文章目录
- TiDB Server架构
- TiDB Server作用
- TiDB Server的进程
- SQL语句的解析和编译
- SQL读写相关模块
- 在线DDL相关模块
- GC机制与相关模块
- TiDB Server的缓存
- 热点小表缓存
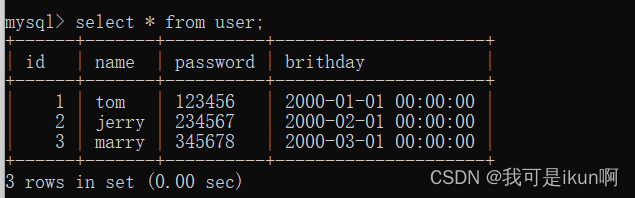
TiDB Server架构
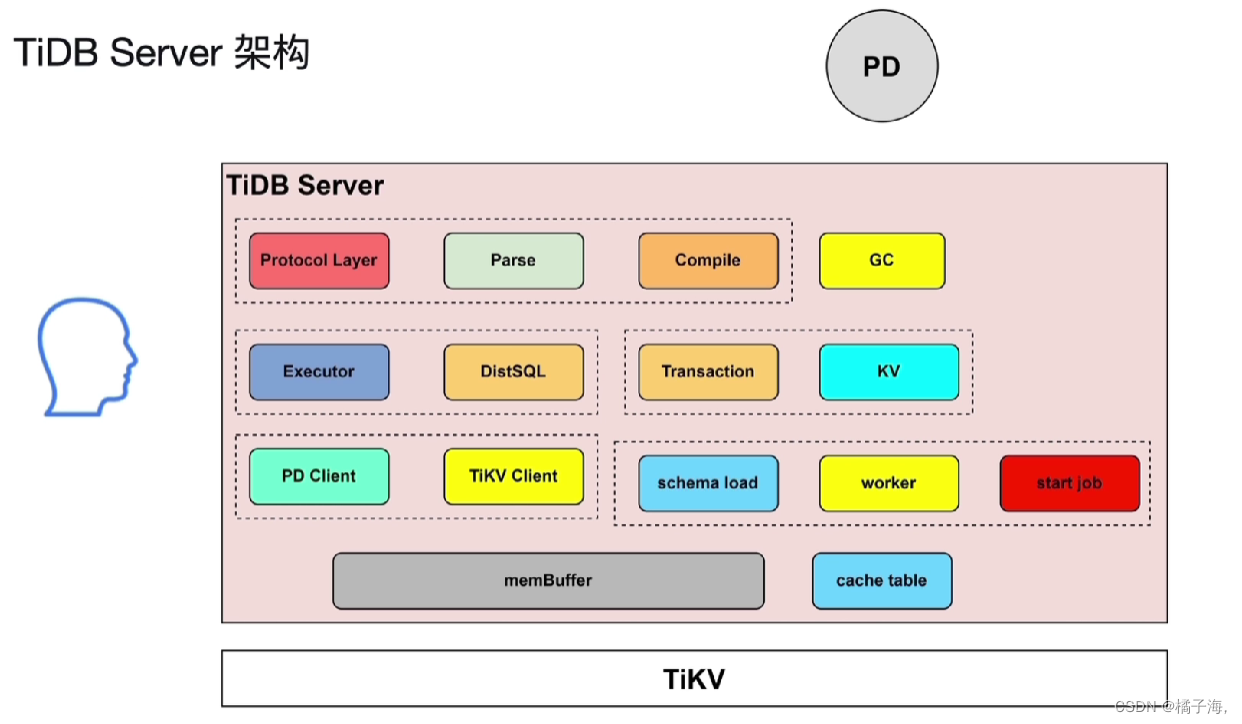
Protocol Layer、Parse、Compile负责sql语句的解析编译和优化,然后生成sql语句执行计划交给Executor
Executor、DistSQL和KV负责分批的执行sql的执行计划
Transaction和KV负责和事务相关的
PD Client和TiKV Client负责与PD TiKV之间的交互
schema load、worker、start job实现DDL语句不会阻塞读写
TiDB Server作用
- 处理客户端的连接(由Protocol Layer完成)
- SQL语句的解析和编译(由Parse、Compile完成)
- 关系型数据与KV的转化
- SQL语句的执行
- Online DDL的执行
- 垃圾回收
- 热点小表缓存 V6.0(由cache table实现)
TiDB Server的进程
SQL语句的解析和编译
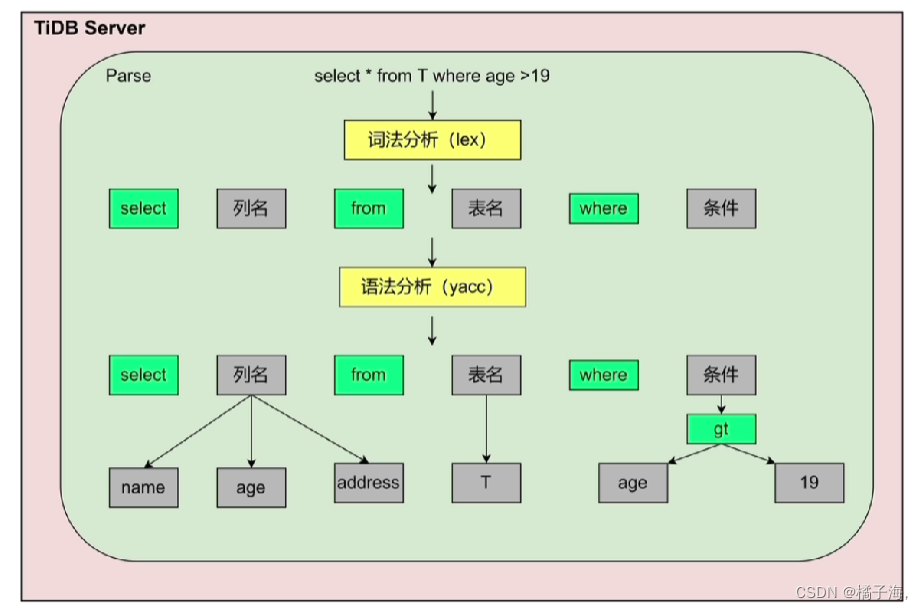
生成树形结构,称为AST抽象语法树
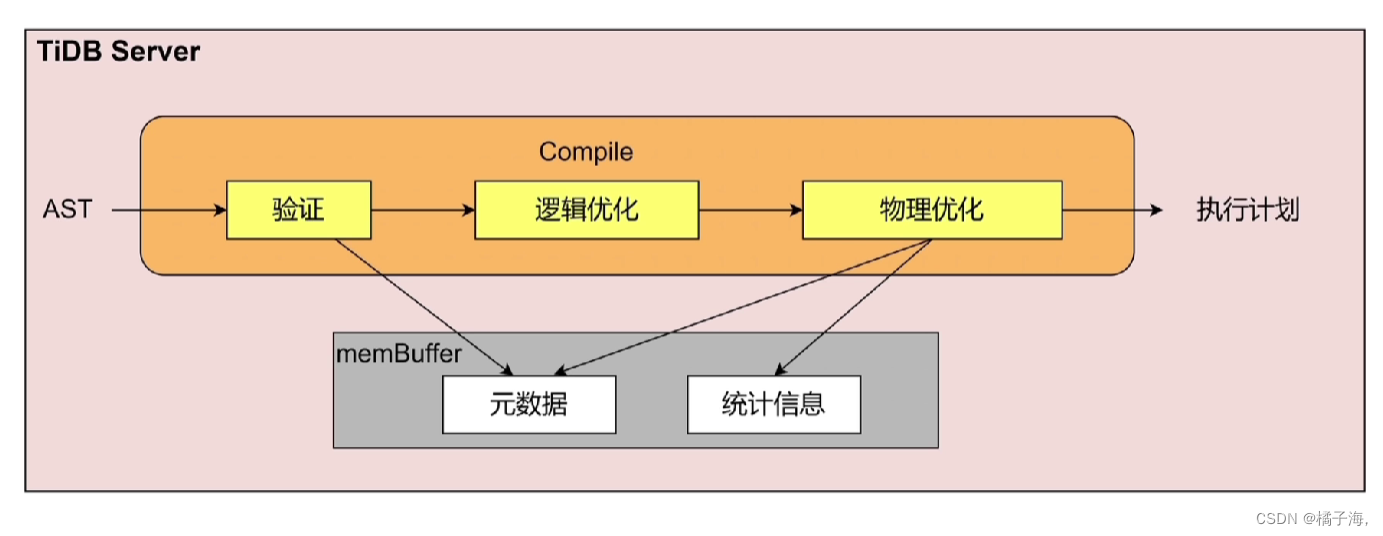
表结构转化为KV的过程
聚簇表:
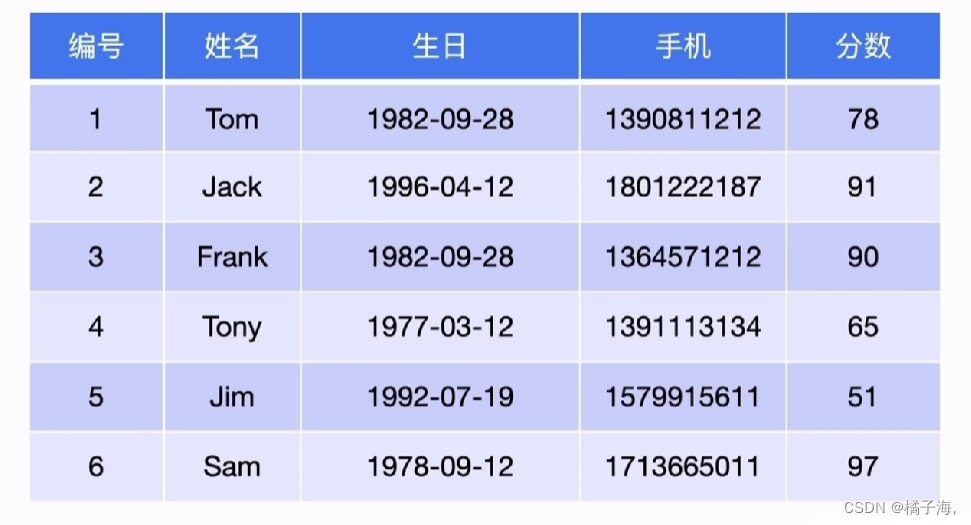
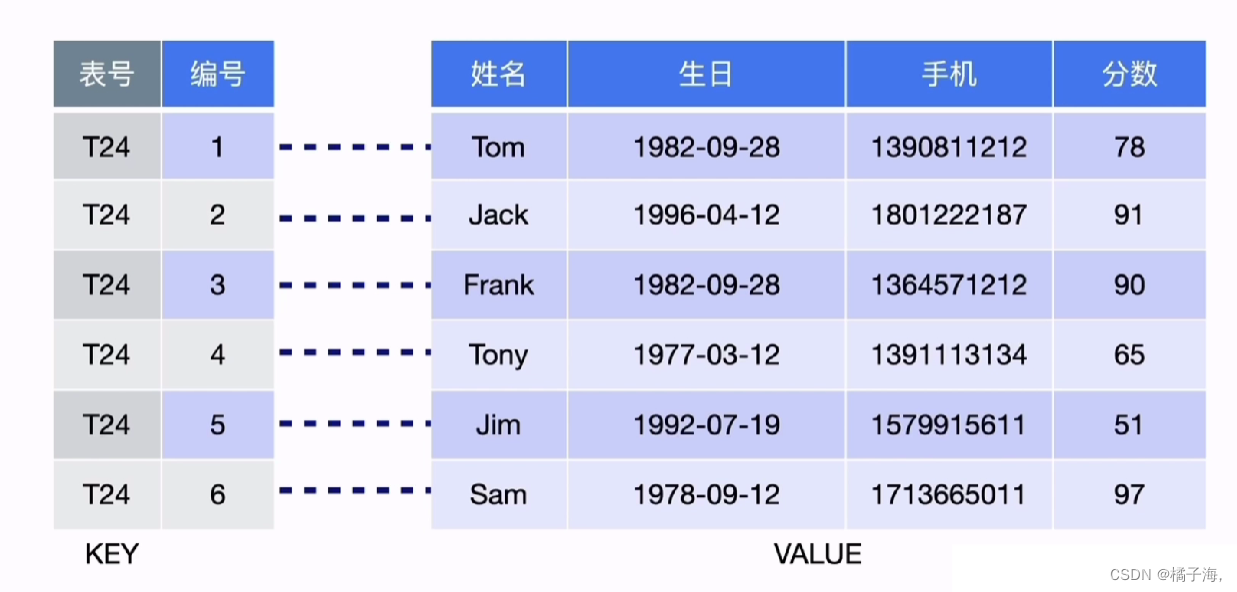

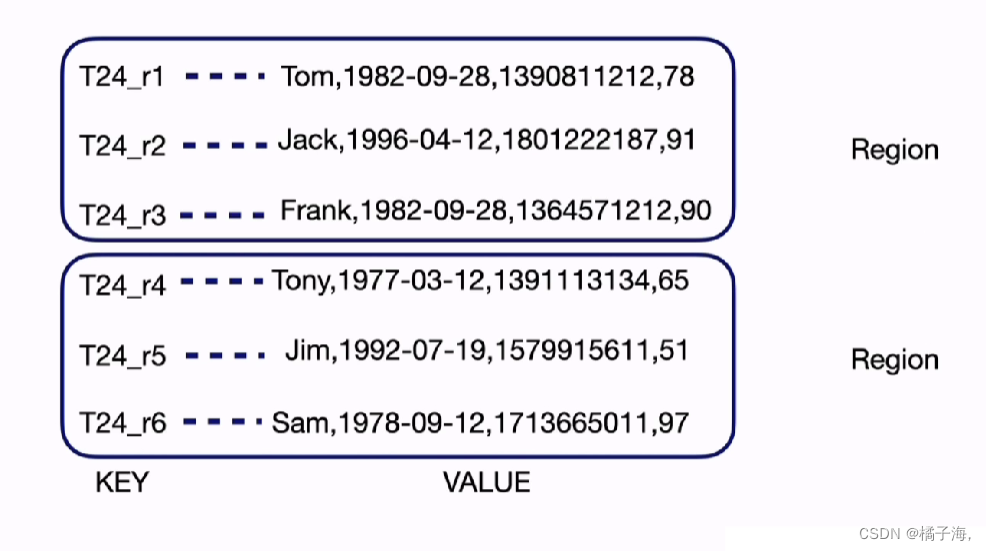

SQL读写相关模块
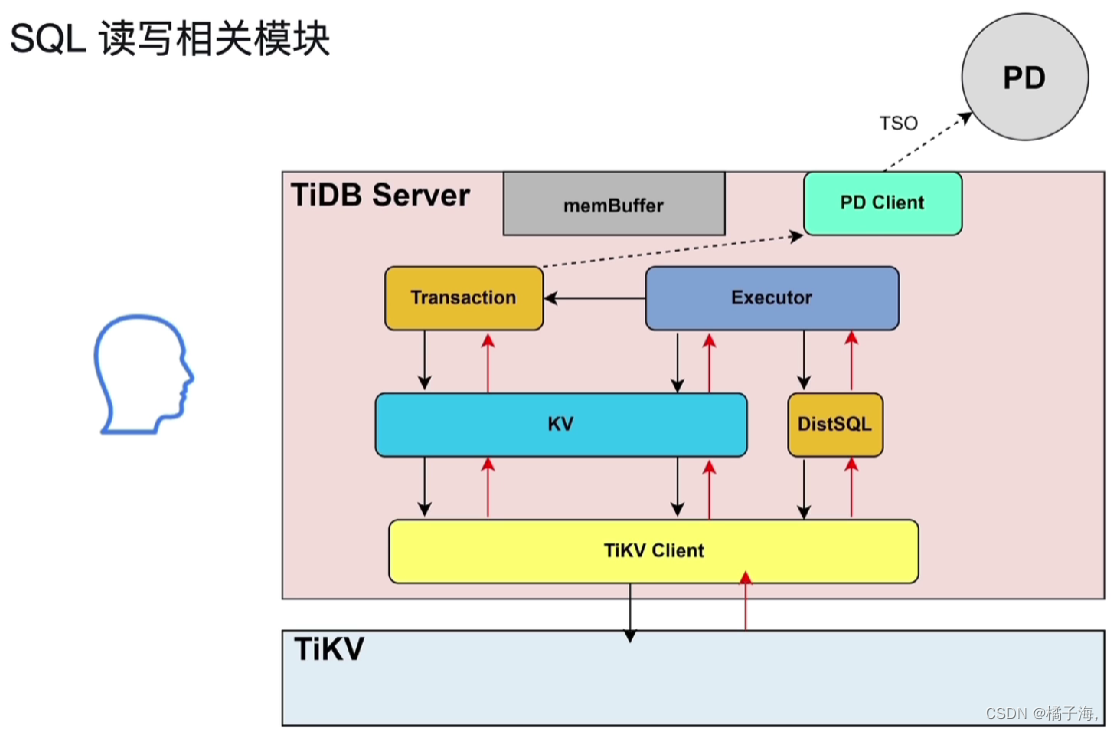
执行计划执行的时候分为两种:
- 比较复杂的SQL:比如范围查询、表连接、相关的嵌套查询等等,为了避免这些复杂的sql和下面的TiKV存取相关进行耦合度太高,抽象出一个接口DistSQL模块,它负责把对于TiKV的请求封装起来,提供一个简单的select方法,因此不管是什么负责的SLQ经过DistSQL都会变成单表的计算任务
- 点查:走KV模块,简单的获取单行数据的请求,例如根据主键或者唯一索引的等值查询等等都是由KV来实现的
在线DDL相关模块
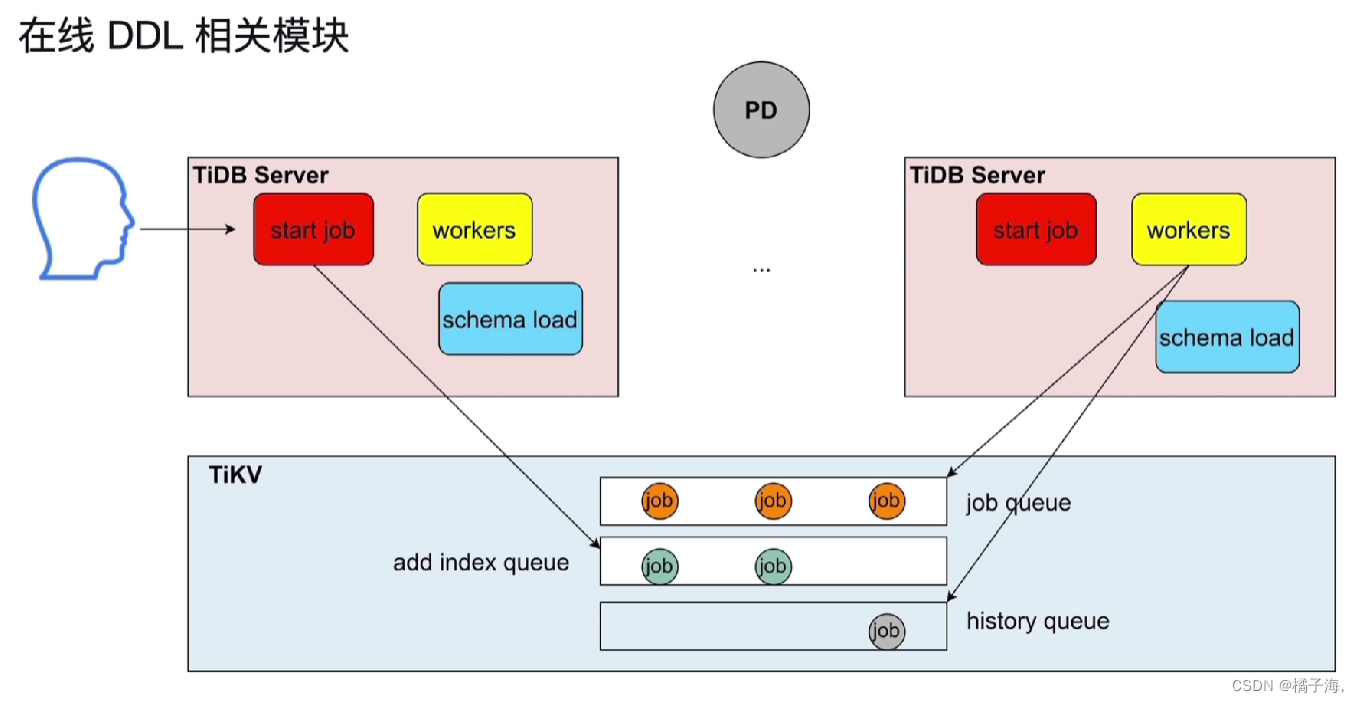
在进行DDL的时候是不会阻塞读写的,在整个集群中会有多个TiDB Server,对于整个TiDB数据库来讲,同一时刻只能有一个TiDB Server进行DDL操作,同一时刻只有一个TiDB Server中的worker可以做操作
用户发送一个DDL语句,首先由start job接收,然后会把它作为一个job放在任务队列中,同一时间只有一个Server在执行,称之为owner,owner中的workers负责从队列中取第一个执行,执行完放在历史队列,然后去取下一个
每一个Server都有一个任期,超出时间段就会重新发起选举,可能会有一个新的owner
schema load用于在当前TiDB Server成为onwer角色之后,会将最新的所有表的信息同步到内部的缓存之中
GC机制与相关模块
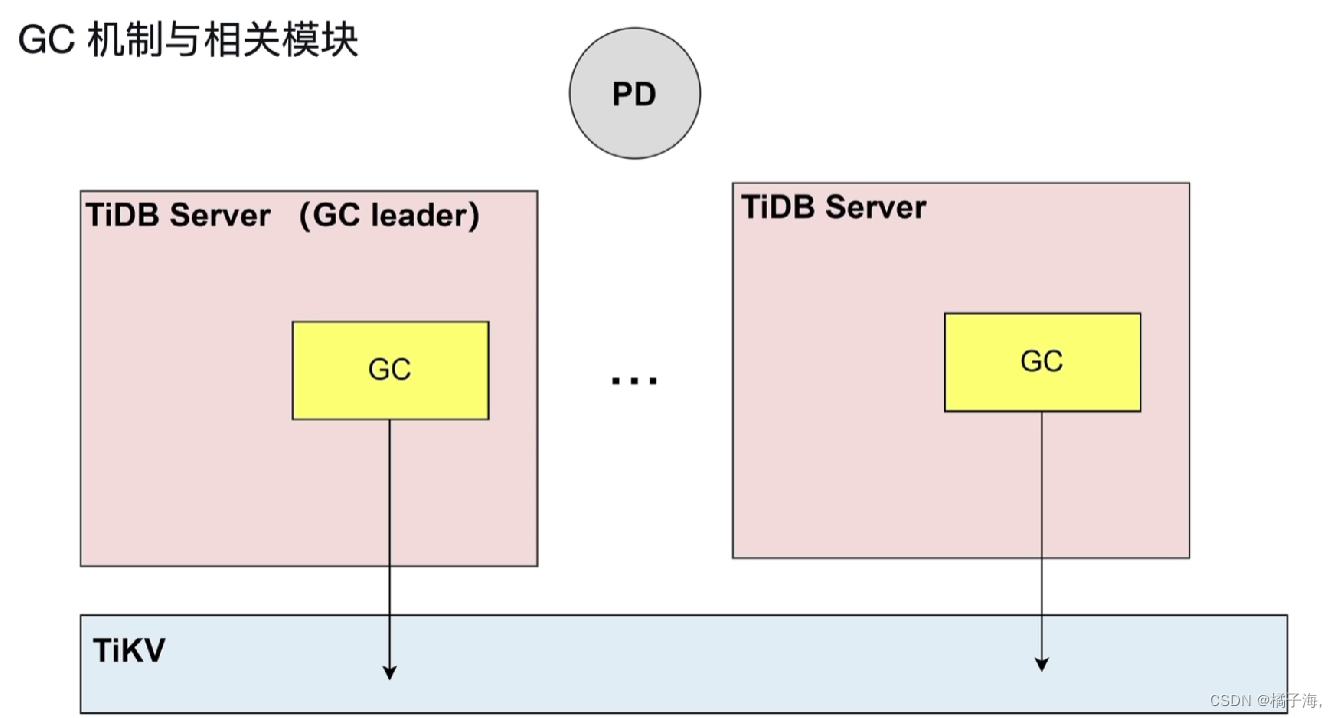
定期清理历史版本
会有一个 TiDB Server会被选为GC leader,由它控制整个GC,会计算出一个时间戳safe point,这个时间以前的数据会被回收
TiDB Server的缓存
-
TiDB Server缓存的组成
- SQL结果
- 线程缓存
- 元数据,统计信息
-
TiDB Server缓存管理
- tidb_mem_quota_query:控制每条SQL语句能够默认使用的存储量
- oom-action:如果SQL的内存使用超过上面设置的tidb_mem_quota_query之后,它是中断这条SQL,返回error,还是记录日志等等行为
热点小表缓存
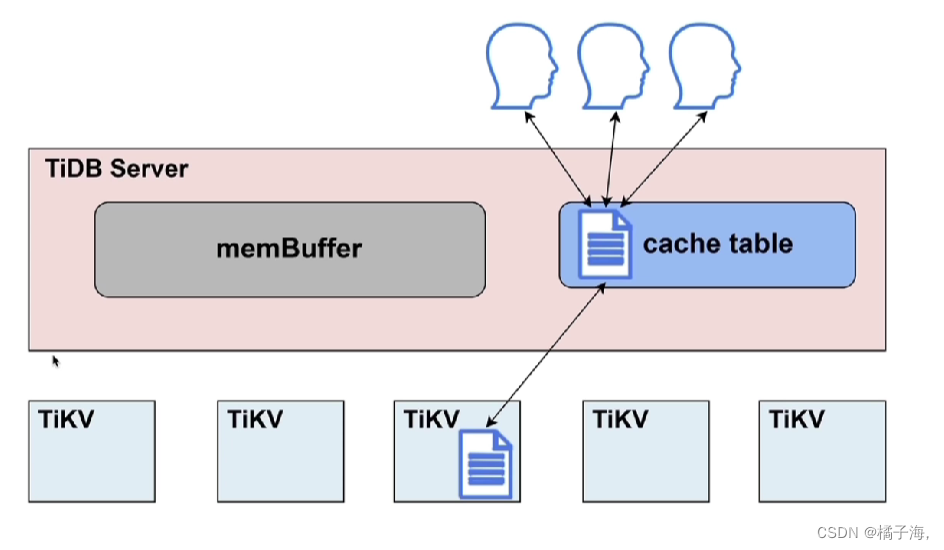
- 表的数据量不大
- 只读表或者修改不频繁的表
- 表的访问很频繁
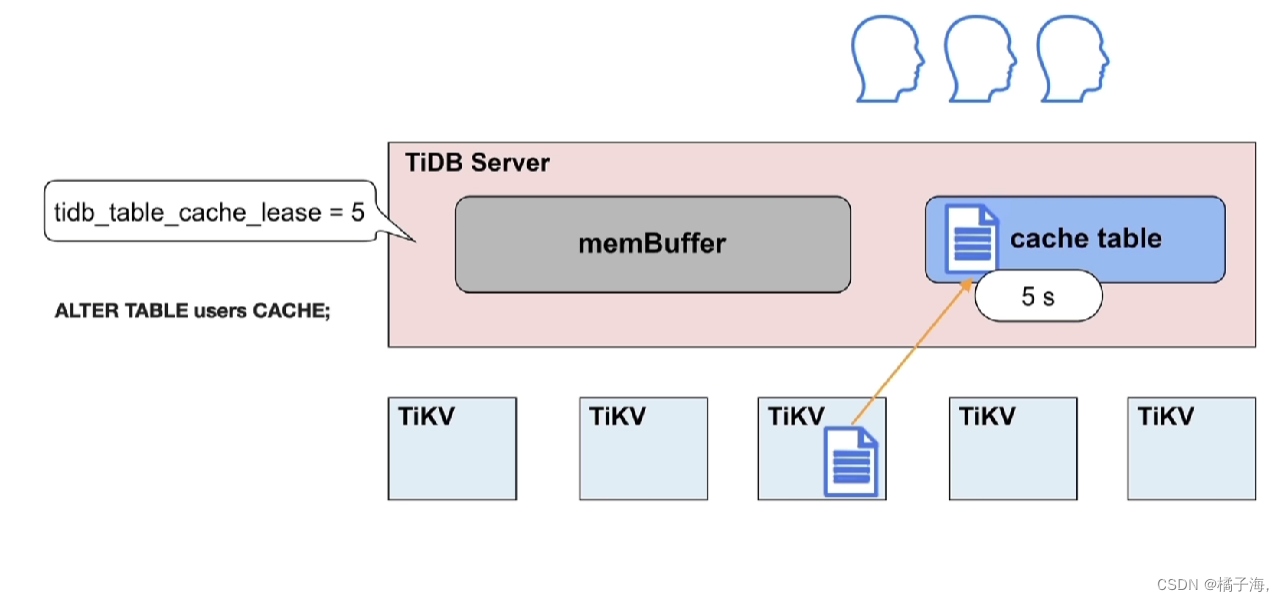
表的大小不能超过64M
放进去之后为了保证读写一致,设置了一个参数tidb_table_cache_lease,也就是租约,默认5s
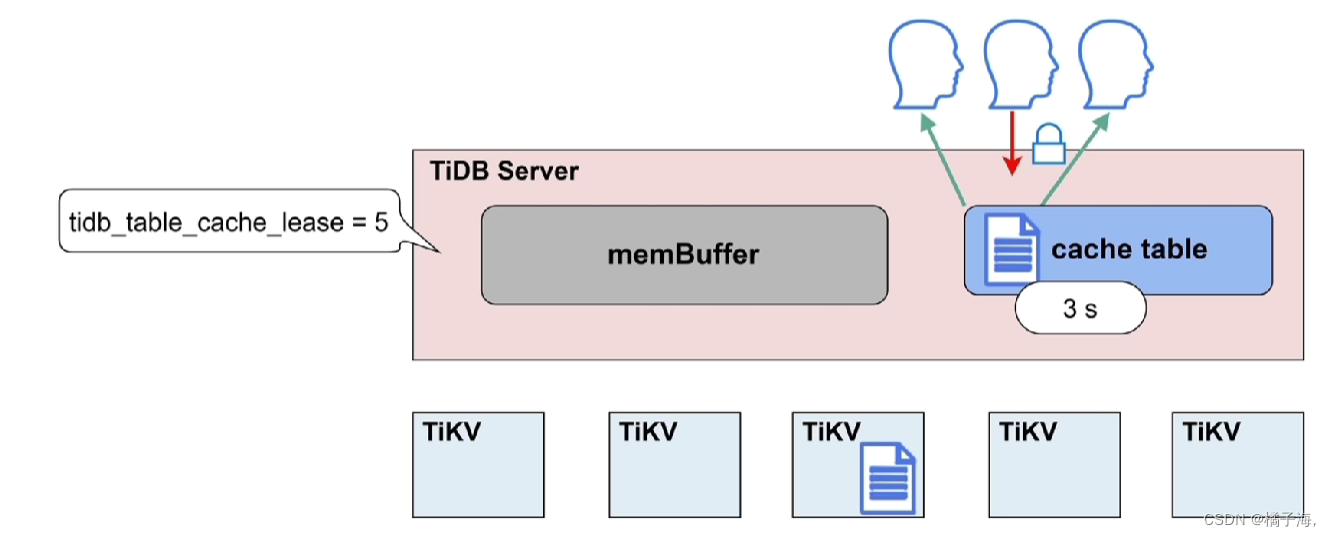
在这5s之内用户可以直接读这张表,租约时间内,无法进行写操作
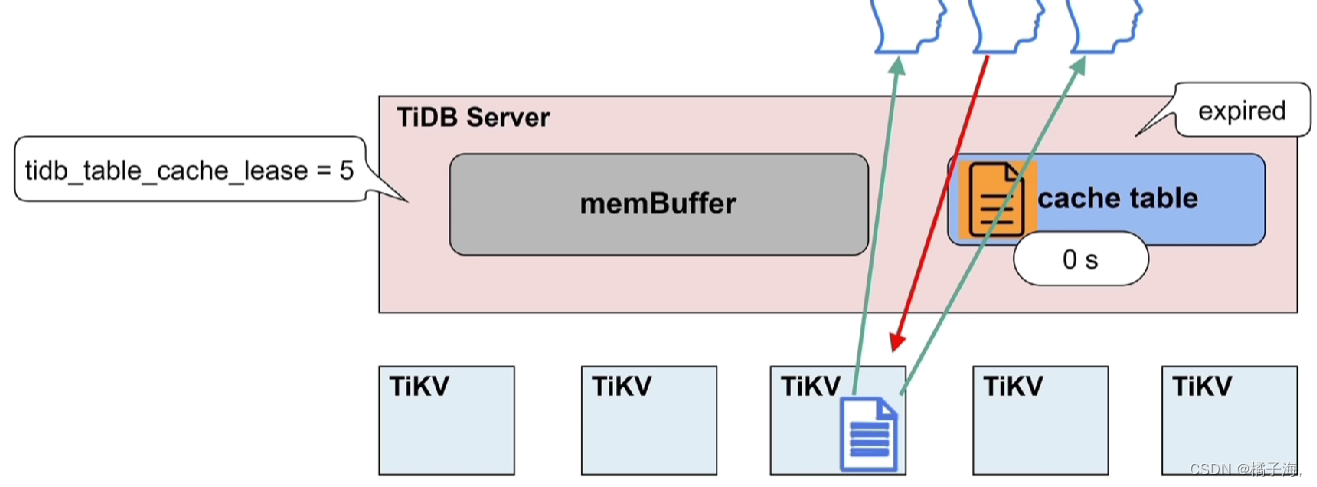
租约到期后,这张小表就过期了,这个时候就可以直接去写TiKV,这个时候从TiKV中读取
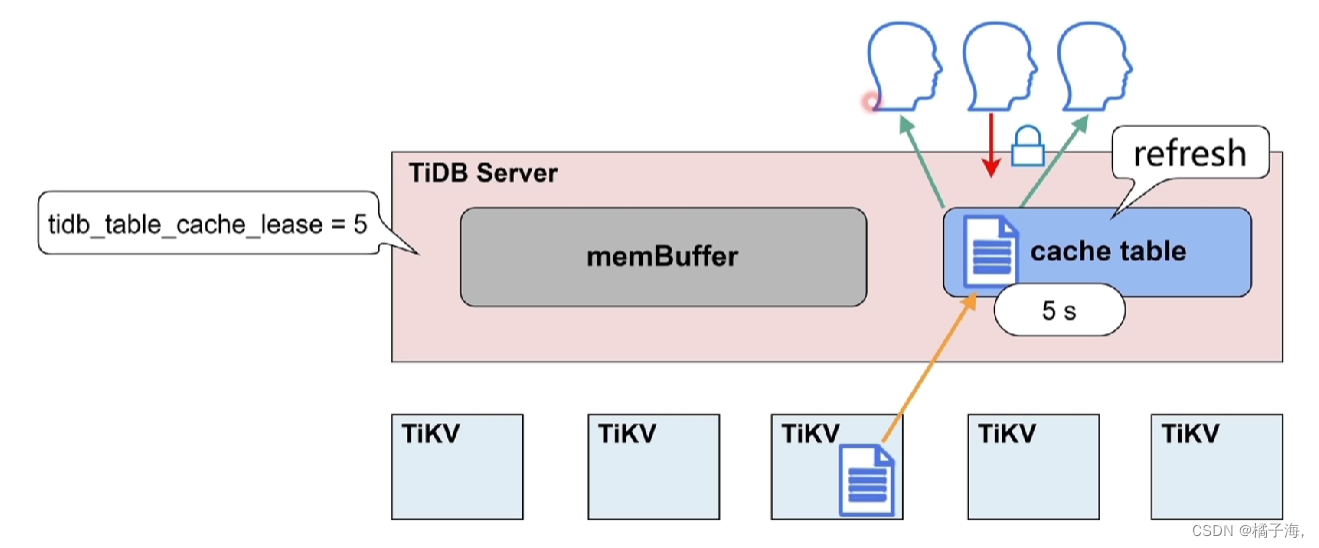
数据更新完毕,租约继续开启