1、项目背景
以英国的在线电子零售公司的跨国交易数据集作为分析样本,通过对该公司的运营指标统计分析以及构建RMF模型、K-Means机器学习算法从大量的电子零售交易数据中分析并找出价值用户,针对价值用户提供以消费者为中心的智能商业模式。
2、数据详情
2.1 数据来源
数据集来自一个在英国注册的在线电子零售公司,其中包含2010年12月1日到2011年12月9日期间发生的网络交易数据。
2.2 数据量
数据集总共有541909条数据,8个字段
2.3 数据理解
| 字段名 | 含义 |
|---|---|
| InvoiceNo | 发票编号。为每笔订单唯一分配的6位整数。若以字母’C’开头,则表示该订单 被取消。 |
| StockCode | 产品代码。为每个产品唯一分配的编码。 |
| Description | 产品描述。 |
| Quantity | 数量。每笔订单中各产品分别的数量。 |
| InvoiceDate | 发票日期和时间。每笔订单发生的日期和时间。 |
| UnitPrice | 单价。单位产品价格,单位为英镑。 |
| CustomerID | 客户编号。为每个客户唯一分配的5位整数。 |
| Country | 国家。客户所在国家/地区的名称 |
3、数据清洗
3.1 准备工作
# 导入库
import pandas as pd
import numpy as np
import datetime as dt# 数据可视化库
import matplotlib.pyplot as plt%matplotlib inline
#更改设计风格
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['SimHei']#(显示中文)
plt.rcParams['axes.unicode_minus'] = False#(显示负数)
import seaborn as sns# 机器学习算法库
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeansimport warnings
warnings.filterwarnings("ignore")
#导入数据
salesOR = pd.read_csv('Online Retail.csv')
#查看数据
salesOR.head()
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | |
|---|---|---|---|---|---|---|---|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 2010/12/1 8:26 | 2.55 | 17850.0 | United Kingdom |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 2010/12/1 8:26 | 3.39 | 17850.0 | United Kingdom |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 2010/12/1 8:26 | 2.75 | 17850.0 | United Kingdom |
| 3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6 | 2010/12/1 8:26 | 3.39 | 17850.0 | United Kingdom |
| 4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6 | 2010/12/1 8:26 | 3.39 | 17850.0 | United Kingdom |
查看数据信息
salesOR.shape
(541909, 8)
salesOR.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 InvoiceNo 541909 non-null object 1 StockCode 541909 non-null object 2 Description 540455 non-null object 3 Quantity 541909 non-null int64 4 InvoiceDate 541909 non-null object 5 UnitPrice 541909 non-null float646 CustomerID 406829 non-null float647 Country 541909 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 33.1+ MB
3.2 删除重复值
salesOR_NoDup=salesOR.drop_duplicates(subset=['InvoiceNo','StockCode','Description','Quantity','InvoiceDate','UnitPrice','CustomerID','Country'])
dup=salesOR.shape[0]-salesOR_NoDup.shape[0]
print('duplicates =',dup)
duplicates = 5268
共删除了5268条重复数据
3.3 缺失值处理
查看数据缺失情况
tab_info=pd.DataFrame(salesOR.dtypes).T.rename(index={0:'特征类型'})
tab_info=tab_info.append(pd.DataFrame(salesOR.isnull().sum()).T.rename(index={0:'缺失值数量'}))
tab_info=tab_info.append(pd.DataFrame(salesOR.isnull().sum()/salesOR.shape[0]).T.rename(index={0:'缺失值占比'}))
display(tab_info)
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | |
|---|---|---|---|---|---|---|---|---|
| 特征类型 | object | object | object | int64 | object | float64 | float64 | object |
| 缺失值数量 | 0 | 0 | 1454 | 0 | 0 | 0 | 135080 | 0 |
| 缺失值占比 | 0.0 | 0.0 | 0.002683 | 0.0 | 0.0 | 0.0 | 0.249267 | 0.0 |
从上表可以看出,有近25%的条目未分配给特定客户。在现有的数据下,不可能为用户估算出数值,因此这些条目对目前的工作没有用处。所以应当从数据框中删除它们。
#删除InvoiceNo和CustomerID字段中的缺失数据
salesOR_NoDupNA=salesOR_NoDup.dropna(subset=['InvoiceNo','CustomerID'],how='any')
missing=salesOR_NoDup.shape[0]-salesOR_NoDupNA.shape[0]
print('missings =',missing)
missings = 135037
共删除InvoiceNo 和 CustomerID字段缺失的数据135037条
3.4 数据一致化处理
将字符串类型数据转化为数值类型
salesOR_NoDupNA['Quantity']=salesOR_NoDupNA['Quantity'].astype('float')
salesOR_NoDupNA['UnitPrice']=salesOR_NoDupNA['UnitPrice'].astype('float')
salesOR_NoDupNA['CustomerID']=salesOR_NoDupNA['CustomerID'].astype('object')
print('Data type after changing:\n',salesOR_NoDupNA.dtypes)
Data type after changing:InvoiceNo object
StockCode object
Description object
Quantity float64
InvoiceDate object
UnitPrice float64
CustomerID object
Country object
dtype: object
将字符串类型数据转化为日期类型
#将InvoiceDate数据转换成日期的数据类型,如果不符合日期的格式,转换后的值为空值
salesOR_NoDupNA['InvoiceDate']=pd.to_datetime(salesOR_NoDupNA['InvoiceDate'], errors='coerce')
#分离出年、月、日、星期几方便之后分析
#这样得到的数据依旧是一个整形数据
salesOR_NoDupNA['Year'] = salesOR_NoDupNA['InvoiceDate'].dt.year
salesOR_NoDupNA['Month'] = salesOR_NoDupNA['InvoiceDate'].dt.month
salesOR_NoDupNA['Date'] = salesOR_NoDupNA['InvoiceDate'].dt.date
salesOR_NoDupNA['weekday'] = salesOR_NoDupNA['InvoiceDate'].dt.weekday
salesOR_NoDupNA.head()
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | Year | Month | Date | weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6.0 | 2010-12-01 08:26:00 | 2.55 | 17850.0 | United Kingdom | 2010 | 12 | 2010-12-01 | 2 |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6.0 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom | 2010 | 12 | 2010-12-01 | 2 |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8.0 | 2010-12-01 08:26:00 | 2.75 | 17850.0 | United Kingdom | 2010 | 12 | 2010-12-01 | 2 |
| 3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6.0 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom | 2010 | 12 | 2010-12-01 | 2 |
| 4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6.0 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom | 2010 | 12 | 2010-12-01 | 2 |
数据转换过程中不符合日期格式的会转换为空值,需要再进行一次删除缺失值处理。
#转换日期过程中不符合日期格式的数值会被转换为空值,
#这里删除InvoiceDate,InvoiceTime,CustomerID,InvoiceNo中为空的行
salesOR_NoDupNA=salesOR_NoDupNA.dropna(subset=['InvoiceNo','CustomerID','InvoiceDate'],how='any')
3.5 异常值处理
#利用描述性指标(describe)查看是否有异常值。
salesOR_NoDupNA[['Quantity','UnitPrice']].describe()
| Quantity | UnitPrice | |
|---|---|---|
| count | 401604.000000 | 401604.000000 |
| mean | 12.183273 | 3.474064 |
| std | 250.283037 | 69.764035 |
| min | -80995.000000 | 0.000000 |
| 25% | 2.000000 | 1.250000 |
| 50% | 5.000000 | 1.950000 |
| 75% | 12.000000 | 3.750000 |
| max | 80995.000000 | 38970.000000 |
描述指标中购买产品的数量最小值为-8095,单品单价为0,这两个不符合实际情况确认为异常值。
querySer=salesOR_NoDupNA.loc[:,'Quantity']>0
salesOR_NoDupNA=salesOR_NoDupNA.loc[querySer,:]
querySer1=salesOR_NoDupNA.loc[:,'UnitPrice']>0
salesOR_NoDupNA=salesOR_NoDupNA.loc[querySer1,:]
print('after delete outlier:',salesOR_NoDupNA.shape)
after delete outlier: (392692, 12)
经过两次条件判断之后数据集大小为(392692,10),为了检查处理后的结果,再次检查描述指标:
salesOR_NoDupNA[['Quantity','UnitPrice']].describe()
| Quantity | UnitPrice | |
|---|---|---|
| count | 392692.000000 | 392692.000000 |
| mean | 13.119702 | 3.125914 |
| std | 180.492832 | 22.241836 |
| min | 1.000000 | 0.001000 |
| 25% | 2.000000 | 1.250000 |
| 50% | 6.000000 | 1.950000 |
| 75% | 12.000000 | 3.750000 |
| max | 80995.000000 | 8142.750000 |
原数据集的时期是2010-12-1到2011-12-09,2011年12月数据不满一个月,为了方便分析和讨论本次分析选择数据时间为:2010-12-01到2011-11-30,12个月。
querySer2=salesOR_NoDupNA.loc[:,'InvoiceDate']<'2011-12-01'
salesOR_NoDupNA=salesOR_NoDupNA.loc[querySer2,:]
print('删除2011-11-30之后的数据:',salesOR_NoDupNA.shape)
删除2011-11-30之后的数据: (375666, 12)
4、运营指标统计分析
4.1 月追踪:月销售量、月销售额、月均销售额
4.11 月销售量
#因为每月交易 = 总唯一交易数,又因为相同的InvoiceNo包含不同的产品,所以需要计算唯一的InvoiceNo
transUni=salesOR_NoDupNA.drop_duplicates(subset=['InvoiceNo'])
monthly_trans=transUni.groupby(['Year','Month'])['InvoiceNo'].count()
print('月销售量 :\n',monthly_trans)
月销售量 :Year Month
2010 12 1400
2011 1 9872 9973 13214 11495 15556 13937 13318 12809 175510 192911 2657
Name: InvoiceNo, dtype: int64
#绘制月销售量条形图
fig,ax = plt.subplots(figsize=(8,3))
monthly_trans.plot(kind='bar')
plt.xlabel('月份')
plt.ylabel('销售量')
plt.title('月销售量')
plt.show()
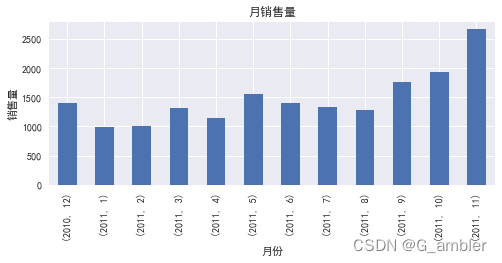
计算结果显示2011年9月、10月、11月的销售单数稳步增长,2011年11月达到最高值2657单,怀疑平台年末促销或者换季用户大量购买冬季产品导致,可以通过查询销售额占比最高的产品确认。
4.12 月销售额
#新增列Amount = Quantity * UnitPrice
salesOR_NoDupNA['Amount']=salesOR_NoDupNA.Quantity*salesOR_NoDupNA.UnitPrice
monthly_sales=salesOR_NoDupNA.groupby(['Year','Month'])['Amount'].sum()
print('月销售额:\n',monthly_sales)
月销售额:Year Month
2010 12 570422.730
2011 1 568101.3102 446084.9203 594081.7604 468374.3315 677355.1506 660046.0507 598962.9018 644051.0409 950690.20210 1035642.45011 1156205.610
Name: Amount, dtype: float64
fig,ax = plt.subplots(figsize=(8,4))
monthly_sales.plot(kind='bar')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.title('月销售额')
plt.show()
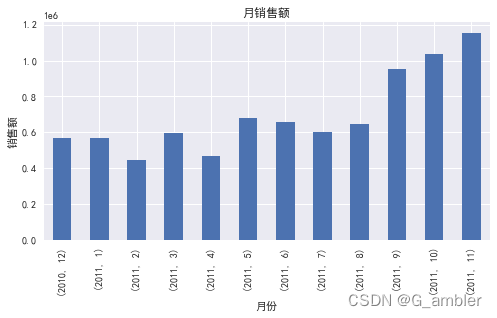
在销售额方面,2011年9月、10月、11月的销售额明显高于其他月份,虽然11月的总销售单数比10月要高出近(2657-1929)/1929100%≈38%但是11月的总销售额却只比10月高出(1156205.610-1035642.450)/1035642.450100%≈11.6%,初步评价2011年10月的销售情况最佳,可以重点看看10月份的销售活动。
4.13 月均销售额
monthSales=salesOR_NoDupNA.groupby(['Year','Month'])['Amount'].sum()
avg_monthSales=round(monthSales.sum()/12,2)
print('月均销售额:',avg_monthSales)
月均销售额: 697501.54
计算得出月均销售额为697501.54英镑,2011年9、10、11月远超平均值。
4.2 周追踪:周销售量、周销售额、周均销售额
4.21 周销售量
transUni=salesOR_NoDupNA.drop_duplicates(subset=['InvoiceNo'])
weekly_trans=transUni.groupby(['weekday'])['InvoiceNo'].count()
print('周销售量:\n',weekly_trans)
周销售量:weekday
0 2747
1 3074
2 3351
3 3801
4 2674
6 2107
Name: InvoiceNo, dtype: int64
发现没有数字5,查找源数据集里是否不包含5的星期数。 真的没有5,查看原始数据以及对应的星期数,5代表星期六。
fig,ax = plt.subplots(figsize=(8,3))
x = ['周一', '周二','周三','周四','周五','周日']
y = weekly_trans
plt.plot(x,y)
plt.xlabel('星期')
plt.ylabel('周销售量')
plt.show()
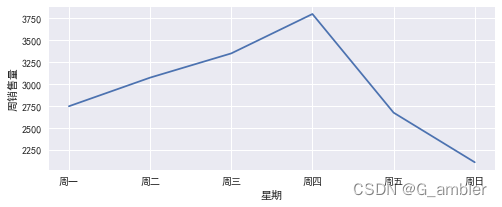
此处计算的是在一年观察时间段内,每个星期天数的累计订单数。星期四的订单数是最多的,怀疑有公司(周末不上班)在该电商平台购买用品和礼品。这里要特别提醒上面的结果是一年里面每一个星期的累计单数,数据集没有星期六的销售订单,需要跟电商公司确认。
4.22 周销售额
weeklySales=salesOR_NoDupNA.groupby(['weekday'])['Amount'].sum()
print('周销售额:\n',weeklySales)
周销售额:weekday
0 1305523.311
1 1651744.141
2 1515053.230
3 1878214.400
4 1254225.051
6 765258.321
Name: Amount, dtype: float64
fig,ax = plt.subplots(figsize=(8,4))
x = ['周一', '周二','周三','周四','周五','周日']
y = weeklySales
plt.plot(x,y)
plt.xlabel('星期')
plt.ylabel('周销售额')
plt.show()
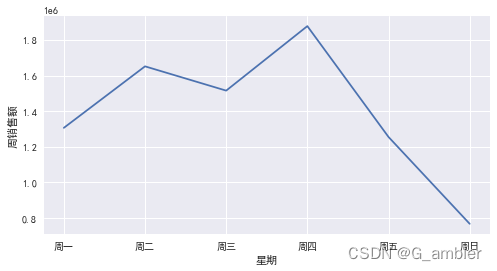
跟销售量相吻合,累计周销售量在星期四达到峰值,临近周末回落,高度怀疑该电商平台出售的产品不是针对普通家庭消费者,因为周末是消费的低谷跟实际情况不符。
4.23 周均销售额
avg_weeklySales=round(weeklySales.sum()/52,2)
print('周均销售额:',avg_weeklySales)
周均销售额: 160961.89
计算结果为160961.89欧元,这是每周平均销售额,给运营者提供一个参考,可以初步评价每一星期的销售情况,是高于还是低于平均值。
4.3 效率指标:客单价、件单价、连带率、退货金额
4.31 客单价
total_Sales=salesOR_NoDupNA.Amount.sum()
total_customer=salesOR_NoDupNA.drop_duplicates(subset=['CustomerID']).shape[0]
#Sales per customer
sales_perCustomer=round(total_Sales/total_customer,2)
print('客单价=',sales_perCustomer)
客单价= 1947.87
客单价=总的销售额/总的客户数,计算结果客单价为1947.87欧元,也即一年里面每个消费者平均贡献了1947.87欧元。
4.32 件单价
total_product=salesOR_NoDupNA.Quantity.sum()
#Sales per item
sale_perItem=round(total_Sales/total_product,2)
print('件单价=',sale_perItem)
件单价= 1.72
件单价=销售总额/售出产品总数量,计算结果为每件产品的平均价格为1.72欧元。
4.33 连带率
total_transUni=transUni.shape[0]
joint_Rate=round(total_product/total_transUni,2)
print('连带率=',joint_Rate)
连带率= 274.04
连带率=售出的产品总数/总的交易单数,计算结果连带率=274.04,在分析的一年时间段里,每一笔交易售出的平均产品总数为274件,这里怀疑有大量采购的用户。
4.34 每月新客占比
grouped_user =salesOR_NoDupNA.groupby(['CustomerID'])
user_life = grouped_user['InvoiceDate'].agg(['min','max'])
user_life.head(10)
| min | max | |
|---|---|---|
| CustomerID | ||
| 12346.0 | 2011-01-18 10:01:00 | 2011-01-18 10:01:00 |
| 12347.0 | 2010-12-07 14:57:00 | 2011-10-31 12:25:00 |
| 12348.0 | 2010-12-16 19:09:00 | 2011-09-25 13:13:00 |
| 12349.0 | 2011-11-21 09:51:00 | 2011-11-21 09:51:00 |
| 12350.0 | 2011-02-02 16:01:00 | 2011-02-02 16:01:00 |
| 12352.0 | 2011-02-16 12:33:00 | 2011-11-03 14:37:00 |
| 12353.0 | 2011-05-19 17:47:00 | 2011-05-19 17:47:00 |
| 12354.0 | 2011-04-21 13:11:00 | 2011-04-21 13:11:00 |
| 12355.0 | 2011-05-09 13:49:00 | 2011-05-09 13:49:00 |
| 12356.0 | 2011-01-18 09:50:00 | 2011-11-17 08:40:00 |
(user_life['min'] == user_life['max']).value_counts()
False 2757
True 1540
dtype: int64
可以算出2757/(2757+1540)≈64%的顾客都在此购买了不止一次
salesOR_NoDupNA['month'] = salesOR_NoDupNA.InvoiceDate.values.astype('datetime64[M]')
#按月份和用户ID分组
grouped_month_user = salesOR_NoDupNA.groupby(['month','CustomerID'])#将 当月用户订单日期最小值 与 用户订单日期最小值 联结
tmp = grouped_month_user.InvoiceDate.agg(['min']).join(grouped_user.InvoiceDate.min())# 判断用户当月订单日期最小值是否与用户订单日期最小值相等,新建字段new,new代表新客户
tmp['new'] = (tmp['min'] == tmp.InvoiceDate)# 重置索引列,并按月分组,作新客占比折线图
tmp.reset_index().groupby('month').new.apply(lambda x: x.sum()/x.count()).plot()
plt.title("新客占比折线图")
plt.xlim('2010-12','2011-11')
plt.show()
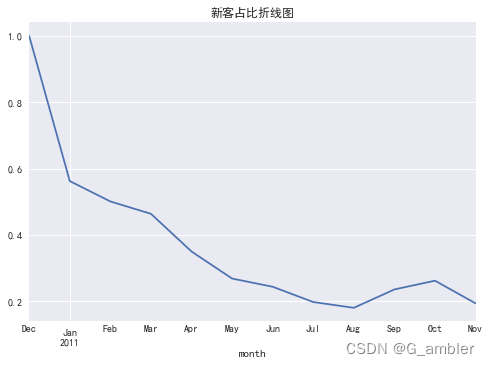
可以看出从去年12月到今年8月,每月新客数都在急剧下降。
4.35 复购率
复购率:即当月内,购买多次的用户占比
#用户每个月的消费次数
pivoted_counts=salesOR_NoDupNA.pivot_table(index='CustomerID',columns='month',values='InvoiceDate',aggfunc='count').fillna(0)
pivoted_counts.head()
| month | 2010-12-01 | 2011-01-01 | 2011-02-01 | 2011-03-01 | 2011-04-01 | 2011-05-01 | 2011-06-01 | 2011-07-01 | 2011-08-01 | 2011-09-01 | 2011-10-01 | 2011-11-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | ||||||||||||
| 12346.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 12347.0 | 31.0 | 29.0 | 0.0 | 0.0 | 24.0 | 0.0 | 18.0 | 0.0 | 22.0 | 0.0 | 47.0 | 0.0 |
| 12348.0 | 17.0 | 6.0 | 0.0 | 0.0 | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3.0 | 0.0 | 0.0 |
| 12349.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 73.0 |
| 12350.0 | 0.0 | 0.0 | 17.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
#用户每个月的消费次数
pivoted_counts=salesOR_NoDupNA.pivot_table(index='CustomerID',columns='month',values='InvoiceNo',aggfunc='nunique').fillna(0)
pivoted_counts.head()
| month | 2010-12-01 | 2011-01-01 | 2011-02-01 | 2011-03-01 | 2011-04-01 | 2011-05-01 | 2011-06-01 | 2011-07-01 | 2011-08-01 | 2011-09-01 | 2011-10-01 | 2011-11-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | ||||||||||||
| 12346.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 12347.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 12348.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 12349.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 12350.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
# applymap() 如果消费超过1次则赋值为1 若等于1则赋值为0 若无消费则赋值为空
purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0)
purchase_r.head()
| month | 2010-12-01 | 2011-01-01 | 2011-02-01 | 2011-03-01 | 2011-04-01 | 2011-05-01 | 2011-06-01 | 2011-07-01 | 2011-08-01 | 2011-09-01 | 2011-10-01 | 2011-11-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | ||||||||||||
| 12346.0 | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 12347.0 | 0.0 | 0.0 | NaN | NaN | 0.0 | NaN | 0.0 | NaN | 0.0 | NaN | 0.0 | NaN |
| 12348.0 | 0.0 | 0.0 | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN |
| 12349.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 |
| 12350.0 | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# 复购率= sum()复购人数 / 总消费人数count()
(purchase_r.sum() / purchase_r.count()).plot(figsize = (10,4))plt.title('2010年12月至2011年11月公司复购率变化趋势图')
plt.xlim('2010-12','2011-11')
plt.show()
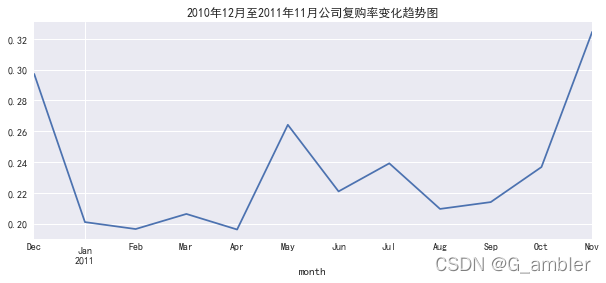
复购率在20%-30%之间波动。
4.36 退货金额
在原数据集说明中,订单号如果以字母c开头表示该订单为取消订单,所以在这里想看看退货的情况。
querySer3=salesOR_NoDupNA.loc[:,'InvoiceNo'].str.startswith('c')
querySer3.unique()
array([False])
结果显示:array([False]),该数据集中并没有包含取消的订单,所以本次分析没能够涉及这一块。
5、构建RFM模型
5.1RFM指标计算
5.11 R - Recency
Recency在这里定义为用户最后一次购物距离现在有多少个月。
#First_purchase:第一次购买日期
#Last_purchase:最后一次购买日期
Last_purchase=salesOR_NoDupNA.groupby(['CustomerID']).Date.max()
First_purchase=salesOR_NoDupNA.groupby(['CustomerID']).Date.min()
Last_purchase.head()
CustomerID
12346.0 2011-01-18
12347.0 2011-10-31
12348.0 2011-09-25
12349.0 2011-11-21
12350.0 2011-02-02
Name: Date, dtype: object
先计算出最后一次购买时间距离最后一天的天数,然后再计算月分数。
#最后一次购买时间距离最后一天的天数
Max_date=salesOR_NoDupNA.Date.max()+dt.timedelta(days=1)
Recency_days=Last_purchase.map(lambda x:(x-Max_date).days)
#最后一次购买时间距离最后一天的月数
Recency_months=Recency_days.map(lambda x:round((-1*x)/30,1))
Recency_months.head()
CustomerID
12346.0 10.6
12347.0 1.0
12348.0 2.2
12349.0 0.3
12350.0 10.1
Name: Date, dtype: float64
为了了解数据集的情况,查看一下描述统计指标。
Recency_months.describe()
count 4297.000000
mean 3.049244
std 3.285932
min 0.000000
25% 0.500000
50% 1.700000
75% 4.900000
max 12.200000
Name: Date, dtype: float64
再切片看看分布情况。
bins1=[0,1,2,3,4,5,6,7,8,9,10,11,12,13]
pd.cut(Recency_months,bins1).value_counts()
(0, 1] 1606
(1, 2] 708
(2, 3] 445
(3, 4] 228
(4, 5] 194
(5, 6] 186
(6, 7] 180
(8, 9] 156
(7, 8] 140
(9, 10] 123
(10, 11] 115
(11, 12] 81
(12, 13] 43
Name: Date, dtype: int64
大概有37.7%的客户在一个月之内有购物行为,再绘制条形图更加直观的观察数据。
pd.cut(Recency_months,bins1).value_counts().plot.bar(rot=20)
<AxesSubplot:>
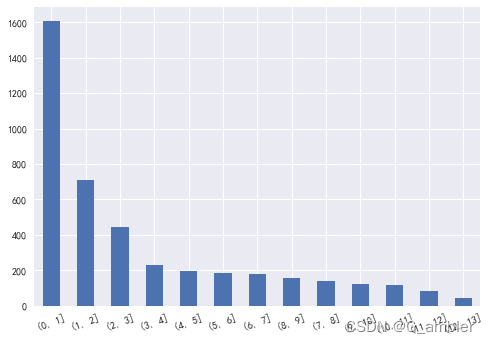
分布总体来说比较理想,可以利用以客户为中心的商业理念来提高[1, 2]以及[2, 3],即1~2个月,2~3个月之内有购物行为的用户。
5.12 F- Frequency
Frequency在这里定义为购物频率,也即在分析的一年里面,用户总购买次数。
#Freq_purchase:购物频率(多久购买一次)
Unique_purchase=salesOR_NoDupNA.drop_duplicates(subset=['InvoiceNo'])
Freq_purchase=Unique_purchase.groupby(['CustomerID']).InvoiceNo.count()
Freq_purchase.head()
CustomerID
12346.0 1
12347.0 6
12348.0 4
12349.0 1
12350.0 1
Name: InvoiceNo, dtype: int64
描述统计指标:
Freq_purchase.describe()
count 4297.000000
mean 4.131720
std 7.412705
min 1.000000
25% 1.000000
50% 2.000000
75% 4.000000
max 200.000000
Name: InvoiceNo, dtype: float64
购买的频率差异很大,最小为1次,最大为200次,切片看数据分布情况。
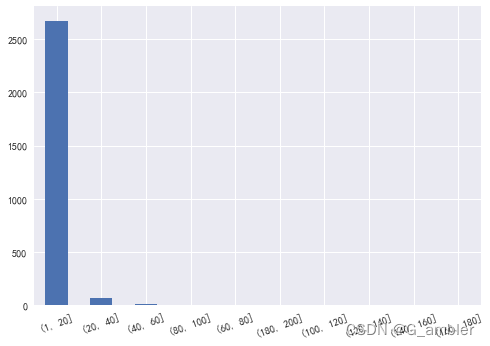
bins2=[1,20,40,60,80,100,120,140,160,180,200]
pd.cut(Freq_purchase,bins2).value_counts()
(1, 20] 2673
(20, 40] 65
(40, 60] 12
(80, 100] 4
(60, 80] 2
(180, 200] 2
(100, 120] 1
(120, 140] 0
(140, 160] 0
(160, 180] 0
Name: InvoiceNo, dtype: int64
大部分用户在一年的时间里购买次数在1~20次以内,比较符合实际情况。这里要注意有些离散的数值,比如一年里面消费100~120次的用户有1位用户,180~200次的用户有2位,后续的分析会针对这些离散值做特殊处理。
pd.cut(Freq_purchase,bins2).value_counts().plot.bar(rot=20)
<AxesSubplot:>
5.13 M - Monetary
Monetary定义为用户在一年之内所花总金额
#Money_purchase:消费金额
Money_purchase=salesOR_NoDupNA.groupby(['CustomerID']).Amount.sum()
Money_purchase.head()
CustomerID
12346.0 77183.60
12347.0 4085.18
12348.0 1797.24
12349.0 1757.55
12350.0 334.40
Name: Amount, dtype: float64
描述统计指标:
Money_purchase.describe()
count 4297.000000
mean 1947.874902
std 8351.696003
min 2.900000
25% 303.160000
50% 650.750000
75% 1594.230000
max 268478.000000
Name: Amount, dtype: float64
每个用户的消费总金额差异很大,最小值位2.9欧元,最大值位268478欧元。
再通过切片看数据分布:
bins3=[2.5,10,50,100,1000,10000,100000,200000,300000]
pd.cut(Money_purchase,bins3).value_counts()
(100.0, 1000.0] 2518
(1000.0, 10000.0] 1520
(50.0, 100.0] 119
(10000.0, 100000.0] 94
(10.0, 50.0] 36
(2.5, 10.0] 4
(100000.0, 200000.0] 4
(200000.0, 300000.0] 2
Name: Amount, dtype: int64
pd.cut(Money_purchase,bins3).value_counts().plot.bar(rot=20)
<AxesSubplot:>
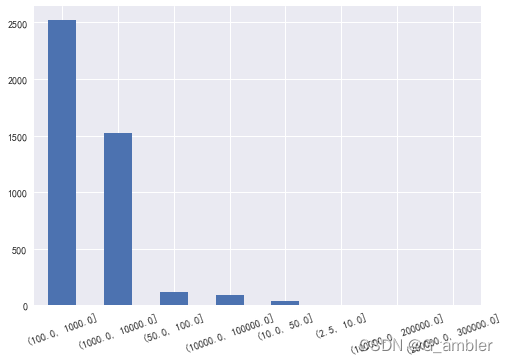
跟购物频率F一样,购买金额也存在一些离散值,后续分析中会特别处理。
综合上面的计算,RFM的三个指标的数据区间范围分别是:
R [0.0, 12.1]
F [1.0, 200.0]
M [2.9, 268478.0]
5.2 利用RFM模型挖掘价值用户
5.21 建立RFM矩阵,并给列名重命名。
#计算RFM指标
rfm=salesOR_NoDupNA.groupby(['CustomerID']).agg({'Date':lambda x:(Max_date-x.max()).days,'InvoiceNo':'count','Amount':'sum'})
#列重命名
rfm.rename(columns={'Date':'Recency','InvoiceNo':'Frequency','Amount':'Monetary'},inplace=True)
rfm.head()
| Recency | Frequency | Monetary | |
|---|---|---|---|
| CustomerID | |||
| 12346.0 | 317 | 1 | 77183.60 |
| 12347.0 | 31 | 171 | 4085.18 |
| 12348.0 | 67 | 31 | 1797.24 |
| 12349.0 | 10 | 73 | 1757.55 |
| 12350.0 | 302 | 17 | 334.40 |
RFM数据概览
sns.pairplot(rfm)
<seaborn.axisgrid.PairGrid at 0x1401bb40550>
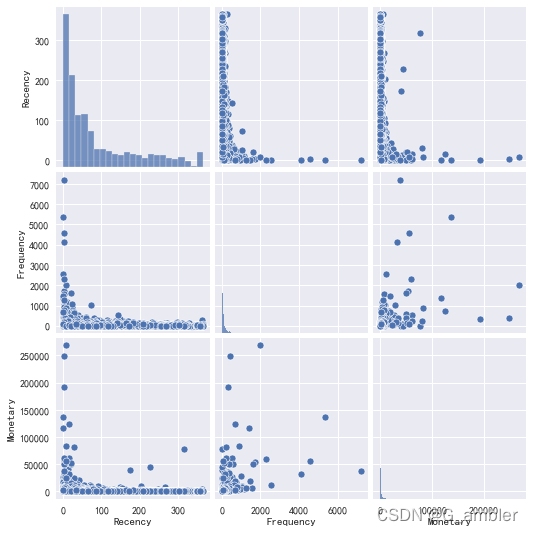
单独抽出RFM直方图观看
plt.figure(1,figsize=(12,6))
n=0
for x in ['Frequency','Recency','Monetary']:n+=1plt.subplot(1,3,n)plt.subplots_adjust(hspace=0.5,wspace=0.5)sns.distplot(rfm[x],bins=30)plt.title('{} 直方图'.format(x))
plt.show()
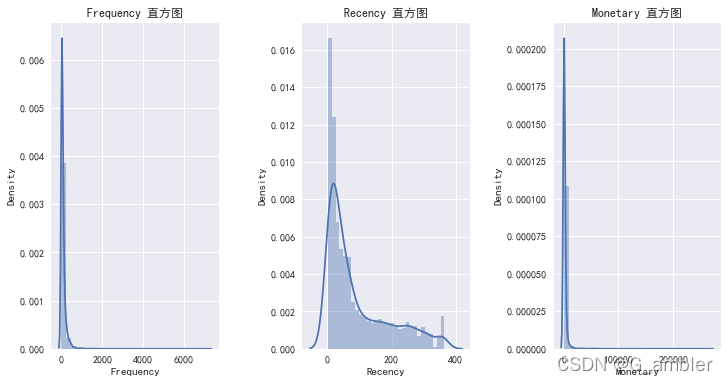
可以看出购买商品的客户绝大多数是进行少量多次购买的客户
5.22 建立用户评分机制
计算用于划分客户的阙值,R、F、M的均值(通过分布直方图可以发现该份数据不适合用中位数来分层,因此这里用均值做分层)
rfm[['Recency','Frequency','Monetary']].apply(lambda x:x-x.mean())
| Recency | Frequency | Monetary | |
|---|---|---|---|
| CustomerID | |||
| 12346.0 | 225.518501 | -86.42518 | 75235.725098 |
| 12347.0 | -60.481499 | 83.57482 | 2137.305098 |
| 12348.0 | -24.481499 | -56.42518 | -150.634902 |
| 12349.0 | -81.481499 | -14.42518 | -190.324902 |
| 12350.0 | 210.518501 | -70.42518 | -1613.474902 |
| ... | ... | ... | ... |
| 18280.0 | 177.518501 | -77.42518 | -1767.274902 |
| 18281.0 | 80.518501 | -80.42518 | -1867.054902 |
| 18282.0 | 26.518501 | -80.42518 | -1847.664902 |
| 18283.0 | -90.481499 | 583.57482 | -110.344902 |
| 18287.0 | -57.481499 | -17.42518 | -110.594902 |
4297 rows × 3 columns
创建label分析
def rfm_func(x):level = x.apply(lambda x : '1' if x>=0 else '0')label = level.Recency + level.Frequency + level.Monetaryd = {'111':'重要价值客户','011':'重要保持客户','101':'重要挽留客户','001':'重要发展客户','110':'一般价值客户','010':'一般保持客户','100':'一般挽留客户','000':'一般发展客户'}result = d[label]return resultrfm['label'] = rfm[['Recency','Frequency','Monetary']].apply(lambda x:x- x.mean()).apply(rfm_func,axis = 1)
rfm.head(10)
| Recency | Frequency | Monetary | label | |
|---|---|---|---|---|
| CustomerID | ||||
| 12346.0 | 317 | 1 | 77183.60 | 重要挽留客户 |
| 12347.0 | 31 | 171 | 4085.18 | 重要保持客户 |
| 12348.0 | 67 | 31 | 1797.24 | 一般发展客户 |
| 12349.0 | 10 | 73 | 1757.55 | 一般发展客户 |
| 12350.0 | 302 | 17 | 334.40 | 一般挽留客户 |
| 12352.0 | 28 | 85 | 2506.04 | 重要发展客户 |
| 12353.0 | 196 | 4 | 89.00 | 一般挽留客户 |
| 12354.0 | 224 | 58 | 1079.40 | 一般挽留客户 |
| 12355.0 | 206 | 13 | 459.40 | 一般挽留客户 |
| 12356.0 | 14 | 59 | 2811.43 | 重要发展客户 |
查看不同类型顾客的总数
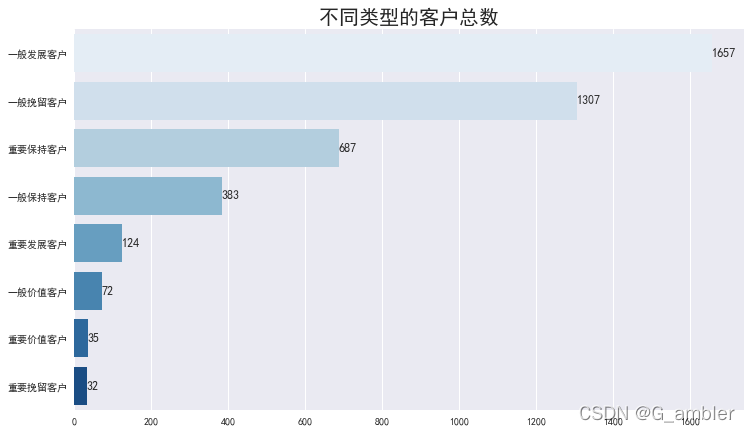
plt.figure(1,figsize=(12,7))
sns.countplot(y="label",order=rfm['label'].value_counts().index ,data=rfm,palette='Blues')
plt.title('不同类型的客户总数',fontsize=20)
plt.xlabel('')
plt.ylabel('')con=list(rfm.groupby('label').label.count().values)
con=sorted(con,reverse=True)for x,y in enumerate(con):plt.text(y+0.1,x,'%s' %y,va='center',size=12)
plt.show()
各个类型顾客收入
rfm.groupby('label').sum()
| Recency | Frequency | Monetary | |
|---|---|---|---|
| label | |||
| 一般价值客户 | 12324 | 9034 | 75783.730 |
| 一般保持客户 | 9907 | 56246 | 449782.530 |
| 一般发展客户 | 59739 | 57494 | 1051071.043 |
| 一般挽留客户 | 281214 | 31068 | 555079.770 |
| 重要价值客户 | 5738 | 5936 | 111406.171 |
| 重要保持客户 | 14553 | 207779 | 5279155.540 |
| 重要发展客户 | 3852 | 6719 | 584836.050 |
| 重要挽留客户 | 5769 | 1390 | 262903.620 |
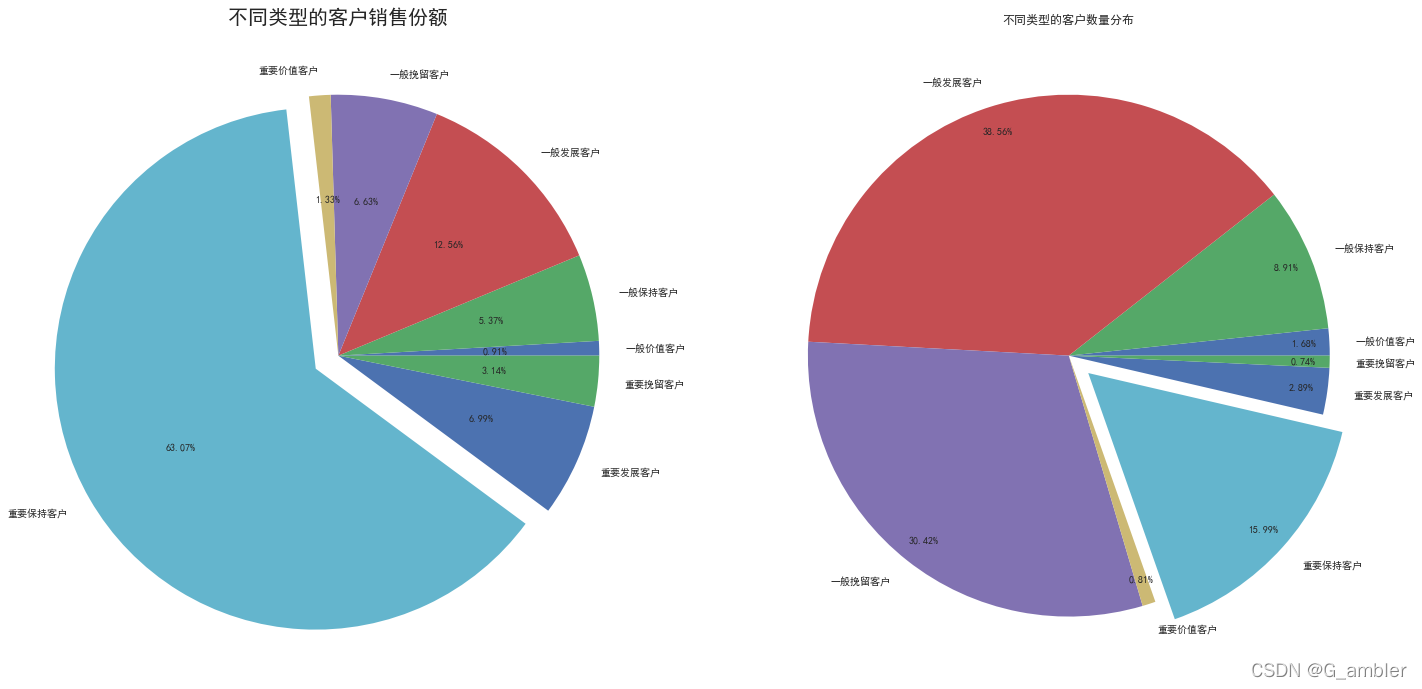
plt.figure(figsize=(24,12))
#不同类型的客户销售份额
plt.subplot(1,2,1)
plt.axis('equal')labels=rfm.groupby('label').Monetary.sum().index
explode=[0,0,0,0,0,0.1,0,0]plt.pie(rfm.groupby('label').Monetary.sum(),explode=explode,labels=labels,radius=1,autopct='%.2f%%')
plt.title('不同类型的客户销售份额',fontsize=20)#不同类型的客户数量分布
plt.subplot(1,2,2)
plt.axis('equal')
plt.pie(rfm.groupby('label').count()['Monetary'],autopct='%.2f%%',labels = labels,pctdistance=0.9,explode=explode,radius=1)
plt.title("不同类型的客户数量分布")
plt.show()
rfm.query("label=='重要保持客户'")['Recency'].describe()
count 687.000000
mean 21.183406
std 20.123775
min 1.000000
25% 7.000000
50% 14.000000
75% 30.000000
max 91.000000
Name: Recency, dtype: float64
5.3 利用K-Means算法挖掘价值用户
5.31 对数变换
rfm_k=rfm[['Recency','Frequency','Monetary']]
#unskew the data with log transformation
rfm_log=rfm[['Recency','Frequency','Monetary']].apply(np.log,axis=1).round(3)
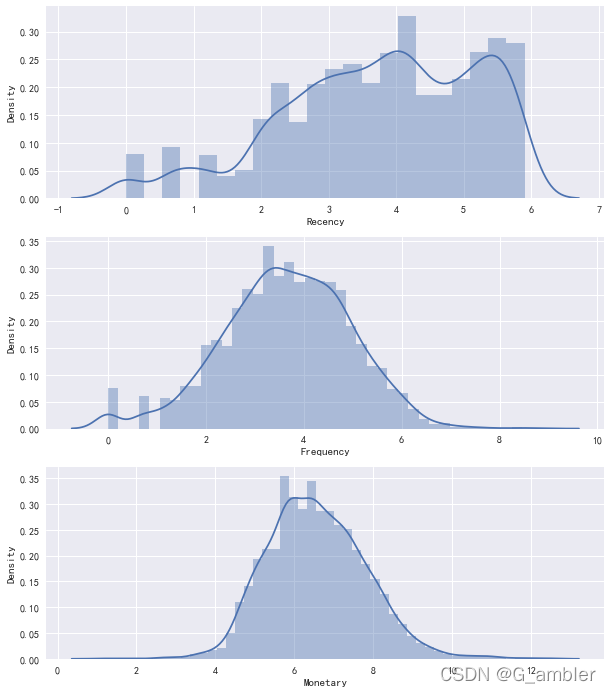
为方便查看,把三个标签的直方图画在一起。
#绘制RFM值的分布
f,ax=plt.subplots(figsize=(10,12))
plt.subplot(3,1,1);sns.distplot(rfm_log.Recency,label='Recency')
plt.subplot(3,1,2);sns.distplot(rfm_log.Frequency,label='Frequency')
plt.subplot(3,1,3);sns.distplot(rfm_log.Monetary,label='Monetary')
plt.show()
5.32 标准化
对数变换之后是标准化,使用公式:Z=(X-μ)/σ 可以使用scikit-learn里面preprocessing下面的StandardScaler实现标准化转换。
#使用StandardScaler对变量进行归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(rfm_log)
#单独存储用于聚类
rfm_normalized=scaler.transform(rfm_log)
5.33 选择适合的聚类数目
选择聚类数目的方法有好几种,这里采用的是Elbow Criterion method。
ks = range(1,8)
inertias=[]for k in ks:kc = KMeans(n_clusters=k, random_state=1)kc.fit(rfm_normalized)inertias.append(kc.inertia_)#样本到它们最近的聚类中心的平方距离的总和
把计算的1-8个聚类数目情况画在一起,寻找Elbow弯点。
f,ax = plt.subplots(figsize=(10,6))
plt.plot(ks,inertias,'-o')
plt.xlabel('Number of clusters,k')
plt.ylabel('Inertia')
plt.title('KMeans 的弯点是多少?')
plt.show()
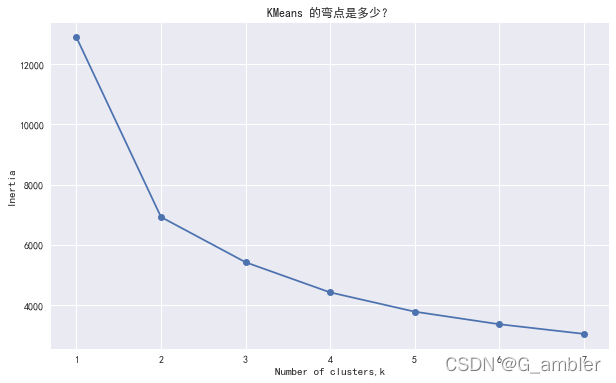
选择cluster_k=3进行分组聚类计算。
# clustering
kc=KMeans(n_clusters=3,random_state=1)
kc.fit(rfm_normalized)# 在原始DataFrame中创建一个簇标签列
cluster_labels = kc.labels_# 计算每个集群的平均 RFM 值和大小
rfm_k3=rfm_k.assign(k_cluster=cluster_labels)
rfm_k3.groupby('k_cluster').agg({'Recency':'mean','Frequency':'mean','Monetary':['mean','count']}).round(0)
| Recency | Frequency | Monetary | ||
|---|---|---|---|---|
| mean | mean | mean | count | |
| k_cluster | ||||
| 0 | 174.0 | 15.0 | 290.0 | 1464 |
| 1 | 67.0 | 58.0 | 1057.0 | 1818 |
| 2 | 17.0 | 245.0 | 5935.0 | 1015 |
通过对比RFM模型得出这里的三个聚类0,1,2最具有价值的用户群是k_cluster = 2这个类别的用户。利用K-Means算法把用户进行分类,从而挖掘出价值用户,得出分析的最终结果。
rfm_k3.head()
| Recency | Frequency | Monetary | k_cluster | |
|---|---|---|---|---|
| CustomerID | ||||
| 12346.0 | 317 | 1 | 77183.60 | 1 |
| 12347.0 | 31 | 171 | 4085.18 | 2 |
| 12348.0 | 67 | 31 | 1797.24 | 1 |
| 12349.0 | 10 | 73 | 1757.55 | 2 |
| 12350.0 | 302 | 17 | 334.40 | 0 |
找到k_cluster=2的价值用户,对价值用户的购物行为进行针对性分析,比如消费习惯(购物时段)、喜欢购买的商品种类、购物种类的关联性(喜欢一起购买的产品)等等,这样就可以给价值用户提供个性化的消费方案,针对价值用户提供以消费者为中心的智能商业模式。
6、价值用户挖掘结果
6.1 用户画像
用户已经进行分组,接下来看看不同类型用户的消费行为特征。
#cov=方差系数
def cov(x):return np.std(x)/np.mean(x)rfm.groupby('label').agg({'Recency':['mean','std',cov],'Frequency':['mean','std',cov],'Monetary':['mean','std',cov]}).round(1)
| Recency | Frequency | Monetary | |||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | std | cov | mean | std | cov | mean | std | cov | |
| label | |||||||||
| 一般价值客户 | 171.2 | 65.7 | 0.4 | 125.5 | 40.8 | 0.3 | 1052.6 | 482.3 | 0.5 |
| 一般保持客户 | 25.9 | 21.3 | 0.8 | 146.9 | 70.6 | 0.5 | 1174.4 | 470.2 | 0.4 |
| 一般发展客户 | 36.1 | 24.7 | 0.7 | 34.7 | 22.7 | 0.7 | 634.3 | 446.5 | 0.7 |
| 一般挽留客户 | 215.2 | 78.7 | 0.4 | 23.8 | 19.7 | 0.8 | 424.7 | 357.8 | 0.8 |
| 重要价值客户 | 163.9 | 71.1 | 0.4 | 169.6 | 86.5 | 0.5 | 3183.0 | 1713.0 | 0.5 |
| 重要保持客户 | 21.2 | 20.1 | 0.9 | 302.4 | 465.7 | 1.5 | 7684.4 | 19262.5 | 2.5 |
| 重要发展客户 | 31.1 | 26.2 | 0.8 | 54.2 | 25.0 | 0.5 | 4716.4 | 6711.4 | 1.4 |
| 重要挽留客户 | 180.3 | 71.3 | 0.4 | 43.4 | 31.6 | 0.7 | 8215.7 | 15891.9 | 1.9 |
通过建立RFM模型及评分方法分组得出的结果显示,重要保持客户用户最近一次消费的平均值是21.2天,平均频率是302.4次,平均花费是7684.4英镑。
#cov=方差系数
def cov(x):return np.std(x)/np.mean(x)rfm_k3_sta=rfm_k3.groupby('k_cluster').agg({'Recency':['mean','std',cov],'Frequency':['mean','std',cov],'Monetary':['mean','std',cov]}).round(1)
rfm_k3_sta
| Recency | Frequency | Monetary | |||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | std | cov | mean | std | cov | mean | std | cov | |
| k_cluster | |||||||||
| 0 | 173.9 | 106.5 | 0.6 | 14.6 | 11.1 | 0.8 | 290.3 | 269.5 | 0.9 |
| 1 | 67.0 | 66.7 | 1.0 | 58.3 | 39.6 | 0.7 | 1056.7 | 2384.9 | 2.3 |
| 2 | 16.5 | 18.8 | 1.1 | 244.6 | 395.6 | 1.6 | 5934.8 | 16245.4 | 2.7 |
上面结果是使用K-Means方法得出的结果,价值用户最近一次消费的平均值是16.5 天,平均频率是244.6次,平均花费是5934.8英镑,结果比使用评分方法要更好一些。
6.2 价值用户对销售额的贡献
# 对不同的用户分组和进行K-means的客户数量统计
customer_num=rfm_k3.groupby('k_cluster').agg({'Recency':['count']})
#饼图
fig=plt.figure(figsize=(6,9))
test=[1815,1462,1020]
labels = [u'cluster0',u'cluster1',u'cluster2']
colors=['red','yellow','green']
patches,text1,text2 = plt.pie(test,labels=labels,colors=colors,autopct = '%3.2f%%',labeldistance = 1.2,shadow=False,startangle=90,pctdistance = 0.6)
plt.axis('equal')
plt.legend()
plt.title('各用户分组占比情况 %')
plt.show()
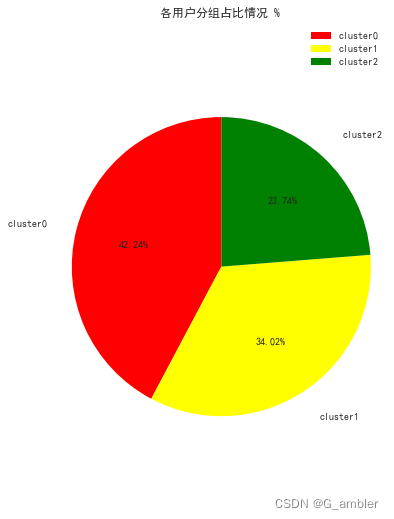
上图是用户分组的情况,按照价值贡献情况排名分别是cluster2, cluster0, cluster1,价值用户cluster2占比23.74%。下面看看不同用户分组对销售额的贡献情况。
# 使用 K-means 进行不同客用户分组和相关销售
customer_sales=rfm_k3.groupby('k_cluster').agg({'Monetary':['sum']})
# pie figure
fig=plt.figure(figsize=(6,9))
test=[1911297.113,424054.261,6034667.080]
labels = [u'cluster0',u'cluster1',u'cluster2']
colors=['red','yellow','green']
patches,text1,text2 = plt.pie(test,labels=labels,colors=colors,autopct = '%3.2f%%',labeldistance = 1.2,shadow=False,startangle=90,pctdistance = 0.6)
plt.axis('equal')
plt.legend()
plt.title('各用户分组对销售额占比情况 %')
plt.show()
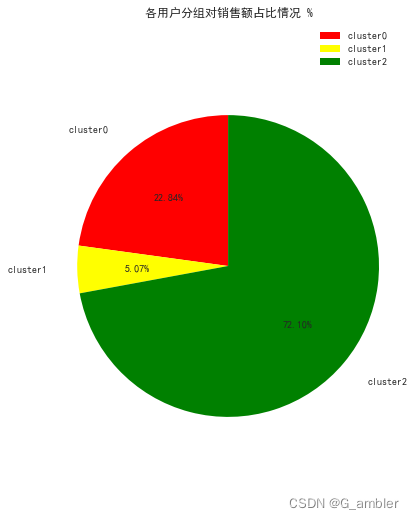
价值用户cluster2占比只有23.74%却贡献了72.10%的销售额,是业务的重点发展对象。
7、总结
本项目利用Python语言对电子零售数据进行了数据分析和挖掘,计算分析主要有两个方面:(1)运营指标统计分析;(2)使用了两种方法RFM模型以及K-Means机器学习算法挖掘价值用户。
(1)通过运营指标统计分析,了解了该电子商务公司的整体运营情况,计算了月销售数量、月销售总额、月均销售额、周销售量、周销售总额、周均销售额、客单价、件单价、连带率,月新客占比,复购率通过这些指标了解到该电子商务公司月销售单数、月销售额在2011年的9月、10月以及11月有明显的增长,周销售额在星期四达到最高值,有64%的顾客购买了两次及以上的商品,相对来说该公司的销售额是较依赖回头客的模式。占总体客户15.99%的重要保持客户,贡献了63.07%的总销售额。。
(2)为了挖掘价值用户,使用了两种方法,第一个方法是利用RFM模型对用户进行评分分组,第二个方法是利用K-Means算法对用户进行“机器学习”分组,两种方法都挖掘出价值用户,比较两种方法得出的用户画像结果,RMF模型中重要保持客户占总体客户15.99%,贡献了63.07%的总销售额,K-Means方法得出的结果更好一些,最终挖掘出的价值用户占比23.74%却贡献了72.10%的销售额。
确定价值用户之后可以进一步学习价值用户的消费习惯,从而提供以消费者为中心的智能商业模式,根据实际应用情况进行多次迭代来优化价值用户挖掘的模型。

![[20140909]oracle cluster index (11g).txt](/images/no-images.jpg)