前言
上一篇文章 python学习——【第三弹】 中学习了python中的流程控制语句,这篇文章我们接着学习python中的序列。先给大家介绍不可变序列 字符串和可变序列 列表,下一篇文章接着补充元组,集合和字典。
序列
指的是一块可以存放多个值的连续内存空间,这些值按一定的顺序排列,可以通过每个值所在的位置的编号,也就是索引来访问他们。
python中的序列类型包括:字符串(string)、列表(list)、元组(tuple)、集合(set),还支持一种映射数据类型:字典(dictionary)。序列的基础操作一般有:增加,删除,修改,查询。
python中的序列又分为可变序列和不可变序列:
可变序列
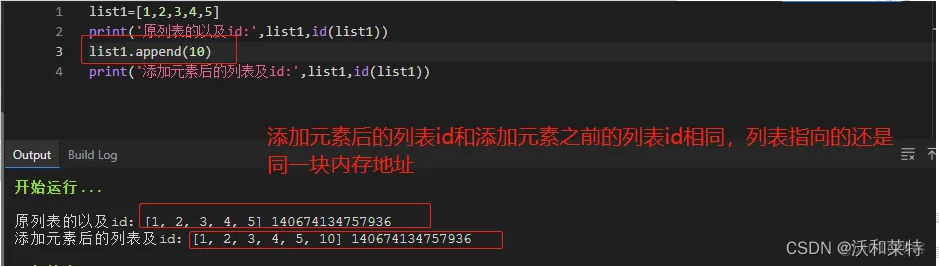
列表,集合以及字典,可变序列的数据结构是可以进行查看的,并且可以对其进行一些修改;操作后id(内存地址)不改变,不会开辟新的内存地址;
以列表为例:
不可变序列
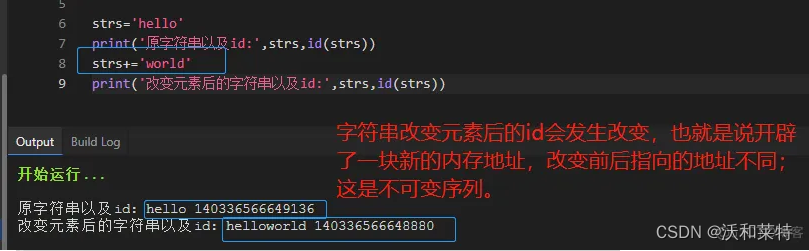
字符串,元组,数值,只允许查看它们的值,当对不可变序列进行修改操作时,它会开辟一块新的内存地址,从而id发生变化。
以字符串为例:
序列操作
1:索引
索引即为序列的下标,通过下标来查询或取出序列中的元素。
strs='人生如戏,全是演技'
zifu1=strs[3]
zifu2=strs[-3]
zifu3=strs[10]
print('第四个字是:',zifu1)# 戏 索引为大于等于0的数,从字符串的左边向右边开始查询,从索引为0开始
print('倒数第三个字是:',zifu2)#是 索引为小于0的数,从字符串的右边向左边开始查询,从索引为-1开始
print('超出字符串的索引范围:',zifu3) #IndexError: string index out of range
2:切片
python中的序列都可以使用切片操作:
切片操作:切片的结果–》原列表片段的拷贝
切片的范围:–》取得到start起始值,取不到stop终止值,可以记作 顾头不顾尾
step步长默认是1——》简写为[start:stop]
step是正数——》[:stop:step] -->切片的第一个元素默认是列表的第一个元素,从第一个元素开始往后计算切片
step是正数——》[start::step] -->切片的最后一个元素默认是列表的最后一个元素,从start开始往后计算切片
step是负数-》[:stop:step] -->切片的第一个元素默认是列表的最后一个元素, 从最后一个元素开始往前计算切片
step是负数——》[start::step] -->切片的最后一个元素默认是列表的第一个元素从start开始往前计算切片
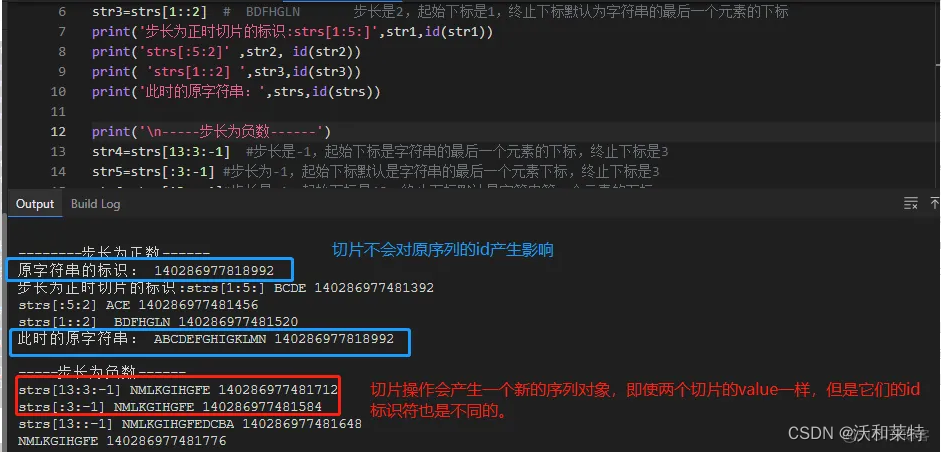
strs='ABCDEFGHIGKLMN'
print('--------步长为正数------')
print('原字符串的标识:',id(strs))
str1=strs[1:5:] # BCDE 以及strs[1:5] 步长默认是1,起始下标是1,终止下标是5
str2=strs[:5:2] # ACE 步长是2,起始下标默认为1,终止下标为5
str3=strs[1::2] # BDFHGLN 步长是2,起始下标是1,终止下标默认为字符串的最后一个元素的下标
print('步长为正时切片的标识:strs[1:5:]',str1,id(str1))
print('strs[:5:2]' ,str2, id(str2))
print( 'strs[1::2] ',str3,id(str3))print('\n-----步长为负数------')
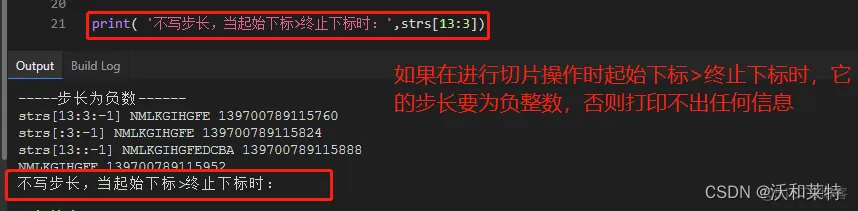
str4=strs[13:3:-1] #步长是-1,起始下标是字符串的最后一个元素的下标,终止下标是3
str5=strs[:3:-1] #步长为-1,起始下标默认是字符串的最后一个元素下标,终止下标是3
str6=strs[13::-1]#步长是-1,起始下标是13,终止下标默认是字符串第一个元素的下标
print('strs[13:3:-1]',str4,id(str4))
print('strs[:3:-1]',str5,id(str5))
print('strs[13::-1]',str6,id(str6))
字符串
python当中的字符串的相关方法可以查看 python学习——【第一弹】 ,这里对字符串的相关操作介绍一下。
1:改变字母大小写
strs='hello World'
# 首字母大写
str1=strs.capitalize()
print('首字母大写',str1)
# 全部大写
str2=strs.upper()
print( '全部大写',str2)
# 全部小写
str3=strs.lower()
print('全部小写:',str3)
# 大小写互换
str4=strs.swapcase()
print('大小写互换', str4)#zifu='abc_def-gkL'
str5=zifu.title()
print('转换后的字符:',str5) #转换后的字符: Abc_Def-Gkl用特殊字符或者数字隔开的单词首字母大写

字母的大小写也可运用于验证码的检验当中
# 将其都转换成大写或小写字母后进行核对检验
yan='abc_De1s5'
yinput=input('请输入验证码:')
while yinput.upper()!=yan.upper():print('验证码错误!')yinput=input('请重新输入验证码:')
print('验证码输入成功!')

2:find(), index()函数查找元素索引
python中提供了find() 和index()方法通过元素查找索引值;
其中利用 find()查找 若找到相应元素就返回该元素的索引值,如果找不到就返回-1;
利用 index()查找 如果找到相应元素就返回该元素索引值,找不到就抛出 ValueError 错误。
zifu='hello world'
print(zifu.find('h')) #0
print(zifu.find('a')) #-1
print(zifu.index('e')) #1
print(zifu.index('a')) #ValueError
3:center()函数居中字符串
strs = 'alexWUsir'
str1 = strs.center(20, '%') # 用%填充后共有20个字符
str2 = strs.center(15, '|') # 用|填充后共有15个字符
str3 = strs.center(20) # 空白填充
print(str1)
print(str2)
print(str3)

4:is判断
strs='123 abc@'
print(strs.isdigit())#判断该字符串是否全由数字组成 False
print(strs.isalpha())#判断该字符串是否全由字母组成 False
print(strs.isalnum())#判断该字符串是否只由字母或数字组成 False
print(strs.isspace())# False 判断该字符串是否全部由空格组成,如果字符串有空格外其他数字组成或者是空,返回False
5:replace()函数替换字符串中的元素
Python中的 replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
语法:str.replace(old, new,[max])
str1 = '来者何人,东方不败!东方不败'
str2 = str1.replace('东方不败','天山果佬')
str3 = str1.replace('东方不败','天山果佬',1)
print(str1)
print(str2)
print(str3)

6:format()函数格式化字符串
是一种字符串格式化的方法,主要是用来构造字符串。
基本语法: 通过 {} 和 : 来代替以前的 % 。在 {} 符号操作过程中,每一个 {} 都可以设置顺序,分别与format的参数顺序对应;如果没有设置{}下标,默认重0开始递增。
strs="我叫{0},今年{2}岁,来自{3},喜欢的语言是{1}。".format('小明','python','19','山东')
str1="我叫{},今年{}岁,来自{},喜欢的语言是{}。".format('小亮','19','山东','PHP')
print(strs)
print(str1)

7:split()函数分割字符串
str1='hello world 你好 世界'
str2='hello:world:你好:世界'
s1=str1.split()
print('默认用空格分割:',s1)
s2=str2.split(':')
print('使用分号分割:',s2)

8:count()函数计算字符串中元素出现的个数
str1='hello world'
str2=str1.count('l')
print('\"l\"的个数是:',str2) #"l"的个数是: 3
str3=str1.count('a')
print('\"a\"的个数是:',str3) #"a"的个数是: 0
9:strip()函数删除字符串前后的空格或字符
str1='--! hello! world! '
str2=str1.strip()#删除字符串前后的空格;默认删除的是字符串两边的空格
print(str2) #--! hello! world!
str3=str1.strip('--')#删除字符串前后的!
print(str3) #! hello! world!

列表
列表(List)是 Python 中最基本的数据结构,它是一种有序的集合,列表中每个元素都有其对应的位置值(索引),类似于其他语言中的数组;是一种可变序列,对其进行增删改等操作不会影响它的id标识符。
列表的特点:
1,按照列表中的顺序有序排序;
2,索引映射唯一一个数据;
3,列表可以存储重复数据;
4,任意数据类型可混存;
5,根据需要动态分配和回收
1:创建列表
python中创建列表由两种方法:
一是使用方括号的方式创建列表
二是使用内置函数list()函数创建列表。
# 1 使用方括号:我们只需要把列表的所有元素放在 方括号 [] 里面,每个元素之间通过 逗号 , 间隔起来即可,当然,列表中允许存放不同数据类型的元素。
list1=['a',{},'b',1,'c']# 2 使用内置函数 list()
list2=['a',{},'b',1,'c']
print(list1,type(list1))
print(list2,type(list2))
#['a', {}, 'b', 1, 'c'] <class 'list'>
# ['a', {}, 'b', 1, 'c'] <class 'list'>
空列表的创建
lis=[]
lis2=list()
2:查询列表中元素的索引值
python中提供了index()函数来查找列表中元素的索引,要注意的是在列表对象中没有find()方法,如果使用回抛出AttributeError错误;而str对象同时具有find()和index()方法!
index()函数
# 当列表中有相同元素时,使用index()函数取返回指定元素的索引时默认返回相同元素中第一个元素的索引;如果要查找的元素在列表中不存在,会报ValueError 的错误
list3=list(['a','b','a','c'])
print(list3,'第一个a的位置是',list3.index('a')) #['a', 'b', 'a', 'c'] 第一个a的位置是 0
# index在指定范围查找元素
print(list3,list3.index('b',1,3))# ['a', 'b', 'a', 'c'] 1 查找下标从1到3之间的元素(包括下标1不包括下标3的元素)
当然,如果想获取列表中所有元素的索引值,我们可以使用列表推导式和enumerate()函数来获取
languages = ["JavaScript","Python","Java","Python","C++","Python"]
python = [index for (index, item) in enumerate(languages)]
print(python) #[0, 1, 2, 3, 4, 5]#输出元素为“python”的索引
'''
使用enumerate()函数,可以存储满足条件的元素的索引,首先将列表中的每一个键值对(index,item)作为参数传递到函数中;
index 表示列表项的索引号, item 表示列表项本身;接着会像一个计数器一样从0开始计数,满足判断条件后自动递增,
选择并移动符合条件的元素索引,并将满足条件的索引存储在 "python" 形成一个新的列表
'''
languages = ["PHP","Python","Java","Python","C++","Python"]
python = [index for (index, item) in enumerate(languages) if item == "Python"]
print(python)
##[1, 3, 5]
3:列表的遍历
使用for — in的方法遍历列表
list2=[10,20,30,'python']
for i in list2: #i代表迭代元素 不需要另外声明 直接利用for循环打印出来列表元素print(i,id(list2))
'''
10 140620010123824
20 140620010123824
30 140620010123824
python 140620010123824
'''
4:列表生成式
生成列表的公式——》语法格式 [i * i for i in range(1,n)]
其中:
i*i中的i 表示列表元素的表达式
for 后面的i 表示自定义变量
range()函数中的1,n表示可迭代的对象
注意事项:表示列表元素的表达式中包含自定义变量
list1=[ i for i in range(1,10)] #注意是左闭右开区间 产生的整数序列 [1, 2, 3, 4, 5, 6, 7, 8, 9]
print('产生的整数序列',list1,id(list1)) #产生的整数序列 [1, 2, 3, 4, 5, 6, 7, 8, 9] 140173346492976
list2=[i*i for i in range(1,10)] #[1, 4, 9, 16, 25, 36, 49, 64, 81]
print(list2) #[1, 4, 9, 16, 25, 36, 49, 64, 81]
5:切片获取列表元素
切片前面已经为大家介绍过了,这里举个例子:
list4=[10,20,30,40,50]
print('原列表:',id(list4)) #原列表: 140709945504304
after=list4[1:3:1]
print('切的片段:',after,id(after)) #切的片段: [20, 30] 139765064281136
print('此时的原列表:',id(list4))#此时的原列表: 139765064278576
6:向列表中添加元素
我们可以直接使用下标索引更新列表
books = ["语文", "数学", "英语", "历史", "物理", "化学"]
books[1] = "地理"
print(books)
#['语文', '地理', '英语', '历史', '物理', '化学']
由于列表是可变序列,因此在python中可以使用append() 或 insert()方法来向列表中添加元素:
使用append()函数在列表的末尾添加元素
books=['Chinese','English','Mathematics']
bookes.append("Science")
print(books)
#['Chinese','English','Mathematics','Science']
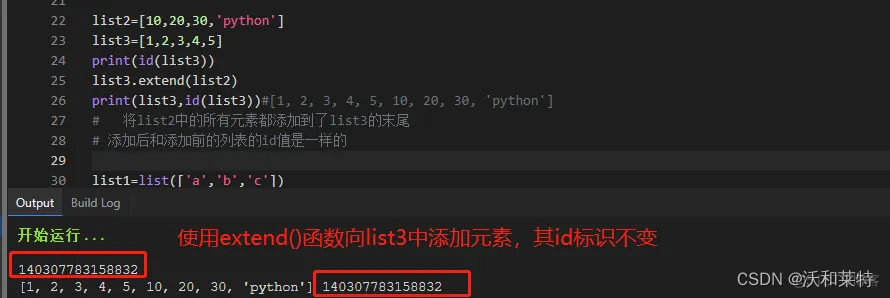
extend()在列表的末尾至少添加一个元素
list2=[10,20,30,'python']
list3=[1,2,3,4,5]
print(id(list3))
list3.extend(list2)
print(list3,id(list3))#[1, 2, 3, 4, 5, 10, 20, 30, 'python']
# 将list2中的所有元素都添加到了list3的末尾,添加后和添加前的原列表的id值是一样的
使用insert()函数在列表的指定位置插入新对象
books=['Chinese','English','Mathematics']
books.insert(1,"Science")
print(books)
#['Chinese', 'Science', 'English', 'Mathematics']
7:对列表排序
常见的两种方式
1:调用sort()方法列表中的所有元素默认按照从小到大的顺序进行排序,可以在函数括号中指定
reverse=True 进行降序排序
2:调用内置函数sorted()可以在函数的括号中指定 reverse=True 进行降序排序 ; 原列表不发生改变 但产生一个新的列表对象。
reverse 颠倒 撤销 使完全相反 相反的
sort 分类 排序 种类 整理(v&n)
sorted v. 整理; 把…分类; 妥善处理; 安排妥当; adj.完成的;已解决的;整理好的;
# 使用sort()方法 没有指定reverse=True,默认为升序排序;排序前后的列表id值不发生改变
list1=[11,22,33,44,55,0,11]
print('排序前的列表',list1)
list1.sort()
print('排序之后的列表',list1)
#排序前的列表 [11, 22, 33, 44, 55, 0, 11]
#排序之后的列表 [0, 11, 11, 22, 33, 44, 55]
list2=[22,33,11,33,22,44,55,99]
list2.sort(reverse=True)#当不指定时,默认是升序
print('降序后的:',list2)
#降序后的: [99, 55, 44, 33, 33, 22, 22, 11]
# 使用内置函数sorted将列表进行排序产生一个新的列表对象
list3=[11,22,55,44,33]
print(list3,id(list3)) #[11, 22, 55, 44, 33] 140335719927232
new_list3=sorted(list3)
print(new_list3,id(new_list3)) #[11, 22, 33, 44, 55] 140335719386160
new_lis3=sorted(list3,reverse=True)
print(new_lis3)#[55, 44, 33, 22, 11]
8:删除列表中的元素
在对列表进行删除操作时,我们可以根据索引删除对应位置的元素,也可以根据元素本身的值进行删除;当然,还可以直接利用 clear()函数 清空整个列表;并且删除操作也不会改变原列表的标识。
del()函数
books = ["语文", "数学", "英语", "历史", "数学", "物理", "数学"]
del books[1] # 删除第 2 个元素
print(books)#['语文', '英语', '历史', '数学', '物理', '数学']
del books[1:4] # 删除第 2 个到第 4 个的所有元素
print(books)#['语文', '物理', '数学']
如果想要删除的列表索引不存在就会抛出 IndexError: list assignment index out of range 的错误
pop()函数
pop()函数默认删除最后一个元素,并返回删除的元素
books = ["语文", "数学", "英语", "历史", "数学", "物理", "数学"]
books.pop() # 默认删除列表最后一个元素 '数学'
print(books) # ['语文', '数学', '英语', '历史', '数学', '物理']books.pop(3) # 删除列表指定索引下的元素 '历史'
print(books)#['语文', '数学', '英语', '数学', '物理']
如果要删除的列表索引不存在,就会抛出 IndexError: pop index out of range 的错误remove
remove()函数
remove()函数删除指定的元素,出现重复元素只删除第一个出现的元素
books = ["语文", "数学", "英语", "历史", "数学", "物理", "数学"]
books.remove("数学")
print(books)#['语文', '英语', '历史', '数学', '物理', '数学']
**如果删除的索引不存在,会抛出 ValueError: list.remove(x): x not in list 的错误
clear()函数
清空列表
books = ["语文", "数学", "英语", "历史", "数学", "物理", "数学"]
books.clear()
print(books)#[]
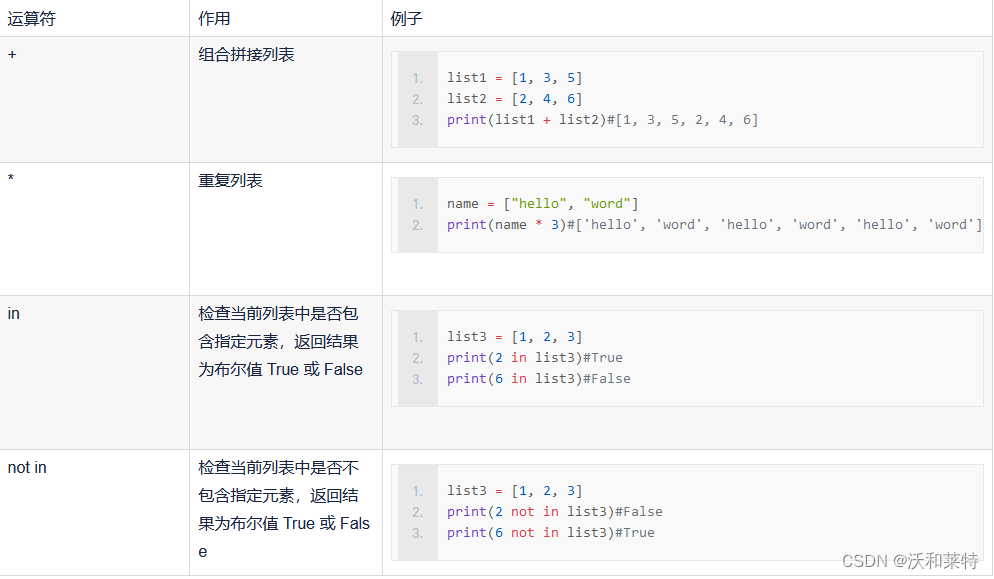
9:列表的运算操作符
利用操作符对列表去重:
list1 = [1,2,3,4,5,6,7,10,1,2,2,3,4,8,9,0]
new = []
for each in list1:if each not in new:new.append(each)
print('去重后的列表:',new)# 去重后的列表: [1, 2, 3, 4, 5, 6, 7, 10, 8, 9, 0]
#遍历list1的每个元素,若不存在于new,调用append添加
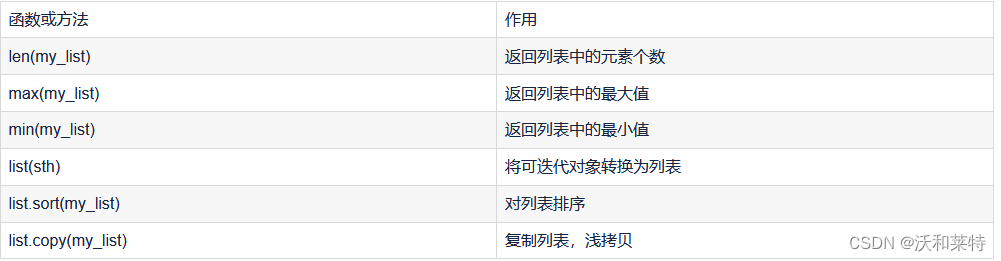
列表函数、方法补充
每篇一语
每个方向都有人奋力追光!
如有不足,感谢指正!