive or),Xd += ^Xm,或者 Xd += ^ imm8,NZC。
OR{I} Xd, Xm|imm8; // 按位或(or),Xd += | Xm,或者 Xd += | imm8,NZC。
AND{I} Xd, Xm|imm8; // 按位与(and),Xd += & Xm,或者 Xd += & imm8,NZC。
MOV Xd, Xm; // 寄存器移动(move),Xd = Xm + X10,NZC。
MOVK Xd', Xm'; // MOVK为内核指令,在用户端寄存器和内核端寄存器之间传送、以便监控。Xd' = Xm' + X10,NZC。
MOVI X15.imm3, imm8; // 寄存器X15装配一个字节,X15.imm3 = imm8,imm3为字节号。跳转类:offset_imm10、offset_imm11、偏移有符号数,label符号位扩展到64位。5
B{Cond} label(offset_imm10);// 条件相对跳转(Branch),转移到 Label 处对应的地址,范围+-500条指令,PC+ = label,LR = PC + 2。
B label(offset_imm11) // 无条件相对跳转,转移到 Label 处对应的地址,范围:+-1K条指令,PC+ = label,LR = PC + 2。
BPC Xd, Xm; // 远端长距离无条件调用跳转、需先压栈,PC+= Xn[Xm],Xn跳转表(模块库)半字基址,Xm半字相对偏移。
BKPT immed_10; // 预取中止 或 进入调试状态。 指令中编码为 10 位的位域。
MOV{Cond} Xd, Xm; // 条件传送指令,减少分支。CISC指令集(复杂指令集Complex instruction set computer)入口类:(含读-修改-写的相关指令、SVCU操控指令、通信指令、等等)
LMRW Xd, Xm; // 本地内存(Local memory)(ITCM、DTCM、CACHE、SVCU空间、配置空间、总线FIFO)读写、CISC指令集。
EMRW Xd, Xm; // 外部内存(External Memory DDR5.0、设备、CPU节点)读写、CISC指令集。BO(Bit Operation)位操作类:纵横交叉开关网络。11
SLL{I} Xd, Xm|imm6; // 逻辑左移(shift left logical),低位移入0,NZC。
SRL{I} Xd, Xm|imm6; // 逻辑右移(shift right logical),高位移入0,NZC。
SRA{I} Xd, Xm|imm6; // 算数右移(shift right arithmetic),符号移入高位,NZC。
SRC Xd, Xm; // 循环(圆圈)右移(shift right Cyclic ),移位次数为Xm数值,NZC。
SRCC Xd, Xm; // 带进位循环(圆圈)右移(shift right Cycle Carry),移位次数为Xm数值,NZC。
BT Xd, Xm|imm6; // 位测试(bit test),复制指定位到进位C标志位。
BF{C|I|XS|XU} Xd, Xm; // 位域(Bit Field )运算:清0(Clear ),插入(insert),有符号提取XS,无符号提取XU。
BFI8 Xd, Xm; // 插入Xm[7:0]字节到Xd的8个字节位置,用SUB8可以做一个字节与8个字节的并行比较。
BI Xd, Xm; // Xd寄存器的指定位、置位或清0。
R{EV|EV32|BIT} Xd, Xm; // 8字节反转,32位大小端转换,反转(reverse)64位字的位顺序。
CLZ Xd, Xm; // 从最高位起计算前导零数目(Count left zero),Xd = Xm 中的前导零的数目。
总结
如果某个“老牛鬼”,晚上做了一个梦,第二天发明了“某某新协议”;比如“LVDS梦”中、抄抄得到的协议就有一大坨:HDMI、DP、eDP、MIPI_DSI、MIPI_CSI、PCIe1.0、PCIe2.0、PCIe3.0、PCIe4.0、PCIe5.0、有线以太网MAC口、SATA3.0、USB2.0、USB3.0、type_c、等等。每一个
协议再软硬件分层,那设备驱动、设备层协议驱动程序就好多、好多了;世界上的“牛鬼蛇神”多去,说不定会有上千万个驱动程序,你能熟悉完?为此耗尽一生?那也太不值了。人生应该是“吃喝玩乐”为主业,工作为副业!