本文代码参考其他教程书籍实现。
文章目录
- 文件读写
- open函数
- 读取文本文件
- 写入文本文件
- 文件和目录操作
- 使用os库
- 使用shutil库
文件读写
open函数
open函数有8个参数,常用前4个,除了file参数外,其他参数都有默认值。file指定了要打开的文件名称,应包含文件路径,不写路径则表示文件和当前py脚本在同一个文件夹。buffering用于指定打开文件所用的缓冲方式,默认值-1表示使用系统默认的缓冲机制。文件读写要与硬盘交互,设置缓冲区的目的是减少CPU操作磁盘的次数,延长硬盘使用寿命。encoding用于指定文件的编码方式,如GBK、UTF-8等,默认采用UTF-8,有时候打开一个文件全是乱码,这是因为编码参数和创建文件时采用的编码方式不一样。
mode指定了文件的打开模式。打开文件的基本模式包括r、w、a,对应读、写、追加写入。附加模式包括b、t、+,表示二进制模式、文本模式、读写模式,附加模式需要和基本模式组合才能使用,如 “rb”表示以二进制只读模式打开文件,“rb+”表示以二进制读写模式打开文件。
要注意的是,凡是带w的模式,操作时都要非常谨慎,它首先会清空原文件,但不会有提示。凡是带r的文件必须先存在,否则会因找不到文件而报错。
新建文本文件python_zen.txt,将python之禅文本(import this 返回的文本)复制粘贴。保存为UTF-8无BOM编码格式

常见的对象方法及其作用说明
| 方法 | 作用 |
|---|---|
| read | 将文件读入字符串中,也可以读取指定字节 |
| readline | 读入文件的一行到字符串中 |
| readlines | 将整个文件按行读入列表中 |
| write | 向文件中写入字符串 |
| writelines | 向文件中写入一个行数据列表 |
| close | 关闭文件 |
| flush | 把缓冲区的内容写入硬盘 |
| tell | 返回文件操作标记的当前位置,以文件的开头为原点 |
| next | 返回下一行,并将文件操作标记位移到下一行 |
| seek | 移动文件指针到指定位置 |
| truncate | 截断文件 |
读取文本文件
# 使用open函数打开文件
f=open('./python_zen.txt',mode='r',encoding='utf-8')
type(f)#查看类型
_io.TextIOWrapper
# 使用read方法将文件读入字符串中
texts=f.read()
print(texts)#输出文件全部内容

f.seek(0)#移动文件指针到文件开始处
0
# 使用readline方法读入文件的一行到字符串
texts=f.readline()
print(texts)

# 继续使用readline方法读取
texts=f.readline()
print(texts)#第二行该行为空行

# 继续使用readline方法读取
texts=f.readline()
print(texts)#第三行

# readline方法每次只读取一行,它常常与for循环配合使用
f.seek(0)
for line in f:print(line,end='')

# readlines方法读取效果
f.seek(0)
texts=f.readlines()
print(texts)

readlines的效果是一次性读取整个文件,并自动将文件内容按行分解成列表。
读取完毕后要用close方法关闭文件。
f.close()
在进行Python文件的读取或者写入的时候,都需要调取close方法来关闭文件,
前者是避免占用内存,后者是保证将内容顺利写入目标文件中。
有些时候我们会忘记调用close方法,或者运行中途代码出错,导致未运行close方法。
为了避免这种情况,可以使用try…finally…结构。
try:f=open(r'./python_zen.txt','r')...
finally:f.close()
这种结构简单地说:无论异常是否发生,在程序结束前,finally中的语句都会被执行。
# 此外,可以用上下文管理器with语句,确保不管使用过
# 程中是否发生异常都会执行必要的“清理”操作,以释放资源。
with open(r'./python_zen.txt','r') as f:texts=r.read()...
统计单词出现的频率
from collections import Counter
lists=[]
punctuation=',。!?、()【】<>《》=:+-*—“”...\n'#跳过其他字符
with open('./python_zen.txt',mode='r',encoding='utf-8') as f:for line in f:for word in line.split(' '):#如果统计字母则去掉[.split(' ')]即可if word not in punctuation:lists.append(word)
counter=Counter(lists)
print(counter)

写入文本文件
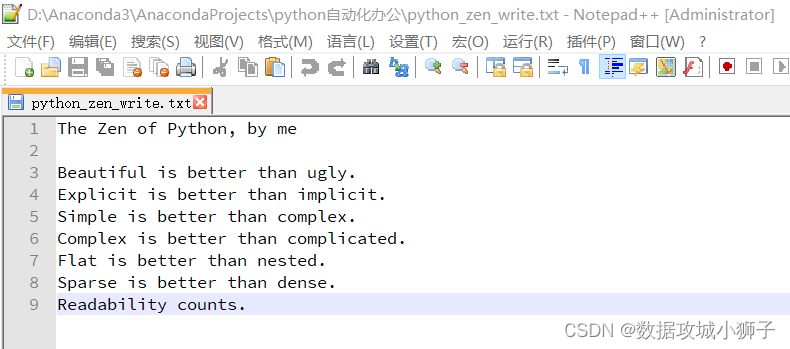
# 写入一个文本文件
f=open(r'./python_zen_write.txt',mode='w',encoding='utf-8')
#首尾文本紧跟引号可以防止输入多余的空行
f.write(
'''The Zen of Python, by meBeautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.'''
)
f.close()
# 有时,我们需要逐步写入内容,每次只写一句话,
# 这时不能用w模式,w会覆盖之前的文本内容,而应该使用追加模式a
f=open(r'./python_zen_write.txt',mode='a',encoding='utf-8')
f.write('这是python之禅的内容')
#我们尝试不运行f.close()会发生什么
打开python_zen_write.txt文件查看,想要追加写入的内容并没有写入。

当写文件时,操作系统往往不会立刻把数据写入硬盘,而是先放入内存中缓存起来,然后再陆续写入。只有调用close方法时,操作系统才保证把没有写入的数据全部写入硬盘。忘记调用close方法的后果是,虽然建立了文件,但是数据并没有写入文件。
# 可以使用flush方法,强制将缓存的数据写入文件
f.flush()
可以看到追加内容已经写入

但是似乎不是换行后追加写入,加个\n换行就行。
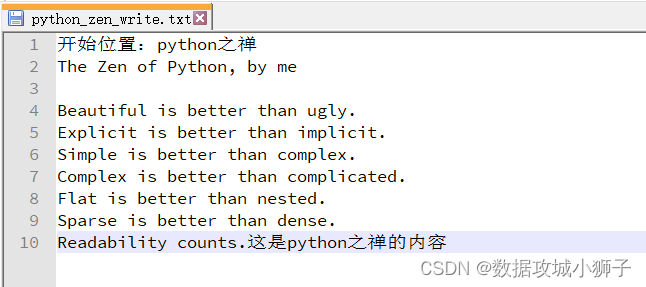
# 要在文件开始位置插入一句话
# file.seek(off, whence)
# whence(0代表文件开始位置,1代表当前位置,2代表文件末尾)偏移off字节
#文章开头介绍过,r+,读写模式,忘了的回到文章开头看
with open('./python_zen_write.txt',mode='r+',encoding='utf-8') as f:content=f.read()f.seek(0,0)f.write('开始位置:python之禅\n'+content)
试试末尾追加写入
with open('./python_zen_write.txt',mode='r+',encoding='utf-8') as f:f.seek(0,2)f.write('\n末尾位置:结束语')

文件和目录操作
使用os库
import os
常用的操作函数
| 函数 | 说明 |
|---|---|
| getcwd | 获取当前工作目录,即当前python脚本所在的目录路径 |
| listdir | 列出指定目录下的所有文件和子目录,包括隐藏文件 |
| mkdir | 创建目录 |
| unlink | 删除文件 |
| remove | 删除文件 |
| rmdir | 删除空目录 |
| removedirs | 若目录为空,则删除,并递归到上一级目录,若上一级目录为空,也删除 |
| rename | 重命名文件 |
| stat | 获取一个文件的属性及状态信息 |
os.path可以调用ntpath.py模块
os.path

常用的操作函数
| 函数 | 说明 |
|---|---|
| abspath | 返回规范化的绝对路径 |
| basename | 返回最后的文件名部分 |
| dirname | 返回目录部分 |
| split | 将文件名分割成目录和文件名 |
| splitext | 分离扩展名 |
| join | 将多个路径组合起来,以字符串中含有/的第一个路径开始拼接 |
| getctime | 返回文件或目录的创建(复制到某个目录)的时间 |
| getatime | 访问时间,读一次文件的内容,这个时间就会更新 |
| getmtime | 修改时间,修改一次文件的内容,这个时间就会更新 |
| getsize | 获取文件大小 |
| isabs | 如果path是绝对路径,返回True |
| exists | 如果path存在,则返回True;如果path不存在,则返回False |
| isdir | 如果path是一个存在的目录,则返回True,否则返回False |
| isfile | 如果path是一个存在的文件,则返回True,否则返回False |
os.getcwd()#当前工作目录

# 修改工作目录
os.chdir('D:\\Anaconda3\\AnacondaProjects')
print(os.getcwd())
os.chdir('D:\\Anaconda3\\AnacondaProjects\\python自动化办公')
print(os.getcwd())

os.listdir()#获取当前工作目录的全部文件和子目录

# 遍历文件目录
# os.listdir()方法不能获取子目录里面的文件,
# 要进一步获取则需要用到os.walk方法。
path=r'D:\Anaconda3\AnacondaProjects\python自动化办公'
for foldName,subfolders,filenames in os.walk(path):for filename in filenames:print(foldName,filename)#foldName文件目录,filename文件名

# 拆分绝对路径文件名
path=r'D:\Anaconda3\AnacondaProjects\python自动化办公\python_zen.txt'
print(os.path.split(path))
print(os.path.dirname(path))
print(os.path.basename(path))
print(os.path.splitext(path))

#组合文件名
print(os.path.join(os.getcwd(),os.path.basename(path)))

# 获取文件属性
path=r'D:\Anaconda3\AnacondaProjects\python自动化办公\python_zen.txt'
print(os.path.getctime(path))#创建时间
print(os.path.getmtime(path))#修改时间
print(os.path.getatime(path))#访问时间

上述格式的时间表示从1970年1月1日到现在已经经过多少秒,要把它转换成可以理解的时间要使用time模块。
import time
print(time.ctime(os.path.getctime(path)))#创建时间
print(time.ctime(os.path.getmtime(path)))#修改时间
print(time.ctime(os.path.getatime(path)))#访问时间

这里的创建时间,并不是指这个文件内容的原创时间,如果文件从别处复制过来,那就是复制的时间。
print(os.path.getsize(path))#查看文件大小

# stat方法获取文件的属性及状态信息
print(os.stat(path))

# 输出文件大于0且后缀为.txt的文件名
for file in os.listdir():path=os.path.abspath(file)filesize=os.path.getsize(path)if filesize>0 and os.path.splitext(path)[-1]=='.txt':print(os.path.basename(path))

同理,也可以删除符合某些条件的文件os.remove(file)
# 新建一个文本文件
with open('new.txt','w',encoding='utf-8') as f:f.write('一个新的txt文件')
for foldName,subfolders,filenames in os.walk(os.getcwd()):print('foldName:',foldName,'\n','subfolders:',subfolders,'\n','filenames:',filenames)

# 将当前目录及子目录所有new.txt文件改名为new2023.txt
for foldName,subfolders,filenames in os.walk(os.getcwd()):for filename in filenames:#不加这个筛选条件,则是更改所有文件文件名。也可加其他筛选条件if filename=='new.txt':abspath=os.path.join(foldName,filename)extension=os.path.splitext(abspath)[1]new_name=filename.replace(extension,'2023'+extension)os.rename(abspath,os.path.join(foldName,new_name))
使用shutil库
下篇文章python自动化办公(二)再继续写吧。