在上一篇文章当中,我们提到了怎样使用spring来创建一个bean对象。下面,我们继续来研究一下,更加优胜的开发方式:基于注解开发【JavaEE进阶篇1】认识Spring、认识IoC、使用spring创建对象_革凡成圣211的博客-CSDN博客springIoc、使用spring创建对象https://blog.csdn.net/weixin_56738054/article/details/129540402?spm=1001.2014.3001.5502
目录
第一步:在pom.xml当中导入依赖、并且在xml文件当中添加如下内容
为什么要使用 并且指定base-package的目录?
第二步:把bean存放到IoC容器当中
类注解(作用于类上面)
@Controller:把一个类标记为"控制器"
spring给类命名的规则
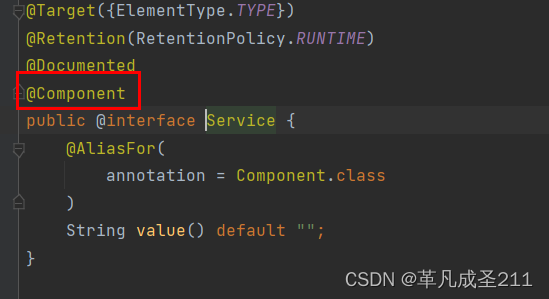
@Service
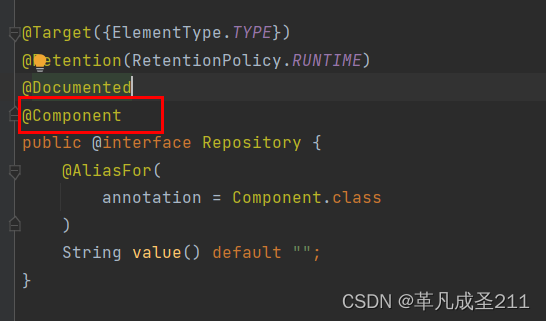
@Repository
@Component
@Configuration
为什么作用都一样,但是还是要这么多注解
5大类注解之间的关系
方法注解(作用在方法上面的注解)
第一步:新建一个User类
第二步:在另外一个类当中自定义一个返回User的方法
第三步:通过getBean方法获取User对象
第一步:在pom.xml当中导入依赖、并且在xml文件当中添加如下内容
在maven项目当中导入(pom.xml)依赖:
<dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.15.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>5.2.15.RELEASE</version></dependency></dependencies>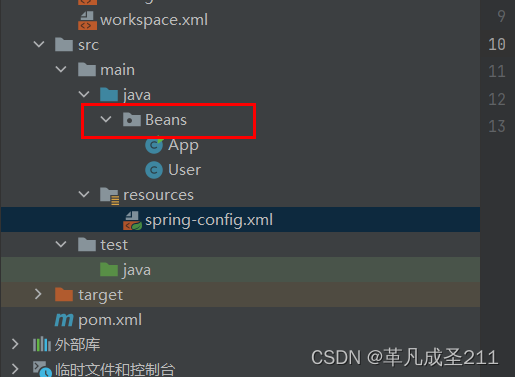
在spring配置文件当中,复制以下的内容即可。
所有要存放到spring中bean的根路径,在此处就指定为"Beans"目录及其子目录下面的所有文件。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd"><!-- 声明扫描包以及子包的类。如果发现有组件注解的类,就创建对象,并加入到容器 --><!--此时,指定的扫描包的名称为Beans,在这个包下面需要存扫描的文件--><context:component-scan base-package="Beans"/></beans>为什么要使用<context:component-scan> 并且指定base-package的目录?
在spring当中的类分为两大类,一大类是在spring当中的,另外一大类是不在spring当中的。
如果使用了这个注解,那么也就意味着:Beans目录下面的类如果被注解作用了,那么就会被放入spring容器当中。
这样设计,可以有效帮助spring减少扫描的次数,只扫描指定目录的类,提升查找的效率。
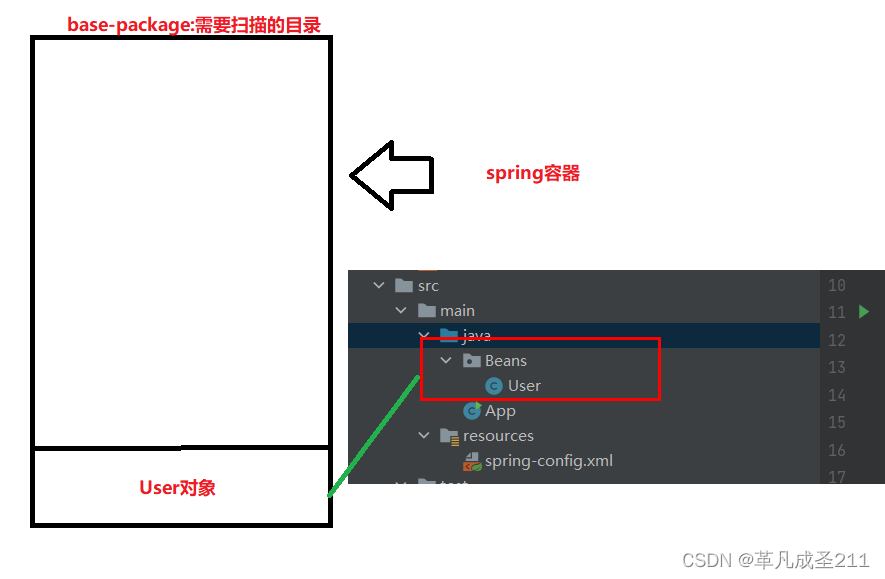
第二步:把bean存放到IoC容器当中
一般情况下面,把bean放入到IoC容器当中,需要使用到下面的5大类注解:
类注解作用于类上面之后,都会为这个类在spring容器当中注入一个对象。
类注解(作用于类上面)
@Controller:把一个类标记为"控制器"
控制器的含义就是:三层架构当中的Controller对应的类。
其中,@Controller注解当中传入的参数,就是这一个类对象的名称。
@Controller("User")
public class User {public void say(){System.out.println("user say...");}
}
如果想要获取这个bean,可以这样获取:
public static void main(String[] args) {ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//在容器当中指定对象的名称,指定User.class的内容User user=applicationContext.getBean("User",User.class);user.say();}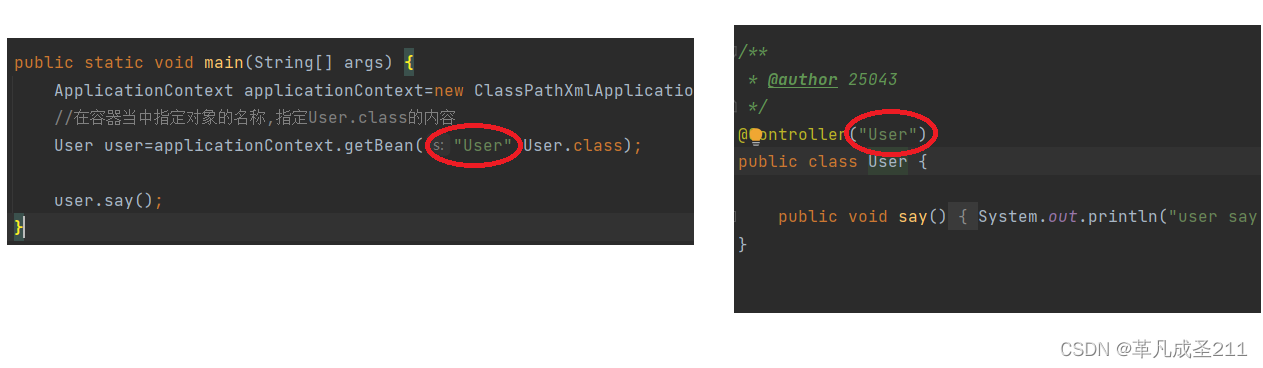 这两个内容要一致。
这两个内容要一致。
如果@Controller当中没有指定名称。那么,getBean的时候,传入的id就应当默认为User类名称的小驼峰:user。
但是,如果一个类的名称,没有按照驼峰命名法的规则来呢? 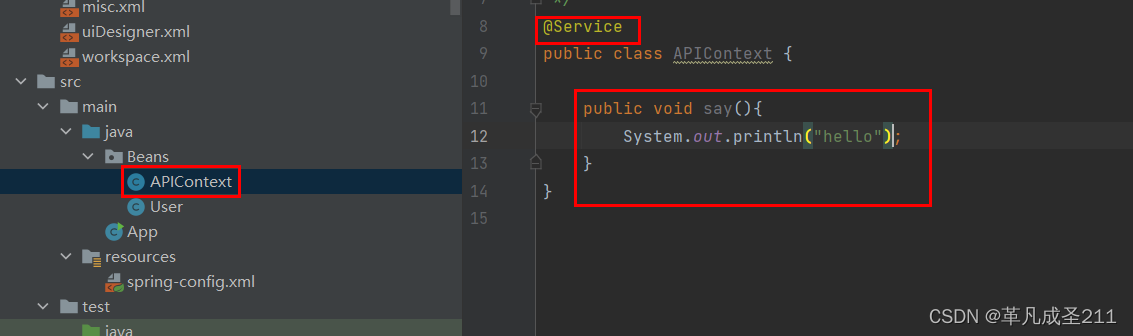
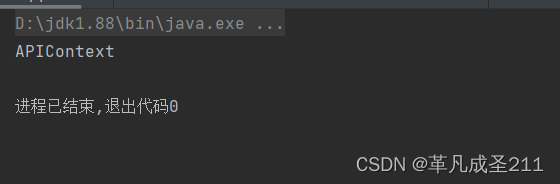
获取APIContext类的对象:
public static void main(String[] args) {ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//在容器当中指定对象的名称,此处假设一个类不按照小驼峰的方式开命名APIContext aPIContext=applicationContext.getBean("aPIContext", APIContext.class);aPIContext.say();}运行就会发现:

下面,来看一下spring给bean命名的潜规则:
spring给类命名的规则
来看一下源码:
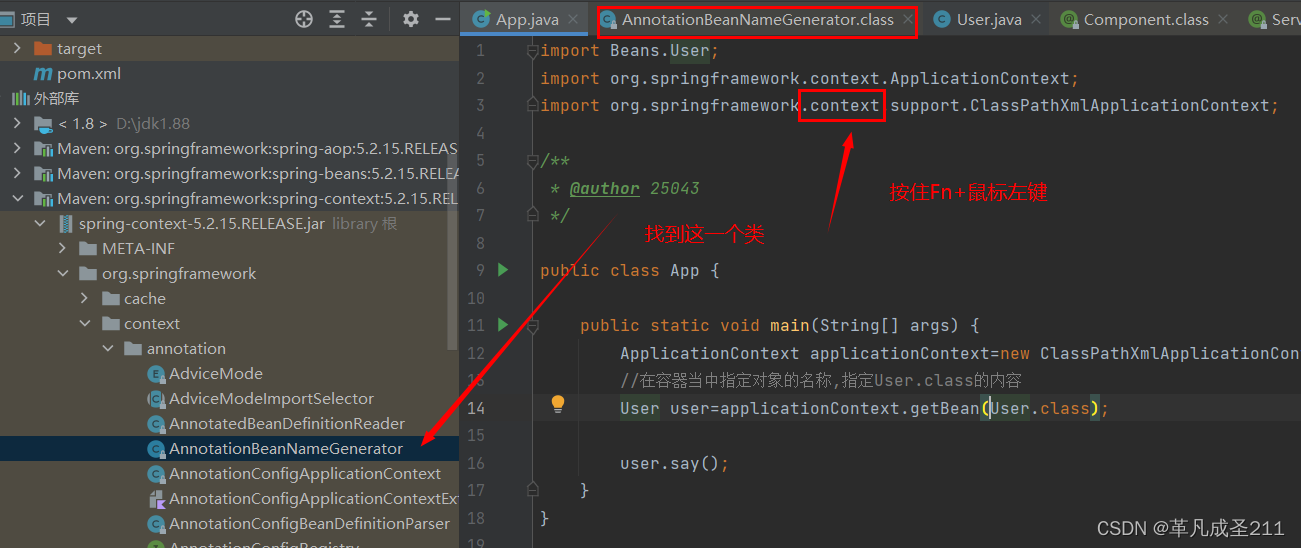
然后,在这个类的内部,往下拉动,找到这两个方法buildDefaultBeanName方法:
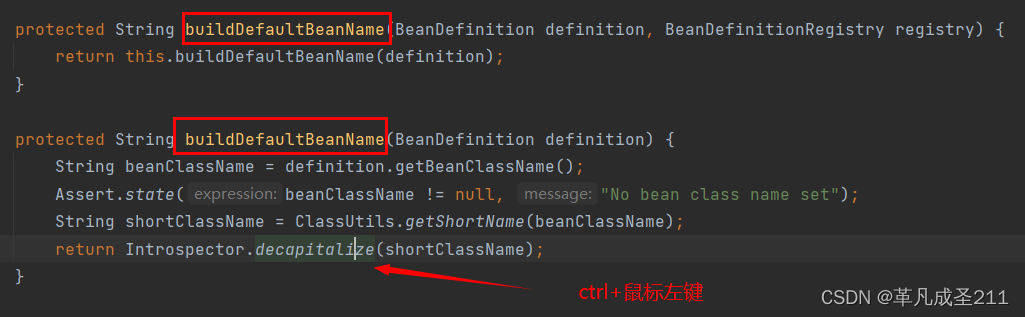
最后,跳转到这个方法:decapitalize。下面,重点来分析一下这个方法:
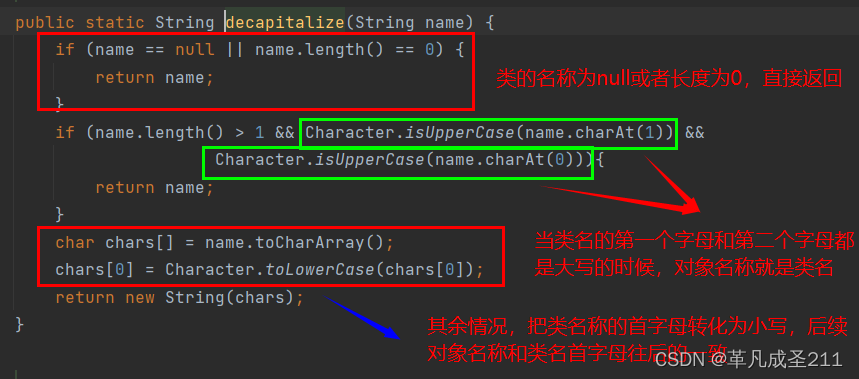
因此,总结一下spring在没有指定类的名称的时候,是怎样转化的:
当类名称的首字母和第二个字母都是大写的时候:那么对象名称(bean的名称)就是类名。
如果类名称的其余情况:对象名称=类名称的第一个字母转为小写+后面内容一致。
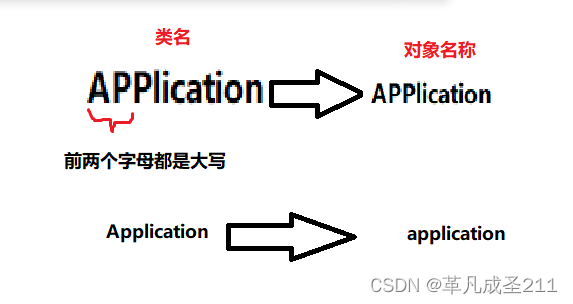
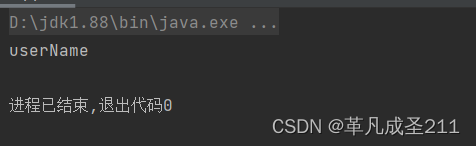
下面,来试验一下这个命名规则:(调用Introspector.decapitalize(String name)这个方法)
public static void main(String[] args) {String name="UserName";System.out.println(Introspector.decapitalize(name));}运行的结果是:
再实验一下API这样的形式:
public static void main(String[] args) {String name="APIContext";System.out.println(Introspector.decapitalize(name));}然后观察一下运行的结果:可以看到,此时bean的名称就是类名称了。
@Service
作用与Controller一样,用于标注"业务逻辑层"的对象。
@Repository
作用与Controller一样,用于标注"持久层"的对象
@Component
不属于前面的任意3层,那么这个注解就可以认为是一个"工具"。
@Configuration
作用与Controller一样,用于标注"配置类"。
为什么作用都一样,但是还是要这么多注解
这就涉及到"软件开发"的模型了。为了实现一个软件功能的解耦合,软件开发一般要至少分为4个层次:
层次1:前端的页面展示;
层次2:接口层,用于接收并且校验前端提交的参数,,调用逻辑层,并且作出响应(一般这个层的类需要使用@Controller来标注);
层次3:逻辑层,用于处理接口层传来的数据,并且处理业务逻辑。如果一些业务需要和数据库层打交道,那么逻辑层就会调用下一层。(使用@Service注解作用)
层次4:持久层,用于和数据库打交道的层面。(使用@Repository来作用)
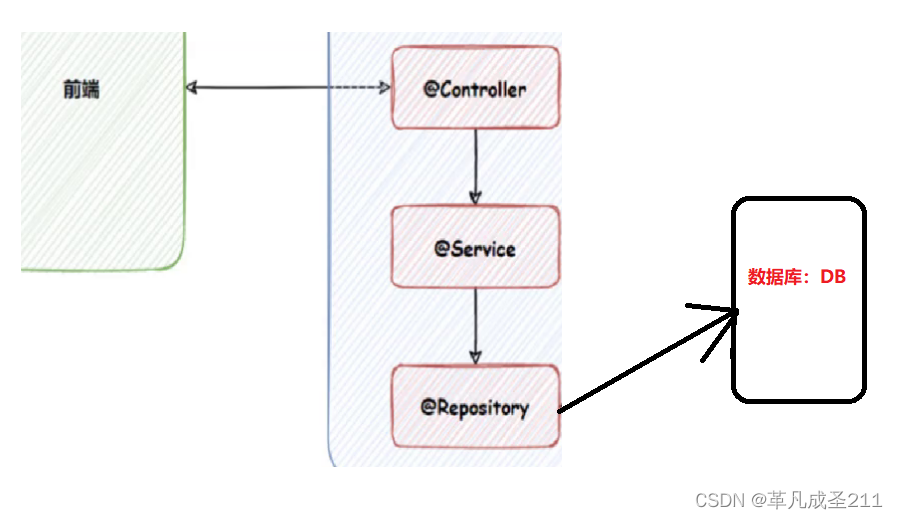
分开了5大类注解,令代码的可读性提高了,让程序员能够直观地判断当前类的业务用途。
5大类注解之间的关系
当我们点开各个注解的时候,可以看到:除了@Component注解以外的注解,都是基于@Component来实现的。也就是说,@Component是上述所有注解的父类。
方法注解(作用在方法上面的注解)
这个注解的作用,也是把bean给注入到spring容器当中,但是这个bean是作为方法的返回值。
第一步:新建一个User类
public class User {private int id;private String name;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +'}';}
}第二步:在另外一个类当中自定义一个返回User的方法
第二步由两个比较重要的部分构成:
第一部分:需要在这个方法上面加一个注解:@Bean。
第二部分:并且还需要在这个方法所在的类上面再加一个五大类注解当中的一个。
为什么spring规定不可以单独把@Bean注解作用于方法上,然后把这个方法的返回值放入到spring容器当中
提高效率!
在类上面增加了注解之后,可以有效降低spring组件扫描的范围。当且仅当一个类被5大注解作用的时候,才会扫描这个类当中@Bean方法返回值注入的对象。
/*** @author 25043*/
//这个注解不可以少
@Service
public class UserBeans {//把方法返回的值作为对象存储到Ioc容器当中@Beanpublic User user1(){//创建一个User对象User user=new User();//设置属性的值user.setId(1);user.setName("你好");//返回user对象return user;}
}此外,还可以在@Bean注解当中指定需要存放对象的名称(通过name属性指定注入的bean的名称):
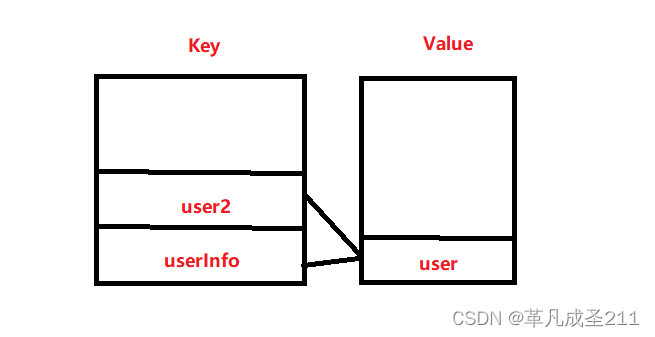
//在注解当中指定name属性,就是返回值在spring容器当中的bean@Bean(name = {"user2","userInfo"})public static User getUser2(){User user=new User();user.setId(2);user.setName("你好2");return user;}这个时候,通过两个不同的key,也可以找到同一个user了。因为此时在ioC容器当中,有两个相同的key指向了同一个user。
第三步:通过getBean方法获取User对象
getBean方法当中,传入的两个参数分别是:
@Bean注解作用的方法的名称
User类的class对象
public static void main(String[] args) {//获取spring上下文对象ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//传入两个参数,一个是方法名称:user1,另外一个是User的class对象User user=applicationContext.getBean("user1",User.class);System.out.println(user);}运行的结果:
第三步注意事项:
如果getBean()方法当中只传入一个参数:User.class的话,那么此时默认IoC容器当中只有一个User类型的bean。如果有两个User类型的bean的话,那么就会报错。
下面演示一下出错的情况:
①放入两个不同的bean,但是都是User类型
@Service
public class UserBeans {@Beanpublic User user1(){User user=new User();user.setId(1);user.setName("你好");return user;}//在注解当中指定name属性,就是返回值在spring容器当中的bean@Bean(name = {"user2","userInfo"})public static User getUser2(){User user=new User();user.setId(2);user.setName("你好2");return user;}
}②调用传入